

Classificador maduro: A Máquina de Vetores de Suporte (SVM) é um algoritmo de classificação binária (ou multivariada) poderoso e maduro. Prever a alta ou queda de uma ação é um problema típico de classificação binária.
Capacidade não linear: ao usar funções de kernel (como o kernel RBF), o SVM pode capturar relacionamentos não lineares complexos entre recursos de entrada, o que é crucial para dados do mercado financeiro.
Orientado por recursos: A eficácia do modelo depende em grande parte dos "recursos" que você fornece a ele. O fator alfa calculado agora é um bom começo, e podemos desenvolver mais recursos desse tipo para melhorar o poder preditivo.
Desta vez comecei com 3 esboços de recursos:
1: Características do fluxo de ordens de alta frequência:
alpha_1min: Fator de desequilíbrio do fluxo de ordens calculado com base em todos os ticks no último minuto.
alpha_5min: Fator de desequilíbrio do fluxo de ordens calculado com base em todos os ticks nos últimos 5 minutos.
alpha_15min: Fator de desequilíbrio do fluxo de ordens calculado com base em todos os ticks nos últimos 15 minutos.
ofi_1min (Desequilíbrio do Fluxo de Ordens): A relação entre (volume de compra / volume de venda) em um período de 1 minuto. Isso é mais direto do que alfa.
vol_per_trade_1min: Volume médio por negociação em 1 minuto. Um sinal de grandes ordens impactando o mercado.
2: Características de preço e volatilidade:
log_return_5min: A taxa de retorno logarítmica nos últimos 5 minutos, log(P_t / P_{t-5min}).
volatility_15min: O desvio padrão dos retornos logarítmicos nos últimos 15 minutos, uma medida de volatilidade de curto prazo.
atr_14 (Average True Range): valor de ATR baseado nos últimos 14 candlesticks de 1 minuto, um indicador clássico de volatilidade.
rsi_14 (Índice de Força Relativa): Esta é uma medida das condições de sobrecompra e sobrevenda com base nos valores RSI dos últimos 14 candlesticks de 1 minuto.
3: Características do tempo:
hour_of_day: Hora atual (0-23). Os mercados se comportam de maneira diferente em diferentes períodos (por exemplo, sessões asiáticas/europeias/americanas).
day_of_week: Dia da semana (0-6). Fins de semana e dias úteis têm padrões de flutuação diferentes.
def calculate_features_and_labels(klines):
"""
核心函数
"""
features = []
labels = []
# 为了计算RSI等指标,我们需要价格序列
close_prices = [k['close'] for k in klines]
# 从第30根K线开始,因为需要足够的前置数据
for i in range(30, len(klines) - PREDICT_HORIZON):
# 1. 价格与波动率特征
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
# 计算RSI
diffs = np.diff(close_prices[i-14:i+1])
gains = np.sum(diffs[diffs > 0]) / 14
losses = -np.sum(diffs[diffs < 0]) / 14
rs = gains / (losses + 1e-10)
rsi_14 = 100 - (100 / (1 + rs))
# 2. 时间特征
dt_object = datetime.fromtimestamp(klines[i]['ts'] / 1000)
hour_of_day = dt_object.hour
day_of_week = dt_object.weekday()
# 组合所有特征
current_features = [price_change_15m, volatility_30m, rsi_14, hour_of_day, day_of_week]
features.append(current_features)
# 3. 数据标注
future_price = klines[i + PREDICT_HORIZON]['close']
current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD):
labels.append(0) # 涨
elif future_price < current_price * (1 - SPREAD_THRESHOLD):
labels.append(1) # 跌
else:
labels.append(2) # 横盘
Em seguida, use três categorias para distinguir entre subida, descida e lateral.
A ideia central da triagem de recursos: encontrar "bons companheiros de equipe" e eliminar "maus companheiros de equipe"
Nosso objetivo é encontrar um conjunto de recursos que:
- Alta relevância: cada característica tem uma forte correlação com futuras mudanças de preço (nosso rótulo alvo).
- Baixa redundância: os recursos não devem conter muitas informações duplicadas. Por exemplo, "momentum de 5 minutos" e "momentum de 6 minutos" são muito semelhantes. Incluir ambos não melhorará muito o modelo e pode até introduzir ruído.
- Estabilidade: A validade de um recurso não pode mudar muito rapidamente ao longo do tempo. Um recurso válido apenas por um dia é perigoso.
