

بالغ درجہ بندی: سپورٹ ویکٹر مشین (SVM) ایک طاقتور اور بالغ بائنری (یا ملٹی ویریٹ) درجہ بندی الگورتھم ہے۔ یہ پیش گوئی کرنا کہ آیا اسٹاک بڑھے گا یا گرے گا ایک عام بائنری درجہ بندی کا مسئلہ ہے۔
غیر خطی صلاحیت: کرنل فنکشنز (جیسے RBF کرنل) کا استعمال کرتے ہوئے، SVM ان پٹ فیچرز کے درمیان پیچیدہ نان لائنر تعلقات کو حاصل کر سکتا ہے، جو کہ مالیاتی مارکیٹ کے ڈیٹا کے لیے اہم ہے۔
فیچر پر مبنی: ماڈل کی تاثیر کا انحصار زیادہ تر ان "خصوصیات" پر ہوتا ہے جو آپ اسے کھلاتے ہیں۔ اب جو الفا فیکٹر کا حساب لگایا گیا ہے وہ ایک اچھی شروعات ہے، اور ہم پیشین گوئی کی طاقت کو بہتر بنانے کے لیے ایسی مزید خصوصیات بنا سکتے ہیں۔
اس بار میں نے 3 خصوصیت کے خاکہ کے ساتھ آغاز کیا:
1: اعلی تعدد آرڈر کے بہاؤ کی خصوصیات:
alpha_1min: آرڈر کے بہاؤ کے عدم توازن کے عنصر کا حساب گزشتہ منٹ میں تمام ٹک کی بنیاد پر کیا جاتا ہے۔
alpha_5min: آرڈر کے بہاؤ کے عدم توازن کے عنصر کا حساب گزشتہ 5 منٹ میں تمام ٹک ٹکوں کی بنیاد پر کیا جاتا ہے۔
alpha_15min: آرڈر کے بہاؤ کے عدم توازن کے عنصر کا حساب پچھلے 15 منٹ میں تمام ٹک کی بنیاد پر کیا جاتا ہے۔
ofi_1min (آرڈر فلو کا عدم توازن): 1 منٹ کی مدت کے اندر (حجم خریدنا/فروخت کرنا) کا تناسب۔ یہ الفا سے زیادہ سیدھا ہے۔
vol_per_trade_1min: اوسط حجم فی تجارت 1 منٹ کے اندر۔ مارکیٹ کو متاثر کرنے والے بڑے آرڈرز کی علامت۔
2: قیمت اور اتار چڑھاؤ کی خصوصیات:
log_return_5min: پچھلے 5 منٹ کے دوران لاگرتھمک واپسی کی شرح، log(P_t / P_{t-5min})۔
volatility_15min: لاگ کا معیاری انحراف پچھلے 15 منٹوں میں واپس آتا ہے، جو کہ قلیل مدتی اتار چڑھاؤ کا ایک پیمانہ ہے۔
atr_14 (اوسط صحیح رینج): ATR قدر گزشتہ 14 1 منٹ کی موم بتیوں پر مبنی، ایک کلاسک اتار چڑھاؤ کا اشارہ۔
rsi_14 (رشتہ دار طاقت کا اشاریہ): یہ گزشتہ 14 1 منٹ کی کینڈل اسٹکس کی RSI اقدار کی بنیاد پر زیادہ خریدی ہوئی اور زیادہ فروخت ہونے والی شرائط کا پیمانہ ہے۔
3: وقت کی خصوصیات:
دن کا_گھنٹہ: موجودہ گھنٹہ (0-23)۔ مارکیٹس مختلف اوقات میں مختلف طریقے سے برتاؤ کرتی ہیں (مثلاً، ایشیائی/یورپی/امریکی سیشنز)۔
ہفتے کا_دن: ہفتے کا دن (0-6)۔ اختتام ہفتہ اور ہفتے کے دنوں میں مختلف اتار چڑھاؤ کے نمونے ہوتے ہیں۔
def calculate_features_and_labels(klines):
"""
核心函数
"""
features = []
labels = []
# 为了计算RSI等指标,我们需要价格序列
close_prices = [k['close'] for k in klines]
# 从第30根K线开始,因为需要足够的前置数据
for i in range(30, len(klines) - PREDICT_HORIZON):
# 1. 价格与波动率特征
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
# 计算RSI
diffs = np.diff(close_prices[i-14:i+1])
gains = np.sum(diffs[diffs > 0]) / 14
losses = -np.sum(diffs[diffs < 0]) / 14
rs = gains / (losses + 1e-10)
rsi_14 = 100 - (100 / (1 + rs))
# 2. 时间特征
dt_object = datetime.fromtimestamp(klines[i]['ts'] / 1000)
hour_of_day = dt_object.hour
day_of_week = dt_object.weekday()
# 组合所有特征
current_features = [price_change_15m, volatility_30m, rsi_14, hour_of_day, day_of_week]
features.append(current_features)
# 3. 数据标注
future_price = klines[i + PREDICT_HORIZON]['close']
current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD):
labels.append(0) # 涨
elif future_price < current_price * (1 - SPREAD_THRESHOLD):
labels.append(1) # 跌
else:
labels.append(2) # 横盘
پھر اٹھنے، گرنے اور کنارے کے درمیان فرق کرنے کے لیے تین زمرے استعمال کریں۔
فیچر اسکریننگ کا بنیادی خیال: "اچھے ساتھی ساتھی" تلاش کریں اور "برے ساتھی" کو ختم کریں۔
ہمارا مقصد خصوصیات کا ایک مجموعہ تلاش کرنا ہے جو:
- اعلیٰ مطابقت: ہر خصوصیت کا مستقبل کی قیمتوں میں ہونے والی تبدیلیوں (ہمارا ہدف کا لیبل) کے ساتھ مضبوط تعلق ہے۔
