
1. Einleitung
Der vorherige Artikel stellte die Verwendung des LSTM-Netzwerks zur Vorhersage von Bitcoin-Preisen vor https://www.fmz.com/digest-topic/4035. Wie im Artikel erwähnt, handelt es sich nur um ein kleines Projekt zum Üben und Kennenlernen von RNN und PyTorch . In diesem Artikel wird die Verwendung von Methoden des bestärkenden Lernens zum direkten Trainieren von Handelsstrategien vorgestellt. Das bestärkende Lernmodell ist das von OpenAI bereitgestellte PPO und die Umgebung basiert auf dem Fitnessstudio-Stil. Um das Verständnis und Testen zu erleichtern, werden das LSTM-PPO-Modell und die Backtesting-Gym-Umgebung direkt geschrieben, ohne vorgefertigte Pakete zu verwenden.
PPO, der vollständige Name von Proximal Policy Optimization, ist eine Optimierungsverbesserung von Policy Gradient, also Policy Gradient. Gym wird auch von OpenAI veröffentlicht. Es kann mit dem Richtliniennetzwerk interagieren und den aktuellen Zustand und die Belohnung der Umgebung zurückmelden. Es ist wie die Verstärkungslernübung, die das LSTM-PPO-Modell verwendet, um direkt Kauf-, Verkaufs- oder Nicht-Operationen basierend auf dem durchzuführen Marktinformationen zu Bitcoin. Anweisungen werden von der Backtesting-Umgebung gegeben und das Modell wird durch Training kontinuierlich optimiert, um das Ziel der Strategierentabilität zu erreichen.
Das Lesen dieses Artikels erfordert gewisse Grundlagen in Python, PyTorch und DRL Deep Reinforcement Learning. Aber es macht nichts, wenn Sie nicht wissen, wie das geht. Mit dem in diesem Artikel angegebenen Code ist es leicht zu lernen und loszulegen. Dieser Artikel wurde von FMZ erstellt, dem Erfinder der quantitativen Handelsplattform für digitale Währungen (www.fmz.com). Willkommen in der QQ-Gruppe: 863946592 zur Kommunikation.
2. Daten und Lernreferenzen
Die Bitcoin-Preisdaten stammen von der quantitativen Handelsplattform des FMZ-Erfinders: https://www.quantinfo.com/Tools/View/4.html
Ein Artikel zur Verwendung von DRL+gym zum Trainieren von Handelsstrategien: https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4
Einige Beispiele für den Einstieg in Pytorch: https://github.com/yunjey/pytorch-tutorial
Dieser Artikel verwendet direkt diese kurze Implementierung des LSTM-PPO-Modells: https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py
Artikel über PPO: https://zhuanlan.zhihu.com/p/38185553
Weitere Artikel zu DRL: https://www.zhihu.com/people/flood-sung/posts
Bezüglich des Fitnessstudios muss dieser Artikel nicht installiert werden, aber bestärkendes Lernen ist sehr verbreitet: https://gym.openai.com/
3.LSTM-PPO
Für eine ausführliche Erklärung von PPO können Sie die vorherigen Referenzen studieren. Hier ist nur eine Einführung in das einfache Konzept. In der vorherigen Ausgabe hat das LSTM-Netzwerk nur einen Preis vorhergesagt. Wie man auf der Grundlage dieses vorhergesagten Preises Kauf- und Verkaufstransaktionen durchführt, muss separat implementiert werden. Natürlich kann man sich vorstellen, dass es direkter wäre, die Kauf- und Verkaufsaktionen direkt auszugeben , Rechts? Policy Gradient funktioniert folgendermaßen: Es kann die Wahrscheinlichkeit verschiedener Aktionen basierend auf den eingegebenen Umgebungsinformationen angeben. Der Verlust von LSTM ist die Differenz zwischen dem vorhergesagten Preis und dem tatsächlichen Preis, während der Verlust von PG -log(p) beträgt.*Q, wobei p die Wahrscheinlichkeit ist, dass eine Aktion ausgegeben wird, und Q der Wert der Aktion (z. B. der Belohnungswert). Die intuitive Erklärung ist, dass das Netzwerk eine höhere Wahrscheinlichkeit ausgeben sollte, wenn der Wert einer Aktion höher ist um den Verlust zu reduzieren. Obwohl PPO viel komplizierter ist, ist das Prinzip ähnlich. Der Schlüssel liegt darin, den Wert jeder Aktion besser zu bewerten und die Parameter besser zu aktualisieren.
