
Um estudo preliminar sobre a aplicação do rastreador Python na plataforma FMZ - rastreando o conteúdo do anúncio da Binance
Recentemente, dei uma olhada na comunidade e na biblioteca e não encontrei nenhuma informação relevante sobre rastreadores Python, com base no espírito de desenvolvimento abrangente como um QUANT. Aprendi os conceitos e conhecimentos relacionados aos crawlers de forma muito simples. Depois de aprender mais sobre isso, descobri que a "tecnologia crawler" é um grande poço. Este artigo é apenas uma exploração preliminar da "tecnologia crawler". Vamos fazer a prática mais simples da tecnologia crawler na plataforma de negociação quantitativa FMZ.
precisar
Os traders que gostam de investir em novas moedas sempre esperam obter informações sobre as moedas listadas na bolsa o mais rápido possível. Obviamente não é realista ficar de olho no site de câmbio manualmente. Então você precisa usar um script rastreador para monitorar a página de anúncios da bolsa e detectar novos anúncios para que você possa ser notificado e lembrado o mais rápido possível.
Exploração inicial
Vamos usar um programa muito simples como ponto de partida (um script de crawler realmente poderoso é muito mais complicado, então não tenha pressa). A lógica do programa é muito simples, que consiste em permitir que o programa acesse continuamente a página de anúncio da bolsa, analise o conteúdo HTML obtido e detecte se o conteúdo de uma tag específica é atualizado.
Código de Implementação
Você pode usar algumas estruturas de rastreadores úteis. Entretanto, considerando que o requisito é muito simples, também é possível escrevê-lo diretamente.
Bibliotecas Python são necessárias:
requests, que pode ser entendido simplesmente como uma biblioteca usada para acessar páginas da web.
bs4, que pode ser entendido simplesmente como uma biblioteca usada para analisar o código HTML de uma página da web.
Código:
from bs4 import BeautifulSoup
import requests
urlBinanceAnnouncement = "https://www.binancezh.io/en/support/announcement/c-48?navId=48" # 币安公告页面地址
def openUrl(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
r = requests.get(url, headers=headers) # 使用requests库访问url,即币安的公告网页地址
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # 访问成功的话返回网页内容文本
else:
Log("failed {}".format(url))
def main():
preNews_href = ""
lastNews = ""
Log("watching...", urlBinanceAnnouncement, "#FF0000")
while True:
ret = openUrl(urlBinanceAnnouncement)
if ret:
soup = BeautifulSoup(ret, 'html.parser') # 把网页文本解析为对象
lastNews_href = soup.find('a', class_='css-1ej4hfo')["href"] # 查找特定的标签,获取href
lastNews = soup.find('a', class_='css-1ej4hfo').get_text() # 获取这个标签中的内容
if preNews_href == "":
preNews_href = lastNews_href
if preNews_href != lastNews_href: # 检测到标签发生变动,即有新的公告产生
Log("New Cryptocurrency Listing update!") # 打印提示信息
preNews_href = lastNews_href
LogStatus(_D(), "\n", "preNews_href:", preNews_href, "\n", "news:", lastNews)
Sleep(1000 * 10)
correr
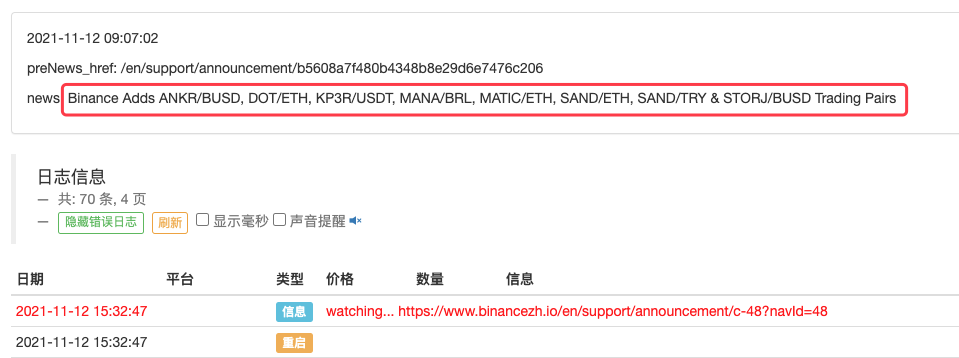
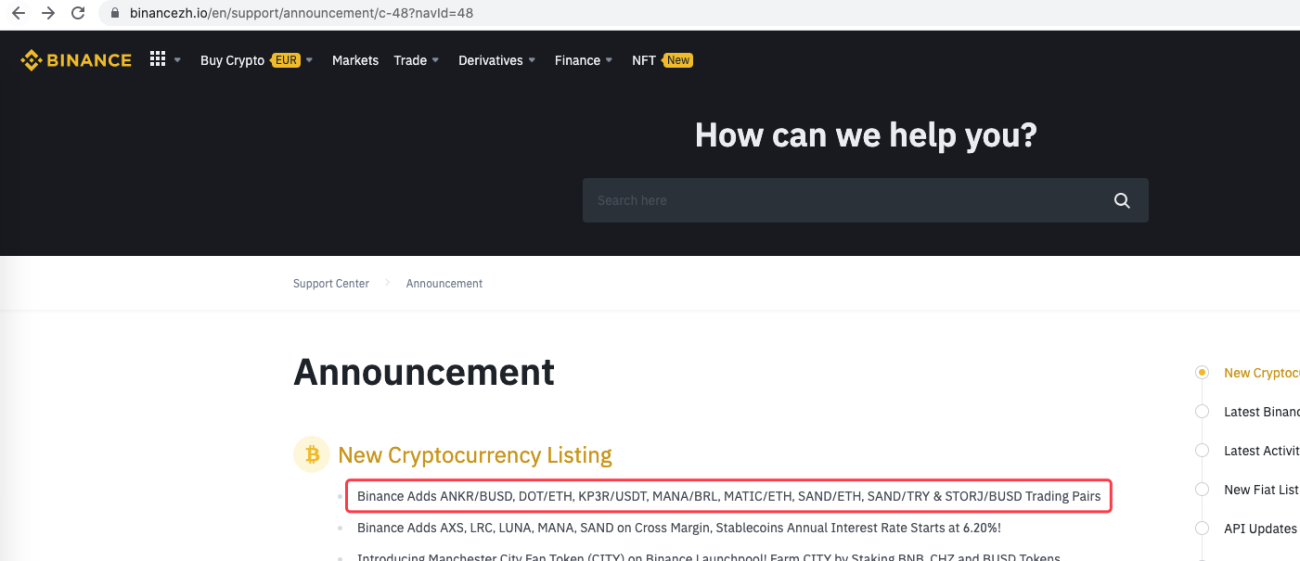
Ele pode até ser estendido para detectar quando um novo anúncio aparece, por exemplo. Analise as novas moedas listadas no anúncio e faça pedidos automaticamente para novas transações.

Traceback (most recent call last): File "<string>", line 999, in init_ctx File "<string>", line 1, in <module> ModuleNotFoundError: No module named 'bs4'
复制代码到实盘提示错误,是不是缺失python的库。怎么添加库到托管着呢。


作者你好,我也写了一个爬币安公告的爬虫,不管是用那个api接口还是主页的爬虫都有30s延迟,不知道你有没有解决这个问题,可以交流下吗,我的vx ShawnQiang1125


- 1