- کم فالتو پن: خصوصیات میں بہت زیادہ ڈپلیکیٹ معلومات نہیں ہونی چاہئیں۔ مثال کے طور پر، "5 منٹ کی رفتار" اور "6 منٹ کی رفتار" بہت ملتی جلتی ہے۔ دونوں کو شامل کرنے سے ماڈل میں زیادہ بہتری نہیں آئے گی اور شور بھی متعارف کرایا جا سکتا ہے۔
- استحکام: کسی خصوصیت کی درستگی وقت کے ساتھ بہت تیزی سے تبدیل نہیں ہو سکتی۔ ایک خصوصیت جو صرف ایک دن درست ہے خطرناک ہے۔
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
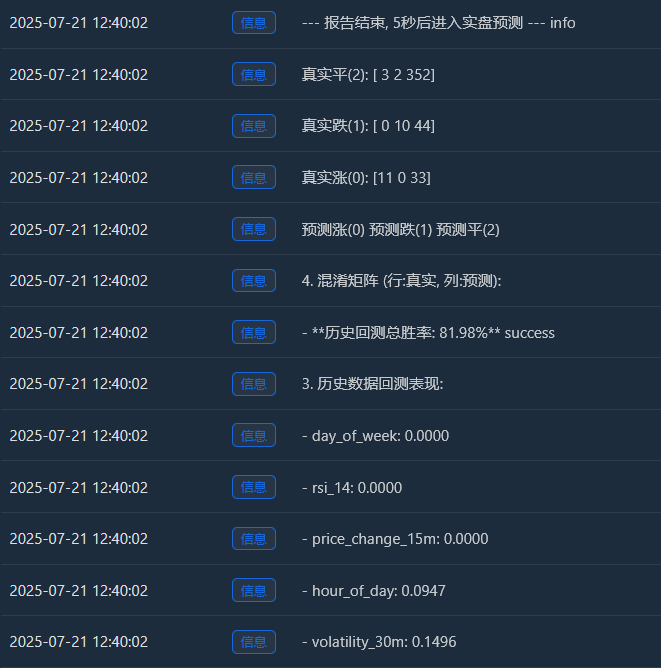
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1) 预测平(2)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0,0]}"); Log(f"真实平(2): {cm[2] if len(cm) > 2 else [0,0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i] and y[i] != 2: balance *= (1 + 0.01)
elif y_pred[i] != y[i] and y_pred[i] != 2: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
عمل یہ ہے:
ڈیٹا اکٹھا کرنا
خصوصیت کی اہمیت

خصوصیات اور لیبلز اور بیک ٹیسٹ معلومات کے درمیان باہمی معلومات
میں نے اصل میں سوچا تھا کہ جیت کی شرح 65% کافی ہو گی، لیکن مجھے امید نہیں تھی کہ یہ 81.98% تک پہنچ جائے گی۔ میرا پہلا ردعمل ہونا چاہئے: "یہ بہت اچھا ہے، لیکن یہ سچ ہونا بہت اچھا ہے۔ یہاں تلاش کرنے کے قابل کچھ ہونا چاہئے۔"
1. تجزیہ رپورٹ کی گہرائی سے تشریح، رپورٹ کے مواد کی ایک ایک کرکے تشریح:
- خصوصیت کی اہمیت اور باہمی معلومات:
اتار چڑھاؤ_30m اور price_change_15m سب سے اہم خصوصیات ہیں۔ یہ منطقی ہے، اس بات کی نشاندہی کرتا ہے کہ مارکیٹ کا حالیہ رجحان اور اتار چڑھاؤ مستقبل کے سب سے مضبوط پیش گو ہیں۔
دن کا_گھنٹہ بھی تھوڑا سا حصہ ڈالتا ہے، جس سے یہ ظاہر ہوتا ہے کہ ماڈل دن کے مختلف اوقات میں ٹریڈنگ پیٹرن کو پکڑتا ہے۔
rsi_14 اور day_of_week کی شراکتیں تقریباً 0 ہیں، جس سے پتہ چلتا ہے کہ موجودہ ڈیٹا سیٹ اور فیچر کے امتزاج کے تحت یہ دونوں خصوصیات "پگ ٹیم میٹس" ہو سکتی ہیں۔ ہم ماڈل کو آسان بنانے اور شور کو روکنے کے لیے مستقبل میں انہیں ہٹانے پر غور کر سکتے ہیں۔ - کنفیوژن میٹرکس (یہ بہت سی معلومات ہے!)
حقیقی اضافہ (0):[11 0 33] -> 44 (11+0+33) حقیقی ریلیوں میں سے، ماڈل نے صحیح طور پر 11 کی پیشین گوئی کی، لیکن 33 بار اسے "مضبوطی" کے طور پر غلط انداز میں پیش کیا۔
حقیقی کمی (1):[0 10 44] -> 54 میں سے (0+10+44) حقیقی کمی، ماڈل نے 10 کی درست پیشین گوئی کی، لیکن 44 بار "سائیڈ وے ٹرینڈ" کے طور پر غلط پیش گوئی کی۔
اصلی پنگ (2):[3 2 352] -> 357 (3+2+352) میں سے حقیقی یکجہتی، ماڈل نے ان میں سے 352 کی درست پیش گوئی کی! - تاریخی بیک ٹیسٹ کل جیت کی شرح: 81.98%
اس اعلیٰ جیتنے کی شرح کا بنیادی ماخذ ماڈل کی پیشین گوئی میں انتہائی اعلیٰ درستگی ہے۔ کل تقریباً 455 نمونوں میں سے، 350 سے زیادہ کنسولیڈیشن مارکیٹس تھے، اور ماڈل نے ان کی شناخت تقریباً مکمل طور پر کی۔
یہ اپنے آپ میں ایک بہت قیمتی صلاحیت ہے! ایک ماڈل جو آپ کو درست طریقے سے بتا سکتا ہے کہ "ابھی منتقل نہ کرنا بہتر ہے" آپ کو بہت ساری فیسوں اور غلط لین دین کو بچانے میں مدد کر سکتا ہے۔
2جیتنے کی اصل شرح 81.98% سے کم کیوں ہو سکتی ہے؟
- "استحکام" کی تعریف بہت ڈھیلی ہے: ہمارا SPREAD_THRESHOLD 0.5% ہے۔ 15 منٹ کی مدت میں قیمتوں میں 0.5% سے زیادہ کا اتار چڑھاو کافی عام ہے۔ نتیجے کے طور پر، ہمارے ڈیٹاسیٹ کی بڑی اکثریت (تقریباً 80%) کے لیے "مضبوطی" کے نمونے ہیں۔ ماڈل نے چالاکی سے سیکھا ہے، "جب مجھے یقین نہ ہو تو، اعلیٰ درستگی کے ساتھ 'مضبوطی' کا اندازہ لگائیں۔" یہ اعداد و شمار کے لحاظ سے درست ہے، لیکن تجارت میں، ہم قیمت کی نقل و حرکت کی پیشن گوئی کرنے کے بارے میں زیادہ فکر مند ہیں۔
- عروج و زوال کی پیشین گوئی کرنے کی صلاحیت:
پیشین گوئی کرنے والے اپ ٹرینڈز کی جیت کی شرح: ماڈل نے 11 + 0 + 3 = 14 اپ ٹرینڈز کی پیشین گوئی کی، جن میں سے صرف 11 درست تھے۔ جیت کی شرح 11/14 = 78.5% ہے۔ بہترین!
