

Зрелый классификатор: Метод опорных векторов (SVM) — мощный и зрелый алгоритм бинарной (или многомерной) классификации. Прогнозирование роста или падения акций — типичная задача бинарной классификации.
Нелинейные возможности: используя функции ядра (например, ядро RBF), SVM может улавливать сложные нелинейные взаимосвязи между входными характеристиками, что имеет решающее значение для данных финансового рынка.
Ориентированная на признаки: эффективность модели во многом зависит от «признаков», которые вы ей предоставляете. Рассчитанный сейчас альфа-фактор — хорошее начало, и мы можем добавить больше таких признаков для повышения предсказательной силы.
На этот раз я начал с трех основных положений:
1: Характеристики потока высокочастотного порядка:
alpha_1min: Фактор дисбаланса потока ордеров, рассчитанный на основе всех тиков за последнюю минуту.
alpha_5min: Фактор дисбаланса потока ордеров, рассчитанный на основе всех тиков за последние 5 минут.
alpha_15min: Фактор дисбаланса потока ордеров, рассчитанный на основе всех тиков за последние 15 минут.
ofi_1min (дисбаланс потока ордеров): соотношение (объема покупки/объема продажи) за 1 минуту. Этот показатель более прямой, чем альфа.
vol_per_trade_1min: Средний объём одной сделки в течение 1 минуты. Признак влияния крупных ордеров на рынок.
2: Характеристики цены и волатильности:
log_return_5min: логарифмическая скорость возврата за последние 5 минут, log(P_t / P_{t-5min}).
volatility_15min: стандартное отклонение логарифмической доходности за последние 15 минут, мера краткосрочной волатильности.
atr_14 (средний истинный диапазон): значение ATR, основанное на последних 14 1-минутных свечах, классический индикатор волатильности.
rsi_14 (индекс относительной силы): это показатель состояний перекупленности и перепроданности, основанный на значениях RSI последних 14 1-минутных свечей.
3: Временные характеристики:
hour_of_day: Текущий час (0–23). Рынки ведут себя по-разному в разные временные периоды (например, в азиатскую, европейскую и американскую сессии).
day_of_week: День недели (0–6). Выходные и будни имеют разные закономерности колебаний.
def calculate_features_and_labels(klines):
"""
核心函数
"""
features = []
labels = []
# 为了计算RSI等指标,我们需要价格序列
close_prices = [k['close'] for k in klines]
# 从第30根K线开始,因为需要足够的前置数据
for i in range(30, len(klines) - PREDICT_HORIZON):
# 1. 价格与波动率特征
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
# 计算RSI
diffs = np.diff(close_prices[i-14:i+1])
gains = np.sum(diffs[diffs > 0]) / 14
losses = -np.sum(diffs[diffs < 0]) / 14
rs = gains / (losses + 1e-10)
rsi_14 = 100 - (100 / (1 + rs))
# 2. 时间特征
dt_object = datetime.fromtimestamp(klines[i]['ts'] / 1000)
hour_of_day = dt_object.hour
day_of_week = dt_object.weekday()
# 组合所有特征
current_features = [price_change_15m, volatility_30m, rsi_14, hour_of_day, day_of_week]
features.append(current_features)
# 3. 数据标注
future_price = klines[i + PREDICT_HORIZON]['close']
current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD):
labels.append(0) # 涨
elif future_price < current_price * (1 - SPREAD_THRESHOLD):
labels.append(1) # 跌
else:
labels.append(2) # 横盘
Затем используйте три категории, чтобы различать рост, падение и движение вбок.
Основная идея отбора функций: найти «хороших товарищей по команде» и исключить «плохих товарищей по команде».
Наша цель — найти набор признаков, которые:
- Высокая релевантность: каждая функция имеет сильную корреляцию с будущими изменениями цен (наша целевая метка).
- Низкая избыточность: признаки не должны содержать слишком много дублирующейся информации. Например, «5-минутный импульс» и «6-минутный импульс» очень похожи. Включение обоих не значительно улучшит модель и может даже внести шум.
- Стабильность: актуальность функции не может меняться слишком быстро со временем. Функция, актуальная только один день, опасна.
