

Предисловие
Система бэктестинга платформы количественной торговли Inventor — это система бэктестинга, которая постоянно итерируется, обновляется и модернизируется. От начальных базовых функций бэктестинга она постепенно добавляет функции и оптимизирует производительность. По мере развития платформы система бэктестинга будет продолжать оптимизироваться и совершенствоваться. Сегодня мы обсудим тему, основанную на системе бэктестинга: «Тестирование стратегии на основе случайных рыночных условий».
нуждаться
В сфере количественной торговли разработка и оптимизация стратегий неотделимы от проверки реальных рыночных данных. Однако в реальных приложениях из-за сложной и изменчивой рыночной среды использование исторических данных для бэктестинга может иметь недостатки, такие как отсутствие охвата экстремальных рыночных условий или особых сценариев. Таким образом, разработка эффективного генератора случайных рыночных данных становится действенным инструментом для разработчиков количественных стратегий.
Когда нам необходимо провести бэктест стратегии на определенной бирже или валюте с использованием исторических данных, мы можем использовать официальный источник данных платформы FMZ для бэктестинга. Иногда мы также хотим увидеть, как стратегия работает на совершенно «незнакомом» рынке. В это время мы можем «сфабриковать» некоторые данные для тестирования стратегии.
Значимость использования случайных рыночных данных заключается в следующем:
-
- Оценка надежности стратегии
Генератор случайных рынков может создавать множество возможных рыночных сценариев, включая экстремальную волатильность, низкую волатильность, трендовые рынки и нестабильные рынки. Тестирование стратегии в таких моделируемых условиях может помочь оценить, является ли ее эффективность стабильной в различных рыночных условиях. Например:
Может ли стратегия адаптироваться к смене тенденций и шоков?
Приведет ли стратегия к существенным потерям в экстремальных рыночных условиях? - Оценка надежности стратегии
-
- Определите потенциальные слабые стороны вашей стратегии
Моделируя некоторые аномальные рыночные ситуации (например, гипотетические события «черного лебедя»), можно обнаружить и устранить потенциальные слабые места в стратегии. Например:
Не слишком ли сильно стратегия опирается на конкретную структуру рынка?
Существует ли риск переобучения параметров? - Определите потенциальные слабые стороны вашей стратегии
-
- Оптимизация параметров стратегии
Случайно сгенерированные данные обеспечивают более разнообразную среду тестирования для настройки параметров стратегии без необходимости полностью полагаться на исторические данные. Это позволяет использовать более полный диапазон параметров стратегии и избежать ограничений, связанных с конкретными рыночными моделями в исторических данных.
- Оптимизация параметров стратегии
-
- Заполнение пробелов в исторических данных
На некоторых рынках (например, на развивающихся рынках или рынках, торгующих небольшими валютами) исторических данных может быть недостаточно для охвата всех возможных рыночных условий. Рандомизатор может предоставить большой объем дополнительных данных для проведения более комплексного тестирования.
- Заполнение пробелов в исторических данных
-
- Быстрая итеративная разработка
Использование случайных данных для быстрого тестирования может ускорить итерацию разработки стратегии, не полагаясь на рыночные условия в реальном времени или на трудоемкую очистку и организацию данных.
- Быстрая итеративная разработка
Однако необходимо также рационально оценить стратегию. Для случайно сгенерированных рыночных данных, пожалуйста, обратите внимание:
-
- Хотя случайные рыночные генераторы полезны, их значимость зависит от качества генерируемых данных и дизайна целевого сценария:
-
- Логика генерации должна быть близка к реальному рынку: если случайно сгенерированные рыночные условия полностью оторваны от реальности, результаты тестирования могут не иметь контрольной ценности. Например, генератор может быть разработан в сочетании с реальными статистическими характеристиками рынка (такими как распределение волатильности, коэффициент тренда).
-
- Он не может полностью заменить тестирование реальных данных: случайные данные могут только дополнять разработку и оптимизацию стратегий. Окончательная стратегия все еще должна быть проверена на эффективность в реальных рыночных данных.
Учитывая все вышесказанное, как мы можем «сфабриковать» некоторые данные? Как можно удобно, быстро и легко «сфабриковать» данные для использования в системе бэктестинга?
Идеи дизайна
Эта статья призвана стать отправной точкой для обсуждения и дает относительно простой расчет случайной генерации рынка. Фактически, существует множество алгоритмов моделирования, моделей данных и других технологий, которые можно применить. Из-за ограниченного пространства обсуждения , мы не будем использовать особо сложные методы моделирования данных.
Объединив функцию пользовательского источника данных системы бэктестинга платформы, мы написали программу на Python.