پیشین گوئی میں کمی کی شرح جیت: ماڈل نے 0 + 10 + 2 = 12 کمی کی پیشین گوئی کی، اور ان میں سے 10 درست تھیں۔ جیت کی شرح 10/12 = 83.3% ہے۔ ایک بار پھر، بہت متاثر کن! - ان-سیمپل اوور فٹنگ: یہ ٹیسٹ اس ڈیٹا پر کیا جاتا ہے جو ماڈل کو "معلوم" ہے (یعنی تربیت اور جانچ کے لیے استعمال ہونے والا ڈیٹا)۔ یہ ایسا ہی ہے جیسے کسی طالب علم سے ایک ٹیسٹ کرنے کے لیے جو اس نے ابھی مکمل کیا ہو۔ سکور عام طور پر زیادہ ہو گا. نئے، ان دیکھے ڈیٹا (لائیو ٹریڈنگ) پر ماڈل کی کارکردگی تقریباً ہمیشہ اس اسکور سے کم رہے گی۔
ہمارے پاس اب ایک ابتدائی، لیکن ممکنہ طور پر بہت بڑا، "الفا ماڈل" ہے۔ اگرچہ ہم 81.98% اعداد و شمار کو مستقبل کے لیے ایک حقیقت پسندانہ پیشین گوئی کے طور پر براہِ راست تشریح نہیں کر سکتے، لیکن یہ ایک مضبوط مثبت اشارہ ہے، جو یہ ظاہر کرتا ہے کہ اعداد و شمار میں پیشین گوئی کے قابل نمونے موجود ہیں، اور یہ کہ ہمارے فریم ورک نے کامیابی کے ساتھ ان پر قبضہ کر لیا ہے!
ہمیں اب ایسا لگتا ہے کہ ہمیں ابھی پہاڑ کے دامن میں اعلیٰ قسم کے سونے کی دھات کا پہلا ٹکڑا ملا ہے۔ ہمارا اگلا مرحلہ اسے فوری طور پر فروخت کرنا نہیں ہے، بلکہ پورے پہاڑ کو زیادہ موثر اور مستحکم طریقے سے کان کرنے کے لیے مزید خصوصی آلات اور تکنیکوں (خصوصیات کو بہتر بنانا اور پیرامیٹرز کو ایڈجسٹ کرنا) کا استعمال کرنا ہے۔
آئیے اب جنگ کی دھند کو "مائیکروکوسم" میں متعارف کراتے ہیں - آرڈر کا بہاؤ اور آرڈر بک کی خصوصیات
مرحلہ 1: ڈیٹا اکٹھا کرنا اپ گریڈ کریں - گہرے چینلز کو سبسکرائب کریں۔
آرڈر بک ڈیٹا حاصل کرنے کے لیے، WebSocket کنکشن کے طریقہ کار کو صرف aggTrade (سودے) کو سبسکرائب کرنے سے لے کر aggTrade اور گہرائی (گہرائی) دونوں کو سبسکرائب کرنے کے لیے تبدیل کیا جانا چاہیے۔
اس کے لیے ہم سے زیادہ عام ملٹی اسٹریم سبسکرپشن URL استعمال کرنے کی ضرورت ہے۔
مرحلہ 2: فیچر انجینئرنگ کو اپ گریڈ کریں - "سمندر، زمین اور ہوا" کے لیے تثلیث فیچر میٹرکس بنائیں
ہم calculate_features_and_labels فنکشن میں درج ذیل نئی خصوصیات شامل کریں گے:
- آرڈر کے بہاؤ کی خصوصیات (الفا - مختصر):
alpha_15m: 15 منٹ کے آرڈر کے بہاؤ میں عدم توازن کا عنصر۔ یہ بنیادی آرڈر فلو میٹرک ہے جس پر ہم نے پہلے بات کی تھی۔ - آرڈر بک کی خصوصیات (کتاب - فوج):
wobi_10s: پچھلے 10 سیکنڈز میں وزنی آرڈر بک کا عدم توازن۔ یہ ایک بہت ہی اعلی تعدد انڈیکیٹر ہے جو مارکیٹ پر خرید و فروخت کے دباؤ کی پیمائش کرتا ہے۔
پھیلاؤ_10s: گزشتہ 10 سیکنڈز میں پھیلی ہوئی بولی کا اوسط۔ قلیل مدتی لیکویڈیٹی کی عکاسی کرتا ہے۔ - اصل خصوصیات (قیمت - بحریہ):
ہم پچھلے ورژن سے بہترین کارکردگی دکھانے والی خصوصیات کو برقرار رکھیں گے اور انہیں بہتر بنائیں گے۔
یہ نیا فیچر میٹرکس ایک مشترکہ جنگی کمانڈ کی طرح ہے، جو بیک وقت "سمندر (قیمت کے رجحانات)"، "زمین (مارکیٹ کی پوزیشنز)" اور "ہوا (لین دین کے اثرات)" سے حقیقی وقت کی ذہانت کو سمجھتا ہے، اور اس کی فیصلہ سازی کی صلاحیتیں پہلے سے کہیں زیادہ بہتر ہوں گی۔
کوڈ درج ذیل ہے:
import json
import math
import time
import websocket
import threading
from datetime import datetime
import numpy as np
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.feature_selection import mutual_info_classif
from sklearn.ensemble import RandomForestClassifier
# ========== 全局配置 ==========
TRAIN_BARS = 100
PREDICT_HORIZON = 15
SPREAD_THRESHOLD = 0.005
SYMBOL_FMZ = "ETH_USDT"
SYMBOL_API = SYMBOL_FMZ.replace('_', '').lower()
WEBSOCKET_URL = f"wss://fstream.binance.com/stream?streams={SYMBOL_API}@aggTrade/{SYMBOL_API}@depth20@100ms"
# ========== 全局状态变量 ==========
g_model, g_scaler = None, None
g_klines_1min, g_ticks, g_order_book_history = [], [], []
g_last_kline_ts = 0
g_feature_names = ['price_change_15m', 'volatility_30m', 'rsi_14', 'hour_of_day',
'alpha_15m', 'wobi_10s', 'spread_10s']
# ========== 特征工程与模型训练 ==========
def calculate_features_and_labels(klines, ticks, order_books_history, is_realtime=False):
features, labels = [], []
close_prices = [k['close'] for k in klines]
# 根据是训练还是实时预测,决定循环范围
start_index = 30
end_index = len(klines) - PREDICT_HORIZON if not is_realtime else len(klines)
for i in range(start_index, end_index):
kline_start_ts = klines[i]['ts']
# --- 特征计算部分 ---
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
diffs = np.diff(close_prices[i-14:i+1]); gains = np.sum(diffs[diffs > 0]) / 14; losses = -np.sum(diffs[diffs < 0]) / 14
rsi_14 = 100 - (100 / (1 + gains / (losses + 1e-10)))
dt_object = datetime.fromtimestamp(kline_start_ts / 1000)
ticks_in_15m = [t for t in ticks if t['ts'] >= klines[i-15]['ts'] and t['ts'] < kline_start_ts]
buy_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'buy'); sell_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'sell')
alpha_15m = (buy_vol - sell_vol) / (buy_vol + sell_vol + 1e-10)