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1) 预测平(2)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0,0]}"); Log(f"真实平(2): {cm[2] if len(cm) > 2 else [0,0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i] and y[i] != 2: balance *= (1 + 0.01)
elif y_pred[i] != y[i] and y_pred[i] != 2: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
Процесс таков:
Сбор данных
Важность функции

Взаимная информация между функциями и метками, а также информация бэктестинга
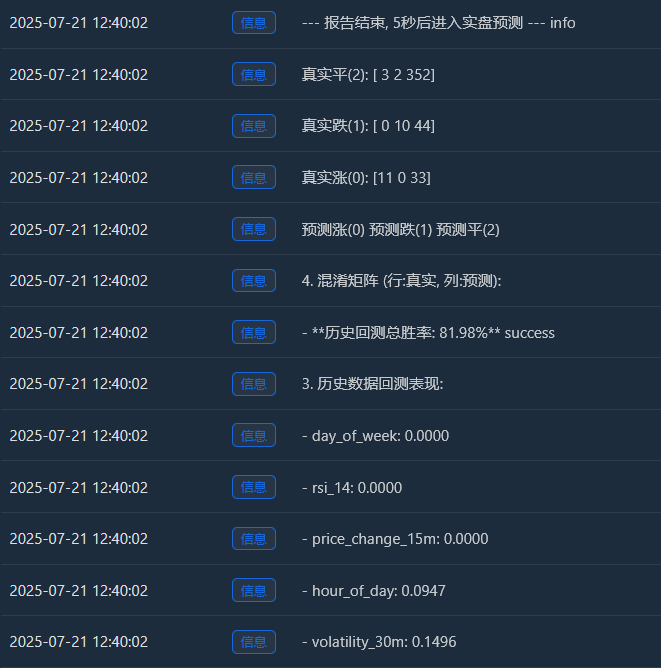
Сначала я думал, что 65% винрейта будет достаточно, но не ожидал, что он достигнет 81,98%. Моя первая реакция должна быть: «Это здорово, но слишком хорошо, чтобы быть правдой. Должно быть, здесь есть что-то, что стоит изучить».
1. Углубленная интерпретация аналитического отчета, последовательное толкование содержания отчета:
- Важность функций и взаимная информация:
Наиболее важными характеристиками являются Volatility_30m и price_change_15m. Это логично, поскольку указывает на то, что недавняя рыночная тенденция и волатильность являются самыми надежными предикторами будущего.
Небольшой вклад вносит и параметр hour_of_day, который указывает на то, что модель фиксирует торговые модели в разное время суток.
Вклад rsi_14 и day_of_week практически равен нулю, что говорит о том, что эти два признака могут быть «партнёрами по команде» в рамках текущего набора данных и комбинации признаков. В будущем мы можем рассмотреть возможность их удаления для упрощения модели и предотвращения шума. - Матрица путаницы (это очень много информации!)
Реальный прирост (0):[11 0 33] -> Из 44 (11+0+33) реальных ралли модель правильно предсказала 11, но неверно предсказала их как «консолидацию» 33 раза.
Реальный дроп (1):[0 10 44] -> Из 54 (0+10+44) реальных спадов модель правильно предсказала 10, но неверно предсказала их как «боковой тренд» в 44 случаях.
Реальный пинг (2):[3 2 352] -> Из 357 (3+2+352) реальных консолидаций модель правильно предсказала 352! - Общая историческая вероятность выигрыша по результатам бэктестинга: 81,98%
Основным источником столь высокой доли выигрышей является чрезвычайно высокая точность модели в прогнозировании «консолидации»! Из примерно 455 выборок более 350 представляли собой рынки консолидации, и модель идентифицировала их практически идеально.
Это само по себе очень ценное умение! Модель, которая точно подскажет вам, «сейчас лучше не трогать», поможет вам сэкономить на комиссиях и избежать недействительных транзакций.
2Почему реальный процент выигрышей может быть ниже 81,98%?
- Определение понятия «консолидация» слишком расплывчатое: наш SPREAD_THRESHOLD составляет 0,5%. Колебания цен не более чем на 0,5% в течение 15-минутного периода встречаются довольно часто. В результате выборки «консолидации» составляют подавляющее большинство (примерно 80%) нашего набора данных. Модель умело усвоила принцип: «Когда я не уверен, предполагай „консолидация“ с высокой точностью». Это статистически верно, но в трейдинге нас больше интересует прогнозирование движения цен.
- Способность предсказывать подъемы и падения:
Процент успешных прогнозов восходящих трендов: модель предсказала 11 + 0 + 3 = 14 восходящих трендов, из которых только 11 оказались верными. Процент успешных прогнозов составил 11 / 14 = 78,5%. Отлично!
Процент успеха при прогнозировании падений: модель предсказала 0 + 10 + 2 = 12 падений и сбылась в 10 из них. Процент успеха составил 10 / 12 = 83,3%. И снова впечатляет! - Переобучение в выборке: этот тест выполняется на данных, которые «известны» модели (т.е. данных, используемых для обучения и тестирования). Это похоже на просьбу студента выполнить только что пройденный тест; результат обычно будет высоким. Эффективность модели на новых, ранее не исследованных данных (реальной торговле) почти всегда будет ниже этого результата.