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
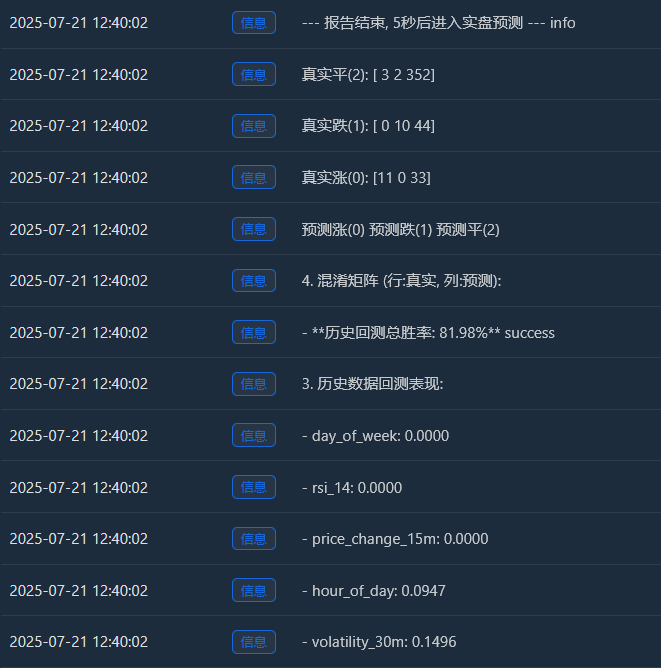
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1) 预测平(2)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0,0]}"); Log(f"真实平(2): {cm[2] if len(cm) > 2 else [0,0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i] and y[i] != 2: balance *= (1 + 0.01)
elif y_pred[i] != y[i] and y_pred[i] != 2: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
O processo é:
Coletando dados
Importância do recurso

Informações mútuas entre recursos e rótulos e informações de backtest
Inicialmente, pensei que uma taxa de vitória de 65% seria suficiente, mas não esperava que chegasse a 81,98%. Minha primeira reação deveria ser: "Isso é ótimo, mas é bom demais para ser verdade. Deve haver algo que valha a pena explorar aqui."
1. Interpretação aprofundada do relatório de análise, interpretando o conteúdo do relatório um por um:
- Importância do recurso e informações mútuas:
Volatilidade_30m e variação_preço_15m são as características mais importantes. Isso é lógico, indicando que a tendência recente do mercado e a volatilidade são os preditores mais fortes do futuro.
O hour_of_day também contribui um pouco, indicando que o modelo captura os padrões de negociação em diferentes momentos do dia.
As contribuições de rsi_14 e day_of_week são quase 0, o que sugere que essas duas características podem ser "companheiras de equipe" no conjunto de dados e na combinação de características atuais. Podemos considerar removê-las no futuro para simplificar o modelo e evitar ruído. - Matriz de Confusão (é muita informação!)
Aumento real (0):[11 0 33] -> De 44 (11+0+33) altas reais, o modelo previu corretamente 11, mas errou como “consolidação” 33 vezes.
Queda real (1):[0 10 44] -> De 54 (0+10+44) declínios reais, o modelo previu corretamente 10, mas errou como uma "tendência lateral" 44 vezes.
Ping Real (2):[3 2 352] -> Das 357 (3+2+352) consolidações reais, o modelo previu corretamente 352 delas! - Taxa de sucesso total do backtest histórico: 81,98%
A principal fonte dessa alta taxa de sucesso é a altíssima precisão do modelo em prever "consolidação"! De um total de aproximadamente 455 amostras, mais de 350 eram mercados de consolidação, e o modelo os identificou quase perfeitamente.
Esta é uma habilidade muito valiosa por si só! Um modelo que pode dizer com precisão que "é melhor não se mudar agora" pode ajudar você a economizar muitas taxas e transações inválidas.
2Por que a taxa real de vitórias pode ser menor que 81,98%?
- A definição de "consolidação" é muito vaga: nosso SPREAD_THRESHOLD é de 0,5%. Flutuações de preço de no máximo 0,5% em um período de 15 minutos são bastante comuns. Como resultado, as amostras de "consolidação" representam a grande maioria (aproximadamente 80%) do nosso conjunto de dados. O modelo aprendeu habilmente: "Quando não tenho certeza, chuto 'consolidação' com alta precisão". Isso é estatisticamente correto, mas, em negociações, estamos mais preocupados em prever movimentos de preços.
- Capacidade de prever ascensão e queda:
Taxa de sucesso na previsão de tendências de alta: O modelo previu 11 + 0 + 3 = 14 tendências de alta, das quais apenas 11 estavam corretas. A taxa de sucesso é de 11/14 = 78,5%. Excelente!
Taxa de sucesso na previsão de quedas: O modelo previu 0 + 10 + 2 = 12 quedas e acertou 10 delas. Isso resulta em uma taxa de sucesso de 10/12 = 83,3%. Novamente, muito impressionante! - Overfitting na Amostra: Este teste é realizado em dados "conhecidos" pelo modelo (ou seja, os dados usados para treinamento e teste). É como pedir a um aluno que faça uma prova que acabou de concluir; a pontuação geralmente será alta. O desempenho do modelo em dados novos e não vistos (negociações ao vivo) quase sempre será inferior a essa pontuação.