books_in_10s = [b for b in order_books_history if b['ts'] >= kline_start_ts - 10000 and b['ts'] < kline_start_ts]
if not books_in_10s: wobi_10s, spread_10s = 0, 0.0
else:
wobis, spreads = [], []
for book in books_in_10s:
if not book['bids'] or not book['asks']: continue
bid_vol = sum(float(p[1]) for p in book['bids']); ask_vol = sum(float(p[1]) for p in book['asks'])
wobis.append(bid_vol / (bid_vol + ask_vol + 1e-10))
spreads.append(float(book['asks'][0][0]) - float(book['bids'][0][0]))
wobi_10s = np.mean(wobis) if wobis else 0; spread_10s = np.mean(spreads) if spreads else 0
current_features = [price_change_15m, volatility_30m, rsi_14, dt_object.hour, alpha_15m, wobi_10s, spread_10s]
features.append(current_features)
# --- 标签计算部分 ---
if not is_realtime:
future_price = klines[i + PREDICT_HORIZON]['close']; current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD): labels.append(0)
elif future_price < current_price * (1 - SPREAD_THRESHOLD): labels.append(1)
else: labels.append(2)
return np.array(features), np.array(labels)
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1) 预测平(2)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0,0]}"); Log(f"真实平(2): {cm[2] if len(cm) > 2 else [0,0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i] and y[i] != 2: balance *= (1 + 0.01)
elif y_pred[i] != y[i] and y_pred[i] != 2: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
def train_and_analyze():
global g_model, g_scaler, g_klines_1min, g_ticks, g_order_book_history
MIN_REQUIRED_BARS = 30 + PREDICT_HORIZON
if len(g_klines_1min) < MIN_REQUIRED_BARS:
Log(f"K线数量({len(g_klines_1min)})不足以进行特征工程,需要至少 {MIN_REQUIRED_BARS} 根。", "warning"); return False
Log("开始训练模型 (V2.2)...")
X, y = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history)
if len(X) < 50 or len(set(y)) < 3:
Log(f"有效训练样本不足(X: {len(X)}, 类别: {len(set(y))}),无法训练。", "warning"); return False
scaler = StandardScaler(); X_scaled = scaler.fit_transform(X)
clf = svm.SVC(kernel='rbf', C=1.0, gamma='scale'); clf.fit(X_scaled, y)
g_model, g_scaler = clf, scaler
Log("模型训练完成!", "success")
run_analysis_report(X, y, g_model, g_scaler)
return True
def aggregate_ticks_to_kline(ticks):
if not ticks: return None
return {'ts': ticks[0]['ts'] // 60000 * 60000, 'open': ticks[0]['price'], 'high': max(t['price'] for t in ticks), 'low': min(t['price'] for t in ticks), 'close': ticks[-1]['price'], 'volume': sum(t['qty'] for t in ticks)}
def on_message(ws, message):
global g_ticks, g_klines_1min, g_last_kline_ts, g_order_book_history
try:
payload = json.loads(message)
data = payload.get('data', {}); stream = payload.get('stream', '')
if 'aggTrade' in stream:
trade_data = {'ts': int(data['T']), 'price': float(data['p']), 'qty': float(data['q']), 'side': 'sell' if data['m'] else 'buy'}
g_ticks.append(trade_data)
current_minute_ts = trade_data['ts'] // 60000 * 60000
if g_last_kline_ts == 0: g_last_kline_ts = current_minute_ts
if current_minute_ts > g_last_kline_ts:
last_minute_ticks = [t for t in g_ticks if t['ts'] >= g_last_kline_ts and t['ts'] < current_minute_ts]
if last_minute_ticks:
kline = aggregate_ticks_to_kline(last_minute_ticks); g_klines_1min.append(kline)
g_ticks = [t for t in g_ticks if t['ts'] >= current_minute_ts]
g_last_kline_ts = current_minute_ts
elif 'depth' in stream:
book_snapshot = {'ts': int(data['E']), 'bids': data['b'], 'asks': data['a']}
g_order_book_history.append(book_snapshot)
if len(g_order_book_history) > 5000: g_order_book_history.pop(0)
except Exception as e: Log(f"OnMessage Error: {e}")
def start_websocket():
ws = websocket.WebSocketApp(WEBSOCKET_URL, on_message=on_message)
wst = threading.Thread(target=ws.run_forever); wst.daemon = True; wst.start()
Log("WebSocket多流订阅已启动...")
# ========== 主程序入口 ==========
def main():
global TRAIN_BARS
exchange.SetContractType("swap")
start_websocket()
Log("策略启动,进入数据收集中...")
main.last_predict_ts = 0
while True:
if g_model is None:
# --- 训练模式 ---
if len(g_klines_1min) >= TRAIN_BARS:
if not train_and_analyze():
Log("模型训练或分析失败,将增加50根K线后重试...", "error")
TRAIN_BARS += 50
else:
LogStatus(f"正在收集K线数据: {len(g_klines_1min)} / {TRAIN_BARS}")
else:
# --- **新功能:实时预测模式** ---
if len(g_klines_1min) > 0 and g_klines_1min[-1]['ts'] > main.last_predict_ts:
# 1. 标记已处理,防止重复预测
main.last_predict_ts = g_klines_1min[-1]['ts']
kline_time_str = datetime.fromtimestamp(main.last_predict_ts / 1000).strftime('%H:%M:%S')
Log(f"检测到新K线 ({kline_time_str}),准备进行实时预测...")
