

1. Pengenalan Ringkas
Rangkaian saraf dalam telah menjadi semakin popular sejak beberapa tahun kebelakangan ini, menyelesaikan masalah yang tidak dapat diselesaikan sebelum ini dalam banyak bidang dan menunjukkan keupayaan hebatnya. Dalam ramalan siri masa, harga rangkaian saraf yang biasa digunakan ialah RNN, kerana RNN bukan sahaja mempunyai input data semasa, tetapi juga input data sejarah Sudah tentu, apabila kita bercakap tentang harga ramalan RNN, kita sering bercakap tentang jenis RNN : LSTM . Artikel ini akan membina model untuk meramalkan harga Bitcoin berdasarkan pytorch. Walaupun terdapat banyak maklumat yang relevan di Internet, ia masih tidak cukup teliti, dan terdapat sedikit orang yang menggunakan pytorch Ia masih perlu untuk menulis artikel Hasil akhir adalah menggunakan harga pembukaan, harga penutupan. harga tertinggi, harga terendah, dan jumlah transaksi pasaran Bitcoin untuk meramalkan harga penutupan seterusnya. Pengetahuan peribadi saya tentang rangkaian saraf adalah sederhana, dan saya mengalu-alukan kritikan dan pembetulan anda.
Tutorial ini dihasilkan oleh FMZ, pencipta platform dagangan kuantitatif mata wang digital (www.fmz.com Selamat datang untuk menyertai kumpulan QQ: 863946592 untuk komunikasi).
2. Data dan rujukan
Contoh ramalan harga yang berkaitan: https://yq.aliyun.com/articles/538484
Pengenalan terperinci kepada model RNN: https://zhuanlan.zhihu.com/p/27485750
Memahami input dan output RNN: https://www.zhihu.com/question/41949741/answer/318771336
Mengenai pytorch: Dokumentasi rasmi https://pytorch.org/docs Cari maklumat lain sendiri.
Selain itu, beberapa pengetahuan prasyarat diperlukan untuk memahami artikel ini, seperti panda/crawler/pemprosesan data, dsb., tetapi tidak mengapa jika anda tidak mengetahuinya.
3. Parameter model pytorch LSTM
Parameter LSTM:
Apabila saya mula-mula melihat parameter padat ini pada dokumen, reaksi saya ialah:

Sambil membaca perlahan-lahan, akhirnya saya faham.

input_size: Saiz ciri vektor input x Jika harga penutup digunakan untuk meramalkan harga penutupan, maka input_size=1 jika harga penutupan diramalkan dengan membuka tinggi dan menutup rendah, maka input_size=4;
hidden_size: Saiz lapisan tersembunyi
num_layers: Bilangan lapisan RNN
batch_first: Jika Benar, dimensi input pertama ialah batch_size Parameter ini juga sangat mengelirukan dan akan diterangkan secara terperinci di bawah.
Parameter data input:
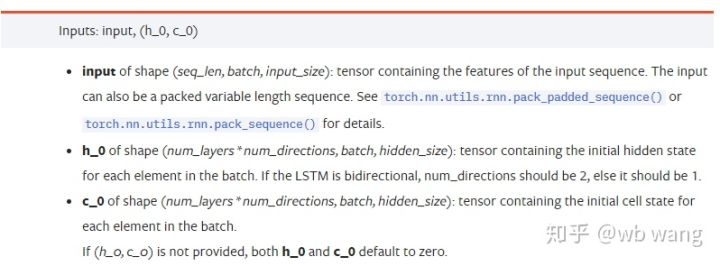
input: Data input khusus ialah tensor tiga dimensi dengan bentuk tertentu (seq_len, batch, input_size). Antaranya, seq_len merujuk kepada panjang jujukan, iaitu, berapa lama data sejarah yang perlu dipertimbangkan oleh LSTM. Sila ambil perhatian bahawa ini hanya merujuk kepada format data, bukan struktur dalaman LSTM model yang sama input data dengan seq_len yang berbeza dan boleh memberikan ramalan Hasil kumpulan merujuk kepada saiz kumpulan, yang mewakili berapa banyak kumpulan data yang ada ialah saiz_masukan.
h_0: Keadaan awal tersembunyi, bentuk ialah (num_layers * num_directions, batch, hidden_size), jika ia adalah rangkaian dwiarah num_directions=2
c_0: Keadaan sel awal, bentuk adalah sama seperti di atas, boleh dibiarkan tidak ditentukan.