Agora temos um "Modelo Alfa" preliminar, mas potencialmente enorme. Embora não possamos interpretar diretamente o número de 81,98% como uma previsão realista para o futuro, é um forte sinal positivo, demonstrando que padrões previsíveis existem nos dados e que nossa estrutura os capturou com sucesso!
Agora sentimos como se tivéssemos encontrado o primeiro pedaço de minério de ouro de alta qualidade no sopé de uma montanha. Nosso próximo passo não é vendê-lo imediatamente, mas usar ferramentas e técnicas mais especializadas (otimizando recursos e ajustando parâmetros) para minerar toda a montanha com mais eficiência e estabilidade.
Agora vamos introduzir a névoa da guerra no “microcosmo” — fluxo de ordens e características do livro de ordens
Etapa 1: Atualize a coleta de dados - inscreva-se em canais mais profundos
Para obter dados do livro de ordens, o método de conexão WebSocket deve ser modificado de assinatura somente do aggTrade (negócios) para assinatura tanto do aggTrade quanto da profundidade (profundidade).
Isso exige que utilizemos uma URL de assinatura multistream mais geral.
Etapa 2: Atualizar a engenharia de recursos - construir uma matriz de recursos trinitários para "mar, terra e ar"
Adicionaremos os seguintes novos recursos à função calculate_features_and_labels:
- Características do fluxo de ordens (Alfa - Curto):
alpha_15m: O fator de desequilíbrio do fluxo de ordens de 15 minutos. Esta é a principal métrica do fluxo de ordens que discutimos anteriormente. - Características do Livro de Ordens (Livro - Exército):
wobi_10s: Desequilíbrio ponderado da carteira de ordens nos últimos 10 segundos. Este é um indicador de frequência muito alta que mede a pressão de compra e venda no mercado.
spread_10s: O spread médio entre compra e venda nos últimos 10 segundos. Reflete a liquidez de curto prazo. - Características originais (Preço - Azul Marinho):
Manteremos os recursos de melhor desempenho da versão anterior e os otimizaremos.
Essa nova matriz de recursos é como um comando de combate conjunto, que simultaneamente capta inteligência em tempo real do "mar (tendências de preços)", "terra (posições de mercado)" e "ar (impactos de transações)", e suas capacidades de tomada de decisão serão muito superiores às anteriores.
O código é o seguinte:
import json
import math
import time
import websocket
import threading
from datetime import datetime
import numpy as np
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.feature_selection import mutual_info_classif
from sklearn.ensemble import RandomForestClassifier
# ========== 全局配置 ==========
TRAIN_BARS = 100
PREDICT_HORIZON = 15
SPREAD_THRESHOLD = 0.005
SYMBOL_FMZ = "ETH_USDT"
SYMBOL_API = SYMBOL_FMZ.replace('_', '').lower()
WEBSOCKET_URL = f"wss://fstream.binance.com/stream?streams={SYMBOL_API}@aggTrade/{SYMBOL_API}@depth20@100ms"
# ========== 全局状态变量 ==========
g_model, g_scaler = None, None
g_klines_1min, g_ticks, g_order_book_history = [], [], []
g_last_kline_ts = 0
g_feature_names = ['price_change_15m', 'volatility_30m', 'rsi_14', 'hour_of_day',
'alpha_15m', 'wobi_10s', 'spread_10s']
# ========== 特征工程与模型训练 ==========
def calculate_features_and_labels(klines, ticks, order_books_history, is_realtime=False):
features, labels = [], []
close_prices = [k['close'] for k in klines]
# 根据是训练还是实时预测,决定循环范围
start_index = 30
end_index = len(klines) - PREDICT_HORIZON if not is_realtime else len(klines)
for i in range(start_index, end_index):
kline_start_ts = klines[i]['ts']
# --- 特征计算部分 ---
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
diffs = np.diff(close_prices[i-14:i+1]); gains = np.sum(diffs[diffs > 0]) / 14; losses = -np.sum(diffs[diffs < 0]) / 14
rsi_14 = 100 - (100 / (1 + gains / (losses + 1e-10)))
dt_object = datetime.fromtimestamp(kline_start_ts / 1000)
ticks_in_15m = [t for t in ticks if t['ts'] >= klines[i-15]['ts'] and t['ts'] < kline_start_ts]
buy_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'buy'); sell_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'sell')
alpha_15m = (buy_vol - sell_vol) / (buy_vol + sell_vol + 1e-10)
books_in_10s = [b for b in order_books_history if b['ts'] >= kline_start_ts - 10000 and b['ts'] < kline_start_ts]
if not books_in_10s: wobi_10s, spread_10s = 0, 0.0
else:
