
Bei der Verwendung von Inventor Quantify haben sich viele Entwickler in den Kommentaren und in der Community gefragt. Dieser Artikel fasst diese häufigsten Fragen zusammen und hilft Ihnen, schnell Lösungen zu finden, indem er die verschiedenen Aspekte der Umgebungskonfiguration, des Knotenverbrauchs, des Datenlesens, der KI-Aufrufe und der Rückmeldungsmechanismen abdeckt.
1. Probleme mit der Umgebungskonfiguration
Q1: Warum kann meine Festplatte die Workflow-Strategie nicht ausführen?
Nur die neueste Version des Host unterstützt den laufenden Workflow. Wenn Ihre Host-Version zu alt ist, kann die Workflow-Strategie nicht gestartet werden und muss zeitnah auf die neueste Version aktualisiert werden.
Q2: Welche Programmiersprachen unterstützt der Workflow?
Der Code-Node des Workflows unterstützt nur JavaScript und nicht Python. Wenn Sie mit Python-Strategien schreiben, müssen Sie in die JS-Sprache wechseln. Die grundlegende Logik von JS und Python ist ähnlich, hauptsächlich aufgrund der Grammatik.
2. Die Funktionsweise der Knoten
Q3: Werden die Knoten im Workflow gleichzeitig oder nacheinander ausgelöst?
Die Workflow-Nodes sind streng seriell, können nur einer nach dem anderen ausgelöst werden und nicht parallel ausgeführt werden. Jeder Node muss warten, bis der vorherige Node abgeschlossen ist, bevor er beginnt, und wir müssen diese Eigenschaft berücksichtigen, wenn wir eine Strategie einrichten.
Q4: Warum wartet der Workflow auf die Ausführung, nachdem der K-Line-Update-Node eingerichtet wurde?
Wenn Sie einen 1-Stunden-Trigger für K-Line-Aktualisierungen eingerichtet haben, wird der Workflow warten, bis der Punkt für die K-Line-Abschlusszeit erreicht ist, um zu starten. Während der Wartezeit wird der Workflow nicht ausgeführt, was normal ist. Wenn Sie während der Wartezeit eine andere Strategie-Logik ausführen möchten, können Sie einen zweiten Trigger einrichten, der Ihre Strategie-Logik ausführt.
3. Lesen und Speichern von Daten
Q5: Wie kann ich die Ausgabe eines Knoten lesen?
Die Standardschreibweise lautet:
javascript
$node["节点名称"].json
Diese Syntax kann die JSON-Ausgabe eines beliebigen Nodes lesen. Es ist jedoch beschränkt, nur die Daten des direkt verbundenen Elternteils zu lesen. Es kann nicht so gelesen werden, wenn keine direkte Verbindung zwischen den beiden Noten besteht.
Q6: Wie können Daten zwischen nicht direkt verbundenen Knoten geteilt werden?
Verwendbar_GGlobale Variablen_GDas ist die globale Speicherung, die der FMZ-Workflow bietet, und die Daten zwischen jedem Knoten und jedem Flow teilen kann.
Die Methode ist einfach:
javascript
// 保存数据
_G("变量名", 值)
// 读取数据
_G("变量名")
Es ist ein großes Problem._GDie Variablen werden nicht gelöscht, auch wenn die Festplatte neu gestartet wird. Wenn Sie feststellen, dass falsche alte Daten gelesen wurden, müssen Sie diese manuell einstellen._G("变量名",null)Die Festplatte wird entweder gelöscht oder direkt neu erstellt.
Q7: Wann wird JSON.stringify benötigt?
In der Praxis ist es häufig notwendig,JSON.stringifyMethode 。 Diese Methode kann komplexe Objekte und Arrays in Textstrings umwandeln, was besonders nützlich ist, wenn Daten an einen KI-Knoten übermittelt werden, da die KI nur die Eingabe in Textformat verstehen kann。
4. Die Datenübertragung der Code-Nodes
Q8: Müssen die Code-Nodes Daten zurückgeben?
Ja, das ist eine sehr wichtige Anforderung.returnGibt Daten zurück, damit die Daten zwischen den Knoten weitergeleitet werden können. Auch wenn Ihre Code-Logik keine Daten ausführen muss, gibt sie ein nulles Array zurück:
javascript
return {}
Vergessen Sie die Return, dann kann der Nachfolge-Node die Daten nicht empfangen, was den gesamten Workflow unterbrechen kann.
Q9: Wie kann man mit mehreren Daten aus den Knoten arbeiten?
Wenn ein Node mehrere Daten ausgibt, z. B. 10 Nachrichten, die Sie integriert und nicht einzeln verarbeiten müssen, können Sie diese nicht direkt an den nächsten Node weiterleiten, sondern müssen die Daten in einem Paket kombinieren.