-
- Случайным образом сгенерируйте набор данных K-линии и запишите их в CSV-файл для постоянной записи, чтобы можно было сохранить сгенерированные данные.
-
- Затем создайте службу, которая будет предоставлять поддержку источника данных для системы бэктестинга.
-
- Отобразите сгенерированные данные K-линии на графике.
Для некоторых стандартов генерации и хранения файлов данных K-line могут быть определены следующие элементы управления параметрами:
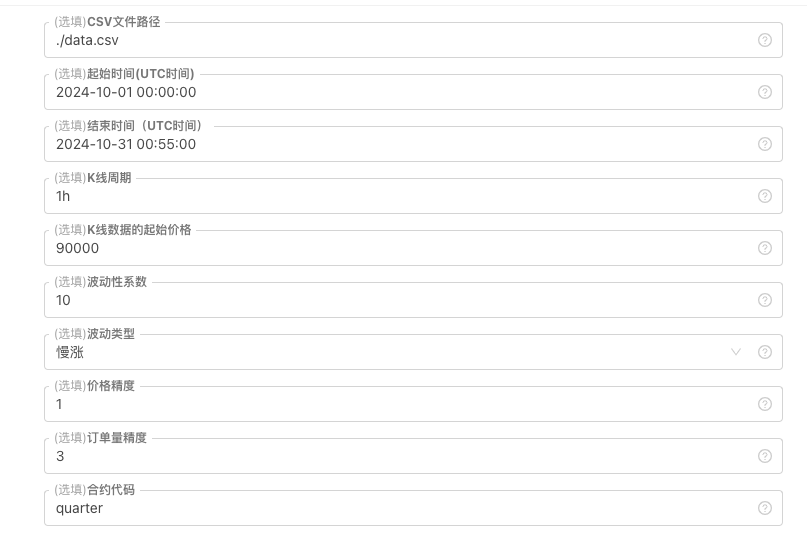
-
Случайно сгенерированный шаблон данных
Для моделирования типа флуктуации данных K-line выполняется простая конструкция с использованием различных вероятностей положительных и отрицательных случайных чисел. Когда сгенерированные данные невелики, требуемая рыночная модель может не отражаться. Если есть лучший способ, вы можете заменить эту часть кода.
На основе этой простой конструкции корректировка диапазона генерации случайных чисел и некоторых коэффициентов в коде может повлиять на эффект генерируемых данных. -
Проверка данных
Сгенерированные данные K-линии также необходимо проверить на рациональность, чтобы проверить, не нарушают ли определение высокие цены открытия и низкие цены закрытия, проверить непрерывность данных K-линии и т. д.
Система бэктестинга Генератор случайных котировок
python
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据data.detail:", data["detail"], "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("不支持的K线周期,请使用 'm', 'h', 或 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("异常数据:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("当前路径:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("文件写入成功,以下是文件内容的一部分:")
Log("".join(lines[:5]))
else:
Log("文件写入失败,文件为空!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("开启自定义数据源服务线程,数据由CSV文件提供。", ", 地址/端口:0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("生成器参数:", "起始时间:", startTime, "结束时间:", endTime, "K线周期:", KLinePeriod, "初始价格:", firstPrice, "波动类型:", arrTrendType[trendType], "波动性系数:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
Практика в системе бэктестинга
- Создайте указанный выше экземпляр политики, настройте параметры и запустите его.
- Реальный рынок (экземпляр стратегии) должен быть запущен на хосте, развернутом на сервере, поскольку для доступа к нему и получения данных системе бэктестинга требуется публичный IP-адрес.
- Нажмите интерактивную кнопку, и стратегия автоматически начнет генерировать случайные рыночные данные.

