
FMZ پلیٹ فارم پر Python کرالر کے اطلاق پر ایک ابتدائی مطالعہ - Binance کے اعلان کے مواد کو رینگنا
میں نے حال ہی میں کمیونٹی اور لائبریری کو دیکھا اور میں نے QUANT کے طور پر جامع ترقی کے جذبے پر مبنی Python کرالر کے بارے میں کوئی متعلقہ معلومات نہیں پائی۔ میں نے کرالرز سے متعلق تصورات اور علم کو بہت آسانی سے سیکھا۔ اس کے بارے میں مزید جاننے کے بعد، میں نے محسوس کیا کہ "کرالر ٹیکنالوجی" کافی بڑا "گڑھا" ہے یہ مضمون "کرالر ٹیکنالوجی" کی صرف ایک ابتدائی تحقیق ہے۔ آئیے FMZ مقداری تجارتی پلیٹ فارم پر کرالر ٹیکنالوجی کی آسان ترین مشق کرتے ہیں۔
ضرورت
تاجروں کے لیے جو نئے سکوں میں سرمایہ کاری کرنا پسند کرتے ہیں، وہ ہمیشہ ایکسچینج پر سکوں کی فہرست کے بارے میں جلد از جلد معلومات حاصل کرنے کی امید رکھتے ہیں۔ ایکسچینج ویب سائٹ پر دستی طور پر نظر رکھنا واضح طور پر غیر حقیقی ہے۔ پھر آپ کو تبادلے کے اعلان کے صفحہ کی نگرانی اور نئے اعلانات کا پتہ لگانے کے لیے ایک کرالر اسکرپٹ استعمال کرنے کی ضرورت ہے تاکہ آپ کو جلد از جلد مطلع اور یاد دہانی کرائی جا سکے۔
ابتدائی تحقیق
آئیے ایک بہت ہی آسان پروگرام کو بطور اسٹارٹر استعمال کریں (واقعی طاقتور کرالر اسکرپٹ بہت زیادہ پیچیدہ ہے، لہذا اپنا وقت نکالیں)۔ پروگرام کی منطق بہت آسان ہے، جس کا مقصد یہ ہے کہ پروگرام کو ایکسچینج کے اعلان کے صفحہ تک مسلسل رسائی حاصل کرنے، حاصل کردہ HTML مواد کو پارس کرنے، اور یہ معلوم کرنا کہ آیا کسی مخصوص ٹیگ کے مواد کو اپ ڈیٹ کیا گیا ہے۔
نفاذ کوڈ
آپ کچھ مفید کرالر فریم ورک استعمال کر سکتے ہیں۔ تاہم، اس بات کو مدنظر رکھتے ہوئے کہ ضرورت بہت آسان ہے، اسے براہ راست لکھنا بھی ممکن ہے۔
ازگر کی لائبریریوں کی ضرورت ہے:
requests، جسے آسانی سے ویب صفحات تک رسائی کے لیے استعمال ہونے والی لائبریری کے طور پر سمجھا جا سکتا ہے۔
