

Prefácio
O sistema de backtesting da Inventor Quantitative Trading Platform é um sistema de backtesting que está constantemente iterando, atualizando e melhorando. Das funções básicas iniciais de backtesting, ele gradualmente adiciona funções e otimiza o desempenho. À medida que a plataforma se desenvolve, o sistema de backtesting continuará a ser otimizado e atualizado. Hoje, discutiremos um tópico baseado no sistema de backtesting: "Teste de estratégia baseado em condições aleatórias de mercado".
precisar
No campo da negociação quantitativa, o desenvolvimento e a otimização de estratégias não podem ser separados da verificação de dados reais de mercado. Entretanto, em aplicações reais, devido ao ambiente de mercado complexo e mutável, confiar em dados históricos para backtesting pode apresentar deficiências, como falta de cobertura de condições extremas de mercado ou cenários especiais. Portanto, projetar um gerador de mercado aleatório eficiente se torna uma ferramenta eficaz para desenvolvedores de estratégias quantitativas.
Quando precisamos testar a estratégia em uma determinada bolsa ou moeda usando dados históricos, podemos usar a fonte de dados oficial da plataforma FMZ para o backtest. Às vezes, também queremos ver como uma estratégia se sai em um mercado completamente "desconhecido". Nesse momento, podemos "fabricar" alguns dados para testar a estratégia.
A importância de usar dados aleatórios de mercado é:
-
- Avaliando a robustez da estratégia
O gerador de mercado aleatório pode criar uma variedade de cenários de mercado possíveis, incluindo volatilidade extrema, baixa volatilidade, mercados de tendência e mercados voláteis. Testar uma estratégia nesses ambientes simulados pode ajudar a avaliar se seu desempenho é estável sob diferentes condições de mercado. Por exemplo:
A estratégia pode se adaptar a mudanças de tendência e choque?
A estratégia resultará em perdas substanciais em condições extremas de mercado? - Avaliando a robustez da estratégia
-
- Identifique potenciais fraquezas em sua estratégia
Ao simular algumas situações anormais de mercado (como eventos hipotéticos de cisne negro), potenciais fraquezas na estratégia podem ser descobertas e melhoradas. Por exemplo:
A estratégia depende muito de uma estrutura de mercado específica?
Existe risco de sobreajuste dos parâmetros? - Identifique potenciais fraquezas em sua estratégia
-
- Otimizando parâmetros de estratégia
Dados gerados aleatoriamente fornecem um ambiente de teste mais diversificado para ajuste de parâmetros de estratégia sem precisar depender inteiramente de dados históricos. Isso permite uma gama mais abrangente de parâmetros estratégicos e evita a limitação a padrões de mercado específicos em dados históricos.
- Otimizando parâmetros de estratégia
-
- Preenchendo a lacuna em dados históricos
Em alguns mercados (como mercados emergentes ou mercados que negociam moedas pequenas), os dados históricos podem não ser suficientes para cobrir todas as condições de mercado possíveis. O randomizador pode fornecer uma grande quantidade de dados suplementares para facilitar testes mais abrangentes.
- Preenchendo a lacuna em dados históricos
-
- Desenvolvimento iterativo rápido
Usar dados aleatórios para testes rápidos pode acelerar a iteração do desenvolvimento de estratégias sem depender de condições de mercado em tempo real ou de limpeza e organização de dados demoradas.
- Desenvolvimento iterativo rápido
No entanto, também é necessário avaliar racionalmente a estratégia. Para dados de mercado gerados aleatoriamente, observe:
-
- Embora os geradores aleatórios de mercado sejam úteis, sua importância depende da qualidade dos dados gerados e do design do cenário-alvo:
-
- A lógica de geração precisa estar próxima do mercado real: se as condições de mercado geradas aleatoriamente estiverem completamente fora da realidade, os resultados do teste podem não ter valor de referência. Por exemplo, o gerador pode ser projetado em combinação com características estatísticas reais do mercado (como distribuição de volatilidade, taxa de tendência).
-
- Não pode substituir completamente o teste de dados reais: dados aleatórios podem apenas suplementar o desenvolvimento e a otimização de estratégias. A estratégia final ainda precisa ser verificada quanto à sua eficácia em dados de mercado reais.
Dito isto, como podemos "fabricar" alguns dados? Como podemos "fabricar" dados de forma conveniente, rápida e fácil para uso em um sistema de backtesting?
Ideias de design
Este artigo foi criado para fornecer um ponto de partida para discussão e fornece um cálculo de geração de mercado aleatório relativamente simples. Na verdade, há uma variedade de algoritmos de simulação, modelos de dados e outras tecnologias que podem ser aplicadas. Devido ao espaço limitado da discussão , não usaremos métodos de simulação de dados particularmente complexos.
