

دیباچہ
انوینٹر کوانٹیٹیو ٹریڈنگ پلیٹ فارم کا بیک ٹیسٹنگ سسٹم ایک بیک ٹیسٹنگ سسٹم ہے جو کہ ابتدائی بنیادی بیک ٹیسٹنگ فنکشنز سے مسلسل اعادہ، اپ ڈیٹ اور اپ گریڈ کر رہا ہے، یہ بتدریج افعال میں اضافہ کرتا ہے اور کارکردگی کو بہتر بناتا ہے۔ جیسے جیسے پلیٹ فارم تیار ہوتا ہے، بیک ٹیسٹنگ سسٹم کو بہتر اور اپ گریڈ کیا جاتا رہے گا آج ہم بیک ٹیسٹنگ سسٹم پر مبنی ایک موضوع پر بات کریں گے: "مارکیٹ کے بے ترتیب حالات پر مبنی حکمت عملی کی جانچ"۔
ضرورت
مقداری تجارت کے میدان میں، حکمت عملیوں کی ترقی اور اصلاح کو حقیقی مارکیٹ ڈیٹا کی تصدیق سے الگ نہیں کیا جا سکتا۔ تاہم، اصل ایپلی کیشنز میں، پیچیدہ اور بدلتے ہوئے بازار کے ماحول کی وجہ سے، بیک ٹیسٹنگ کے لیے تاریخی ڈیٹا پر انحصار کرنے میں کوتاہیاں ہو سکتی ہیں، جیسے کہ مارکیٹ کے انتہائی حالات یا خصوصی حالات کی کوریج کی کمی۔ لہذا، ایک موثر بے ترتیب مارکیٹ جنریٹر کو ڈیزائن کرنا مقداری حکمت عملی تیار کرنے والوں کے لیے ایک مؤثر ذریعہ بن جاتا ہے۔
جب ہمیں تاریخی ڈیٹا کا استعمال کرتے ہوئے کسی مخصوص تبادلے یا کرنسی پر حکمت عملی کو بیک ٹیسٹ کرنے کی ضرورت ہوتی ہے، تو ہم بیک ٹیسٹنگ کے لیے FMZ پلیٹ فارم کے آفیشل ڈیٹا سورس کا استعمال کر سکتے ہیں۔ بعض اوقات ہم یہ بھی دیکھنا چاہتے ہیں کہ کوئی حکمت عملی مکمل طور پر "ناواقف" مارکیٹ میں کیسے کام کرتی ہے، اس وقت ہم حکمت عملی کو جانچنے کے لیے کچھ ڈیٹا "من گھڑت" کر سکتے ہیں۔
بے ترتیب مارکیٹ ڈیٹا استعمال کرنے کی اہمیت یہ ہے:
-
- حکمت عملی کی مضبوطی کا اندازہ لگانا