Parameter keluaran:
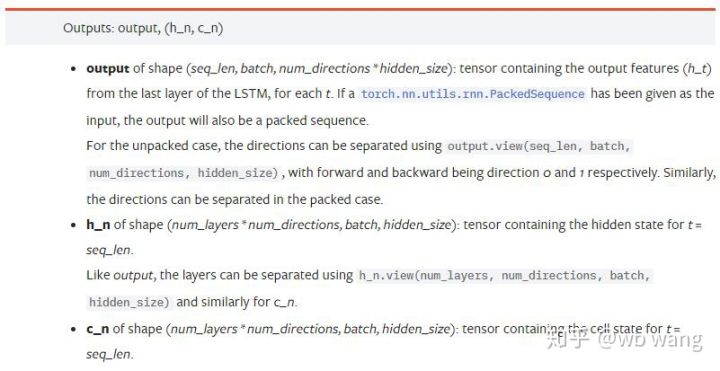
output: Bentuk output (seq_len, batch, num_directions * hidden_size), ambil perhatian bahawa ia berkaitan dengan parameter model batch_first
h_n: h nyatakan pada masa t = seq_len, sama bentuk dengan h_0
c_n: c nyatakan pada masa t = seq_len, sama bentuk dengan c_0
4. Contoh mudah input dan output LSTM
Mula-mula import pakej yang diperlukan
python
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
Mentakrifkan model LSTM
python
LSTM = nn.LSTM(input_size=5, hidden_size=10, num_layers=2, batch_first=True)
Menyediakan data input
python
x = torch.randn(3,4,5)
# x的值为:
tensor([[[ 0.4657, 1.4398, -0.3479, 0.2685, 1.6903],
[ 1.0738, 0.6283, -1.3682, -0.1002, -1.7200],
[ 0.2836, 0.3013, -0.3373, -0.3271, 0.0375],
[-0.8852, 1.8098, -1.7099, -0.5992, -0.1143]],
[[ 0.6970, 0.6124, -0.1679, 0.8537, -0.1116],
[ 0.1997, -0.1041, -0.4871, 0.8724, 1.2750],
[ 1.9647, -0.3489, 0.7340, 1.3713, 0.3762],
[ 0.4603, -1.6203, -0.6294, -0.1459, -0.0317]],
[[-0.5309, 0.1540, -0.4613, -0.6425, -0.1957],
[-1.9796, -0.1186, -0.2930, -0.2619, -0.4039],
[-0.4453, 0.1987, -1.0775, 1.3212, 1.3577],
[-0.5488, 0.6669, -0.2151, 0.9337, -1.1805]]])
Bentuk x ialah (3,4,5), kerana kita takrifkanbatch_first=True, pada masa ini, saiz_kelompok ialah 3, sqe_len ialah 4 dan saiz_input ialah 5. x[0] mewakili kumpulan pertama.
Jika batch_first tidak ditakrifkan, ia lalai kepada False, dan data diwakili sepenuhnya berbeza, dengan saiz kelompok 4, sqe_len 3 dan input_size 5. Pada masa ini x[0] mewakili data semua kelompok pada t=0, dan seterusnya. Saya secara peribadi merasakan bahawa tetapan ini tidak intuitif, jadi saya menambah parameterbatch_first=True.