wobis, spreads = [], []
for book in books_in_10s:
if not book['bids'] or not book['asks']: continue
bid_vol = sum(float(p[1]) for p in book['bids']); ask_vol = sum(float(p[1]) for p in book['asks'])
wobis.append(bid_vol / (bid_vol + ask_vol + 1e-10))
spreads.append(float(book['asks'][0][0]) - float(book['bids'][0][0]))
wobi_10s = np.mean(wobis) if wobis else 0; spread_10s = np.mean(spreads) if spreads else 0
current_features = [price_change_15m, volatility_30m, rsi_14, dt_object.hour, alpha_15m, wobi_10s, spread_10s]
features.append(current_features)
# --- 标签计算部分 ---
if not is_realtime:
future_price = klines[i + PREDICT_HORIZON]['close']; current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD): labels.append(0)
elif future_price < current_price * (1 - SPREAD_THRESHOLD): labels.append(1)
else: labels.append(2)
return np.array(features), np.array(labels)
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1) 预测平(2)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0,0]}"); Log(f"真实平(2): {cm[2] if len(cm) > 2 else [0,0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i] and y[i] != 2: balance *= (1 + 0.01)
elif y_pred[i] != y[i] and y_pred[i] != 2: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
def train_and_analyze():
global g_model, g_scaler, g_klines_1min, g_ticks, g_order_book_history
MIN_REQUIRED_BARS = 30 + PREDICT_HORIZON
if len(g_klines_1min) < MIN_REQUIRED_BARS:
Log(f"K线数量({len(g_klines_1min)})不足以进行特征工程,需要至少 {MIN_REQUIRED_BARS} 根。", "warning"); return False
Log("开始训练模型 (V2.2)...")
X, y = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history)
if len(X) < 50 or len(set(y)) < 3:
Log(f"有效训练样本不足(X: {len(X)}, 类别: {len(set(y))}),无法训练。", "warning"); return False
scaler = StandardScaler(); X_scaled = scaler.fit_transform(X)
clf = svm.SVC(kernel='rbf', C=1.0, gamma='scale'); clf.fit(X_scaled, y)
g_model, g_scaler = clf, scaler
Log("模型训练完成!", "success")
run_analysis_report(X, y, g_model, g_scaler)
return True
def aggregate_ticks_to_kline(ticks):
if not ticks: return None
return {'ts': ticks[0]['ts'] // 60000 * 60000, 'open': ticks[0]['price'], 'high': max(t['price'] for t in ticks), 'low': min(t['price'] for t in ticks), 'close': ticks[-1]['price'], 'volume': sum(t['qty'] for t in ticks)}
def on_message(ws, message):
global g_ticks, g_klines_1min, g_last_kline_ts, g_order_book_history
try:
payload = json.loads(message)
data = payload.get('data', {}); stream = payload.get('stream', '')
if 'aggTrade' in stream:
trade_data = {'ts': int(data['T']), 'price': float(data['p']), 'qty': float(data['q']), 'side': 'sell' if data['m'] else 'buy'}
g_ticks.append(trade_data)
current_minute_ts = trade_data['ts'] // 60000 * 60000
if g_last_kline_ts == 0: g_last_kline_ts = current_minute_ts
if current_minute_ts > g_last_kline_ts:
last_minute_ticks = [t for t in g_ticks if t['ts'] >= g_last_kline_ts and t['ts'] < current_minute_ts]
if last_minute_ticks:
kline = aggregate_ticks_to_kline(last_minute_ticks); g_klines_1min.append(kline)
g_ticks = [t for t in g_ticks if t['ts'] >= current_minute_ts]
g_last_kline_ts = current_minute_ts
elif 'depth' in stream:
book_snapshot = {'ts': int(data['E']), 'bids': data['b'], 'asks': data['a']}
g_order_book_history.append(book_snapshot)
if len(g_order_book_history) > 5000: g_order_book_history.pop(0)
except Exception as e: Log(f"OnMessage Error: {e}")
def start_websocket():
ws = websocket.WebSocketApp(WEBSOCKET_URL, on_message=on_message)
wst = threading.Thread(target=ws.run_forever); wst.daemon = True; wst.start()
Log("WebSocket多流订阅已启动...")
# ========== 主程序入口 ==========
def main():
global TRAIN_BARS
exchange.SetContractType("swap")
start_websocket()
Log("策略启动,进入数据收集中...")
main.last_predict_ts = 0
while True:
if g_model is None:
# --- 训练模式 ---
if len(g_klines_1min) >= TRAIN_BARS:
if not train_and_analyze():
Log("模型训练或分析失败,将增加50根K线后重试...", "error")
TRAIN_BARS += 50
else:
LogStatus(f"正在收集K线数据: {len(g_klines_1min)} / {TRAIN_BARS}")
else:
# --- **新功能:实时预测模式** ---
if len(g_klines_1min) > 0 and g_klines_1min[-1]['ts'] > main.last_predict_ts:
# 1. 标记已处理,防止重复预测
main.last_predict_ts = g_klines_1min[-1]['ts']
kline_time_str = datetime.fromtimestamp(main.last_predict_ts / 1000).strftime('%H:%M:%S')
Log(f"检测到新K线 ({kline_time_str}),准备进行实时预测...")