Der Quellcode von LSTM-PPO ist unten angegeben und kann in Kombination mit den vorherigen Informationen verstanden werden:
python
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
#模型的超参数
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # 也可以改为GPU版本
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
#输出各个动作的概率,由于是LSTM网络还要包含hidden层的信息,可以参考上一期文章
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
#价值函数,用于评价当前局面的好坏,所以只有一个输出
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
#准备训练数据
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) #同时训练了价值网络和决策网络
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. Bitcoin-Backtesting-Umgebung
Gemäß dem Format des Fitnessstudios gibt es eine Reset-Initialisierungsmethode, eine Schritteingabeaktion und das zurückgegebene Ergebnis ist (nächster Status, Aktionsvorteil, ob sie abgeschlossen ist, zusätzliche Informationen). Die gesamte Backtest-Umgebung besteht nur aus 60 Zeilen, die von Ihnen selbst geändert. Komplexe Version, spezifischer Code:
python
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks #初始的比特币数量
self.initial_balance = initial_balance #初始的资产
self.current_time = 0 #回测的时间位置
self.commission = commission #易手续费
self.done = False #回测是否结束
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) #标准化方法,简单的收益率标准化
self.mode = all_data # 是否为抽样回测模式
self.sample_length = 500 # 抽样长度
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
#action即策略采取的动作,这里将更新账户和计算reward
done = False
if action == 0: #持有
pass
elif action == 1: #买入
buy_value = self.balance*0.5
if buy_value > 1: #余钱不足,不操作账户
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: #卖出
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # 每回合的reward是新增收益
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. Mehrere bemerkenswerte Details
Warum verfügt das Startkonto über Münzen?
Die Formel zur Berechnung der Rendite in der Backtesting-Umgebung lautet: Aktuelle Rendite = Aktueller Kontowert – Aktueller Anfangswert des Kontos. Dies bedeutet, dass, wenn der Preis von Bitcoin fällt und die Strategie die Münzen verkauft, die Strategie tatsächlich belohnt werden sollte, selbst wenn der Gesamtkontowert sinkt. Bei einem langen Backtesting-Zeitraum ist das ursprüngliche Konto möglicherweise nicht stark betroffen, hat aber zu Beginn dennoch große Auswirkungen. Durch die Berechnung der relativen Rendite wird sichergestellt, dass jede korrekte Operation eine positive Belohnung erhält.
Warum führen wir im Rahmen der Schulung eine Marktsondierung durch?
Die Gesamtdatenmenge beträgt mehr als 10.000 K-Zeilen. Wenn jedes Mal ein vollständiger Zyklus ausgeführt wird, dauert dies lange und die Strategie wird jedes Mal mit genau derselben Situation konfrontiert, was zu einer Überanpassung führen kann. Als Backtest-Daten werden jedes Mal 500 Balken gezeichnet. Obwohl Überanpassung immer noch möglich ist, sieht sich die Strategie mit mehr als 10.000 verschiedenen möglichen Starts konfrontiert.
Was tun, wenn Sie kein Kleingeld oder Geld haben?