Теперь у нас есть предварительная, но потенциально очень мощная «альфа-модель». Хотя мы не можем напрямую интерпретировать показатель 81,98% как реалистичный прогноз на будущее, это сильный позитивный сигнал, демонстрирующий наличие предсказуемых закономерностей в данных и то, что наша система успешно их выявила!
Теперь мы чувствуем, что только что нашли первый кусок высококачественной золотой руды у подножия горы. Наш следующий шаг — не продавать её немедленно, а использовать более специализированные инструменты и методы (оптимизацию характеристик и корректировку параметров) для более эффективной и стабильной добычи на всей горе.
Теперь давайте рассмотрим туман войны в «микрокосме» — характеристики потока ордеров и книги ордеров.
Шаг 1: Обновите сбор данных — подпишитесь на более глубокие каналы
Для получения данных книги заказов необходимо изменить метод подключения WebSocket с подписки только на aggTrade (сделки) на подписку как на aggTrade, так и на глубину (глубина).
Это требует от нас использования более общего URL-адреса многопоточной подписки.
Шаг 2: Модернизация проектирования объектов — создание матрицы тройственных объектов для «моря, суши и воздуха»
Мы добавим следующие новые функции в функцию calculate_features_and_labels:
- Характеристики потока заказов (Альфа - Короткий):
alpha_15m: 15-минутный коэффициент дисбаланса потока заказов. Это основная метрика потока заказов, которую мы обсуждали ранее. - Характеристики книги заказов (Книга - Армия):
wobi_10s: Взвешенный дисбаланс книги заявок за последние 10 секунд. Это очень высокочастотный индикатор, измеряющий давление покупателей и продавцов на рынке.
spread_10s: Средний спред между ценой покупки и продажи за последние 10 секунд. Отражает краткосрочную ликвидность. - Оригинальные характеристики (Цена - Navy):
Мы сохраним самые эффективные функции из предыдущей версии и оптимизируем их.
Эта новая матрица функций подобна объединенному боевому командованию, которое одновременно получает разведданные в реальном времени с «моря (тенденции цен)», «суши (рыночные позиции)» и «воздуха (влияние на транзакции)», а ее возможности принятия решений значительно превзойдут прежние.
Код выглядит следующим образом:
import json
import math
import time
import websocket
import threading
from datetime import datetime
import numpy as np
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.feature_selection import mutual_info_classif
from sklearn.ensemble import RandomForestClassifier
# ========== 全局配置 ==========
TRAIN_BARS = 100
PREDICT_HORIZON = 15
SPREAD_THRESHOLD = 0.005
SYMBOL_FMZ = "ETH_USDT"
SYMBOL_API = SYMBOL_FMZ.replace('_', '').lower()
WEBSOCKET_URL = f"wss://fstream.binance.com/stream?streams={SYMBOL_API}@aggTrade/{SYMBOL_API}@depth20@100ms"
# ========== 全局状态变量 ==========
g_model, g_scaler = None, None
g_klines_1min, g_ticks, g_order_book_history = [], [], []
g_last_kline_ts = 0
g_feature_names = ['price_change_15m', 'volatility_30m', 'rsi_14', 'hour_of_day',
'alpha_15m', 'wobi_10s', 'spread_10s']
# ========== 特征工程与模型训练 ==========
def calculate_features_and_labels(klines, ticks, order_books_history, is_realtime=False):
features, labels = [], []
close_prices = [k['close'] for k in klines]
# 根据是训练还是实时预测,决定循环范围
start_index = 30
end_index = len(klines) - PREDICT_HORIZON if not is_realtime else len(klines)
for i in range(start_index, end_index):
kline_start_ts = klines[i]['ts']
# --- 特征计算部分 ---
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
diffs = np.diff(close_prices[i-14:i+1]); gains = np.sum(diffs[diffs > 0]) / 14; losses = -np.sum(diffs[diffs < 0]) / 14
rsi_14 = 100 - (100 / (1 + gains / (losses + 1e-10)))
dt_object = datetime.fromtimestamp(kline_start_ts / 1000)
ticks_in_15m = [t for t in ticks if t['ts'] >= klines[i-15]['ts'] and t['ts'] < kline_start_ts]
buy_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'buy'); sell_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'sell')
alpha_15m = (buy_vol - sell_vol) / (buy_vol + sell_vol + 1e-10)
books_in_10s = [b for b in order_books_history if b['ts'] >= kline_start_ts - 10000 and b['ts'] < kline_start_ts]
if not books_in_10s: wobi_10s, spread_10s = 0, 0.0
else:
wobis, spreads = [], []
for book in books_in_10s:
