

1. Giới thiệu tóm tắt
Mạng nơ-ron sâu ngày càng trở nên phổ biến trong những năm gần đây, giải quyết được những vấn đề trước đây không thể giải quyết được trong nhiều lĩnh vực và chứng minh được khả năng mạnh mẽ của chúng. Trong dự đoán chuỗi thời gian, giá mạng nơ-ron thường được sử dụng là RNN, vì RNN không chỉ có dữ liệu đầu vào hiện tại mà còn có dữ liệu đầu vào lịch sử. Tất nhiên, khi chúng ta nói về RNN dự đoán giá, chúng ta thường nói về một loại RNN : LSTM . Bài viết này sẽ xây dựng một mô hình để dự đoán giá Bitcoin dựa trên pytorch. Mặc dù có rất nhiều thông tin liên quan trên Internet, nhưng vẫn chưa đủ đầy đủ và tương đối ít người sử dụng pytorch. Vẫn cần phải viết một bài viết. Kết quả cuối cùng là sử dụng giá mở cửa, giá đóng cửa, giá cao nhất , giá thấp nhất và khối lượng giao dịch của thị trường Bitcoin để dự đoán giá đóng cửa tiếp theo. Kiến thức cá nhân của tôi về mạng nơ-ron ở mức trung bình và tôi hoan nghênh những lời chỉ trích và sửa lỗi của bạn.
Hướng dẫn này được thực hiện bởi FMZ, nhà phát minh ra nền tảng giao dịch định lượng tiền kỹ thuật số (www.fmz.com). Chào mừng bạn tham gia nhóm QQ: 863946592 để giao lưu.
2. Dữ liệu và tài liệu tham khảo
Một ví dụ dự đoán giá liên quan: https://yq.aliyun.com/articles/538484
Giới thiệu chi tiết về mô hình RNN: https://zhuanlan.zhihu.com/p/27485750
Hiểu về đầu vào và đầu ra của RNN: https://www.zhihu.com/question/41949741/answer/318771336
Giới thiệu về pytorch: Tài liệu chính thức https://pytorch.org/docs Tự tìm kiếm thông tin khác.
Ngoài ra, cần có một số kiến thức tiên quyết để hiểu bài viết này, chẳng hạn như pandas/crawlers/xử lý dữ liệu, v.v., nhưng không sao nếu bạn không biết.
3. Các tham số của mô hình pytorch LSTM
Các tham số của LSTM:
Khi lần đầu tiên nhìn thấy những thông số dày đặc này trên tài liệu, phản ứng của tôi là:

Khi tôi đọc chậm lại, cuối cùng tôi đã hiểu.

input_size: Kích thước tính năng của vectơ đầu vào x. Nếu giá đóng cửa được sử dụng để dự đoán giá đóng cửa, thì input_size=1; nếu giá đóng cửa được dự đoán bằng mức mở cửa cao và mức đóng cửa thấp, thì input_size=4
hidden_size: Kích thước lớp ẩn
num_layers: Số lớp của RNN
batch_first: Nếu Đúng, chiều đầu vào đầu tiên là batch_size. Tham số này cũng rất khó hiểu và sẽ được mô tả chi tiết bên dưới.
Tham số dữ liệu đầu vào:
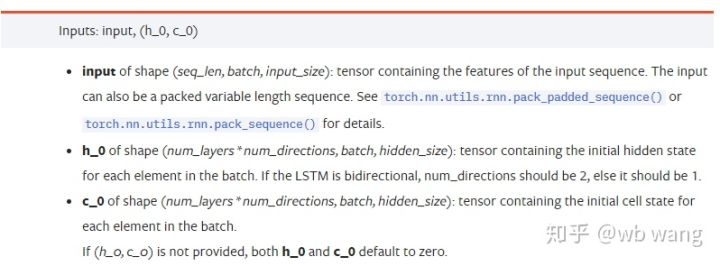
input:Dữ liệu đầu vào cụ thể là một tenxơ ba chiều có hình dạng cụ thể là (seq_len, batch, input_size). Trong số đó, seq_len đề cập đến độ dài của chuỗi, tức là độ dài dữ liệu lịch sử mà LSTM cần xem xét. Lưu ý rằng điều này chỉ đề cập đến định dạng của dữ liệu, không phải cấu trúc bên trong của LSTM. Cùng một mô hình LSTM có thể dữ liệu đầu vào với seq_len khác nhau và có thể đưa ra dự đoán. Kết quả; batch đề cập đến kích thước batch, biểu thị số lượng nhóm dữ liệu khác nhau; input_size là input_size trước đó.