Diese Situation wird in der Backtest-Umgebung nicht berücksichtigt. Wenn die Münze ausverkauft ist oder das Mindesttransaktionsvolumen nicht erreicht wird, ist die Ausführung des Verkaufsvorgangs zu diesem Zeitpunkt tatsächlich gleichbedeutend mit der Ausführung keiner Operation. Wenn der Preis fällt, gemäß der relativen Die Methode zur Berechnung der Rendite basiert weiterhin auf der positiven Belohnung der Strategie. Die Auswirkung dieser Situation besteht darin, dass, wenn die Strategie feststellt, dass der Markt fällt und die verbleibenden Münzen auf dem Konto nicht verkauft werden können, es unmöglich ist, zwischen Verkaufsaktionen und Nicht-Operationen zu unterscheiden, aber es hat keinen Einfluss auf das eigene Urteil der Strategie über der Markt.
Warum Kontoinformationen als Status zurückgeben?
Das PPO-Modell verfügt über ein Wertnetzwerk, mit dem der Wert des aktuellen Zustands bewertet wird. Wenn die Strategie feststellt, dass der Preis steigen wird, hat der gesamte Zustand natürlich nur dann einen positiven Wert, wenn das aktuelle Konto Bitcoin enthält, und umgekehrt. Daher sind Kontoinformationen eine wichtige Grundlage zur Beurteilung des Wertschöpfungsnetzwerks. Beachten Sie, dass die Informationen zu vergangenen Aktionen nicht als Status zurückgegeben werden, was meiner Meinung nach zur Wertbeurteilung unbrauchbar ist.
Unter welchen Umständen wird „Kein Vorgang“ zurückgegeben?
Wenn die Strategie ergibt, dass der Gewinn aus Kauf und Verkauf die Transaktionsgebühr nicht decken kann, sollte sie auf „Keine Aktion“ zurückgeführt werden. Obwohl in der vorherigen Beschreibung wiederholt Strategien zur Ermittlung von Preistrends verwendet wurden, diente dies nur der besseren Verständlichkeit. Tatsächlich macht dieses PPO-Modell keine Vorhersagen über den Markt, sondern gibt nur die Wahrscheinlichkeiten von drei Aktionen aus.
6. Datenerfassung und Schulung
Wie im vorherigen Artikel werden die Daten im folgenden Format abgerufen: die einstündige K-Linie des BTC_USD-Handelspaares an der Bitfinex-Börse vom 07.05.2018 bis 27.06.2019:
python
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
Da das LSTM-Netzwerk verwendet wurde, war die Trainingszeit sehr lang, sodass ich auf eine GPU-Version umgestiegen bin, die etwa dreimal schneller war.
python
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 #记录总收益
profit_list = [] #记录每次训练收益
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. Trainingsergebnisse und Analyse
Nach langem Warten:

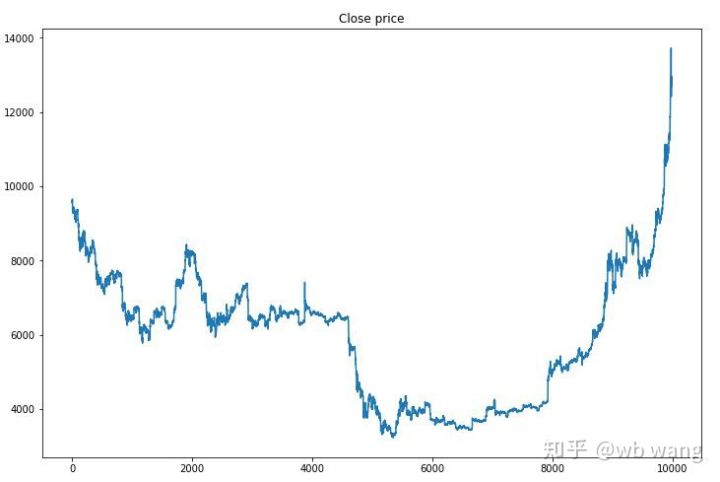
Werfen wir zunächst einen Blick auf die Markttrends der Trainingsdaten. Generell war die erste Hälfte von einem langen Rückgang geprägt, die zweite von einer starken Erholung.