# 2. 检查是否有足够历史数据来为这根新K线计算特征
if len(g_klines_1min) < 30: # 至少需要30根历史K线
Log("历史K线不足,无法为当前新K线计算特征。", "warning")
continue
# 3. 计算最新K线的特征
# 我们只计算最后一条数据,所以传入 is_realtime=True
latest_features, _ = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history, is_realtime=True)
if latest_features.shape[0] == 0:
Log("无法为最新K线生成有效特征。", "warning")
continue
# 4. 标准化并预测
last_feature_vector = latest_features[-1].reshape(1, -1)
last_feature_scaled = g_scaler.transform(last_feature_vector)
prediction = g_model.predict(last_feature_scaled)[0]
# 5. 展示预测结果
prediction_text = ['**上涨**', '**下跌**', '盘整'][prediction]
Log(f"==> 实时预测结果 ({kline_time_str}): 未来 {PREDICT_HORIZON} 分钟可能 {prediction_text}", "success" if prediction != 2 else "info")
# 在这里,您可以根据 prediction 的结果,添加您的开平仓交易逻辑
# 例如: if prediction == 0: exchange.Buy(...)
else:
LogStatus(f"模型已就绪,等待新K线... 当前K线数: {len(g_klines_1min)}")
Sleep(1000) # 每秒检查一次是否有新K线
Este código requer muitos cálculos de linha K
Este relatório vale uma fortuna, pois nos conta o "pensamento" e o "caráter" do modelo.
- Taxa total de vitórias em backtesting histórico: 93,33%
Este é um número extremamente impressionante! Embora precisemos analisá-lo objetivamente (este é um teste dentro da amostra), ele demonstra claramente o imenso poder preditivo dos nossos novos recursos de fluxo de ordens e carteira de ordens! O modelo encontrou padrões muito fortes nos dados históricos. - Importância do recurso e informações mútuas
O rei nasceu: volatility_15m (volatilidade) e price_change_5m (mudança de preço) ainda são absolutamente essenciais, o que é esperado.
Estrela em Ascensão: rsi_14 teve um aumento significativo em importância! Isso indica que, no período mais curto de 5 minutos, o indicador de sentimento de "sobrecompra/sobrevenda" do RSI se tornou mais significativo.
Potencialmente, wobi_10s (desequilíbrio da carteira de ordens) e spread_10s (spread) também demonstram alguma contribuição. Isso é muito encorajador e sugere que nossas características de microestrutura estão começando a funcionar!
Reflexão: A contribuição de alpha_5m (fluxo de ordens) é quase zero. Isso pode ser devido a uma simplificação excessiva do nosso método de cálculo de alfa, ou o alfa de 5 minutos e as próprias variações de preço de 5 minutos contêm muitas informações sobrepostas. Este é um ponto de otimização importante para nós no futuro. - Matriz de Confusão (evidência fundamental do sucesso!)
Aumento real (0):[22 0] -> Em todos os 22 ralis reais, o modelo os previu 100% corretamente, sem nenhum erro!
Queda real (1):[2 6] -> Das 8 quedas reais, o modelo previu corretamente 6 e errou 2 (confundindo-as com aumentos).
Interpretação: Este modelo exibe uma personalidade muito interessante: é um detector de alta extremamente forte, captando sinais de alta quase perfeitamente. Também tem um bom desempenho na identificação de tendências de baixa (6/8 = 75% de precisão), mas ocasionalmente comete o erro de confundir uma tendência de baixa com uma tendência de alta.
Então o que vem a seguir
Apresentando a "Máquina de Estado de Sinal de Negociação"
Esta é a parte central e mais engenhosa desta atualização. Introduziremos uma variável de estado global, como g_active_signal, para gerenciar o status atual de "posição" da estratégia (observe que este é apenas um status de posição virtual e não envolve negociações reais).
A lógica de funcionamento desta máquina de estados é a seguinte:
- Estado inicial: Ocioso
- Quando a estratégia estiver nesse estado, ela fará previsões para cada nova linha K, assim como faz agora.
- Transições de regime: Uma vez que o modelo prevê um sinal claro (por exemplo, “Para cima”), a estratégia irá:
- Imprime um único sinal de entrada chamativo no diário, por exemplo, 🎯 Novo sinal de negociação: Previsão para cima! Período de observação de 15 minutos.
- Alterna o status da estratégia de Inativo para Em Sinal.