h_0: Trạng thái ẩn ban đầu, hình dạng là (num_layers * num_directions, batch, hidden_size), nếu đó là mạng hai chiều num_directions=2
c_0: Trạng thái tế bào ban đầu, hình dạng giống như trên, có thể để nguyên không xác định.
Tham số đầu ra:
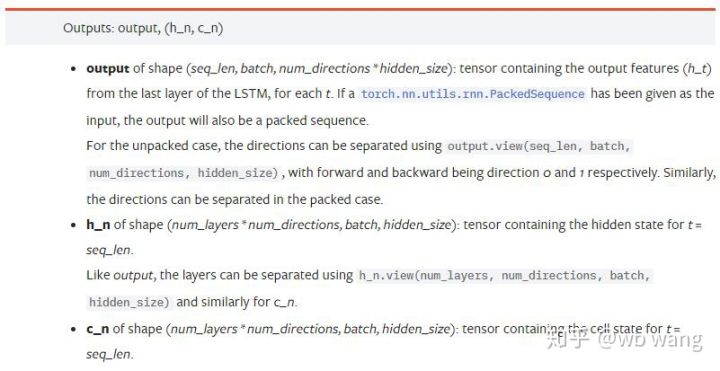
output: Hình dạng đầu ra (seq_len, batch, num_directions * hidden_size), lưu ý rằng nó liên quan đến tham số mô hình batch_first
h_n: trạng thái h tại thời điểm t = seq_len, cùng hình dạng với h_0
c_n: trạng thái c tại thời điểm t = seq_len, cùng hình dạng với c_0
4. Ví dụ đơn giản về đầu vào và đầu ra LSTM
Đầu tiên nhập các gói cần thiết
python
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
Định nghĩa mô hình LSTM
python
LSTM = nn.LSTM(input_size=5, hidden_size=10, num_layers=2, batch_first=True)
Chuẩn bị dữ liệu đầu vào
python
x = torch.randn(3,4,5)
# x的值为:
tensor([[[ 0.4657, 1.4398, -0.3479, 0.2685, 1.6903],
[ 1.0738, 0.6283, -1.3682, -0.1002, -1.7200],
[ 0.2836, 0.3013, -0.3373, -0.3271, 0.0375],
[-0.8852, 1.8098, -1.7099, -0.5992, -0.1143]],
[[ 0.6970, 0.6124, -0.1679, 0.8537, -0.1116],
[ 0.1997, -0.1041, -0.4871, 0.8724, 1.2750],
[ 1.9647, -0.3489, 0.7340, 1.3713, 0.3762],
[ 0.4603, -1.6203, -0.6294, -0.1459, -0.0317]],
[[-0.5309, 0.1540, -0.4613, -0.6425, -0.1957],
[-1.9796, -0.1186, -0.2930, -0.2619, -0.4039],
[-0.4453, 0.1987, -1.0775, 1.3212, 1.3577],
[-0.5488, 0.6669, -0.2151, 0.9337, -1.1805]]])
Hình dạng của x là (3,4,5), vì chúng ta đã xác địnhbatch_first=True, tại thời điểm này, batch_size là 3, sqe_len là 4 và input_size là 5. x[0] biểu thị lô đầu tiên.
Nếu batch_first không được xác định, giá trị mặc định sẽ là False và dữ liệu sẽ được biểu diễn hoàn toàn khác, với kích thước lô là 4, sqe_len là 3 và input_size là 5. Vào thời điểm này x[0] biểu thị dữ liệu của tất cả các lô tại t=0, v.v. Cá nhân tôi cảm thấy rằng thiết lập này không trực quan, vì vậy tôi đã thêm tham sốbatch_first=True.