Der Vorteil dabei ist, dass die Datenstruktur klar ist und die Nachverarbeitung an den Noten erleichtert wird. Um beispielsweise mehrere Nachrichten an die KI zu analysieren, muss zuerst ein Array zusammengefasst werden, damit die KI alle Informationen gleichzeitig sehen kann.
Fünftens: Konfiguration und Debugging von KI-Noten
Q10: Was ist die erste Sache, die bei einem Fehler im AI-Node überprüft werden sollte?
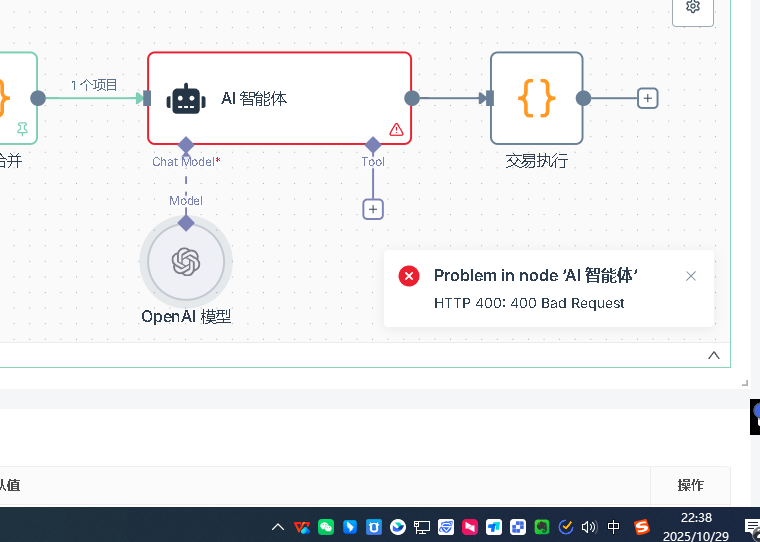
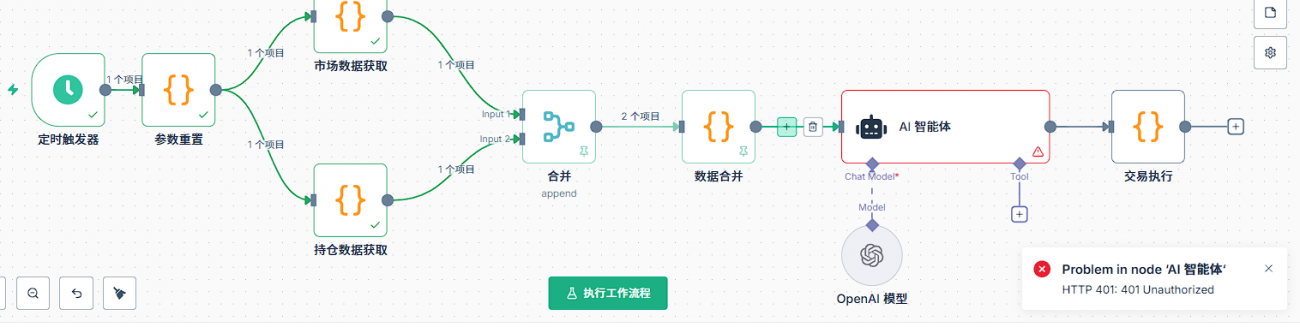
Zuerst ist die grundlegende Einstellung des AI-Knoten. Der AI-Knoten muss das Modellmodell hinzufügen, in dem die Berechtigung eingerichtet werden muss. Zuerst wird ein neuer Berechtigungsnachweis erstellt. Die Berechtigungskonfiguration enthält zwei wichtige Informationen: API-Key und Base-url.