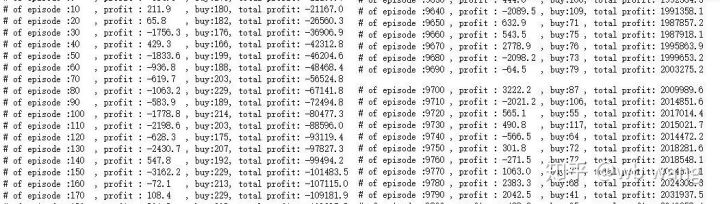
In der Anfangsphase des Trainings gibt es viele Kaufvorgänge und grundsätzlich keine gewinnbringenden Runden. Bis zur Mitte der Trainingsphase nahm die Anzahl der Käufe allmählich ab und die Gewinnwahrscheinlichkeit wurde immer größer, es bestand jedoch immer noch eine hohe Verlustwahrscheinlichkeit.
Glättet man den Umsatz pro Runde, ergeben sich folgende Ergebnisse:
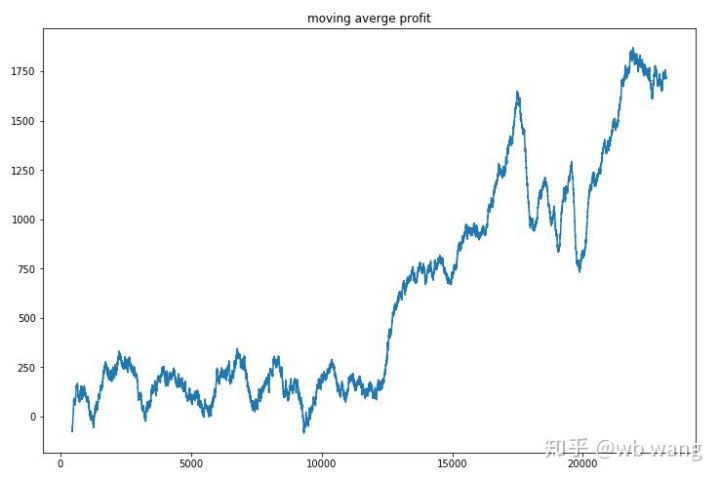
Die Strategie beseitigte die negativen Renditen in den Anfangsphasen schnell, aber die Schwankungen waren groß. Erst nach 10.000 Runden begannen die Renditen schnell zu wachsen. Im Allgemeinen war das Training des Modells schwierig.
Nachdem das letzte Training abgeschlossen ist, lassen Sie das Modell alle Daten erneut ausführen, um zu sehen, wie es funktioniert. Notieren Sie während dieses Zeitraums den gesamten Marktwert des Kontos, die Anzahl der gehaltenen Bitcoins, den Anteil des Bitcoin-Werts und das Gesamteinkommen .
Zunächst der Gesamtmarktwert. Der Gesamtumsatz ist ähnlich, deshalb werde ich ihn hier nicht veröffentlichen:
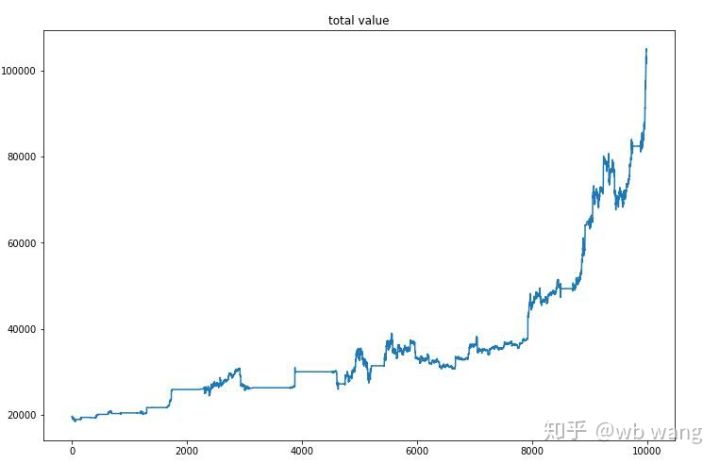
Der Gesamtmarktwert stieg während der frühen Baisse langsam an und hielt auch während der späteren Hausse mit dem Anstieg Schritt, es kam jedoch weiterhin zu periodischen Verlusten.
