
Nghiên cứu sơ bộ về ứng dụng của Python crawler trên nền tảng FMZ - thu thập thông tin nội dung thông báo của Binance
Gần đây tôi đã xem cộng đồng và thư viện và không tìm thấy thông tin liên quan nào về trình thu thập dữ liệu Python, dựa trên tinh thần phát triển toàn diện như một QUANT. Tôi đã học được các khái niệm và kiến thức liên quan đến trình thu thập thông tin một cách rất đơn giản. Sau khi tìm hiểu thêm về nó, tôi phát hiện ra rằng "công nghệ bánh xích" là một "hố" khá lớn. Bài viết này chỉ là một cuộc khám phá sơ bộ về "công nghệ bánh xích". Chúng ta hãy cùng thực hành công nghệ thu thập dữ liệu đơn giản nhất trên nền tảng giao dịch định lượng FMZ.
nhu cầu
Đối với các nhà giao dịch muốn đầu tư vào các đồng tiền mới, họ luôn hy vọng có được thông tin về các đồng tiền được niêm yết trên sàn giao dịch càng sớm càng tốt. Rõ ràng là không thực tế khi theo dõi trang web trao đổi theo cách thủ công. Sau đó, bạn cần sử dụng một tập lệnh thu thập thông tin để theo dõi trang thông báo trao đổi và phát hiện các thông báo mới để có thể được thông báo và nhắc nhở sớm nhất có thể.
Khám phá ban đầu
Chúng ta hãy sử dụng một chương trình rất đơn giản để bắt đầu (một tập lệnh thu thập dữ liệu thực sự mạnh mẽ sẽ phức tạp hơn nhiều, vì vậy hãy từ từ). Logic của chương trình rất đơn giản, đó là cho phép chương trình liên tục truy cập vào trang thông báo của sàn giao dịch, phân tích nội dung HTML thu được và phát hiện xem nội dung của thẻ cụ thể có được cập nhật hay không.
Mã thực hiện
Bạn có thể sử dụng một số khung thu thập thông tin hữu ích. Tuy nhiên, vì yêu cầu này rất đơn giản nên cũng có thể viết trực tiếp.
Các thư viện Python cần có:
requests, có thể hiểu đơn giản là một thư viện dùng để truy cập các trang web.