Việc chuyển đổi dữ liệu giữa hai hệ thống này cũng rất tiện lợi:x.permute(1,0,2)
Đầu vào và đầu ra
Hình dạng của đầu vào và đầu ra LSTM rất dễ bị nhầm lẫn, bạn có thể tham khảo hình minh họa sau để hiểu rõ hơn:
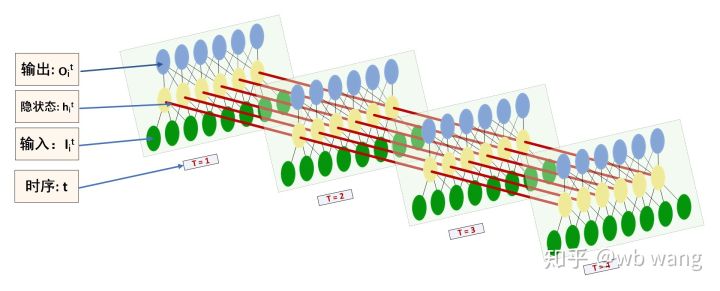
Nguồn: https://www.zhihu.com/question/41949741/answer/318771336
python
x = torch.randn(3,4,5)
h0 = torch.randn(2, 3, 10)
c0 = torch.randn(2, 3, 10)
output, (hn, cn) = LSTM(x, (h0, c0))
print(output.size()) #在这里思考一下,如果batch_first=False输出的大小会是多少?
print(hn.size())
print(cn.size())
#结果
torch.Size([3, 4, 10])
torch.Size([2, 3, 10])
torch.Size([2, 3, 10])
Quan sát kết quả đầu ra, chúng có phù hợp với giải thích về tham số trước đó không. Lưu ý rằng giá trị thứ hai của hn.size() là 3, phù hợp với kích thước của batch_size, cho biết không có trạng thái trung gian nào được lưu trong hn, chỉ có bước cuối cùng.
Vì mạng LSTM của chúng ta có hai lớp, đầu ra của lớp cuối cùng của hn thực sự là giá trị của đầu ra và hình dạng của đầu ra là[3, 4, 10], lưu kết quả của tất cả các thời điểm t=0,1,2,3, do đó:
python
hn[-1][0] == output[0][-1] #第一个batch在hn最后一层的输出等于第一个batch在t=3时output的结果
hn[-1][1] == output[1][-1]
hn[-1][2] == output[2][-1]
5. Chuẩn bị dữ liệu thị trường Bitcoin
Rất nhiều điều tôi đã nói trước đây chỉ là phần mở đầu. Việc hiểu đầu vào và đầu ra của LSTM là rất quan trọng. Nếu không, bạn sẽ dễ mắc lỗi nếu sao chép ngẫu nhiên một số mã từ Internet. Do khả năng mạnh mẽ của LSTM theo chuỗi thời gian, ngay cả khi mô hình sai, cuối cùng bạn vẫn có thể có được kết quả. Kết quả tốt.
Thu thập dữ liệu
Dữ liệu được sử dụng là dữ liệu thị trường của cặp giao dịch BTC_USD trên sàn giao dịch Bitfinex.
python
import requests
import json
resp = requests.get('https://q.fmz.com/chart/history?symbol=bitfinex.btc_usd&resolution=15&from=0&to=0&from=1525622626&to=1562658565')
data = resp.json()
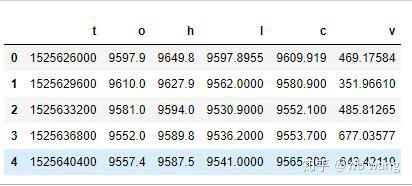
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
print(df.head(5))
Định dạng dữ liệu như sau:
Tiền xử lý dữ liệu
python
df.index = df['t'] # index设为时间戳
df = (df-df.mean())/df.std() # 数据的标准化,否则模型的Loss会非常大,不利于收敛
df['n'] = df['c'].shift(-1) # n为下一个周期的收盘价,是我们预测的目标
df = df.dropna()
df = df.astype(np.float32) # 改变下数据格式适应pytorch
Phương pháp chuẩn hóa dữ liệu rất thô sơ và sẽ có một số vấn đề. Nó chỉ để minh họa. Bạn có thể sử dụng chuẩn hóa dữ liệu như yield.