بے ترتیب مارکیٹ جنریٹر مارکیٹ کے متعدد ممکنہ منظرنامے تشکیل دے سکتا ہے، بشمول انتہائی اتار چڑھاؤ، کم اتار چڑھاؤ، رجحان ساز مارکیٹس، اور اتار چڑھاؤ والے بازار۔ ان نقلی ماحول میں حکمت عملی کی جانچ کرنے سے یہ اندازہ لگانے میں مدد مل سکتی ہے کہ آیا اس کی کارکردگی مختلف مارکیٹ کے حالات میں مستحکم ہے۔ مثال کے طور پر:
کیا حکمت عملی رجحان اور شاک سوئچنگ کے مطابق ہو سکتی ہے؟
کیا حکمت عملی کے نتیجے میں مارکیٹ کے انتہائی حالات میں کافی نقصان ہوگا؟ - حکمت عملی کی مضبوطی کا اندازہ لگانا
-
- اپنی حکمت عملی میں ممکنہ کمزوریوں کی نشاندہی کریں۔
مارکیٹ کے کچھ غیر معمولی حالات (جیسے فرضی بلیک سوان واقعات) کی تقلید کرتے ہوئے، حکمت عملی میں ممکنہ کمزوریوں کو دریافت اور بہتر کیا جا سکتا ہے۔ مثال کے طور پر:
کیا حکمت عملی کسی خاص مارکیٹ کے ڈھانچے پر بہت زیادہ انحصار کرتی ہے؟
کیا پیرامیٹرز کو زیادہ فٹ ہونے کا خطرہ ہے؟ - اپنی حکمت عملی میں ممکنہ کمزوریوں کی نشاندہی کریں۔
-
- حکمت عملی کے پیرامیٹرز کو بہتر بنانا
تصادفی طور پر تیار کردہ ڈیٹا حکمت عملی پیرامیٹر ٹیوننگ کے لیے مکمل طور پر تاریخی ڈیٹا پر انحصار کیے بغیر ٹیسٹنگ کا ایک زیادہ متنوع ماحول فراہم کرتا ہے۔ یہ حکمت عملی کے پیرامیٹرز کی زیادہ جامع رینج کی اجازت دیتا ہے اور تاریخی اعداد و شمار میں مخصوص مارکیٹ پیٹرن تک محدود رہنے سے گریز کرتا ہے۔
- حکمت عملی کے پیرامیٹرز کو بہتر بنانا
-
- تاریخی اعداد و شمار میں خلا کو پُر کرنا
کچھ بازاروں میں (جیسے ابھرتی ہوئی مارکیٹیں یا چھوٹی کرنسیوں کی تجارت کرنے والی مارکیٹیں)، تاریخی ڈیٹا مارکیٹ کے تمام ممکنہ حالات کا احاطہ کرنے کے لیے کافی نہیں ہو سکتا۔ رینڈمائزر زیادہ جامع جانچ کی سہولت کے لیے اضافی ڈیٹا کی ایک بڑی مقدار فراہم کر سکتا ہے۔