bs4, có thể hiểu đơn giản là một thư viện được sử dụng để phân tích cú pháp mã HTML của một trang web.
Mã số:
from bs4 import BeautifulSoup
import requests
urlBinanceAnnouncement = "https://www.binancezh.io/en/support/announcement/c-48?navId=48" # 币安公告页面地址
def openUrl(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
r = requests.get(url, headers=headers) # 使用requests库访问url,即币安的公告网页地址
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # 访问成功的话返回网页内容文本
else:
Log("failed {}".format(url))
def main():
preNews_href = ""
lastNews = ""
Log("watching...", urlBinanceAnnouncement, "#FF0000")
while True:
ret = openUrl(urlBinanceAnnouncement)
if ret:
soup = BeautifulSoup(ret, 'html.parser') # 把网页文本解析为对象
lastNews_href = soup.find('a', class_='css-1ej4hfo')["href"] # 查找特定的标签,获取href
lastNews = soup.find('a', class_='css-1ej4hfo').get_text() # 获取这个标签中的内容
if preNews_href == "":
preNews_href = lastNews_href
if preNews_href != lastNews_href: # 检测到标签发生变动,即有新的公告产生
Log("New Cryptocurrency Listing update!") # 打印提示信息
preNews_href = lastNews_href
LogStatus(_D(), "\n", "preNews_href:", preNews_href, "\n", "news:", lastNews)
Sleep(1000 * 10)
chạy
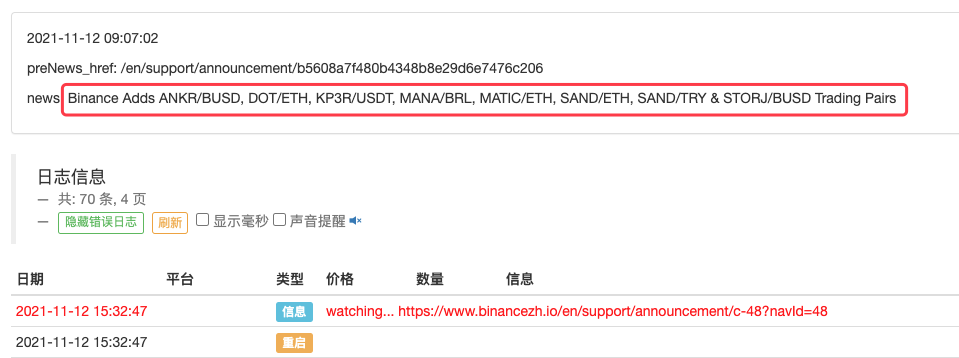
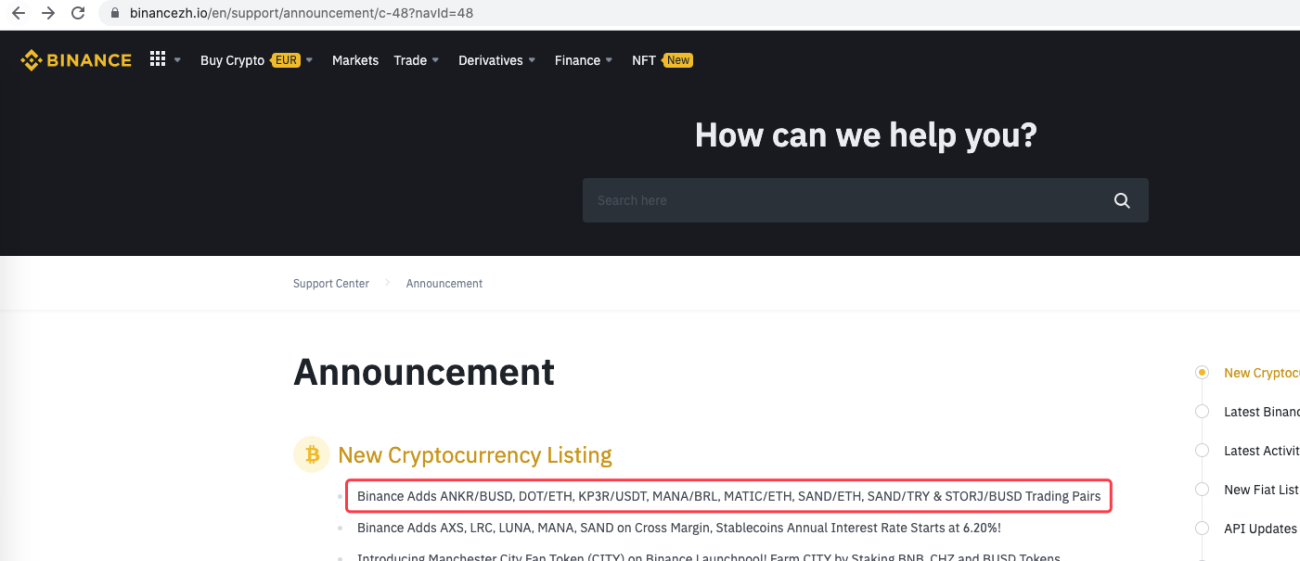
Thậm chí, nó có thể được mở rộng để phát hiện thời điểm có thông báo mới xuất hiện chẳng hạn. Phân tích các loại tiền tệ mới được liệt kê trong thông báo và tự động đặt lệnh cho các giao dịch mới.

Traceback (most recent call last): File "<string>", line 999, in init_ctx File "<string>", line 1, in <module> ModuleNotFoundError: No module named 'bs4'
复制代码到实盘提示错误,是不是缺失python的库。怎么添加库到托管着呢。


作者你好,我也写了一个爬币安公告的爬虫,不管是用那个api接口还是主页的爬虫都有30s延迟,不知道你有没有解决这个问题,可以交流下吗,我的vx ShawnQiang1125


- 1