# 2. 检查是否有足够历史数据来为这根新K线计算特征
if len(g_klines_1min) < 30: # 至少需要30根历史K线
Log("历史K线不足,无法为当前新K线计算特征。", "warning")
continue
# 3. 计算最新K线的特征
# 我们只计算最后一条数据,所以传入 is_realtime=True
latest_features, _ = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history, is_realtime=True)
if latest_features.shape[0] == 0:
Log("无法为最新K线生成有效特征。", "warning")
continue
# 4. 标准化并预测
last_feature_vector = latest_features[-1].reshape(1, -1)
last_feature_scaled = g_scaler.transform(last_feature_vector)
prediction = g_model.predict(last_feature_scaled)[0]
# 5. 展示预测结果
prediction_text = ['**上涨**', '**下跌**', '盘整'][prediction]
Log(f"==> 实时预测结果 ({kline_time_str}): 未来 {PREDICT_HORIZON} 分钟可能 {prediction_text}", "success" if prediction != 2 else "info")
# 在这里,您可以根据 prediction 的结果,添加您的开平仓交易逻辑
# 例如: if prediction == 0: exchange.Buy(...)
else:
LogStatus(f"模型已就绪,等待新K线... 当前K线数: {len(g_klines_1min)}")
Sleep(1000) # 每秒检查一次是否有新K线
اس کوڈ کے لیے بہت سارے K-line حساب کی ضرورت ہے۔
یہ رپورٹ ایک خوش قسمتی کے قابل ہے، کیونکہ یہ ہمیں ماڈل کی "سوچ" اور "کردار" بتاتی ہے۔
- تاریخی بیک ٹیسٹنگ کل جیت کی شرح: 93.33%
یہ ایک انتہائی متاثر کن نمبر ہے! جب کہ ہمیں اسے معروضی طور پر دیکھنے کی ضرورت ہے (یہ ایک نمونہ ٹیسٹ ہے)، یہ ہمارے نئے شامل کردہ آرڈر فلو اور آرڈر بک کی خصوصیات کی بے پناہ پیش گوئی کی طاقت کو واضح طور پر ظاہر کرتا ہے! ماڈل کو تاریخی اعداد و شمار میں بہت مضبوط نمونے ملے ہیں۔ - خصوصیت کی اہمیت اور باہمی معلومات
بادشاہ پیدا ہوا ہے: volatility_15m (متزلزل) اور price_change_5m (قیمت میں تبدیلی) اب بھی بالکل بنیادی ہیں، جو کہ توقع کے مطابق ہے۔
ابھرتا ہوا ستارہ: rsi_14 کی اہمیت میں نمایاں اضافہ دیکھا گیا ہے! اس سے ظاہر ہوتا ہے کہ 5 منٹ کے مختصر ٹائم فریم پر، RSI کا "زیادہ خریدا ہوا/اوور سیلڈ" جذباتی اشارے زیادہ معنی خیز ہو گیا ہے۔
ممکنہ طور پر، wobi_10s (آرڈر بک عدم توازن) اور اسپریڈ_10s (پھیلاؤ) بھی کچھ حصہ دکھاتے ہیں۔ یہ بہت حوصلہ افزا ہے اور تجویز کرتا ہے کہ ہماری مائیکرو اسٹرکچر کی خصوصیات کام کرنا شروع کر رہی ہیں!
عکاسی: alpha_5m (آرڈر فلو) کی شراکت تقریبا صفر ہے۔ یہ ہمارے الفا کیلکولیشن کے طریقہ کار کی حد سے زیادہ آسان ہونے کی وجہ سے ہو سکتا ہے، یا 5 منٹ کے الفا اور 5 منٹ کی قیمت میں تبدیلی خود بہت زیادہ اوور لیپنگ معلومات پر مشتمل ہے۔ یہ مستقبل میں ہمارے لیے ایک اہم اصلاحی نقطہ ہے۔ - کنفیوژن میٹرکس (کامیابی کا اہم ثبوت!)
حقیقی اضافہ (0):[22 0] -> تمام 22 حقیقی ریلیوں میں، ماڈل نے بغیر کسی غلطی کے ان کی 100% درست پیش گوئی کی!
حقیقی کمی (1):[2 6] -> 8 اصل کمیوں میں سے، ماڈل نے صحیح طور پر 6 کی پیشین گوئی کی اور 2 چھوٹ گئے (ان میں اضافہ کے لیے غلطی کرتے ہوئے)۔
تشریح: یہ ماڈل ایک بہت ہی دلچسپ شخصیت کی نمائش کرتا ہے: یہ ایک انتہائی مضبوط تیزی کا پتہ لگانے والا ہے، جو تیزی کے سگنل کو تقریباً مکمل طور پر پکڑتا ہے۔ یہ مندی کے رجحانات کی نشاندہی کرنے میں بھی اچھی کارکردگی کا مظاہرہ کرتا ہے (6/8 = 75% درستگی)، لیکن کبھی کبھار اوپری رجحان کے لیے بیئرش رجحان کو سمجھنے کی غلطی کرتا ہے۔
پھر آگے کیا آتا ہے۔
"ٹریڈنگ سگنل اسٹیٹ مشین" کا تعارف
یہ اس اپ گریڈ کا بنیادی اور سب سے ذہین حصہ ہے۔ ہم حکمت عملی کی موجودہ "پوزیشن" کی حیثیت کو منظم کرنے کے لیے ایک عالمی ریاستی متغیر، جیسے g_active_signal متعارف کرائیں گے (نوٹ کریں کہ یہ صرف ایک ورچوئل پوزیشن کی حیثیت ہے اور اس میں حقیقی تجارت شامل نہیں ہے)۔
اس ریاستی مشین کی ورکنگ منطق مندرجہ ذیل ہے:
- ابتدائی حالت: بیکار
- جب حکمت عملی اس حالت میں ہوگی، تو یہ ہر نئی K-لائن کے لیے پیشین گوئیاں کرے گی، بالکل اسی طرح جیسے یہ اب کرتی ہے۔
- نظام کی منتقلی: ایک بار جب ماڈل واضح سگنل کی پیشین گوئی کرتا ہے (مثال کے طور پر، "UP")، حکمت عملی یہ کرے گی:
- جرنل میں ایک واحد، دلکش اندراج سگنل پرنٹ کرتا ہے، مثال کے طور پر، 🎯 نیا تجارتی سگنل: پیشن گوئی اپ! مشاہدے کی مدت 15 منٹ۔
- حکمت عملی کی حیثیت کو Idle سے In-Signal میں تبدیل کرتا ہے۔
موجودہ سگنل کے ٹرگر کا وقت اور سمت ریکارڈ کریں۔
- پوزیشن کی حیثیت: سگنل میں
- جب حکمت عملی اس حالت میں ہو گی، تو یہ نئی K لائنوں کی پیش گوئی کرنا مکمل طور پر بند کر دے گی۔ یہ اب ہر منٹ کے اتار چڑھاؤ کی پرواہ نہیں کرتا اور "گولی کو اڑنے دو" موڈ میں داخل ہوتا ہے۔
- یہ صرف وقت کی جانچ کرتا ہے: آیا سگنل کے شروع ہونے کے بعد سے 15 منٹ (PREDICT_HORIZON کی لمبائی) گزر چکے ہیں۔
- ریاست کی منتقلی: 15 منٹ کے مشاہدے کی مدت کے بعد، پالیسی یہ کرے گی:
- لاگ پر ایک واضح ایگزٹ سگنل پرنٹ کریں، جیسے 🏁 سگنل کی مدت کا اختتام۔ حکمت عملی کو دوبارہ ترتیب دیں اور نئے مواقع تلاش کریں...