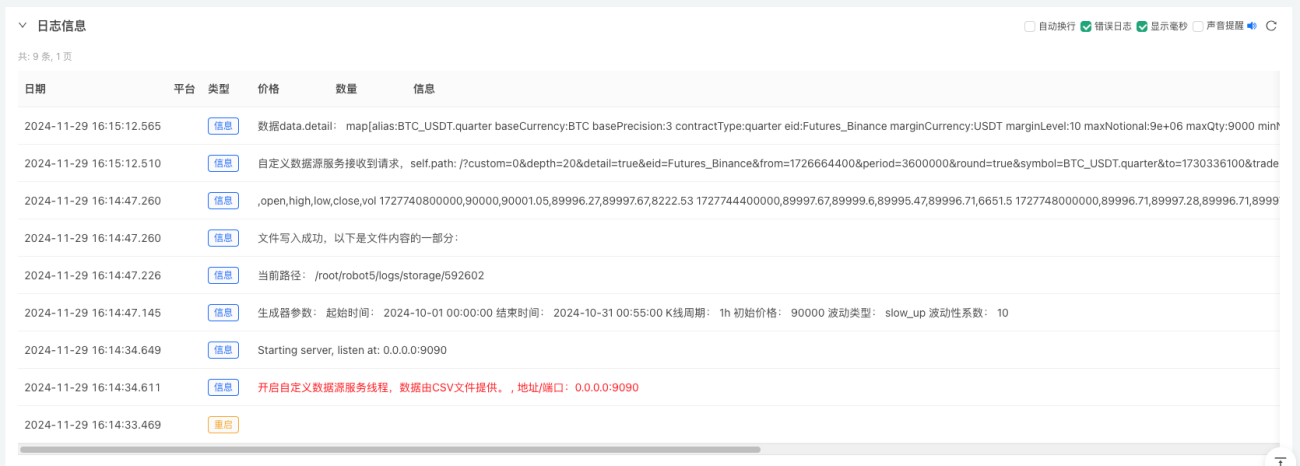
- Сгенерированные данные будут отображены на графике для удобства наблюдения, а также будут записаны в локальный файл data.csv.
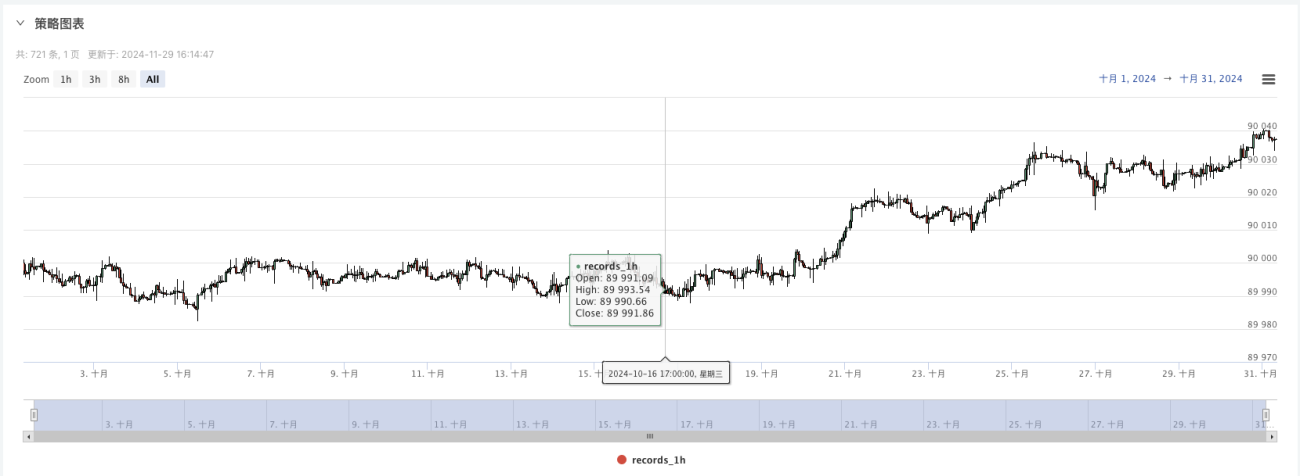
- Теперь мы можем использовать эти случайно сгенерированные данные и использовать любую стратегию для бэктестинга.
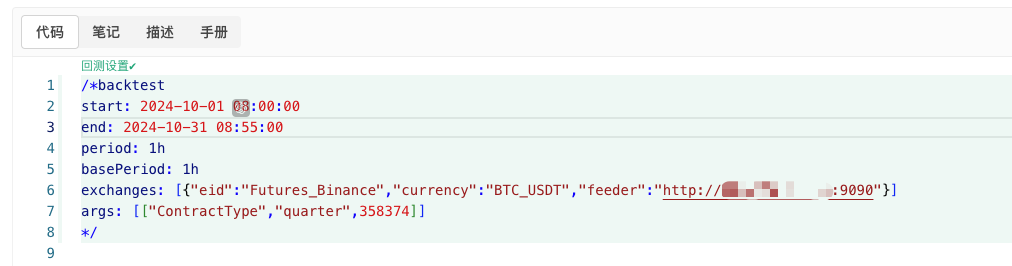
/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
Выполните настройку в соответствии с приведенной выше информацией и внесите необходимые изменения.http://xxx.xxx.xxx.xxx:9090Это IP-адрес сервера и открытый порт реального диска стратегии случайной генерации рынка.
Это пользовательский источник данных. Вы можете обратиться к разделу пользовательских источников данных в документации API платформы для получения дополнительной информации.
- После того, как система бэктестинга настроит источник данных, вы можете протестировать случайные рыночные данные.