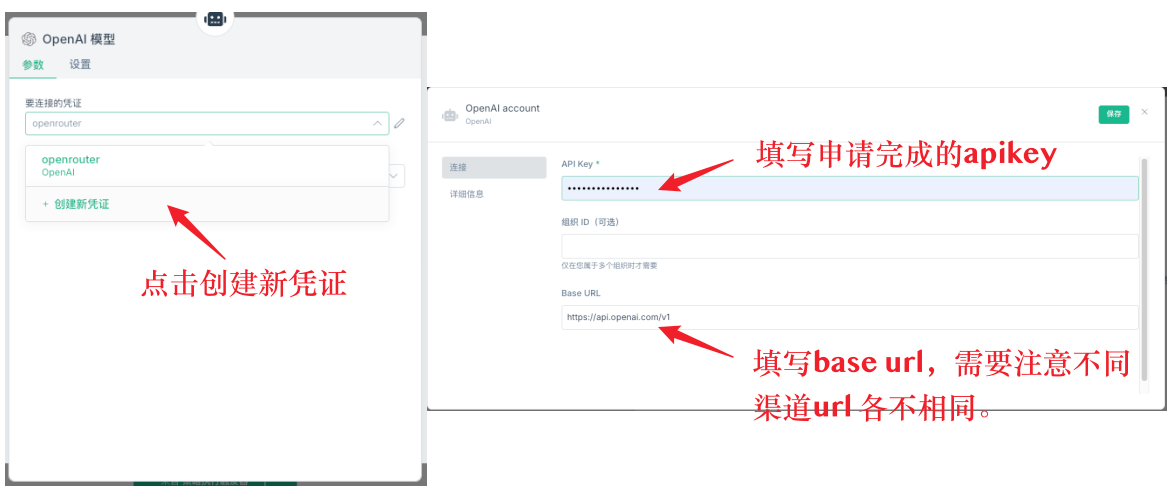
Q11: Welche API-Dienste sind besser zu verwenden?
Die direkte API von deepseek wird nicht empfohlen, da die Reaktionsgeschwindigkeit langsamer ist und die Kapazitäten begrenzt sind. Es wird empfohlen, OpenRouter zu verwenden, der sich mit verschiedenen großen Modellen verbindet, um eine bessere Stabilität und Geschwindigkeit zu erzielen.
Q12: Gibt es Gebühren für die Nutzung von KI?
Ja, es ist teuer, KI-Aufrufe zu tätigen, und jede Anfrage verbraucht Token. Wenn ein Aufruf fehlschlägt, überprüfen Sie, ob der Kontostand ausreichend ist. Es wird empfohlen, ein billiges Modell für die Teststrategie-Logikphase zu verwenden, um die richtige Strategie-Logik zu bestätigen und dann in ein leistungsfähigeres Modell zu wechseln.
Q13: Wie schreibt man eine effektive KI-Prompt?
Das ist eine Kunst, die sich an den Eigenschaften verschiedener Großmodelle optimieren lässt. Grok ist beispielsweise aggressiver, Claude ist vorsichtiger, DeepSeek hat eine natürliche Neigung zum Mehrmachen, da er mit A-Stock-Daten trainiert wurde.
6. Stabilität und Windkontrolle der KI-Modelle
Q14: Ist die Entscheidungsfindung des KI-Modells stabil?
Das KI-Modell ist noch nicht vollständig stabil. Obwohl die KI die Entscheidungsqualität von Strategien verbessern kann, kann sie selbst auch Fehleinschätzungen verursachen. Unterschiedliche Marktumgebungen, unterschiedliche Pressemitteilungen und sogar die gleiche Eingabe können zu unterschiedlichen Zeiten unterschiedliche Ausgänge erhalten. Diese Unsicherheit ist eine inhärente Eigenschaft der KI.
Q15: Was ist bei der Anwendung von KI-Strategien zu beachten?
Bei der Verwendung von KI-Strategien müssen strenge Risikokontrollmaßnahmen ergänzt werden. Zum Beispiel: Setzen Sie eine Maximalverlustgrenze für einen einzelnen Handel, setzen Sie eine Obergrenze für die Gesamtposition, fügen Sie eine Stop-Loss-Stop-Logik hinzu, lassen Sie die KI nicht die volle Kontrolle über das Geld haben.
KI sollte ein Hilfsmittel für Ihre Entscheidungen sein und nicht das Objekt, das Sie mit Vollmacht beauftragen. Es gibt immer eine manuelle Überwachung und Risikokontrolle. Mit der Entwicklung der KI-Technologie werden die Modelle immer stabiler, aber es ist klug, vorsichtig zu sein.
7. Die Besonderheiten von AI-Strategien
Q16: Können Strategien, die KI beinhalten, normal zurückverfolgt werden?
Strategien mit KI sind sehr spezifisch in Bezug auf die Rückmessung, was klar zu verstehen ist. Die herkömmlichen Strategien können mit historischen Daten nach Belieben zurückgespürt werden, aber die KI-Strategie nicht.
Warum? Weil jeder Einsatz von KI Token verbraucht und tatsächlich Kosten verursacht. Wenn man mit einem Jahr an historischen Daten zurückblickt, könnten Tausende von Einsätzen von KI erforderlich sein, was sehr teuer wäre.
Um den Geldbeutel zu schützen, hat FMZ einen Mechanismus entwickelt: In der Rückmessmodus wird der KI-Node nur drei echte Aufrufe gemacht, die anschließend die drei Cache-Daten verwenden. Die Rückmessresultate sind also nur ein Referenz, sie repräsentieren nicht die Qualität der echten KI-Entscheidungen.