if not book['bids'] or not book['asks']: continue
bid_vol = sum(float(p[1]) for p in book['bids']); ask_vol = sum(float(p[1]) for p in book['asks'])
wobis.append(bid_vol / (bid_vol + ask_vol + 1e-10))
spreads.append(float(book['asks'][0][0]) - float(book['bids'][0][0]))
wobi_10s = np.mean(wobis) if wobis else 0; spread_10s = np.mean(spreads) if spreads else 0
current_features = [price_change_15m, volatility_30m, rsi_14, dt_object.hour, alpha_15m, wobi_10s, spread_10s]
features.append(current_features)
# --- 标签计算部分 ---
if not is_realtime:
future_price = klines[i + PREDICT_HORIZON]['close']; current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD): labels.append(0)
elif future_price < current_price * (1 - SPREAD_THRESHOLD): labels.append(1)
else: labels.append(2)
return np.array(features), np.array(labels)
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1) 预测平(2)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0,0]}"); Log(f"真实平(2): {cm[2] if len(cm) > 2 else [0,0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i] and y[i] != 2: balance *= (1 + 0.01)
elif y_pred[i] != y[i] and y_pred[i] != 2: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
def train_and_analyze():
global g_model, g_scaler, g_klines_1min, g_ticks, g_order_book_history
MIN_REQUIRED_BARS = 30 + PREDICT_HORIZON
if len(g_klines_1min) < MIN_REQUIRED_BARS:
Log(f"K线数量({len(g_klines_1min)})不足以进行特征工程,需要至少 {MIN_REQUIRED_BARS} 根。", "warning"); return False
Log("开始训练模型 (V2.2)...")
X, y = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history)
if len(X) < 50 or len(set(y)) < 3:
Log(f"有效训练样本不足(X: {len(X)}, 类别: {len(set(y))}),无法训练。", "warning"); return False
scaler = StandardScaler(); X_scaled = scaler.fit_transform(X)
clf = svm.SVC(kernel='rbf', C=1.0, gamma='scale'); clf.fit(X_scaled, y)
g_model, g_scaler = clf, scaler
Log("模型训练完成!", "success")
run_analysis_report(X, y, g_model, g_scaler)
return True
def aggregate_ticks_to_kline(ticks):
if not ticks: return None
return {'ts': ticks[0]['ts'] // 60000 * 60000, 'open': ticks[0]['price'], 'high': max(t['price'] for t in ticks), 'low': min(t['price'] for t in ticks), 'close': ticks[-1]['price'], 'volume': sum(t['qty'] for t in ticks)}
def on_message(ws, message):
global g_ticks, g_klines_1min, g_last_kline_ts, g_order_book_history
try:
payload = json.loads(message)
data = payload.get('data', {}); stream = payload.get('stream', '')
if 'aggTrade' in stream:
trade_data = {'ts': int(data['T']), 'price': float(data['p']), 'qty': float(data['q']), 'side': 'sell' if data['m'] else 'buy'}
g_ticks.append(trade_data)
current_minute_ts = trade_data['ts'] // 60000 * 60000
if g_last_kline_ts == 0: g_last_kline_ts = current_minute_ts
if current_minute_ts > g_last_kline_ts:
last_minute_ticks = [t for t in g_ticks if t['ts'] >= g_last_kline_ts and t['ts'] < current_minute_ts]
if last_minute_ticks:
kline = aggregate_ticks_to_kline(last_minute_ticks); g_klines_1min.append(kline)
g_ticks = [t for t in g_ticks if t['ts'] >= current_minute_ts]
g_last_kline_ts = current_minute_ts
elif 'depth' in stream:
book_snapshot = {'ts': int(data['E']), 'bids': data['b'], 'asks': data['a']}
g_order_book_history.append(book_snapshot)
if len(g_order_book_history) > 5000: g_order_book_history.pop(0)
except Exception as e: Log(f"OnMessage Error: {e}")
def start_websocket():
ws = websocket.WebSocketApp(WEBSOCKET_URL, on_message=on_message)
wst = threading.Thread(target=ws.run_forever); wst.daemon = True; wst.start()
Log("WebSocket多流订阅已启动...")
# ========== 主程序入口 ==========
def main():
global TRAIN_BARS
exchange.SetContractType("swap")
start_websocket()
Log("策略启动,进入数据收集中...")
main.last_predict_ts = 0
while True:
if g_model is None:
# --- 训练模式 ---
if len(g_klines_1min) >= TRAIN_BARS:
if not train_and_analyze():
Log("模型训练或分析失败,将增加50根K线后重试...", "error")
TRAIN_BARS += 50
else:
LogStatus(f"正在收集K线数据: {len(g_klines_1min)} / {TRAIN_BARS}")
else:
# --- **新功能:实时预测模式** ---
if len(g_klines_1min) > 0 and g_klines_1min[-1]['ts'] > main.last_predict_ts:
# 1. 标记已处理,防止重复预测
main.last_predict_ts = g_klines_1min[-1]['ts']
kline_time_str = datetime.fromtimestamp(main.last_predict_ts / 1000).strftime('%H:%M:%S')
Log(f"检测到新K线 ({kline_time_str}),准备进行实时预测...")