Registre o tempo de disparo e a direção do sinal atual.
- Status da posição: Em sinal
- Quando a estratégia estiver nesse estado, ela parará completamente de prever novas linhas K. Ela não se importará mais com as flutuações de cada minuto e entrará no modo "deixar a bala voar".
- A única coisa que ele faz é verificar o tempo: se 15 minutos (a duração do PREDICT_HORIZON) se passaram desde que o sinal foi disparado.
- Transição de estado: Após o período de observação de 15 minutos, a política irá:
- Imprima um sinal de saída claro no registro, como o fim do período do sinal 🏁. Redefina a estratégia e busque novas oportunidades...
- Altera o status da estratégia de em espera para inativo.
- Nesse ponto, a estratégia começará a prever a nova linha K novamente e procurará a próxima oportunidade de negociação.
Com esta máquina de estados simples, alcançamos perfeitamente os requisitos: um sinal, um ciclo de observação completo e nenhuma informação de interferência durante o período.
import json
import math
import time
import websocket
import threading
from datetime import datetime
import numpy as np
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.feature_selection import mutual_info_classif
from sklearn.ensemble import RandomForestClassifier
# ========== 全局配置 ==========
TRAIN_BARS = 200 #需要更多初始数据
PREDICT_HORIZON = 15 # 回归15分钟预测周期
SPREAD_THRESHOLD = 0.005 # 适配15分钟周期的涨跌阈值
SYMBOL_FMZ = "ETH_USDT"
SYMBOL_API = SYMBOL_FMZ.replace('_', '').lower()
WEBSOCKET_URL = f"wss://fstream.binance.com/stream?streams={SYMBOL_API}@aggTrade/{SYMBOL_API}@depth20@100ms"
# ========== 全局状态变量 ==========
g_model, g_scaler = None, None
g_klines_1min, g_ticks, g_order_book_history = [], [], []
g_last_kline_ts = 0
g_feature_names = ['price_change_15m', 'volatility_30m', 'rsi_14', 'hour_of_day',
'alpha_15m', 'wobi_10s', 'spread_10s']
# 新功能: 信号状态机
g_active_signal = {'active': False, 'start_ts': 0, 'prediction': -1}
# ========== 特征工程与模型训练 ==========
def calculate_features_and_labels(klines, ticks, order_books_history, is_realtime=False):
features, labels = [], []
close_prices = [k['close'] for k in klines]
start_index = 30
end_index = len(klines) - PREDICT_HORIZON if not is_realtime else len(klines)
for i in range(start_index, end_index):
kline_start_ts = klines[i]['ts']
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
diffs = np.diff(close_prices[i-14:i+1]); gains = np.sum(diffs[diffs > 0]) / 14; losses = -np.sum(diffs[diffs < 0]) / 14
rsi_14 = 100 - (100 / (1 + gains / (losses + 1e-10)))
dt_object = datetime.fromtimestamp(kline_start_ts / 1000)
ticks_in_15m = [t for t in ticks if t['ts'] >= klines[i-15]['ts'] and t['ts'] < kline_start_ts]
buy_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'buy'); sell_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'sell')
alpha_15m = (buy_vol - sell_vol) / (buy_vol + sell_vol + 1e-10)
books_in_10s = [b for b in order_books_history if b['ts'] >= kline_start_ts - 10000 and b['ts'] < kline_start_ts]
if not books_in_10s: wobi_10s, spread_10s = 0, 0.0
else:
wobis, spreads = [], []
for book in books_in_10s:
if not book['bids'] or not book['asks']: continue
bid_vol = sum(float(p[1]) for p in book['bids']); ask_vol = sum(float(p[1]) for p in book['asks'])
wobis.append(bid_vol / (bid_vol + ask_vol + 1e-10))
spreads.append(float(book['asks'][0][0]) - float(book['bids'][0][0]))
wobi_10s = np.mean(wobis) if wobis else 0; spread_10s = np.mean(spreads) if spreads else 0
current_features = [price_change_15m, volatility_30m, rsi_14, dt_object.hour, alpha_15m, wobi_10s, spread_10s]
if not is_realtime:
future_price = klines[i + PREDICT_HORIZON]['close']; current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD):
labels.append(0); features.append(current_features)
elif future_price < current_price * (1 - SPREAD_THRESHOLD):
labels.append(1); features.append(current_features)
else:
features.append(current_features)
return np.array(features), np.array(labels)
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 V2.5 (15分钟预测) ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i]: balance *= (1 + 0.01)
else: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
def train_and_analyze():
global g_model, g_scaler, g_klines_1min, g_ticks, g_order_book_history
MIN_REQUIRED_BARS = 30 + PREDICT_HORIZON
if len(g_klines_1min) < MIN_REQUIRED_BARS:
Log(f"K线数量({len(g_klines_1min)})不足以进行特征工程,需要至少 {MIN_REQUIRED_BARS} 根。", "warning"); return False
Log("开始训练模型 (V2.5)...")