Combinando a função de fonte de dados personalizada do sistema de backtesting da plataforma, escrevemos um programa em Python.
-
- Gere aleatoriamente um conjunto de dados de K-line e grave-os em um arquivo CSV para gravação persistente, para que os dados gerados possam ser salvos.
-
- Em seguida, crie um serviço para fornecer suporte de fonte de dados para o sistema de backtesting.
-
- Exiba os dados da linha K gerados no gráfico.
Para alguns padrões de geração e armazenamento de arquivos de dados da linha K, os seguintes controles de parâmetros podem ser definidos:
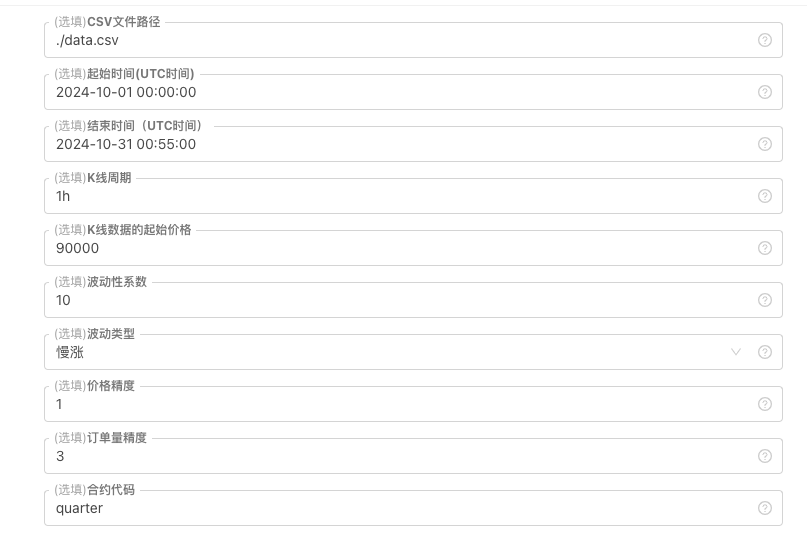
-
Padrão de dados gerado aleatoriamente
Para simular o tipo de flutuação dos dados da linha K, simplesmente usamos as diferentes probabilidades de números aleatórios positivos e negativos para fazer um design simples. Quando os dados gerados não são muitos, eles podem não ser capazes de refletir o padrão de mercado necessário. Se houver uma maneira melhor, você pode substituir esta parte do código.
Com base nesse design simples, ajustar o intervalo de geração de números aleatórios e alguns coeficientes no código pode afetar o efeito dos dados gerados. -
Verificação de dados
Os dados da linha K gerados também precisam ser verificados quanto à racionalidade, para verificar se os preços altos de abertura e baixos de fechamento violam a definição, para verificar a continuidade dos dados da linha K, etc.
Sistema de Backtesting Gerador de Cotações Aleatórias
python
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据data.detail:", data["detail"], "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("不支持的K线周期,请使用 'm', 'h', 或 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("异常数据:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("当前路径:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("文件写入成功,以下是文件内容的一部分:")
Log("".join(lines[:5]))
else:
Log("文件写入失败,文件为空!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("开启自定义数据源服务线程,数据由CSV文件提供。", ", 地址/端口:0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("生成器参数:", "起始时间:", startTime, "结束时间:", endTime, "K线周期:", KLinePeriod, "初始价格:", firstPrice, "波动类型:", arrTrendType[trendType], "波动性系数:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
Prática em sistema de backtesting
- Crie a instância de política acima, configure os parâmetros e execute-a.
- O mercado real (instância de estratégia) precisa ser executado em um host implantado em um servidor, porque um IP público é necessário para que o sistema de backtesting o acesse e obtenha dados.
- Clique no botão interativo e a estratégia começará automaticamente a gerar dados de mercado aleatórios.