- حکمت عملی کی حیثیت کو ہولڈنگ سے بیکار پر سوئچ کرتا ہے۔
- اس مقام پر، حکمت عملی نئی K-لائن کی دوبارہ پیشن گوئی کرنا شروع کر دے گی اور اگلے تجارتی مواقع کی تلاش کرے گی۔
اس سادہ ریاستی مشین کے ساتھ، ہم نے ضروریات کو مکمل طور پر حاصل کر لیا ہے: ایک سگنل، ایک مکمل مشاہداتی سائیکل، اور مدت کے دوران کوئی مداخلت کی معلومات نہیں۔
import json
import math
import time
import websocket
import threading
from datetime import datetime
import numpy as np
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.feature_selection import mutual_info_classif
from sklearn.ensemble import RandomForestClassifier
# ========== 全局配置 ==========
TRAIN_BARS = 200 #需要更多初始数据
PREDICT_HORIZON = 15 # 回归15分钟预测周期
SPREAD_THRESHOLD = 0.005 # 适配15分钟周期的涨跌阈值
SYMBOL_FMZ = "ETH_USDT"
SYMBOL_API = SYMBOL_FMZ.replace('_', '').lower()
WEBSOCKET_URL = f"wss://fstream.binance.com/stream?streams={SYMBOL_API}@aggTrade/{SYMBOL_API}@depth20@100ms"
# ========== 全局状态变量 ==========
g_model, g_scaler = None, None
g_klines_1min, g_ticks, g_order_book_history = [], [], []
g_last_kline_ts = 0
g_feature_names = ['price_change_15m', 'volatility_30m', 'rsi_14', 'hour_of_day',
'alpha_15m', 'wobi_10s', 'spread_10s']
# 新功能: 信号状态机
g_active_signal = {'active': False, 'start_ts': 0, 'prediction': -1}
# ========== 特征工程与模型训练 ==========
def calculate_features_and_labels(klines, ticks, order_books_history, is_realtime=False):
features, labels = [], []
close_prices = [k['close'] for k in klines]
start_index = 30
end_index = len(klines) - PREDICT_HORIZON if not is_realtime else len(klines)
for i in range(start_index, end_index):
kline_start_ts = klines[i]['ts']
price_change_15m = (klines[i]['close'] - klines[i-15]['close']) / klines[i-15]['close']
volatility_30m = np.std(close_prices[i-30:i])
diffs = np.diff(close_prices[i-14:i+1]); gains = np.sum(diffs[diffs > 0]) / 14; losses = -np.sum(diffs[diffs < 0]) / 14
rsi_14 = 100 - (100 / (1 + gains / (losses + 1e-10)))
dt_object = datetime.fromtimestamp(kline_start_ts / 1000)
ticks_in_15m = [t for t in ticks if t['ts'] >= klines[i-15]['ts'] and t['ts'] < kline_start_ts]
buy_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'buy'); sell_vol = sum(t['qty'] for t in ticks_in_15m if t['side'] == 'sell')
alpha_15m = (buy_vol - sell_vol) / (buy_vol + sell_vol + 1e-10)
books_in_10s = [b for b in order_books_history if b['ts'] >= kline_start_ts - 10000 and b['ts'] < kline_start_ts]
if not books_in_10s: wobi_10s, spread_10s = 0, 0.0
else:
wobis, spreads = [], []
for book in books_in_10s:
if not book['bids'] or not book['asks']: continue
bid_vol = sum(float(p[1]) for p in book['bids']); ask_vol = sum(float(p[1]) for p in book['asks'])
wobis.append(bid_vol / (bid_vol + ask_vol + 1e-10))
spreads.append(float(book['asks'][0][0]) - float(book['bids'][0][0]))
wobi_10s = np.mean(wobis) if wobis else 0; spread_10s = np.mean(spreads) if spreads else 0
current_features = [price_change_15m, volatility_30m, rsi_14, dt_object.hour, alpha_15m, wobi_10s, spread_10s]
if not is_realtime:
future_price = klines[i + PREDICT_HORIZON]['close']; current_price = klines[i]['close']
if future_price > current_price * (1 + SPREAD_THRESHOLD):
labels.append(0); features.append(current_features)
elif future_price < current_price * (1 - SPREAD_THRESHOLD):
labels.append(1); features.append(current_features)
else:
features.append(current_features)
return np.array(features), np.array(labels)
def run_analysis_report(X, y, clf, scaler):
Log("--- 模型分析报告 V2.5 (15分钟预测) ---", "info")
Log("1. 特征重要性 (代理模型: 随机森林):")
rf = RandomForestClassifier(n_estimators=50, random_state=42); rf.fit(X, y)
importances = sorted(zip(g_feature_names, rf.feature_importances_), key=lambda x: x[1], reverse=True)
for name, importance in importances: Log(f" - {name}: {importance:.4f}")
Log("2. 特征与标签的互信息:"); mi_scores = mutual_info_classif(X, y)
mi_scores = sorted(zip(g_feature_names, mi_scores), key=lambda x: x[1], reverse=True)
for name, score in mi_scores: Log(f" - {name}: {score:.4f}")
Log("3. 历史数据回测表现:"); y_pred = clf.predict(scaler.transform(X)); accuracy = accuracy_score(y, y_pred)
Log(f" - **历史回测总胜率: {accuracy * 100:.2f}%**", "success")
Log("4. 混淆矩阵 (行:真实, 列:预测):"); cm = confusion_matrix(y, y_pred)
Log(" 预测涨(0) 预测跌(1)"); Log(f"真实涨(0): {cm[0] if len(cm) > 0 else [0,0]}")
Log(f"真实跌(1): {cm[1] if len(cm) > 1 else [0,0]}")
profit_chart = Chart({'title': {'text': f'历史回测净值曲线 (胜率: {accuracy*100:.2f}%)'}}); profit_chart.reset(); balance = 1
for i in range(len(y)):
if y_pred[i] == y[i]: balance *= (1 + 0.01)
else: balance *= (1 - 0.01)
profit_chart.add(i, balance)
Log("--- 报告结束, 5秒后进入实盘预测 ---", "info"); Sleep(5000)
def train_and_analyze():
global g_model, g_scaler, g_klines_1min, g_ticks, g_order_book_history
MIN_REQUIRED_BARS = 30 + PREDICT_HORIZON
if len(g_klines_1min) < MIN_REQUIRED_BARS:
Log(f"K线数量({len(g_klines_1min)})不足以进行特征工程,需要至少 {MIN_REQUIRED_BARS} 根。", "warning"); return False
Log("开始训练模型 (V2.5)...")