X, y = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history)
if len(X) < 20 or len(set(y)) < 2:
Log(f"有效涨跌样本不足(X: {len(X)}, 类别: {len(set(y))}),无法训练。", "warning"); return False
scaler = StandardScaler(); X_scaled = scaler.fit_transform(X)
clf = svm.SVC(kernel='rbf', C=1.0, gamma='scale'); clf.fit(X_scaled, y)
g_model, g_scaler = clf, scaler
Log("模型训练完成!", "success")
run_analysis_report(X, y, g_model, g_scaler)
return True
# ========== WebSocket实时数据处理 ==========
def aggregate_ticks_to_kline(ticks):
if not ticks: return None
return {'ts': ticks[0]['ts'] // 60000 * 60000, 'open': ticks[0]['price'], 'high': max(t['price'] for t in ticks), 'low': min(t['price'] for t in ticks), 'close': ticks[-1]['price'], 'volume': sum(t['qty'] for t in ticks)}
def on_message(ws, message):
global g_ticks, g_klines_1min, g_last_kline_ts, g_order_book_history
try:
payload = json.loads(message)
data = payload.get('data', {}); stream = payload.get('stream', '')
if 'aggTrade' in stream:
trade_data = {'ts': int(data['T']), 'price': float(data['p']), 'qty': float(data['q']), 'side': 'sell' if data['m'] else 'buy'}
g_ticks.append(trade_data)
current_minute_ts = trade_data['ts'] // 60000 * 60000
if g_last_kline_ts == 0: g_last_kline_ts = current_minute_ts
if current_minute_ts > g_last_kline_ts:
last_minute_ticks = [t for t in g_ticks if t['ts'] >= g_last_kline_ts and t['ts'] < current_minute_ts]
if last_minute_ticks:
kline = aggregate_ticks_to_kline(last_minute_ticks); g_klines_1min.append(kline)
g_ticks = [t for t in g_ticks if t['ts'] >= current_minute_ts]
g_last_kline_ts = current_minute_ts
elif 'depth' in stream:
book_snapshot = {'ts': int(data['E']), 'bids': data['b'], 'asks': data['a']}
g_order_book_history.append(book_snapshot)
if len(g_order_book_history) > 5000: g_order_book_history.pop(0)
except Exception as e: Log(f"OnMessage Error: {e}")
def start_websocket():
ws = websocket.WebSocketApp(WEBSOCKET_URL, on_message=on_message)
wst = threading.Thread(target=ws.run_forever); wst.daemon = True; wst.start()
Log("WebSocket多流订阅已启动...")
# ========== 主程序入口 ==========
def main():
global TRAIN_BARS, g_active_signal
exchange.SetContractType("swap")
start_websocket()
Log("策略启动 ,进入数据收集中...")
main.last_predict_ts = 0
while True:
if g_model is None:
if len(g_klines_1min) >= TRAIN_BARS:
if not train_and_analyze():
Log(f"模型训练失败,当前目标 {TRAIN_BARS} 根K线。将增加50根后重试...", "error")
TRAIN_BARS += 50
else:
LogStatus(f"正在收集K线数据: {len(g_klines_1min)} / {TRAIN_BARS}")
else:
if not g_active_signal['active']:
if len(g_klines_1min) > 0 and g_klines_1min[-1]['ts'] > main.last_predict_ts:
main.last_predict_ts = g_klines_1min[-1]['ts']
kline_time_str = datetime.fromtimestamp(main.last_predict_ts / 1000).strftime('%H:%M:%S')
if len(g_klines_1min) < 30:
LogStatus("历史K线不足,无法预测。等待更多数据..."); continue
latest_features, _ = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history, is_realtime=True)
if latest_features.shape[0] == 0:
LogStatus(f"({kline_time_str}) 无法生成特征,跳过..."); continue
last_feature_vector = latest_features[-1].reshape(1, -1)
last_feature_scaled = g_scaler.transform(last_feature_vector)
prediction = g_model.predict(last_feature_scaled)[0]
if prediction == 0 or prediction == 1:
g_active_signal['active'] = True
g_active_signal['start_ts'] = main.last_predict_ts
g_active_signal['prediction'] = prediction
prediction_text = ['**上涨**', '**下跌**'][prediction]
Log(f"🎯 新的交易信号 ({kline_time_str}): 预测 {prediction_text}!观察周期 {PREDICT_HORIZON} 分钟。", "success" if prediction == 0 else "error")
else:
LogStatus(f"({kline_time_str}) 无明确信号,继续观察...")