- تاریخی اعداد و شمار میں خلا کو پُر کرنا
-
- تیزی سے تکراری ترقی
تیز رفتار جانچ کے لیے بے ترتیب ڈیٹا کا استعمال ریئل ٹائم مارکیٹ کے حالات یا ڈیٹا کی صفائی اور تنظیم پر بھروسہ کیے بغیر حکمت عملی کی ترقی کی رفتار کو تیز کر سکتا ہے۔
- تیزی سے تکراری ترقی
تاہم، تصادفی طور پر تیار کردہ مارکیٹ ڈیٹا کے لیے حکمت عملی کا جائزہ لینا بھی ضروری ہے، براہ کرم نوٹ کریں:
-
- اگرچہ بے ترتیب مارکیٹ جنریٹر کارآمد ہوتے ہیں، لیکن ان کی اہمیت پیدا کردہ ڈیٹا کے معیار اور ہدف کے منظر نامے کے ڈیزائن پر منحصر ہے:
-
- نسل کی منطق کو حقیقی مارکیٹ کے قریب ہونے کی ضرورت ہے: اگر تصادفی طور پر پیدا ہونے والے بازار کے حالات حقیقت سے بالکل باہر ہیں، تو ٹیسٹ کے نتائج میں حوالہ کی قدر کی کمی ہو سکتی ہے۔ مثال کے طور پر، جنریٹر کو مارکیٹ کی اصل شماریاتی خصوصیات (جیسے اتار چڑھاؤ کی تقسیم، رجحان کا تناسب) کے ساتھ مل کر ڈیزائن کیا جا سکتا ہے۔
-
- یہ حقیقی ڈیٹا ٹیسٹنگ کو مکمل طور پر تبدیل نہیں کر سکتا: بے ترتیب ڈیٹا صرف حکمت عملیوں کی ترقی اور اصلاح میں اضافہ کر سکتا ہے، حتمی حکمت عملی کو حقیقی مارکیٹ ڈیٹا میں اس کی تاثیر کی تصدیق کرنے کی ضرورت ہے۔
یہ سب کہنے کے بعد، ہم کچھ ڈیٹا کیسے "من گھڑت" کر سکتے ہیں۔ بیک ٹیسٹنگ سسٹم میں استعمال کے لیے ہم آسانی سے، جلدی اور آسانی سے ڈیٹا کیسے "من گھڑت" کر سکتے ہیں؟
ڈیزائن کے خیالات