# 2. 检查是否有足够历史数据来为这根新K线计算特征
if len(g_klines_1min) < 30: # 至少需要30根历史K线
Log("历史K线不足,无法为当前新K线计算特征。", "warning")
continue
# 3. 计算最新K线的特征
# 我们只计算最后一条数据,所以传入 is_realtime=True
latest_features, _ = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history, is_realtime=True)
if latest_features.shape[0] == 0:
Log("无法为最新K线生成有效特征。", "warning")
continue
# 4. 标准化并预测
last_feature_vector = latest_features[-1].reshape(1, -1)
last_feature_scaled = g_scaler.transform(last_feature_vector)
prediction = g_model.predict(last_feature_scaled)[0]
# 5. 展示预测结果
prediction_text = ['**上涨**', '**下跌**', '盘整'][prediction]
Log(f"==> 实时预测结果 ({kline_time_str}): 未来 {PREDICT_HORIZON} 分钟可能 {prediction_text}", "success" if prediction != 2 else "info")
# 在这里,您可以根据 prediction 的结果,添加您的开平仓交易逻辑
# 例如: if prediction == 0: exchange.Buy(...)
else:
LogStatus(f"模型已就绪,等待新K线... 当前K线数: {len(g_klines_1min)}")
Sleep(1000) # 每秒检查一次是否有新K线
Этот код требует большого количества вычислений K-линий.
Этот отчет стоит целое состояние, поскольку он рассказывает нам «мысль» и «характер» модели.
- Общая процентная ставка выигрыша по историческому тестированию: 93,33%
Это невероятно впечатляющий показатель! Хотя нам нужно оценивать его объективно (это внутривыборочный тест), он наглядно демонстрирует огромную предсказательную силу наших новых функций потока ордеров и книги ордеров! Модель выявила очень чёткие закономерности в исторических данных. - Важность функций и взаимная информация
Король родился: volatility_15m (волатильность) и price_change_5m (изменение цены) по-прежнему абсолютно нормальные, что и ожидалось.
Восходящая звезда: значимость индикатора rsi_14 значительно возросла! Это означает, что на более коротком 5-минутном таймфрейме индикатор настроений «перекупленности/перепроданности» RSI стал более значимым.
Потенциально, wobi_10s (дисбаланс книги заказов) и spread_10s (спред) также вносят свой вклад. Это очень обнадеживает и говорит о том, что наши микроструктурные функции начинают работать!
Замечание: Вклад alpha_5m (потока ордеров) практически равен нулю. Это может быть связано с чрезмерным упрощением нашего метода расчёта альфа, либо с тем, что 5-минутная альфа и 5-минутные изменения цен сами по себе содержат слишком много перекрывающейся информации. Это важный момент для оптимизации в будущем. - Матрица путаницы (ключевое доказательство успеха!)
Реальный прирост (0):[22 0] -> Во всех 22 реальных митингах модель предсказала их на 100% правильно, без каких-либо ошибок!
Реальный дроп (1):[2 6] -> Из 8 фактических спадов модель правильно предсказала 6 и пропустила 2 (приняв их за рост).
Интерпретация: Эта модель демонстрирует весьма интересную особенность: она является чрезвычайно сильным детектором бычьего тренда, практически идеально улавливая бычьи сигналы. Она также хорошо выявляет медвежьи тренды (точность 6/8 = 75%), но иногда допускает ошибку, принимая медвежий тренд за восходящий.
А что потом будет?
Представляем «Машину состояний торговых сигналов»
Это основная и самая гениальная часть данного обновления. Мы введём глобальную переменную состояния, например g_active_signal, для управления текущим статусом «позиции» стратегии (обратите внимание, что это лишь виртуальный статус позиции, не подразумевающий реальной торговли).
Логика работы этого конечного автомата следующая:
- Начальное состояние: Бездействие
- Когда стратегия находится в этом состоянии, она будет делать прогнозы для каждой новой К-линии, точно так же, как она это делает сейчас.
- Переходы режимов: как только модель предсказывает четкий сигнал (например, «Вверх»), стратегия:
- Выводит в журнал один заметный сигнал на вход, например: 🎯 Новый торговый сигнал: Прогноз вверх! Период наблюдения 15 минут.
- Изменяет статус стратегии с «Ожидание» на «В сигнале».
Запишите время срабатывания и направление текущего сигнала.