Chuẩn bị dữ liệu đào tạo
python
seq_len = 10 # 输入10个周期的数据
train_size = 800 # 训练集batch_size
def create_dataset(data, seq_len):
dataX, dataY=[], []
for i in range(0,len(data)-seq_len, seq_len):
dataX.append(data[['o','h','l','c','v']][i:i+seq_len].values)
dataY.append(data['n'][i:i+seq_len].values)
return np.array(dataX), np.array(dataY)
data_X, data_Y = create_dataset(df, seq_len)
train_x = torch.from_numpy(data_X[:train_size].reshape(-1,seq_len,5)) #变化形状,-1代表的值会自动计算
train_y = torch.from_numpy(data_Y[:train_size].reshape(-1,seq_len,1))
Hình dạng cuối cùng của train_x và train_y là: torch.Size([800, 10, 5]), torch.Size([800, 10, 1]). Vì mô hình của chúng tôi dự đoán giá đóng cửa của kỳ tiếp theo dựa trên dữ liệu từ 10 kỳ, về mặt lý thuyết, 800 lô chỉ yêu cầu 800 giá đóng cửa dự đoán. Nhưng train_y có 10 dữ liệu trong mỗi lô. Trên thực tế, kết quả trung gian của mỗi dự đoán lô được giữ lại, không chỉ kết quả cuối cùng. Khi tính toán tổn thất cuối cùng, tất cả 10 kết quả dự đoán đều có thể được tính đến và so sánh với các giá trị thực tế trong train_y. Về mặt lý thuyết, người ta chỉ có thể tính toán được mức tổn thất của kết quả dự đoán cuối cùng. Tôi đã vẽ một sơ đồ để minh họa cho vấn đề này. Vì mô hình LSTM thực sự không chứa tham số seq_len nên mô hình có thể được áp dụng cho các độ dài khác nhau và kết quả dự đoán trung gian cũng có ý nghĩa, do đó tôi có xu hướng hợp nhất phép tính Mất mát.
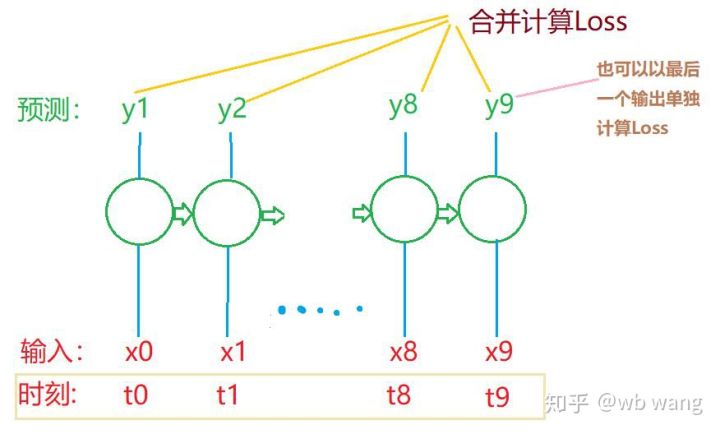
Lưu ý rằng khi chuẩn bị dữ liệu đào tạo, chuyển động của cửa sổ bị nhảy và dữ liệu đã sử dụng không còn được sử dụng nữa. Tất nhiên, các cửa sổ cũng có thể được di chuyển từng cái một, do đó tập đào tạo thu được sẽ lớn hơn nhiều . Nhưng tôi cảm thấy dữ liệu lô liền kề có tính lặp lại quá nhiều nên tôi đã áp dụng phương pháp hiện tại.
6. Xây dựng mô hình LSTM
Mô hình cuối cùng như sau, bao gồm một LSTM hai lớp và một lớp tuyến tính.
python
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size=1, num_layers=2):
super(LSTM, self).__init__()
self.rnn = nn.LSTM(input_size,hidden_size,num_layers,batch_first=True)
self.reg = nn.Linear(hidden_size,output_size) # 线性层,把LSTM的结果输出成一个值
def forward(self, x):
x, _ = self.rnn(x) # 如果不理解前向传播中数据维度的变化,可单独调试
x = self.reg(x)
return x
net = LSTM(5, 10) # input_size为5,代表了高开低收和交易量. 隐含层为10.