اس مضمون کو بحث کے لیے نقطہ آغاز فراہم کرنے کے لیے ڈیزائن کیا گیا ہے اور یہ ایک نسبتاً آسان مارکیٹ کی تیاری کا حساب کتاب فراہم کرتا ہے، درحقیقت، مختلف قسم کے نقلی الگورتھم، ڈیٹا ماڈلز اور دیگر ٹیکنالوجیز ہیں جن کا اطلاق محدود جگہ کی وجہ سے کیا جا سکتا ہے۔ ، ہم خاص طور پر پیچیدہ ڈیٹا سمولیشن طریقے استعمال نہیں کریں گے۔
پلیٹ فارم بیک ٹیسٹنگ سسٹم کے کسٹم ڈیٹا سورس فنکشن کو یکجا کرتے ہوئے، ہم نے Python میں ایک پروگرام لکھا۔
-
- بے ترتیب طور پر K-line ڈیٹا کا ایک سیٹ بنائیں اور مستقل ریکارڈنگ کے لیے انہیں CSV فائل میں لکھیں، تاکہ تیار کردہ ڈیٹا کو محفوظ کیا جا سکے۔
-
- پھر بیک ٹیسٹنگ سسٹم کے لیے ڈیٹا سورس سپورٹ فراہم کرنے کے لیے ایک سروس بنائیں۔
-
- تیار کردہ K-line ڈیٹا کو چارٹ میں دکھائیں۔
کچھ نسل کے معیارات اور K-line ڈیٹا کی فائل اسٹوریج کے لیے، درج ذیل پیرامیٹر کنٹرولز کی وضاحت کی جا سکتی ہے:
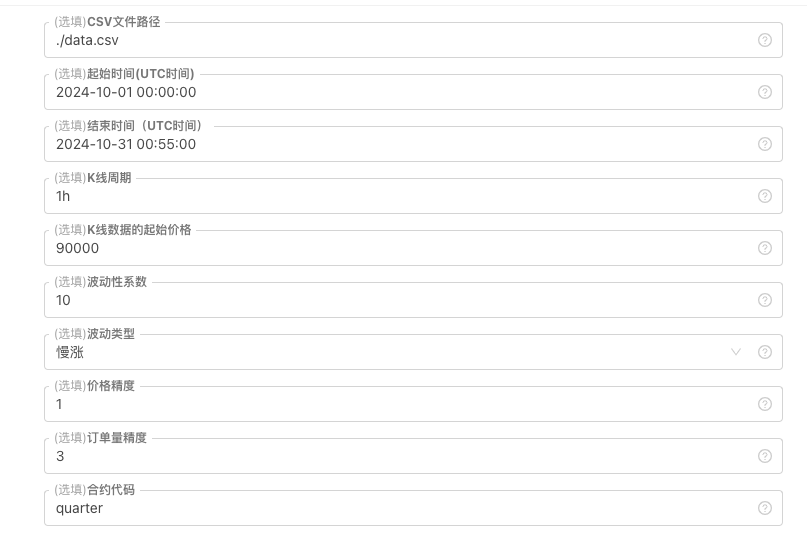
-
تصادفی طور پر تیار کردہ ڈیٹا پیٹرن
K-line ڈیٹا کے اتار چڑھاؤ کی قسم کو بنانے کے لیے، مثبت اور منفی بے ترتیب نمبروں کے مختلف احتمالات کا استعمال کرتے ہوئے ایک سادہ ڈیزائن کیا جاتا ہے جب تیار کردہ ڈیٹا بڑا نہیں ہوتا ہے، مطلوبہ مارکیٹ پیٹرن ظاہر نہیں ہوتا ہے۔ اگر کوئی بہتر طریقہ ہے تو، آپ کوڈ کے اس حصے کو بدل سکتے ہیں۔
اس سادہ ڈیزائن کی بنیاد پر، کوڈ میں رینڈم نمبر جنریشن رینج اور کچھ گتانکوں کو ایڈجسٹ کرنے سے پیدا کردہ ڈیٹا اثر متاثر ہو سکتا ہے۔ -
ڈیٹا کی تصدیق
تیار کردہ K-line ڈیٹا کو بھی معقولیت کے لیے چیک کرنے کی ضرورت ہے، یہ چیک کرنے کے لیے کہ آیا زیادہ اوپننگ اور کم بند ہونے والی قیمتیں تعریف کی خلاف ورزی کرتی ہیں، K-line ڈیٹا کے تسلسل کو چیک کرنے کے لیے وغیرہ۔