Penukaran data antara keduanya juga sangat mudah:x.permute(1,0,2)
Input dan Output
Bentuk input dan output LSTM mudah dikelirukan, dengan bantuan angka berikut untuk membantu memahami:
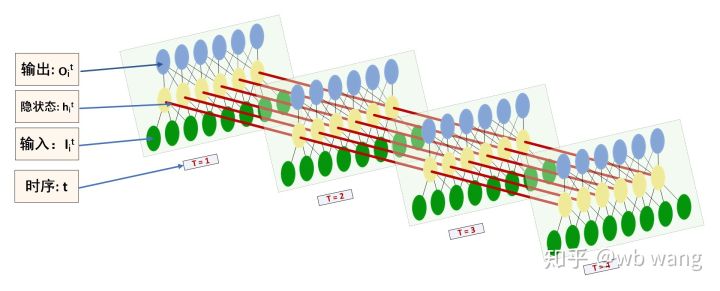
Sumber: https://www.zhihu.com/question/41949741/answer/318771336
python
x = torch.randn(3,4,5)
h0 = torch.randn(2, 3, 10)
c0 = torch.randn(2, 3, 10)
output, (hn, cn) = LSTM(x, (h0, c0))
print(output.size()) #在这里思考一下,如果batch_first=False输出的大小会是多少?
print(hn.size())
print(cn.size())
#结果
torch.Size([3, 4, 10])
torch.Size([2, 3, 10])
torch.Size([2, 3, 10])
Perhatikan hasil keluaran, yang konsisten dengan penjelasan parameter sebelumnya. Ambil perhatian bahawa nilai kedua hn.size() ialah 3, yang konsisten dengan saiz batch_size, menunjukkan bahawa tiada keadaan perantaraan disimpan dalam hn, hanya langkah terakhir.
Oleh kerana rangkaian LSTM kami mempunyai dua lapisan, output lapisan terakhir hn sebenarnya adalah nilai output, dan bentuk output ialah[3, 4, 10], menyimpan keputusan semua momen t=0,1,2,3, jadi:
python
hn[-1][0] == output[0][-1] #第一个batch在hn最后一层的输出等于第一个batch在t=3时output的结果
hn[-1][1] == output[1][-1]
hn[-1][2] == output[2][-1]
5. Sediakan data pasaran Bitcoin
Banyak daripada apa yang saya katakan sebelum ini hanyalah pendahuluan. Adalah sangat penting untuk memahami input dan output LSTM. Jika tidak, adalah mudah untuk membuat kesilapan jika anda menyalin beberapa kod secara rawak LSTM dalam siri masa, walaupun model itu salah, anda boleh mendapatkannya pada akhirnya.
Pemerolehan Data
Data yang digunakan ialah data pasaran pasangan dagangan BTC_USD bursa Bitfinex.
python
import requests
import json
resp = requests.get('https://q.fmz.com/chart/history?symbol=bitfinex.btc_usd&resolution=15&from=0&to=0&from=1525622626&to=1562658565')
data = resp.json()
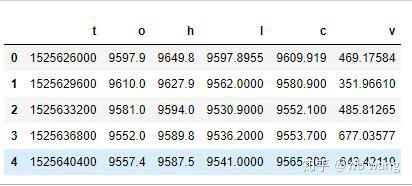
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
print(df.head(5))
Format data adalah seperti berikut:
Prapemprosesan data
python
df.index = df['t'] # index设为时间戳
df = (df-df.mean())/df.std() # 数据的标准化,否则模型的Loss会非常大,不利于收敛
df['n'] = df['c'].shift(-1) # n为下一个周期的收盘价,是我们预测的目标
df = df.dropna()
df = df.astype(np.float32) # 改变下数据格式适应pytorch
Kaedah penyeragaman data adalah sangat kasar dan akan ada beberapa masalah Ia hanya untuk demonstrasi Anda boleh menggunakan penyeragaman data seperti hasil.