Q17: Können KI-Strategien mit aktuellen Nachrichten zurückverfolgt werden?
Wenn Ihre Strategie auf die neuesten Nachrichten zurückgreift, ist die Rückmeldung noch unlogischer, da Sie die Daten der K-Linie der Vergangenheit verwenden, aber die aktuellen Nachrichten lesen, und die beiden Zeiten stimmen nicht überein, so dass die Rückmeldung sinnlos ist.
Q18: Wie sollte man eine KI-Strategie testen?
Die empfohlene Methode ist: mit kleinen Mitteln und in kleinen Zyklen in der Praxis zu testen, die Qualität der AI-Entscheidungen und die Strategie-Performance zu beobachten, nach der Stabilisierung nach und nach zu erhöhen. Für die AI-Strategie ist die Überprüfung in der Praxis viel wichtiger als die historische Rückvergleiche.
8. Konfigurierung von HTTP- und MCP-Knoten
Q19: Was ist mit HTTP-Noten, die keine Daten erhalten?
HTTP-Noten und MCP-Noten werden normalerweise verwendet, um externe Daten zu erhalten, aber viele API-Dienste benötigen einen Schlüssel, um darauf zuzugreifen. Wenn Sie HTTP-Anfragen konfiguriert haben, aber keine Daten erhalten, überprüfen Sie, ob Sie einen API-Schlüssel benötigen und ob die Authentifizierungsdaten korrekt konfiguriert sind. Einige APIs haben auch eine Frequenzbeschränkung für Anfragen, die bei zu häufigen Aufrufen eingeschränkt oder sogar gesperrt werden.
Q20: Wie kann die Stabilität der externen Datenerfassung verbessert werden?
MCP-Nodes sind leistungsfähiger und können an verschiedene strukturierte Datendienste angeschlossen werden, sind aber auch komplexer konfiguriert. Es ist erforderlich, die Service-Endpunkte, die Authentifizierungsmethoden, die Anforderungsparameter usw. richtig einzurichten. Es wird empfohlen, zuerst mit HTTP-Noten zu testen, ob die API normal zugänglich ist, und das Datenformat zu bestätigen, um es dann in den Workflow zu integrieren.
Zusätzlich können diese Knoten mit einem Failure-Retry-Mechanismus ausgestattet werden, um die Stabilität zu erhöhen. In den Knoten-Einstellungen können die Wiederholungsversuche gestartet und die Wiederholungsfrequenz und -intervalle festgelegt werden, so dass temporäre Netzwerkprobleme nicht zum Ausfall des gesamten Workflows führen.
9. Probleme mit der Code-Kompatibilität
Q21: Können FMZ-Workflows und n8n-Codes miteinander kombiniert werden?
Der Inventor-Workflow basiert auf dem n8n Open-Source-Framework und ist maßgeschneidert, aber der Code der beiden kann nicht direkt miteinander kopiert werden. Wenn Sie den n8n-Workflow-Code im Internet finden, funktioniert es nicht, ihn direkt in FMZ zu kopieren, sondern es müssen Änderungen an den API- und Node-Spezifikationen von FMZ vorgenommen werden. Umgekehrt kann der FMZ-Workflow-Code nicht direkt auf n8n verwendet werden.
Die Hauptunterschiede bestehen darin, dass die FMZ bestimmte Nodes individuell modifiziert hat. Die Parameter und das Ausgabeformat sind unterschiedlich. Wenn der Code migriert werden soll, müssen die Konfiguration und die Funktionsaufrufe jedes einzelnen Nodes sorgfältig geprüft werden, um sicherzustellen, dass sie den Spezifikationen der Zielplattform entsprechen.
Zusammenfassen
Dies sind die Antworten auf die häufigsten Fragen der Erfinder zur Quantifizierung von Workflows. Wir decken alle Aspekte ab, die von der Umgebungskonfiguration, der Knotenmechanik, dem Datenlesen, der Code-Spezifikation, der KI-Aufrufung bis hin zum Feedback-Test häufig auftreten.
Aber Quantifizierung ist ein ständiger Lernprozess, und neue Probleme werden immer wieder auftauchen. Wenn Sie Probleme haben, lassen Sie sich nicht entmutigen, schauen Sie sich zuerst die offiziellen Dokumente von FMZ an, suchen Sie in den Diskussionen in der Community, viele Probleme haben bereits vorherige Probleme.
Denken Sie daran: Probleme sind die besten Lehrer, und mit jeder Lösung erhalten Sie ein tieferes Verständnis für den Workflow. Hoffentlich hilft Ihnen diese FAQ dabei, die Quantifizierungsstrategien für die Entwicklung von Workflows besser zu nutzen!


- 1