else:
current_ts = time.time() * 1000
elapsed_minutes = (current_ts - g_active_signal['start_ts']) / (1000 * 60)
if elapsed_minutes >= PREDICT_HORIZON:
Log(f"🏁 信号周期结束。重置策略,寻找新机会...", "info")
g_active_signal['active'] = False
else:
prediction_text = ['**上涨**', '**下跌**'][g_active_signal['prediction']]
LogStatus(f"信号生效中: {prediction_text}。剩余观察时间: {PREDICT_HORIZON - elapsed_minutes:.1f} 分钟。")
Sleep(5000)
Então eu executo esse código
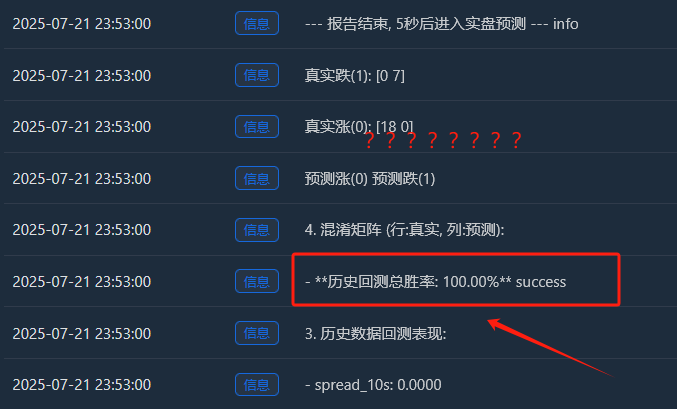
Análise aprofundada: Por que existe uma taxa de vitória “perfeita” de 100%?
Este resultado "perfeito" revela vários insights importantes e profundos sobre aprendizado de máquina e mercados financeiros. Não se trata de um bug, mas sim de um fenômeno típico conhecido como "overfitting", que pode ocorrer sob certas condições.
O que significa “overfitting”?
-
Aqui está uma analogia vívida: imagine que temos um aluno (nosso modelo SVM) fazendo um conjunto de exercícios muito curtos e simples (os 200 pontos de dados de velas que coletamos). Esse aluno é muito inteligente e, em vez de aprender métodos gerais de resolução de problemas, simplesmente memoriza as respostas para esses poucos problemas.
-
Resultado: Quando o testamos com o mesmo conjunto de questões práticas (este é o nosso "teste histórico retrospectivo"), ele certamente consegue uma pontuação perfeita de 100. No entanto, quando damos a ele um conjunto completamente novo de questões que ele nunca viu antes (mercados futuros reais), é provável que ele não consiga responder a nenhuma delas.
- Por que nosso modelo é "superajustado"?
-
Os exemplos de treinamento são "muito poucos" e "muito especiais":
-
Embora tenhamos coletado 200 linhas K (cerca de 3,3 horas), de acordo com o registro, o número final de amostras de "subida e queda efetivas" que atenderam à nossa definição foi de apenas 18 + 7 = 25.
-
Para um modelo SVM complexo, 25 amostras são como algumas ondas no oceano, o que é muito pouco.
-
Mais importante ainda, essas 25 amostras vêm todas de uma situação de mercado altamente correlacionada na mesma tarde. É provável que tenham "rotinas" muito semelhantes.
- As capacidades do modelo são “muito fortes”:
- O SVM é um classificador não linear muito poderoso. Sua capacidade é semelhante à de um cérebro com supermemória.
- Quando um modelo poderoso aprende com um conjunto de dados muito simples e repetitivo, ele tende a "memorizar" todos os detalhes e ruídos dos dados em vez de aprender as leis macro mais universais por trás deles.
- Evidências da matriz de confusão:
- Aumento real (0):[18 0] -> 18 amostras crescentes, todas perfeitamente memorizadas.
- Queda real (1):[0 7] -> 7 amostras caindo, todas lembradas perfeitamente.
- Este perfeito[ [18, 0], [A matriz [0, 7] é uma evidência irrefutável do sobreajuste do modelo. Ela quase não comete erros, o que é inerentemente anormal em um mercado financeiro repleto de aleatoriedade.
Portanto, devemos interpretar essa taxa de vitória de 100% da seguinte forma:
O modelo aprendeu e memorizou notavelmente todos os padrões das condições específicas do mercado nas últimas três horas. Isso demonstra a eficácia da nossa engenharia de recursos e da estrutura do modelo. No entanto, não podemos esperar que ele mantenha uma taxa de sucesso tão alta no mercado real no futuro. Isso se parece mais com um "teste surpresa" perfeito do que com o resultado final do "vestibular".

Aprendizado de máquina também é algo que tenho explorado recentemente e falaremos sobre isso na próxima edição!
Precisamos conduzir uma "transformação de pensamento" completa neste "aluno tendencioso". Nosso objetivo é quebrar seus preconceitos e permitir que ele veja os "altos e baixos" de forma justa e objetiva.