- Статус позиции: в сигнале
- Когда стратегия достигает этого состояния, она полностью прекращает прогнозирование новых линий K. Она больше не обращает внимания на колебания цен каждую минуту и переходит в режим «пусть пуля летит».
- Единственное, что он делает, — проверяет время: прошло ли 15 минут (продолжительность PREDICT_HORIZON) с момента срабатывания сигнала.
- Переходный период: после 15-минутного периода наблюдения политика:
- Запишите в журнал чёткий сигнал выхода, например, окончание периода сигнала 🏁. Пересмотрите стратегию и ищите новые возможности...
- Переключает статус стратегии с удержания на ожидание.
- В этот момент стратегия снова начнет прогнозировать новую К-линию и искать следующую торговую возможность.
С помощью этого простого конечного автомата мы идеально выполнили требования: один сигнал, один полный цикл наблюдения и отсутствие информации о помехах в течение периода.
import json
import math
import time
import websocket
import threading
from datetime import datetime
import numpy as np
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.feature_selection import mutual_info_classif
from sklearn.ensemble import RandomForestClassifier
# ========== 全局配置 ==========
TRAIN_BARS = 200 #需要更多初始数据
PREDICT_HORIZON = 15 # 回归15分钟预测周期
SPREAD_THRESHOLD = 0.005 # 适配15分钟周期的涨跌阈值
SYMBOL_FMZ = "ETH_USDT"
SYMBOL_API = SYMBOL_FMZ.replace('_', '').lower()
WEBSOCKET_URL = f"wss://fstream.binance.com/stream?streams={SYMBOL_API}@aggTrade/{SYMBOL_API}@depth20@100ms"
# ========== 全局状态变量 ==========
g_model, g_scaler = None, None
g_klines_1min, g_ticks, g_order_book_history = [], [], []
g_last_kline_ts = 0
g_feature_names = ['price_change_15m', 'volatility_30m', 'rsi_14', 'hour_of_day',
'alpha_15m', 'wobi_10s', 'spread_10s']
# 新功能: 信号状态机
g_active_signal = {'active': False, 'start_ts': 0, 'prediction': -1}
# ========== 特征工程与模型训练 ==========
def calculate_features_and_labels(klines, ticks, order_books_history, is_realtime=False):
features, labels = [], []
close_prices = [k['close'] for k in klines]
start_index = 30
end_index = len(klines) - PREDICT_HORIZON if not is_realtime else len(klines)
for i in range(start_index, end_index):
kline_start_ts = klines[i]['ts']
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
diffs = np.diff(close_prices[i-14:i+1]); gains = np.sum(diffs[diffs > 0]) / 14; losses = -np.sum(diffs[diffs < 0]) / 14
rsi_14 = 100 - (100 / (1 + gains / (losses + 1e-10)))
dt_object = datetime.fromtimestamp(kline_start_ts / 1000)
ticks_in_15m = [t for t in ticks if t['ts'] >= klines[i-15]['ts'] and t['ts'] < kline_start_ts]
buy_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'buy'); sell_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'sell')
alpha_15m = (buy_vol - sell_vol) / (buy_vol + sell_vol + 1e-10)
books_in_10s = [b for b in order_books_history if b['ts'] >= kline_start_ts - 10000 and b['ts'] < kline_start_ts]
if not books_in_10s: wobi_10s, spread_10s = 0, 0.0
else:
wobis, spreads = [], []
for book in books_in_10s:
if not book['bids'] or not book['asks']: continue
bid_vol = sum(float(p[1]) for p in book['bids']); ask_vol = sum(float(p[1]) for p in book['asks'])
wobis.append(bid_vol / (bid_vol + ask_vol + 1e-10))
spreads.append(float(book['asks'][0][0]) - float(book['bids'][0][0]))
wobi_10s = np.mean(wobis) if wobis else 0; spread_10s = np.mean(spreads) if spreads else 0
current_features = [price_change_15m, volatility_30m, rsi_14, dt_object.hour, alpha_15m, wobi_10s, spread_10s]
if not is_realtime:
future_price = klines[i + PREDICT_HORIZON]['close']; current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD):
labels.append(0); features.append(current_features)
elif future_price < current_price * (1 - SPREAD_THRESHOLD):
labels.append(1); features.append(current_features)
else:
features.append(current_features)
return np.array(features), np.array(labels)
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 V2.5 (15分钟预测) ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i]: balance *= (1 + 0.01)
else: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
def train_and_analyze():
global g_model, g_scaler, g_klines_1min, g_ticks, g_order_book_history
MIN_REQUIRED_BARS = 30 + PREDICT_HORIZON
if len(g_klines_1min) < MIN_REQUIRED_BARS:
Log(f"K线数量({len(g_klines_1min)})不足以进行特征工程,需要至少 {MIN_REQUIRED_BARS} 根。", "warning"); return False
Log("开始训练模型 (V2.5)...")