بیک ٹیسٹنگ سسٹم رینڈم کوٹ جنریٹر
python
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据data.detail:", data["detail"], "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("不支持的K线周期,请使用 'm', 'h', 或 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("异常数据:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("当前路径:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("文件写入成功,以下是文件内容的一部分:")
Log("".join(lines[:5]))
else:
Log("文件写入失败,文件为空!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("开启自定义数据源服务线程,数据由CSV文件提供。", ", 地址/端口:0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("生成器参数:", "起始时间:", startTime, "结束时间:", endTime, "K线周期:", KLinePeriod, "初始价格:", firstPrice, "波动类型:", arrTrendType[trendType], "波动性系数:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
بیک ٹیسٹنگ سسٹم میں مشق کریں۔
- مندرجہ بالا پالیسی مثال بنائیں، پیرامیٹرز کو ترتیب دیں، اور اسے چلائیں۔
- حقیقی مارکیٹ (حکمت عملی کی مثال) کو سرور پر تعینات میزبان پر چلانے کی ضرورت ہے، کیونکہ بیک ٹیسٹنگ سسٹم کو اس تک رسائی اور ڈیٹا حاصل کرنے کے لیے ایک عوامی IP کی ضرورت ہوتی ہے۔
- انٹرایکٹو بٹن پر کلک کریں اور حکمت عملی خود بخود بے ترتیب مارکیٹ ڈیٹا تیار کرنا شروع کر دے گی۔

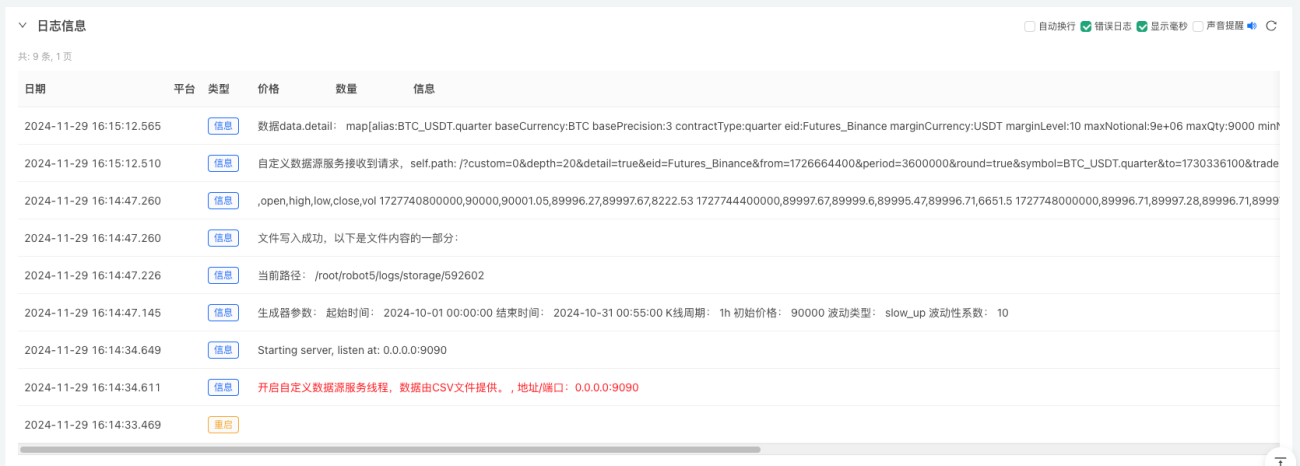
- آسانی سے مشاہدے کے لیے تیار کردہ ڈیٹا کو چارٹ پر دکھایا جائے گا، اور ڈیٹا کو مقامی data.csv فائل میں ریکارڈ کیا جائے گا۔