X, y = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history)
if len(X) < 20 or len(set(y)) < 2:
Log(f"有效涨跌样本不足(X: {len(X)}, 类别: {len(set(y))}),无法训练。", "warning"); return False
scaler = StandardScaler(); X_scaled = scaler.fit_transform(X)
clf = svm.SVC(kernel='rbf', C=1.0, gamma='scale'); clf.fit(X_scaled, y)
g_model, g_scaler = clf, scaler
Log("模型训练完成!", "success")
run_analysis_report(X, y, g_model, g_scaler)
return True
# ========== WebSocket实时数据处理 ==========
def aggregate_ticks_to_kline(ticks):
if not ticks: return None
return {'ts': ticks[0]['ts'] // 60000 * 60000, 'open': ticks[0]['price'], 'high': max(t['price'] for t in ticks), 'low': min(t['price'] for t in ticks), 'close': ticks[-1]['price'], 'volume': sum(t['qty'] for t in ticks)}
def on_message(ws, message):
global g_ticks, g_klines_1min, g_last_kline_ts, g_order_book_history
try:
payload = json.loads(message)
data = payload.get('data', {}); stream = payload.get('stream', '')
if 'aggTrade' in stream:
trade_data = {'ts': int(data['T']), 'price': float(data['p']), 'qty': float(data['q']), 'side': 'sell' if data['m'] else 'buy'}
g_ticks.append(trade_data)
current_minute_ts = trade_data['ts'] // 60000 * 60000
if g_last_kline_ts == 0: g_last_kline_ts = current_minute_ts
if current_minute_ts > g_last_kline_ts:
last_minute_ticks = [t for t in g_ticks if t['ts'] >= g_last_kline_ts and t['ts'] < current_minute_ts]
if last_minute_ticks:
kline = aggregate_ticks_to_kline(last_minute_ticks); g_klines_1min.append(kline)
g_ticks = [t for t in g_ticks if t['ts'] >= current_minute_ts]
g_last_kline_ts = current_minute_ts
elif 'depth' in stream:
book_snapshot = {'ts': int(data['E']), 'bids': data['b'], 'asks': data['a']}
g_order_book_history.append(book_snapshot)
if len(g_order_book_history) > 5000: g_order_book_history.pop(0)
except Exception as e: Log(f"OnMessage Error: {e}")
def start_websocket():
ws = websocket.WebSocketApp(WEBSOCKET_URL, on_message=on_message)
wst = threading.Thread(target=ws.run_forever); wst.daemon = True; wst.start()
Log("WebSocket多流订阅已启动...")
# ========== 主程序入口 ==========
def main():
global TRAIN_BARS, g_active_signal
exchange.SetContractType("swap")
start_websocket()
Log("策略启动 ,进入数据收集中...")
main.last_predict_ts = 0
while True:
if g_model is None:
if len(g_klines_1min) >= TRAIN_BARS:
if not train_and_analyze():
Log(f"模型训练失败,当前目标 {TRAIN_BARS} 根K线。将增加50根后重试...", "error")
TRAIN_BARS += 50
else:
LogStatus(f"正在收集K线数据: {len(g_klines_1min)} / {TRAIN_BARS}")
else:
if not g_active_signal['active']:
if len(g_klines_1min) > 0 and g_klines_1min[-1]['ts'] > main.last_predict_ts:
main.last_predict_ts = g_klines_1min[-1]['ts']
kline_time_str = datetime.fromtimestamp(main.last_predict_ts / 1000).strftime('%H:%M:%S')
if len(g_klines_1min) < 30:
LogStatus("历史K线不足,无法预测。等待更多数据..."); continue
latest_features, _ = calculate_features_and_labels(g_klines_1min, g_ticks, g_order_book_history, is_realtime=True)
if latest_features.shape[0] == 0:
LogStatus(f"({kline_time_str}) 无法生成特征,跳过..."); continue
last_feature_vector = latest_features[-1].reshape(1, -1)
last_feature_scaled = g_scaler.transform(last_feature_vector)
prediction = g_model.predict(last_feature_scaled)[0]
if prediction == 0 or prediction == 1:
g_active_signal['active'] = True
g_active_signal['start_ts'] = main.last_predict_ts
g_active_signal['prediction'] = prediction
prediction_text = ['**上涨**', '**下跌**'][prediction]
Log(f"🎯 新的交易信号 ({kline_time_str}): 预测 {prediction_text}!观察周期 {PREDICT_HORIZON} 分钟。", "success" if prediction == 0 else "error")
else:
LogStatus(f"({kline_time_str}) 无明确信号,继续观察...")