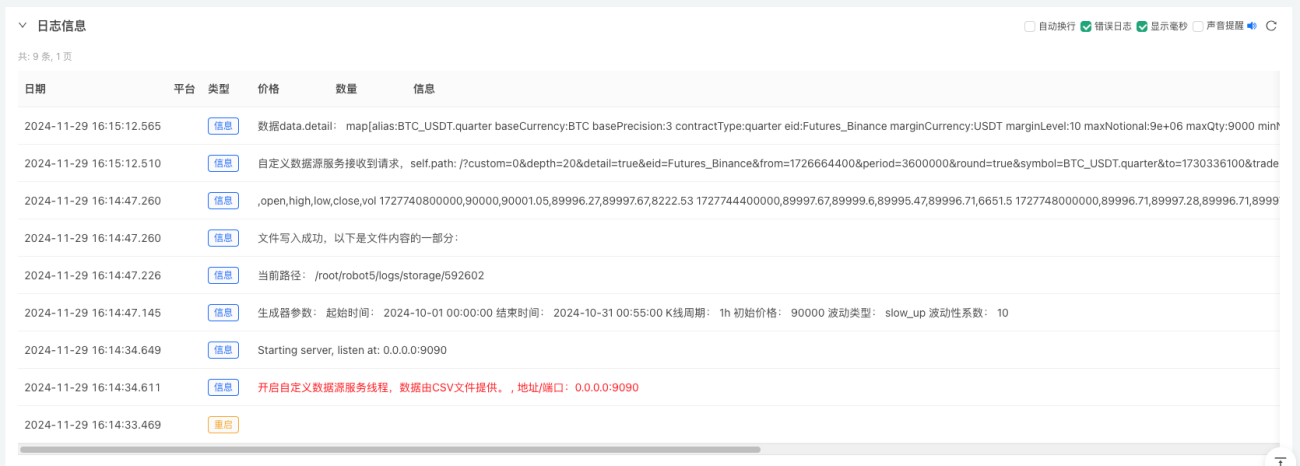
- Os dados gerados serão exibidos no gráfico para fácil observação e os dados serão registrados no arquivo data.csv local
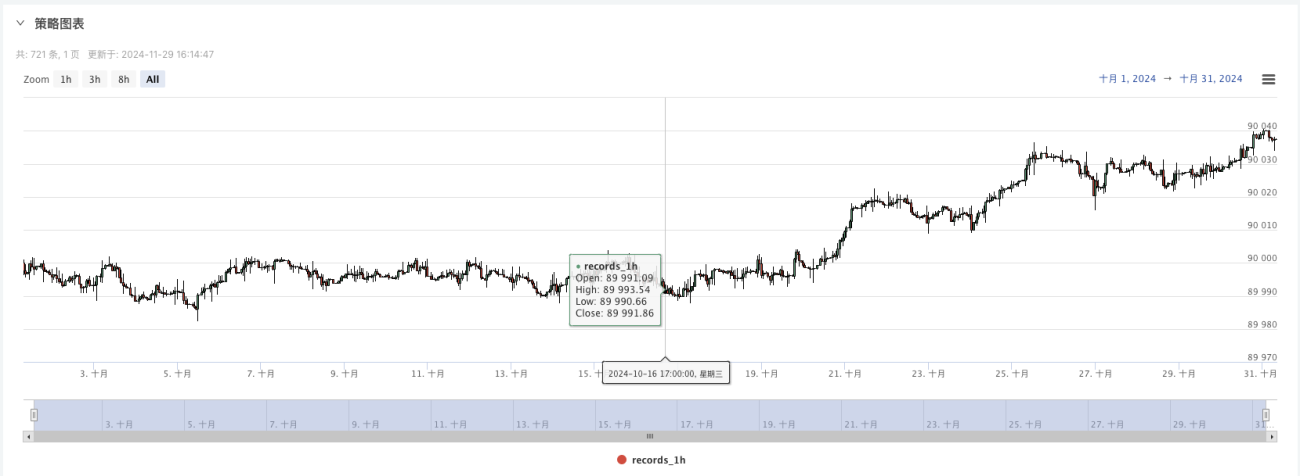
- Agora podemos usar esses dados gerados aleatoriamente e usar qualquer estratégia para backtesting
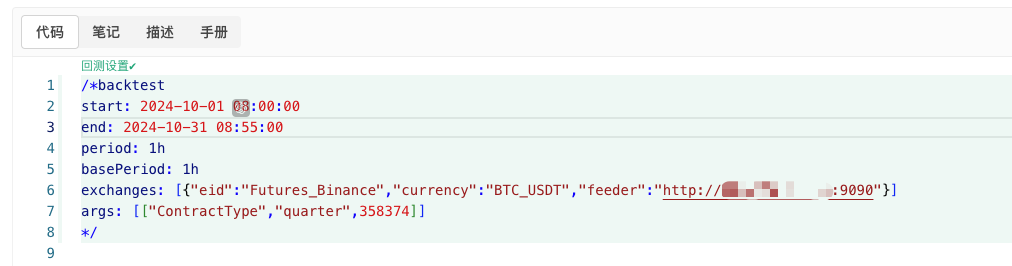
/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
Configure de acordo com as informações acima e faça ajustes específicos.http://xxx.xxx.xxx.xxx:9090É o endereço IP do servidor e a porta aberta do disco real da estratégia de geração de mercado aleatório.
Esta é uma fonte de dados personalizada. Você pode consultar a seção de fonte de dados personalizada na documentação da API da plataforma para obter mais informações.