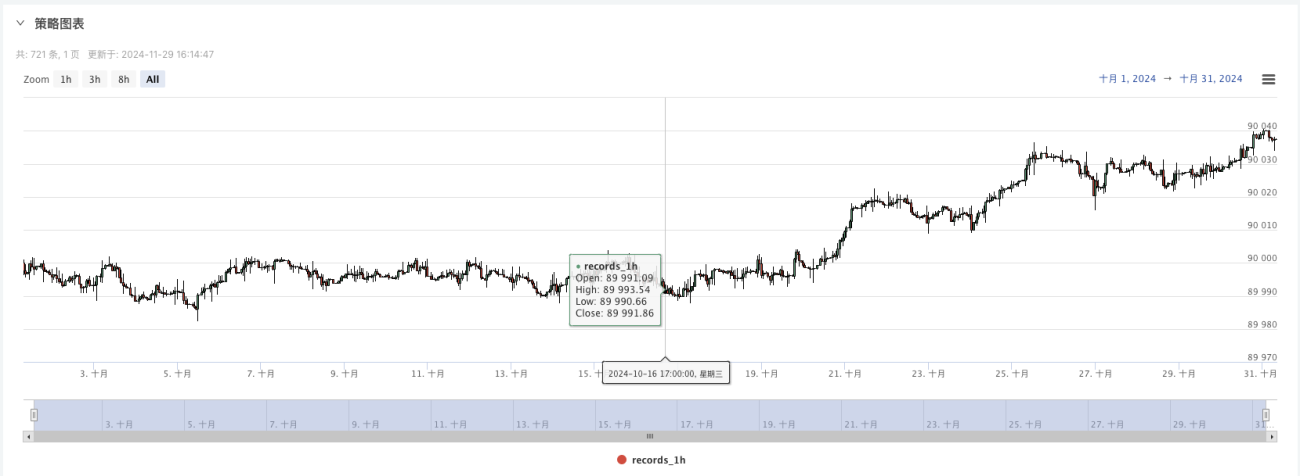
- اب ہم اس تصادفی طور پر تیار کردہ ڈیٹا کو استعمال کر سکتے ہیں اور بیک ٹیسٹنگ کے لیے کوئی بھی حکمت عملی استعمال کر سکتے ہیں۔
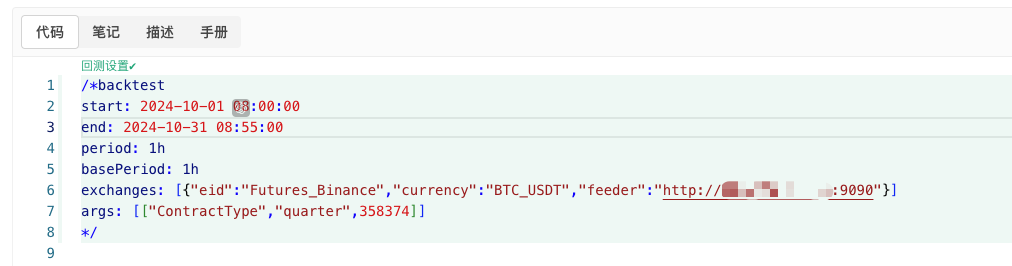
/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
مندرجہ بالا معلومات کے مطابق ترتیب دیں اور مخصوص ایڈجسٹمنٹ کریں۔http://xxx.xxx.xxx.xxx:9090یہ سرور کا آئی پی ایڈریس اور رینڈم مارکیٹ جنریشن اسٹریٹجی اصلی ڈسک کا اوپن پورٹ ہے۔
یہ ایک حسب ضرورت ڈیٹا سورس ہے مزید معلومات کے لیے آپ پلیٹ فارم API دستاویزات میں حسب ضرورت ڈیٹا سورس کا حوالہ دے سکتے ہیں۔
- بیک ٹیسٹ سسٹم ڈیٹا سورس کو سیٹ کرنے کے بعد، آپ بے ترتیب مارکیٹ ڈیٹا کی جانچ کر سکتے ہیں۔
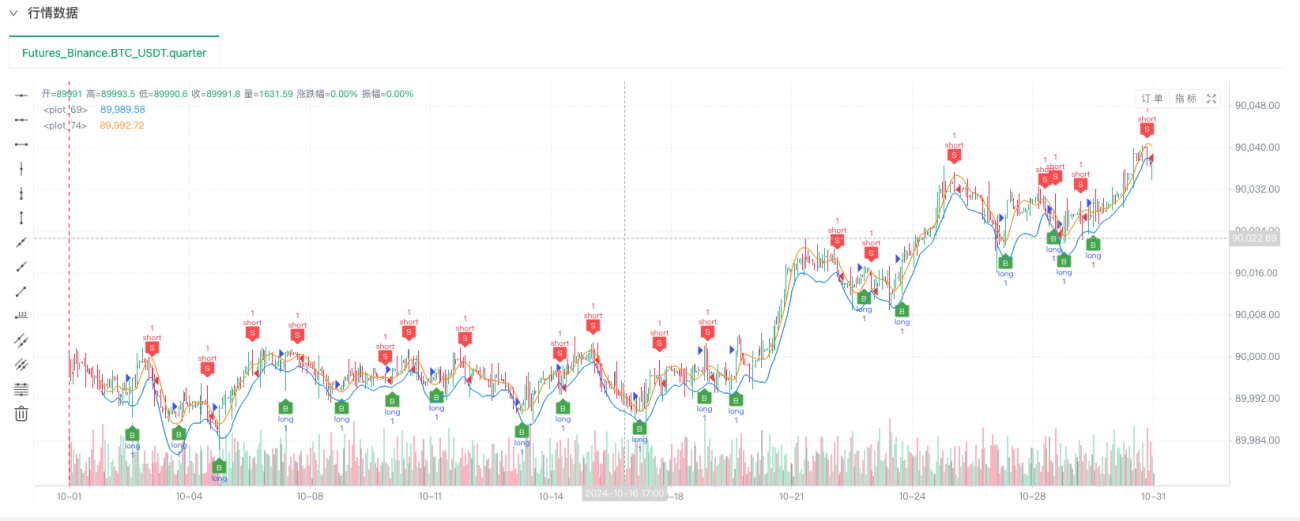
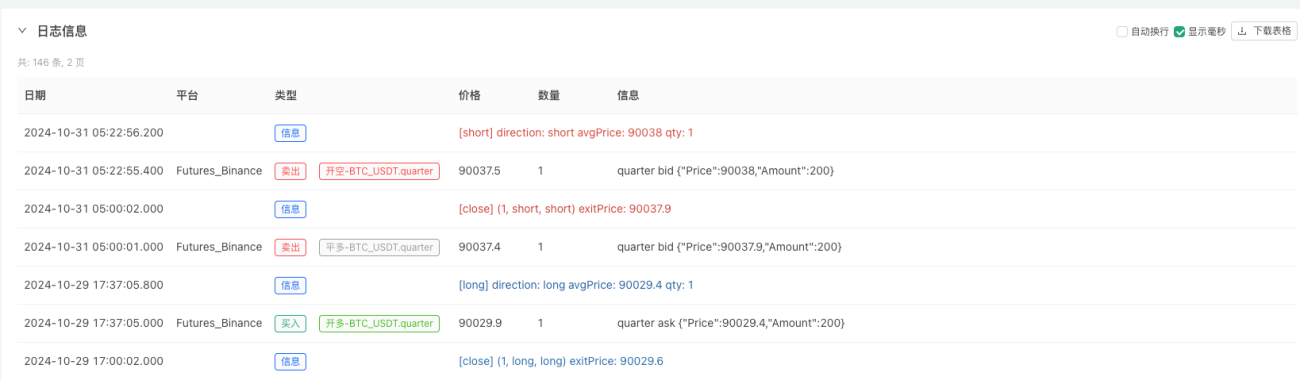
اس مقام پر، ہمارے "من گھڑت" نقلی ڈیٹا کا استعمال کرتے ہوئے بیک ٹیسٹنگ سسٹم کی جانچ کی جاتی ہے۔ بیک ٹیسٹ کے دوران مارکیٹ چارٹ میں موجود ڈیٹا کے مطابق، مارکیٹ کے بے ترتیب حالات سے تیار کردہ ڈیٹا کا موازنہ کریں، 16 اکتوبر 2024 کا وقت 17:00 ہے۔ ڈیٹا ایک جیسا ہے۔
- اوہ ہاں، میں یہ کہنا تقریباً بھول گیا تھا! یہ بے ترتیب مارکیٹ جنریٹر Python پروگرام ایک حقیقی مارکیٹ بنانے کی وجہ پیدا کردہ K-line ڈیٹا کے مظاہرے، آپریشن اور ڈسپلے میں سہولت فراہم کرنا ہے۔ اصل ایپلی کیشن میں، آپ ایک آزاد ازگر اسکرپٹ لکھ سکتے ہیں، لہذا آپ کو اصل ڈسک چلانے کی ضرورت نہیں ہے۔
حکمت عملی کا ماخذ کوڈ:بیک ٹیسٹنگ سسٹم رینڈم کوٹ جنریٹر
آپ کی حمایت اور پڑھنے کے لیے آپ کا شکریہ۔
- 1