else:
current_ts = time.time() * 1000
elapsed_minutes = (current_ts - g_active_signal['start_ts']) / (1000 * 60)
if elapsed_minutes >= PREDICT_HORIZON:
Log(f"🏁 信号周期结束。重置策略,寻找新机会...", "info")
g_active_signal['active'] = False
else:
prediction_text = ['**上涨**', '**下跌**'][g_active_signal['prediction']]
LogStatus(f"信号生效中: {prediction_text}。剩余观察时间: {PREDICT_HORIZON - elapsed_minutes:.1f} 分钟。")
Sleep(5000)
پھر میں اس کوڈ کو چلاتا ہوں۔
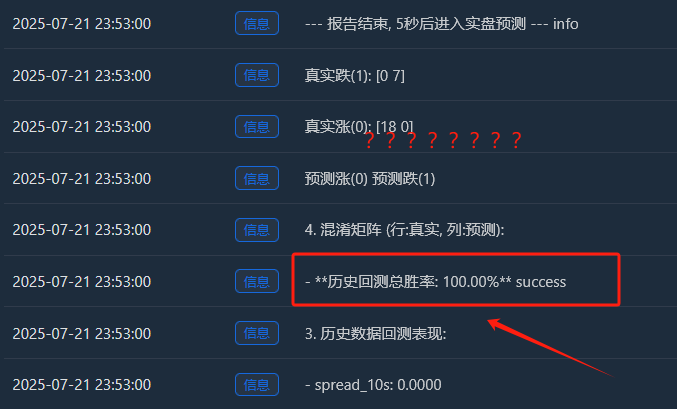
گہرائی سے تجزیہ: "کامل" 100% جیتنے کی شرح کیوں موجود ہے؟
یہ "کامل" نتیجہ مشین لرننگ اور مالیاتی منڈیوں کے بارے میں کئی اہم اور گہری بصیرت کو ظاہر کرتا ہے۔ یہ کوئی بگ نہیں ہے، بلکہ ایک عام رجحان ہے جسے "اوور فٹنگ" کے نام سے جانا جاتا ہے، جو بعض حالات میں ہو سکتا ہے۔
"اوور فٹنگ" کا کیا مطلب ہے؟
-
یہاں ایک واضح تشبیہ ہے: تصور کریں کہ ہمارے پاس ایک طالب علم (ہمارا SVM ماڈل) بہت مختصر، بہت آسان مشقوں کا ایک سیٹ کرتا ہے (ہم نے جمع کیے گئے 200 کینڈل سٹک ڈیٹا پوائنٹس)۔ یہ طالب علم بہت ذہین ہے، اور عام مسائل کو حل کرنے کے طریقے سیکھنے کے بجائے، وہ صرف ان چند مسائل کے جوابات کو حفظ کر لیتے ہیں۔
-
نتیجہ: جب ہم اس کو پریکٹس سوالات کے ایک ہی سیٹ سے آزماتے ہیں (یہ ہمارا "تاریخی بیک ٹیسٹ" ہے)، تو وہ یقینی طور پر 100 کا کامل سکور حاصل کر سکتا ہے۔ تاہم، ایک بار جب ہم اسے سوالات کا بالکل نیا سیٹ دیتے ہیں جو اس نے پہلے کبھی نہیں دیکھا ہو گا (حقیقی مستقبل کے بازاروں)، تو امکان ہے کہ وہ ان میں سے کسی کا بھی جواب نہ دے سکے۔
- ہمارا ماڈل "اوور فٹ" کیوں ہے؟
-
تربیتی نمونے "بہت کم" اور "بہت خاص" ہیں:
-
اگرچہ ہم نے 200 K-لائنز (تقریباً 3.3 گھنٹے) جمع کیں، لاگ کے مطابق، ہماری تعریف پر پورا اترنے والے "موثر عروج و زوال" کے نمونوں کی حتمی تعداد صرف 18 + 7 = 25 تھی۔
-
ایک پیچیدہ SVM ماڈل کے لیے، 25 نمونے سمندر کی چند لہروں کی طرح ہیں، جو بہت چھوٹی ہیں۔
-
مزید اہم بات یہ ہے کہ یہ 25 نمونے ایک ہی سہ پہر کو مارکیٹ کی انتہائی متعلقہ صورتحال سے آتے ہیں۔ ان کے بہت ملتے جلتے "معمولات" ہونے کا امکان ہے۔
- ماڈل کی صلاحیتیں "بہت مضبوط" ہیں:
- SVM ایک بہت طاقتور، نان لائنر درجہ بندی کرنے والا ہے۔ اس کی صلاحیت سپر میموری کے ساتھ دماغ کی طرح ہے۔
- جب ایک طاقتور ماڈل کسی ایسے ڈیٹاسیٹ سے سیکھتا ہے جو بہت آسان اور بار بار ہوتا ہے، تو یہ ڈیٹا کی تمام تفصیلات اور شور کو "حافظ" کرنے کا رجحان رکھتا ہے بجائے اس کے کہ اس کے پیچھے موجود زیادہ عالمگیر میکرو قوانین کو سیکھے۔
- کنفیوژن میٹرکس سے ثبوت:
- حقیقی اضافہ (0):[18 0] -> 18 ابھرتے ہوئے نمونے، سبھی بالکل حفظ ہیں۔
- حقیقی کمی (1):[0 7] -> 7 گرتے ہوئے نمونے، سب بالکل یاد ہیں۔
- یہ کامل[ [18, 0], [[0, 7] میٹرکس ماڈل کی اوور فٹنگ کا ناقابل تردید ثبوت ہے۔ یہ تقریباً کوئی غلطی نہیں کرتا، جو کہ بے ترتیب پن سے بھری مالیاتی منڈی میں فطری طور پر غیر معمولی ہے۔
لہذا، ہمیں اس 100% جیتنے کی شرح کی تشریح اس طرح کرنی چاہیے:
"ماڈل نے گزشتہ تین گھنٹوں کے دوران مارکیٹ کے مخصوص حالات کے تمام نمونوں کو نمایاں طور پر سیکھا اور یاد کیا ہے۔ یہ ہماری فیچر انجینئرنگ اور ماڈل فریم ورک کی تاثیر کو ظاہر کرتا ہے۔ تاہم، ہم اس سے مستقبل میں حقیقی مارکیٹ میں اتنی زیادہ جیت کی شرح کو برقرار رکھنے کی قطعی طور پر توقع نہیں کر سکتے۔ یہ 'کالج' کے امتحان کے حتمی نتائج سے زیادہ ایک بہترین 'پاپ کوئز' کی طرح ہے۔"

مشین لرننگ بھی ایک ایسی چیز ہے جسے میں حال ہی میں دریافت کر رہا ہوں، ہم اگلے شمارے میں اس پر بات کریں گے!
ہمیں اس "متعصب طالب علم" پر ایک مکمل "سوچ کی تبدیلی" کرنے کی ضرورت ہے۔ ہمارا مقصد اس کے تعصبات کو توڑنا ہے اور اسے منصفانہ اور معروضی طور پر "اُتار چڑھاؤ" دیکھنے کی اجازت دینا ہے۔