7. Bắt đầu đào tạo mô hình
Cuối cùng đã bắt đầu đào tạo, mã như sau:
python
criterion = nn.MSELoss() # 使用了简单的均方差损失函数
optimizer = torch.optim.Adam(net.parameters(),lr=0.01) # 优化函数,lr可调
for epoch in range(600): # 由于速度很快,这里的epoch多一些
out = net(train_x) # 由于数据量很小, 直接拿全量数据计算
loss = criterion(out, train_y)
optimizer.zero_grad()
loss.backward() # 反向传播损失
optimizer.step() # 更新参数
print('Epoch: {:<3}, Loss:{:.6f}'.format(epoch+1, loss.item()))
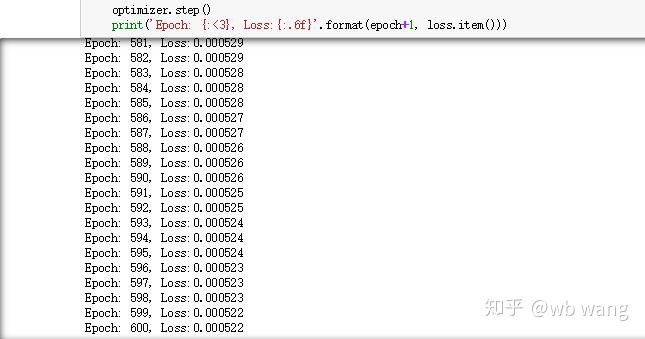
Kết quả đào tạo như sau:
8. Đánh giá mô hình
Các giá trị dự đoán của mô hình là:
python
p = net(torch.from_numpy(data_X))[:,-1,0] # 这里只取最后一个预测值作为比较
plt.figure(figsize=(12,8))
plt.plot(p.data.numpy(), label= 'predict')
plt.plot(data_Y[:,-1], label = 'real')
plt.legend()
plt.show()
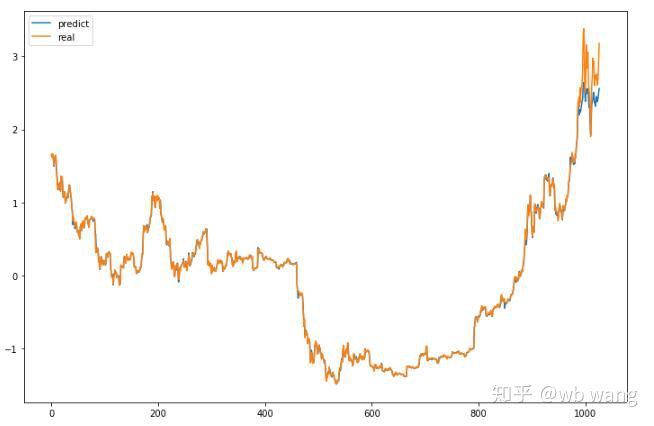
Như có thể thấy từ hình, mức độ phù hợp của dữ liệu đào tạo (trước 800) là rất cao, nhưng giá Bitcoin đã tăng lên mức cao mới sau đó và mô hình chưa thấy những dữ liệu này, vì vậy dự đoán là không thể thực hiện tốt. Điều này cũng cho thấy đã có vấn đề trong quá trình chuẩn hóa dữ liệu trước đó.
Mặc dù giá dự đoán có thể không chính xác, nhưng dự đoán về mức tăng và giảm chính xác đến mức nào? Hãy xem một phần dữ liệu dự đoán:
python
r = data_Y[:,-1][800:1000]
y = p.data.numpy()[800:1000]
r_change = np.array([1 if i > 0 else 0 for i in r[1:200] - r[:199]])
y_change = np.array([1 if i > 0 else 0 for i in y[1:200] - r[:199]])
print((r_change == y_change).sum()/float(len(r_change)))
Độ chính xác khi dự đoán giá tăng và giảm đạt 81,4%, vượt quá mong đợi của tôi. Tôi không biết liệu tôi có mắc lỗi ở đâu không.
Tất nhiên, mô hình này không có giá trị thực sự, nhưng nó đơn giản và dễ hiểu. Chỉ cần sử dụng nó như một điểm khởi đầu. Sẽ có nhiều khóa học giới thiệu hơn về ứng dụng mạng nơ-ron trong định lượng tiền kỹ thuật số.