- Depois que o sistema de backtest configura a fonte de dados, você pode testar os dados de mercado aleatórios
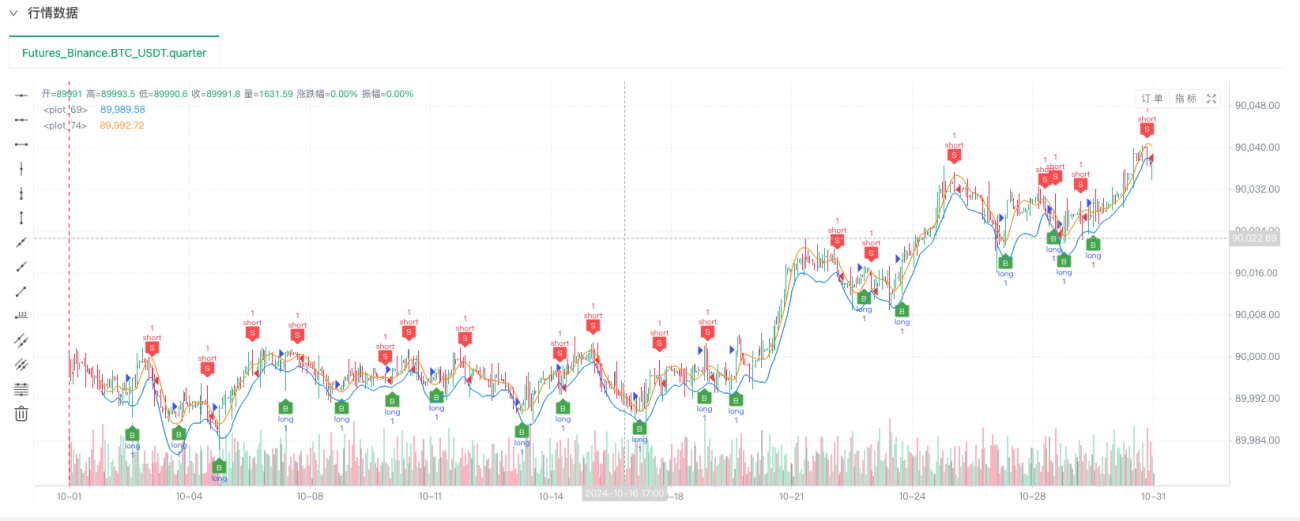
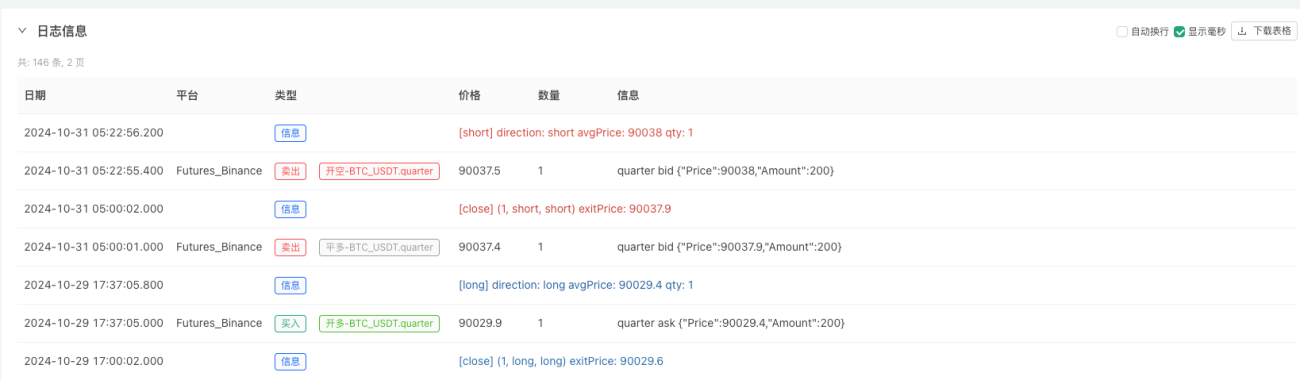
Neste ponto, o sistema de backtesting é testado usando nossos dados simulados "fabricados". De acordo com os dados no gráfico de mercado durante o backtest, compare os dados no gráfico em tempo real gerado por condições aleatórias de mercado. O horário é 17:00 em 16 de outubro de 2024. Os dados são os mesmos.
- Ah sim, quase esqueci de dizer isso! O motivo pelo qual este programa Python gerador de mercado aleatório cria um mercado real é para facilitar a demonstração, operação e exibição dos dados da linha K gerados. Na aplicação real, você pode escrever um script python independente, para não precisar executar o disco real.
Código fonte da estratégia:Sistema de Backtesting Gerador de Cotações Aleatórias
Obrigado pelo seu apoio e leitura.
- 1