bs4، جسے کسی ویب صفحہ کے HTML کوڈ کو پارس کرنے کے لیے استعمال ہونے والی لائبریری کے طور پر سمجھا جا سکتا ہے۔
کوڈ:
from bs4 import BeautifulSoup
import requests
urlBinanceAnnouncement = "https://www.binancezh.io/en/support/announcement/c-48?navId=48" # 币安公告页面地址
def openUrl(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
r = requests.get(url, headers=headers) # 使用requests库访问url,即币安的公告网页地址
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # 访问成功的话返回网页内容文本
else:
Log("failed {}".format(url))
def main():
preNews_href = ""
lastNews = ""
Log("watching...", urlBinanceAnnouncement, "#FF0000")
while True:
ret = openUrl(urlBinanceAnnouncement)
if ret:
soup = BeautifulSoup(ret, 'html.parser') # 把网页文本解析为对象
lastNews_href = soup.find('a', class_='css-1ej4hfo')["href"] # 查找特定的标签,获取href
lastNews = soup.find('a', class_='css-1ej4hfo').get_text() # 获取这个标签中的内容
if preNews_href == "":
preNews_href = lastNews_href
if preNews_href != lastNews_href: # 检测到标签发生变动,即有新的公告产生
Log("New Cryptocurrency Listing update!") # 打印提示信息
preNews_href = lastNews_href
LogStatus(_D(), "\n", "preNews_href:", preNews_href, "\n", "news:", lastNews)
Sleep(1000 * 10)
چلائیں
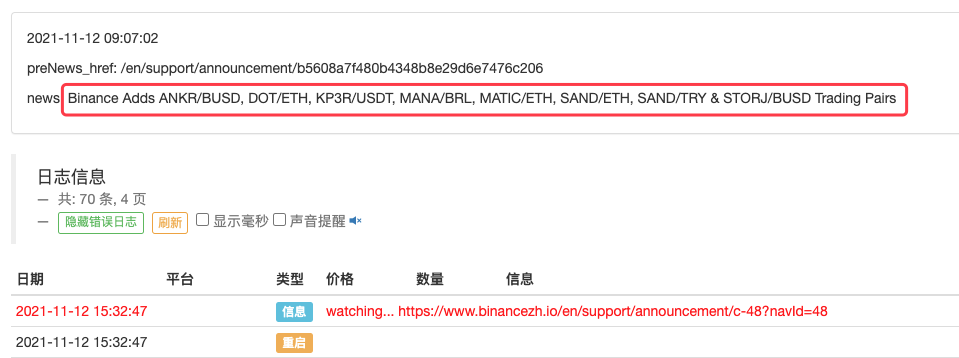
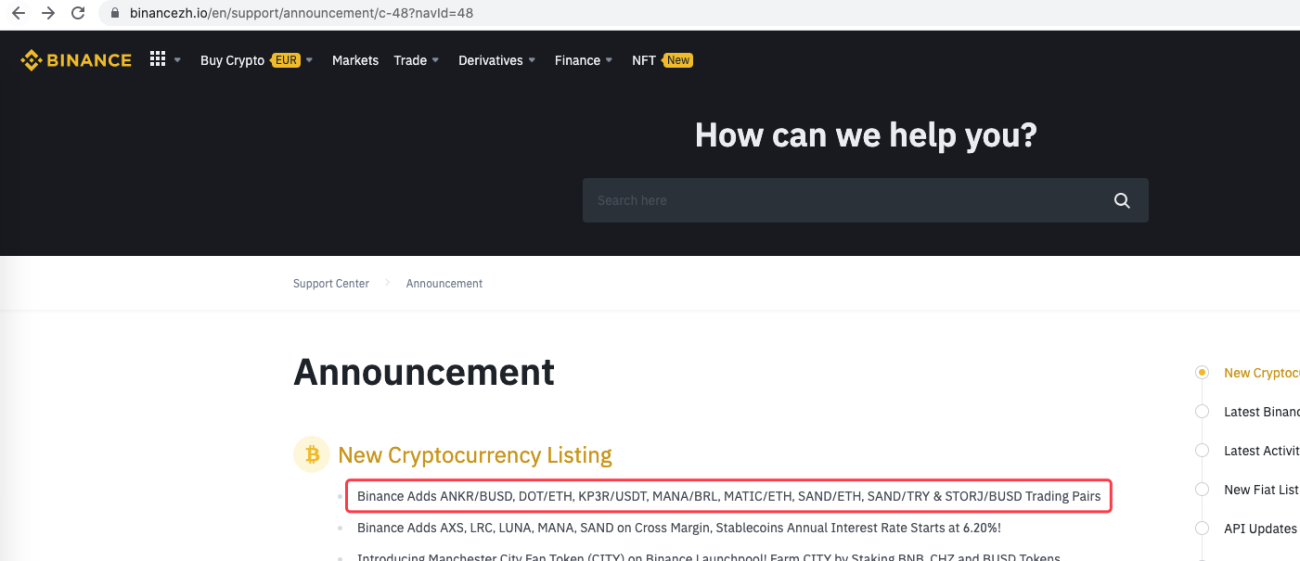
مثال کے طور پر جب کوئی نیا اعلان ظاہر ہوتا ہے تو اس کو بڑھایا جا سکتا ہے۔ اعلان میں نئی کرنسیوں کا تجزیہ کریں اور نئے لین دین کے لیے خود بخود آرڈر دیں۔

Traceback (most recent call last): File "<string>", line 999, in init_ctx File "<string>", line 1, in <module> ModuleNotFoundError: No module named 'bs4'
复制代码到实盘提示错误,是不是缺失python的库。怎么添加库到托管着呢。


作者你好,我也写了一个爬币安公告的爬虫,不管是用那个api接口还是主页的爬虫都有30s延迟,不知道你有没有解决这个问题,可以交流下吗,我的vx ShawnQiang1125


- 1