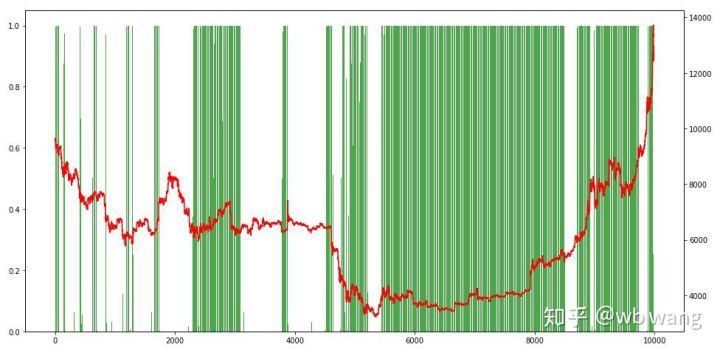
Schauen wir uns zum Schluss noch den Anteil der Positionen an. Die linke Achse des Diagramms stellt den Anteil der Positionen dar, die rechte Achse die Marktsituation. Es lässt sich vorläufig feststellen, dass das Modell überangepasst ist. Die Häufigkeit der Positionen betrug niedrig im frühen Bärenmarkt, und die Häufigkeit der Positionen war am Markttief sehr hoch. Wir sehen außerdem, dass das Modell nicht gelernt hat, Positionen lange zu halten und immer schnell verkauft.
8. Testdatenanalyse
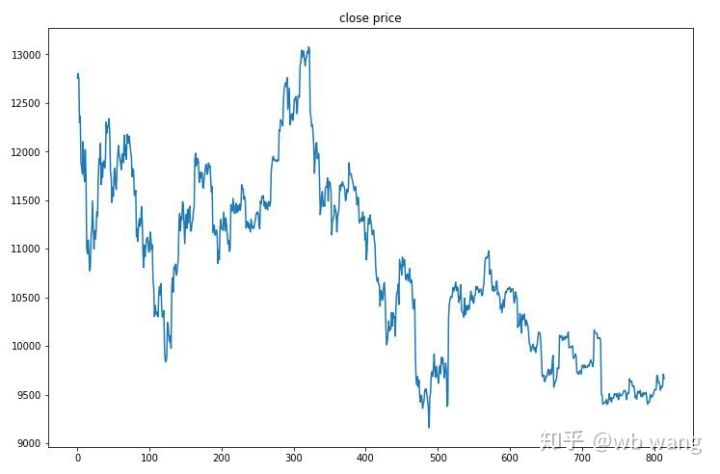
Die Testdaten wurden aus dem einstündigen Bitcoin-Markt vom 27.06.2019 bis heute gewonnen. Wie aus der Abbildung ersichtlich ist, ist der Preis von anfangs 13.000 \( auf heute über 9.000 \) gefallen, was ein großartiger Test für das Modell ist.
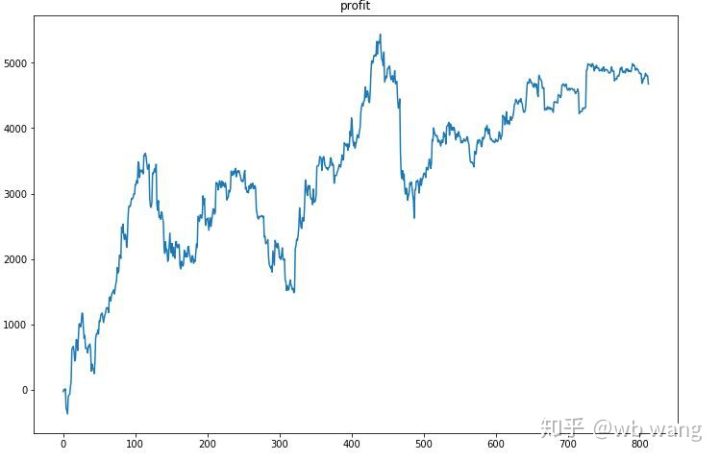
Zunächst einmal war die relative Rendite am Ende nicht zufriedenstellend, es entstand jedoch auch kein Verlust.