Menyediakan data latihan
python
seq_len = 10 # 输入10个周期的数据
train_size = 800 # 训练集batch_size
def create_dataset(data, seq_len):
dataX, dataY=[], []
for i in range(0,len(data)-seq_len, seq_len):
dataX.append(data[['o','h','l','c','v']][i:i+seq_len].values)
dataY.append(data['n'][i:i+seq_len].values)
return np.array(dataX), np.array(dataY)
data_X, data_Y = create_dataset(df, seq_len)
train_x = torch.from_numpy(data_X[:train_size].reshape(-1,seq_len,5)) #变化形状,-1代表的值会自动计算
train_y = torch.from_numpy(data_Y[:train_size].reshape(-1,seq_len,1))
Bentuk akhir train_x dan train_y ialah: torch.Size([800, 10, 5]), torch.Size([800, 10, 1]). Memandangkan model kami meramalkan harga penutupan tempoh seterusnya berdasarkan data daripada 10 tempoh, secara teorinya, 800 kelompok hanya memerlukan 800 harga penutup yang diramalkan. Tetapi train_y mempunyai 10 data dalam setiap kumpulan Malah, keputusan perantaraan setiap ramalan kumpulan dikekalkan, bukan hanya yang terakhir. Apabila mengira Kerugian akhir, kesemua 10 keputusan ramalan boleh diambil kira dan dibandingkan dengan nilai sebenar dalam train_y. Secara teorinya, adalah mungkin untuk hanya mengira Kehilangan hasil ramalan terakhir. Saya melukis gambarajah kasar untuk menggambarkan masalah ini. Oleh kerana model LSTM sebenarnya tidak mengandungi parameter seq_len, model itu boleh digunakan pada panjang yang berbeza, dan keputusan ramalan pertengahan juga bermakna, jadi saya cenderung untuk menggabungkan pengiraan Kerugian.
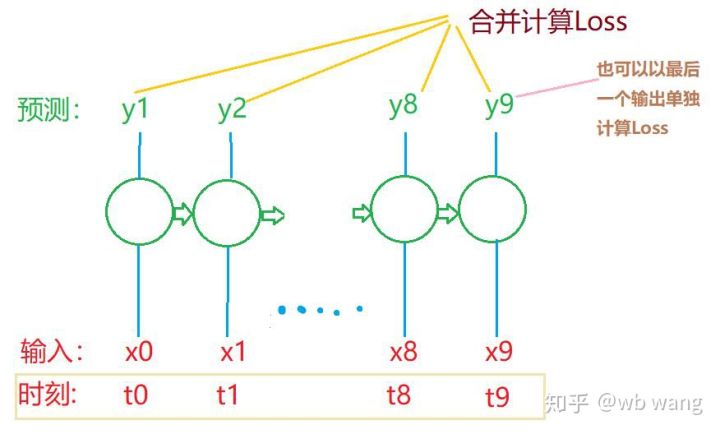
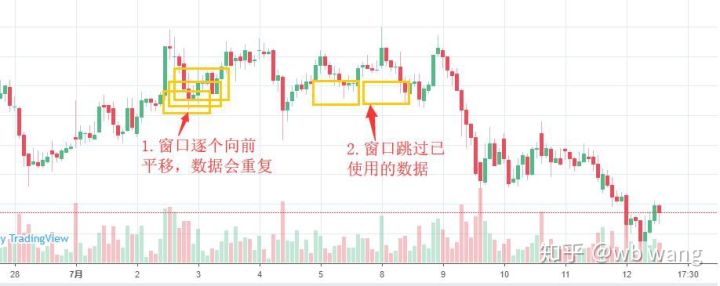
Perhatikan bahawa semasa menyediakan data latihan, pergerakan tetingkap adalah gelisah, dan data yang telah digunakan sudah tidak digunakan lagi, tingkap juga boleh digerakkan satu demi satu, supaya set latihan yang diperoleh akan menjadi lebih besar . Tetapi saya merasakan bahawa data kelompok bersebelahan terlalu berulang, jadi saya menggunakan kaedah semasa.
6. Membina model LSTM
Model akhir adalah seperti berikut, yang merangkumi LSTM dua lapisan dan lapisan Linear.
python
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size=1, num_layers=2):
super(LSTM, self).__init__()
self.rnn = nn.LSTM(input_size,hidden_size,num_layers,batch_first=True)
self.reg = nn.Linear(hidden_size,output_size) # 线性层,把LSTM的结果输出成一个值
def forward(self, x):
x, _ = self.rnn(x) # 如果不理解前向传播中数据维度的变化,可单独调试
x = self.reg(x)
return x
net = LSTM(5, 10) # input_size为5,代表了高开低收和交易量. 隐含层为10.