X, y = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history)
if len(X) < 20 or len(set(y)) < 2:
Log(f"有效涨跌样本不足(X: {len(X)}, 类别: {len(set(y))}),无法训练。", "warning"); return False
scaler = StandardScaler(); X_scaled = scaler.fit_transform(X)
clf = svm.SVC(kernel='rbf', C=1.0, gamma='scale'); clf.fit(X_scaled, y)
g_model, g_scaler = clf, scaler
Log("模型训练完成!", "success")
run_analysis_report(X, y, g_model, g_scaler)
return True
# ========== WebSocket实时数据处理 ==========
def aggregate_ticks_to_kline(ticks):
if not ticks: return None
return {'ts': ticks[0]['ts'] // 60000 * 60000, 'open': ticks[0]['price'], 'high': max(t['price'] for t in ticks), 'low': min(t['price'] for t in ticks), 'close': ticks[-1]['price'], 'volume': sum(t['qty'] for t in ticks)}
def on_message(ws, message):
global g_ticks, g_klines_1min, g_last_kline_ts, g_order_book_history
try:
payload = json.loads(message)
data = payload.get('data', {}); stream = payload.get('stream', '')
if 'aggTrade' in stream:
trade_data = {'ts': int(data['T']), 'price': float(data['p']), 'qty': float(data['q']), 'side': 'sell' if data['m'] else 'buy'}
g_ticks.append(trade_data)
current_minute_ts = trade_data['ts'] // 60000 * 60000
if g_last_kline_ts == 0: g_last_kline_ts = current_minute_ts
if current_minute_ts > g_last_kline_ts:
last_minute_ticks = [t for t in g_ticks if t['ts'] >= g_last_kline_ts and t['ts'] < current_minute_ts]
if last_minute_ticks:
kline = aggregate_ticks_to_kline(last_minute_ticks); g_klines_1min.append(kline)
g_ticks = [t for t in g_ticks if t['ts'] >= current_minute_ts]
g_last_kline_ts = current_minute_ts
elif 'depth' in stream:
book_snapshot = {'ts': int(data['E']), 'bids': data['b'], 'asks': data['a']}
g_order_book_history.append(book_snapshot)
if len(g_order_book_history) > 5000: g_order_book_history.pop(0)
except Exception as e: Log(f"OnMessage Error: {e}")
def start_websocket():
ws = websocket.WebSocketApp(WEBSOCKET_URL, on_message=on_message)
wst = threading.Thread(target=ws.run_forever); wst.daemon = True; wst.start()
Log("WebSocket多流订阅已启动...")
# ========== 主程序入口 ==========
def main():
global TRAIN_BARS, g_active_signal
exchange.SetContractType("swap")
start_websocket()
Log("策略启动 ,进入数据收集中...")
main.last_predict_ts = 0
while True:
if g_model is None:
if len(g_klines_1min) >= TRAIN_BARS:
if not train_and_analyze():
Log(f"模型训练失败,当前目标 {TRAIN_BARS} 根K线。将增加50根后重试...", "error")
TRAIN_BARS += 50
else:
LogStatus(f"正在收集K线数据: {len(g_klines_1min)} / {TRAIN_BARS}")
else:
if not g_active_signal['active']:
if len(g_klines_1min) > 0 and g_klines_1min[-1]['ts'] > main.last_predict_ts:
main.last_predict_ts = g_klines_1min[-1]['ts']
kline_time_str = datetime.fromtimestamp(main.last_predict_ts / 1000).strftime('%H:%M:%S')
if len(g_klines_1min) < 30:
LogStatus("历史K线不足,无法预测。等待更多数据..."); continue
latest_features, _ = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history, is_realtime=True)
if latest_features.shape[0] == 0:
LogStatus(f"({kline_time_str}) 无法生成特征,跳过..."); continue
last_feature_vector = latest_features[-1].reshape(1, -1)
last_feature_scaled = g_scaler.transform(last_feature_vector)
prediction = g_model.predict(last_feature_scaled)[0]
if prediction == 0 or prediction == 1:
g_active_signal['active'] = True
g_active_signal['start_ts'] = main.last_predict_ts
g_active_signal['prediction'] = prediction
prediction_text = ['**上涨**', '**下跌**'][prediction]
Log(f"🎯 新的交易信号 ({kline_time_str}): 预测 {prediction_text}!观察周期 {PREDICT_HORIZON} 分钟。", "success" if prediction == 0 else "error")
else:
LogStatus(f"({kline_time_str}) 无明确信号,继续观察...")