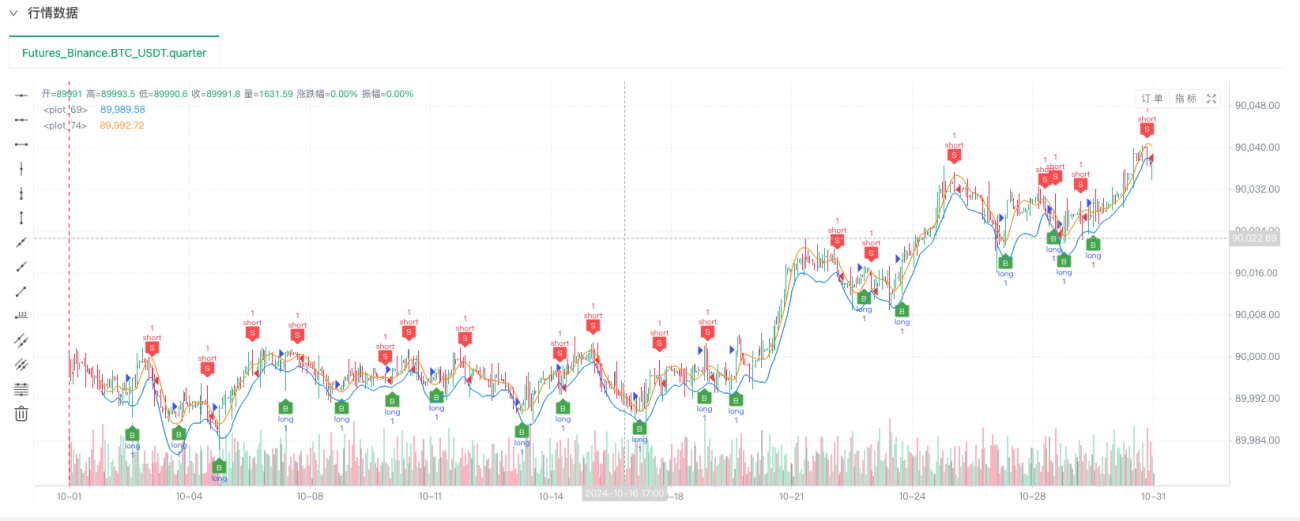
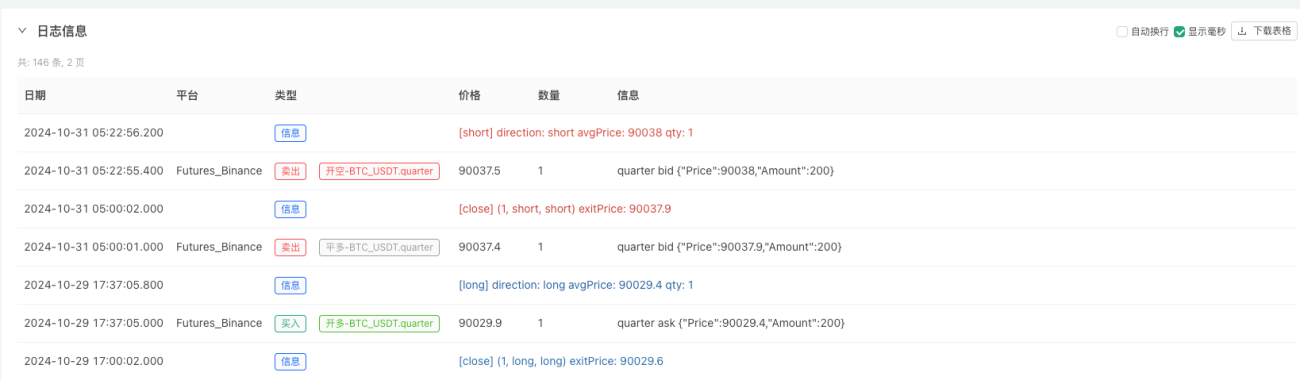
На этом этапе система бэктестинга тестируется с использованием наших «сфабрикованных» смоделированных данных. Согласно данным на графике рынка во время бэктеста, сравните данные на графике в реальном времени, сгенерированном случайными рыночными условиями. Время 17:00 16 октября 2024 года. Данные те же самые.
- Ах да, чуть не забыл сказать! Причина, по которой эта программа Python-генератора случайных рыночных данных создает реальный рынок, заключается в том, чтобы облегчить демонстрацию, эксплуатацию и отображение сгенерированных данных K-line. В реальном приложении вы можете написать независимый скрипт Python, поэтому вам не придется запускать реальный диск.
Исходный код стратегии:Система бэктестинга Генератор случайных котировок
Спасибо за вашу поддержку и чтение.
- 1