7. Mula melatih model
Akhirnya memulakan latihan, kodnya adalah seperti berikut:
python
criterion = nn.MSELoss() # 使用了简单的均方差损失函数
optimizer = torch.optim.Adam(net.parameters(),lr=0.01) # 优化函数,lr可调
for epoch in range(600): # 由于速度很快,这里的epoch多一些
out = net(train_x) # 由于数据量很小, 直接拿全量数据计算
loss = criterion(out, train_y)
optimizer.zero_grad()
loss.backward() # 反向传播损失
optimizer.step() # 更新参数
print('Epoch: {:<3}, Loss:{:.6f}'.format(epoch+1, loss.item()))
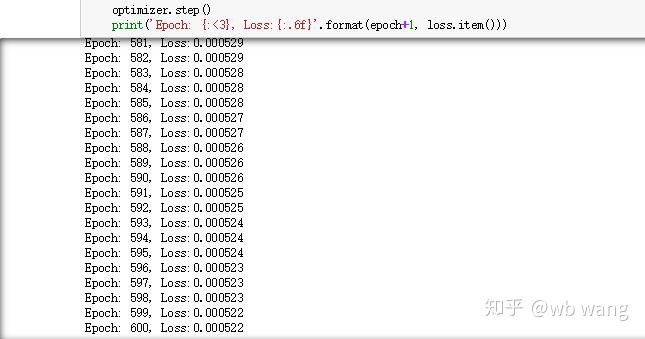
Keputusan latihan adalah seperti berikut:
8. Penilaian Model
Nilai ramalan model ialah:
python
p = net(torch.from_numpy(data_X))[:,-1,0] # 这里只取最后一个预测值作为比较
plt.figure(figsize=(12,8))
plt.plot(p.data.numpy(), label= 'predict')
plt.plot(data_Y[:,-1], label = 'real')
plt.legend()
plt.show()
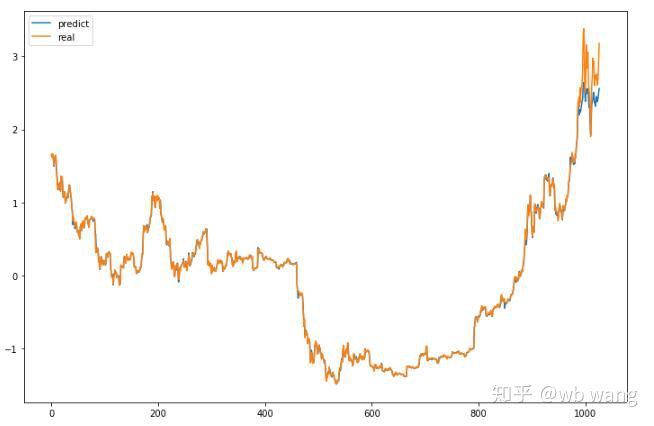
Seperti yang dapat dilihat dari rajah, tahap kesesuaian data latihan (sebelum 800) adalah sangat tinggi, tetapi harga Bitcoin telah meningkat ke tahap tinggi baru kemudian, dan model tidak melihat data ini, jadi ramalannya adalah tidak dapat beraksi dengan baik. Ini juga menunjukkan bahawa terdapat masalah dalam penyeragaman data sebelumnya.
Walaupun harga yang diramalkan mungkin tidak tepat, sejauh manakah ramalan kenaikan dan kejatuhan tersebut. Lihat bahagian data ramalan:
python
r = data_Y[:,-1][800:1000]
y = p.data.numpy()[800:1000]
r_change = np.array([1 if i > 0 else 0 for i in r[1:200] - r[:199]])
y_change = np.array([1 if i > 0 else 0 for i in y[1:200] - r[:199]])
print((r_change == y_change).sum()/float(len(r_change)))
Ketepatan meramalkan kenaikan dan penurunan mencapai 81.4%, yang melebihi jangkaan saya. Saya tidak tahu sama ada saya membuat kesilapan di suatu tempat.
Sudah tentu, model ini tidak mempunyai nilai sebenar, tetapi ia adalah mudah dan mudah untuk difahami. Hanya gunakan ini sebagai titik permulaan akan ada lebih banyak kursus pengenalan mengenai aplikasi rangkaian saraf dalam kuantiti mata wang digital.