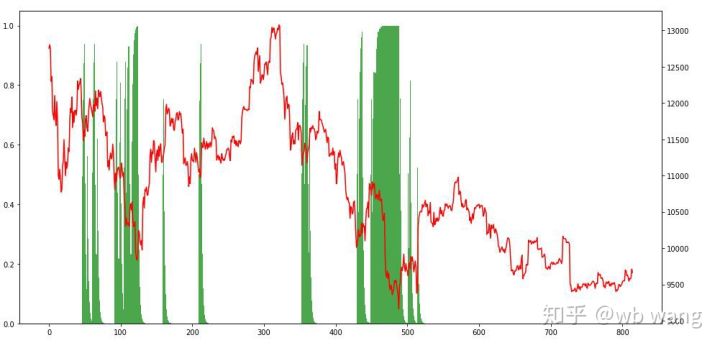
Wenn wir uns die Positionen ansehen, können wir vermuten, dass das Modell dazu neigt, nach einem starken Rückgang zu kaufen und nach einer Erholung zu verkaufen. In letzter Zeit schwankte der Bitcoin-Markt sehr wenig und das Modell befand sich in einer Short-Position.
9. Zusammenfassung
In diesem Artikel wird die Deep-Reinforcement-Learning-Methode PPO verwendet, um einen automatischen Bitcoin-Handelsroboter zu trainieren, und es werden einige Schlussfolgerungen gezogen. Aufgrund der begrenzten Zeit gibt es noch einige Bereiche, die im Modell verbessert werden können. Jeder ist herzlich eingeladen, darüber zu diskutieren. Die wichtigste Lektion ist, dass die Datenstandardisierung die richtige Methode ist. Verwenden Sie keine Methoden wie Skalierung, da sich das Modell sonst schnell an die Beziehung zwischen Preis und Marktbedingungen erinnert und in eine Überanpassung gerät. Nach der Normalisierung wird die Änderungsrate zu relativen Daten, was es für das Modell schwierig macht, sich an seine Beziehung zum Markt zu erinnern, und es zwingt, die Verbindung zwischen der Änderungsrate und dem Anstieg und Abfall zu finden.
Vorherige Artikel:
Einige öffentliche Strategiefreigaben auf der FMZ Inventor Quantitative Platform: https://zhuanlan.zhihu.com/p/64961672
Kurs zum quantitativen Handel mit digitalen Währungen von NetEase Cloud Classroom, nur 20 Yuan: https://study.163.com/course/courseMain.htm?courseId=1006074239&share=2&shareId=400000000602076
Ich habe eine Hochfrequenzstrategie veröffentlicht, die einst sehr profitabel war: https://www.fmz.com/bbs-topic/1211


profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.current_time,4]) 有bug
应该是:profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.start,4])
profit = self.value - (self.initial_balance+self.initial_stocksself.df.iloc[self.current_time,4]) 有bug
应该是:profit = self.value - (self.initial_balance+self.initial_stocksself.df.iloc[self.start,4])




GPU版
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class PPO(nn.Module):
def __init__(self):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(8,64)
self.lstm = nn.LSTM(64,32)
self.fc_pi = nn.Linear(32,3)
self.fc_v = nn.Linear(32,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 64)
x, lstm_hidden = self.lstm(x, hidden )
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 64)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float).to(device), torch.tensor(a_lst).to(device).to(device), \
torch.tensor(r_lst).to(device), torch.tensor(s_prime_lst, dtype=torch.float).to(device), \
torch.tensor(done_lst, dtype=torch.float).to(device), torch.tensor(prob_a_lst).to(device)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.to(device).detach(), h2.to(device).detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.cpu().detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float).to(device)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach())
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
- 1