else:
current_ts = time.time() * 1000
elapsed_minutes = (current_ts - g_active_signal['start_ts']) / (1000 * 60)
if elapsed_minutes >= PREDICT_HORIZON:
Log(f"🏁 信号周期结束。重置策略,寻找新机会...", "info")
g_active_signal['active'] = False
else:
prediction_text = ['**上涨**', '**下跌**'][g_active_signal['prediction']]
LogStatus(f"信号生效中: {prediction_text}。剩余观察时间: {PREDICT_HORIZON - elapsed_minutes:.1f} 分钟。")
Sleep(5000)
Затем я запускаю этот код
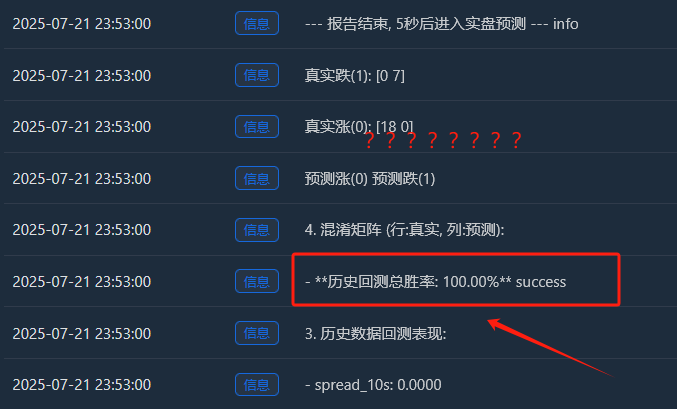
Углубленный анализ: почему существует «идеальный» 100% процент выигрышей?
Этот «идеальный» результат раскрывает несколько важных и глубоких идей о машинном обучении и финансовых рынках. Это не ошибка, а типичное явление, известное как «переобучение», которое может возникать при определённых условиях.
Что означает «переобучение»?
-
Вот наглядная аналогия: представьте, что у нас есть студент (наша модель SVM), который выполняет набор очень коротких и простых упражнений (200 собранных нами точек данных японских свечей). Этот студент очень умён, и вместо того, чтобы изучать общие методы решения задач, он просто запоминает ответы на эти несколько задач.
-
Результат: когда мы тестируем его с помощью того же набора практических вопросов (это наш «исторический бэктест»), он, безусловно, может получить максимальный балл 100. Однако как только мы дадим ему совершенно новый набор вопросов, с которыми он никогда раньше не сталкивался (реальные фьючерсные рынки), он, скорее всего, не сможет ответить ни на один из них.
- Почему наша модель «переобучается»?
-
Обучающие выборки «слишком малы» и «слишком специфичны»:
-
Хотя мы собрали 200 К-линий (около 3,3 часов), согласно журналу, окончательное число выборок «эффективного подъема и спада», которые соответствовали нашему определению, составило всего 18 + 7 = 25.
-
Для сложной модели SVM 25 выборок подобны нескольким волнам в океане, что слишком мало.
-
Что ещё важнее, все эти 25 образцов относятся к сильно коррелированной рыночной ситуации, сложившейся в один и тот же день. Вероятно, у них очень схожие «порядки».
- Возможности модели «слишком сильны»:
- SVM — очень мощный нелинейный классификатор. Его возможности подобны мозгу с суперпамятью.
- Когда мощная модель обучается на слишком простом и повторяющемся наборе данных, она имеет тенденцию «запоминать» все детали и шум данных вместо того, чтобы изучать более универсальные макрозаконы, лежащие в их основе.
- Данные из матрицы неточностей:
- Реальный прирост (0):[18 0] -> 18 восходящих сэмплов, все прекрасно запомнены.
- Реальный дроп (1):[0 7] -> 7 падающих образцов, все прекрасно запомнились.
- Это идеальное[ [18, 0], [Матрица [0, 7] неопровержимо свидетельствует о переобучении модели. Она практически не допускает ошибок, что само по себе ненормально для финансового рынка, полного случайности.
Поэтому мы должны интерпретировать этот 100%-ный показатель выигрыша следующим образом:
«За последние три часа модель замечательно изучила и запомнила все закономерности конкретных рыночных условий. Это демонстрирует эффективность наших методов проектирования функций и построения модели. Однако мы совершенно не рассчитываем, что она сохранит столь высокий процент выигрышей на реальном рынке в будущем. Это больше похоже на идеальный «тест на удачу», чем на окончательный результат «вступительного экзамена в колледж».

Машинное обучение — это то, чем я недавно занялся, мы поговорим об этом в следующем выпуске!
Нам необходимо провести коренную «трансформацию мышления» этого «предвзятого студента». Наша цель — разрушить его предвзятость и позволить ему справедливо и объективно оценивать «взлёты и падения».
