
Eine vollständige Erklärung der Vor- und Nachteile der drei Hauptkategorien und sechs Hauptalgorithmen des maschinellen Lernens
In der Methode des maschinellen Lernens ist das Ziel entweder die Vorhersage oder das Clustering. In diesem Artikel geht es um die Vorhersage. Die Vorhersage ist der Prozess, den Wert einer Ausgabevariable aus einer Gruppe von Eingabevariablen zu prognostizieren.
Wir haben die Algorithmen in drei Kategorien unterteilt: lineare Modelle, Baum-basierte Modelle und neuronale Netzwerke. Hier sind sechs der am häufigsten verwendeten Algorithmen:
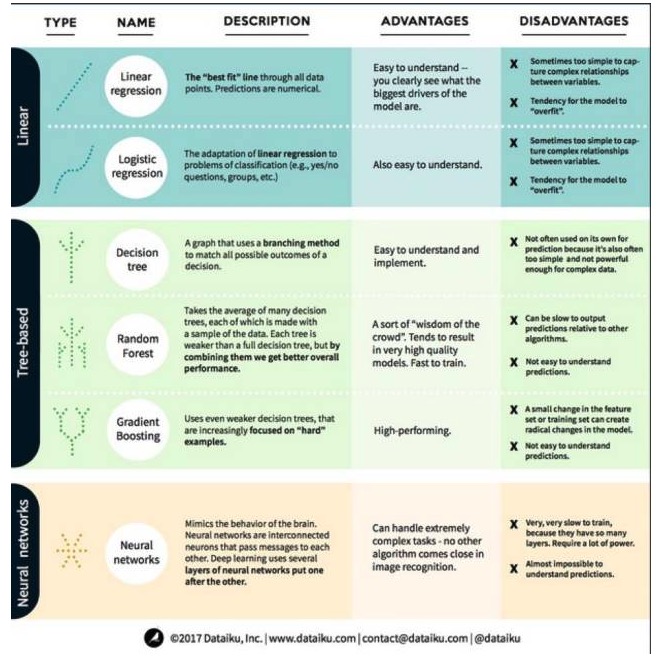
Ein Linearmodell-Algorithmus: Ein Linearmodell verwendet einfache Formeln, um die optimal geeignete Linie für den Quadrat durch eine Reihe von Datenpunkten zu finden. Diese Methode, die mehr als 200 Jahre alt ist, ist in der Statistik und im Bereich des maschinellen Lernens weit verbreitet. Sie ist aufgrund ihrer Einfachheit für die Statistik nützlich.
-
1. Lineare Regression
Die lineare Regression, oder genauer gesagt die Regression zum Minimum, ist die standardisierteste Form eines linearen Modells. Sie ist das einfachste lineare Modell für Regressionsprobleme. Ihr Nachteil ist, dass die Modelle leicht zu überpassen sind, d. h. dass sie sich vollständig an die geschulten Daten anpassen, auf Kosten ihrer Fähigkeit, neue Daten zu verbreiten.
Ein weiterer Nachteil von linearen Modellen ist, dass sie, da sie sehr einfach sind, nicht leicht das Verhalten von komplexeren Variablen vorhersagen können, wenn die eingegebenen Variablen nicht unabhängig sind.
-
2. Logische Regression
Die logische Regression ist eine Anpassung der linearen Regression an die Klassifizierungsfrage. Die logische Regression hat die gleichen Nachteile wie die lineare Regression. Die logische Funktion ist sehr gut für die Klassifizierungsfrage, da sie die Threshold-Effekte einführt.
2. Algorithmen für Baummodelle
-
1. Entscheidungsbaum
Ein Entscheidungsbaum ist ein Diagramm, das jedes mögliche Ergebnis einer Entscheidung anhand einer verzweigten Methode darstellt. Sagen wir, Sie haben sich entschieden, einen Salat zu bestellen, und Ihre erste Entscheidung könnte die Art des Gemüses sein, dann die Art des Essens, dann die Art des Salats.
Um die Entscheidungsträucher zu trainieren, müssen wir die Trainingsdatensätze verwenden und herausfinden, welche Eigenschaft am nützlichsten für das Ziel ist. In einem Fraud-Detection-Anwendungsfall, zum Beispiel, könnten wir feststellen, dass die Eigenschaft, die am meisten zur Vorhersage des Betrugsrisikos beiträgt, das Land ist. Nach dem Abzweigen mit der ersten Eigenschaft erhalten wir zwei Subsätze, die wir am besten vorhersagen können, wenn wir nur die erste Eigenschaft kennen.
-
2. Zufällige Wälder
Ein zufälliger Wald ist der Durchschnitt von vielen Entscheidungsträumen, bei denen jeder Entscheidungsbaum mit einem zufälligen Datensatz trainiert wird. Jeder Baum im zufälligen Wald ist schwächer als ein vollständiger Entscheidungsbaum, aber wenn wir alle Bäume zusammenlegen, können wir aufgrund der Vorteile der Vielfalt eine bessere Gesamtleistung erzielen.
Der Random Forest ist ein sehr beliebter Algorithmus im heutigen Maschinellen Lernen. Der Random Forest ist leicht zu trainieren und funktioniert ziemlich gut. Sein Nachteil ist, dass die Prognose der Random Forest-Ausgabe im Vergleich zu anderen Algorithmen möglicherweise langsam ist, so dass der Random Forest möglicherweise nicht ausgewählt wird, wenn eine schnelle Prognose erforderlich ist.
-
3. Steigerung
GradientBoosting besteht, wie auch Random Forest, aus schwachen und schwachen Entscheidungsträumen. Der größte Unterschied zwischen GradientBoosting und Random Forest besteht darin, dass bei GradientBoosting die Bäume eins nach dem anderen trainiert werden. Jeder nachfolgende Baum wird hauptsächlich durch die falschen Daten der vorangegangenen Bäume trainiert.
Das Training mit der Gradientsteigerung ist schnell und sehr gut. Kleine Veränderungen des Trainingsdatensatzes können jedoch zu grundlegenden Änderungen des Modells führen, so dass die Ergebnisse, die es liefert, möglicherweise nicht die besten sind.
3. Neuralnetzwerk-Algorithmen: Neuralnetzwerke sind biologische Phänomene, die sich aus miteinander verbundenen Neuronen im Gehirn zusammensetzen, um Informationen miteinander auszutauschen. Diese Idee wird jetzt auf das Gebiet des maschinellen Lernens angewendet und wird als ANN (Artificial Neural Network) bezeichnet.
Übertragung von Big Data Land
- 1