
Предварительное исследование применения Python Crawler на платформе FMZ - Crawling Binance Анонс контента
Недавно я просмотрел сообщество и библиотеку и не нашел никакой важной информации о краулерах Python, исходя из духа всесторонней разработки как КВАНТА. Я очень просто изучил концепции и знания, связанные с краулерами. Узнав больше об этом, я обнаружил, что "технология гусеничных машин" - это довольно большая "яма". Эта статья - лишь предварительное исследование "технологии гусеничных машин". Давайте выполним простейшую практику использования технологии краулера на количественной торговой платформе FMZ.
нуждаться
Трейдеры, желающие инвестировать в новые монеты, всегда надеются как можно скорее получить информацию о монетах, котирующихся на бирже. Очевидно, что следить за сайтом биржи вручную нереально. Затем вам необходимо использовать скрипт-сканер для мониторинга страницы объявлений биржи и обнаружения новых объявлений, чтобы вы могли получать уведомления и напоминания как можно скорее.
Первичное исследование
Давайте для начала воспользуемся очень простой программой (действительно мощный скрипт сканера гораздо сложнее, так что не торопитесь). Логика программы очень проста: она позволяет программе непрерывно обращаться к странице объявлений биржи, анализировать полученный HTML-контент и определять, обновлено ли содержимое определенного тега.
Код реализации
Вы можете использовать некоторые полезные фреймворки для сканирования. Однако, учитывая, что требование очень простое, его можно записать и напрямую.
Необходимы библиотеки Python:
requests, что можно просто понимать как библиотеку, используемую для доступа к веб-страницам.
bs4, которую можно просто понимать как библиотеку, используемую для анализа HTML-кода веб-страницы.
Код:
from bs4 import BeautifulSoup
import requests
urlBinanceAnnouncement = "https://www.binancezh.io/en/support/announcement/c-48?navId=48" # 币安公告页面地址
def openUrl(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
r = requests.get(url, headers=headers) # 使用requests库访问url,即币安的公告网页地址
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # 访问成功的话返回网页内容文本
else:
Log("failed {}".format(url))
def main():
preNews_href = ""
lastNews = ""
Log("watching...", urlBinanceAnnouncement, "#FF0000")
while True:
ret = openUrl(urlBinanceAnnouncement)
if ret:
soup = BeautifulSoup(ret, 'html.parser') # 把网页文本解析为对象
lastNews_href = soup.find('a', class_='css-1ej4hfo')["href"] # 查找特定的标签,获取href
lastNews = soup.find('a', class_='css-1ej4hfo').get_text() # 获取这个标签中的内容
if preNews_href == "":
preNews_href = lastNews_href
if preNews_href != lastNews_href: # 检测到标签发生变动,即有新的公告产生
Log("New Cryptocurrency Listing update!") # 打印提示信息
preNews_href = lastNews_href
LogStatus(_D(), "\n", "preNews_href:", preNews_href, "\n", "news:", lastNews)
Sleep(1000 * 10)
бегать
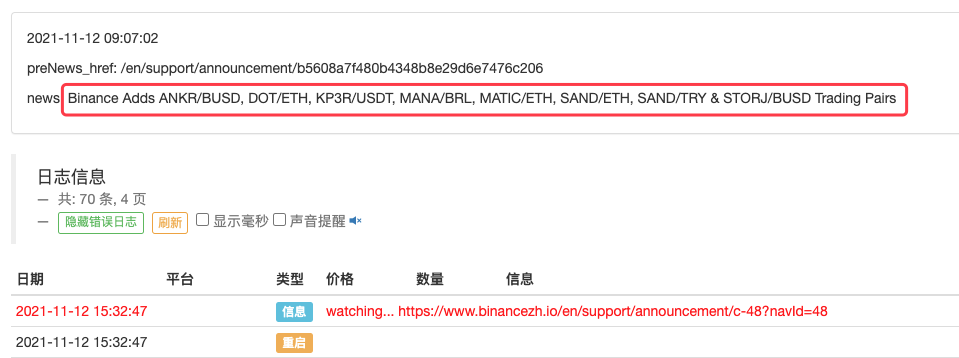
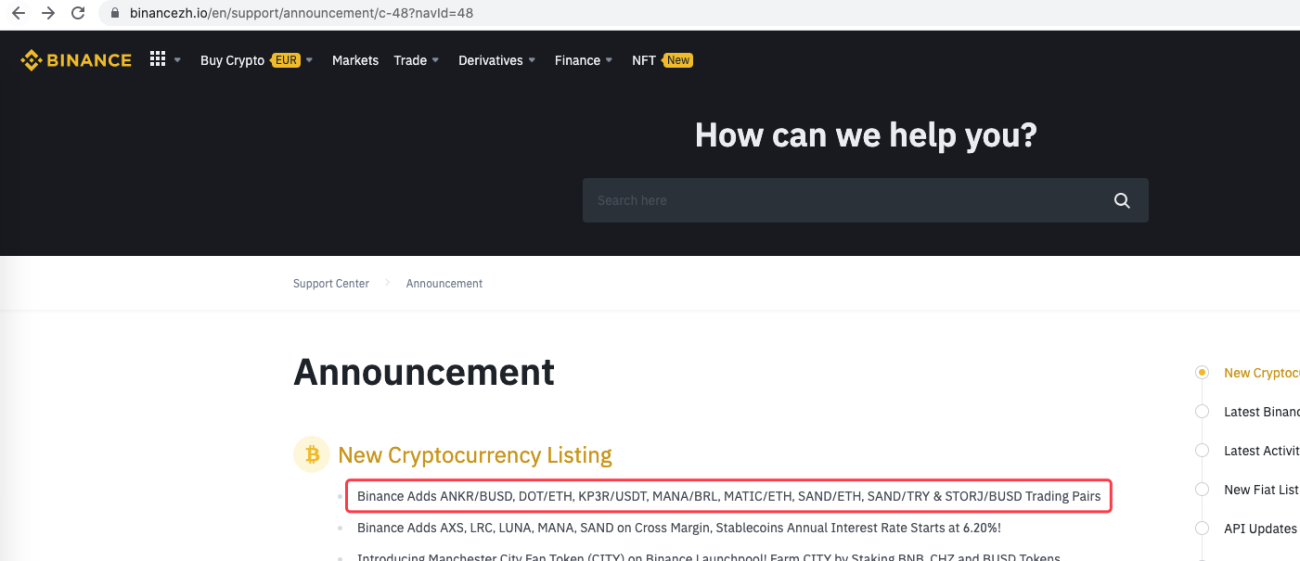
Его можно даже расширить, например, для обнаружения появления нового объявления. Анализируйте новые валюты, указанные в объявлении, и автоматически размещайте заказы на новые транзакции.

Traceback (most recent call last): File "<string>", line 999, in init_ctx File "<string>", line 1, in <module> ModuleNotFoundError: No module named 'bs4'
复制代码到实盘提示错误,是不是缺失python的库。怎么添加库到托管着呢。


作者你好,我也写了一个爬币安公告的爬虫,不管是用那个api接口还是主页的爬虫都有30s延迟,不知道你有没有解决这个问题,可以交流下吗,我的vx ShawnQiang1125


- 1