
Muchos desarrolladores han planteado una gran cantidad de preguntas en las áreas de comentarios y comunidades en el proceso de uso de la flujo de trabajo de inventor de inventor. Este artículo recopila estos problemas de alta frecuencia, que abarcan la configuración del entorno, el uso de nodos, la lectura de datos, la invocación de AI y el mecanismo de retroalimentación, para ayudar a encontrar soluciones rápidamente.
I. Problemas de configuración del entorno
Q1: ¿Por qué mi disco duro no puede ejecutar la estrategia de flujo de trabajo?
Solo los administradores con la versión más reciente de la aplicación pueden ejecutar el flujo de trabajo. Si la versión de su administrador es demasiado antigua, la política de flujo de trabajo no se puede iniciar y debe actualizarse a la versión más reciente.
Q2: ¿Qué lenguajes de programación soporta el flujo de trabajo?
Los nodos de código del flujo de trabajo solo soportan JavaScript, no soportan Python. Si estás acostumbrado a escribir estrategias en Python, necesitas convertirte a la gramática de JS. Bueno, la lógica básica de JS y Python es similar, principalmente las diferencias gramaticales.
Mecanismos de funcionamiento de los nodos
Q3: ¿Los nodos en el flujo de trabajo se activan simultáneamente o en secuencia?
Los nodos de flujo de trabajo son estrictamente en serie, sólo pueden ser activados uno tras otro, no funcionan en paralelo. Cada nodo debe esperar a que el nodo anterior termine de ejecutarse para comenzar, y se debe tener en cuenta esta característica al configurar el mecanismo de la política.
Q4: ¿Por qué el flujo de trabajo no se ejecuta después de configurar el punto de actualización de la línea K?
Si se configura el gatillo de actualización de la línea K de 1 hora, el flujo de trabajo esperará hasta que la línea K se cierre en un punto entero para comenzar a funcionar. Durante la espera, el flujo de trabajo no se ejecutará, lo cual es normal. Si desea ejecutar una lógica de política diferente durante la espera, se puede configurar un segundo gatillo para ejecutar la lógica de su política.
C. Lectura de datos y conservación de variables
Q5: ¿Cómo leer los datos de salida de un nodo?
La ortografía estándar es:
javascript
$node["节点名称"].json
Esta sintaxis puede leer la salida JSON de cualquier nodo. Pero hay una restricción: solo se puede leer el dato del nodo padre directamente conectado. No se puede leer de esta manera si no hay una relación directa entre los dos nodos.
Q6: ¿Cómo se comparten datos entre nodos que no están directamente conectados?
Se puede usar_GVariables globales_GEs el almacenamiento interno global proporcionado por el flujo de trabajo FMZ, que permite compartir datos entre cualquier nodo y cualquier flujo.
La forma de hacerlo es simple:
javascript
// 保存数据
_G("变量名", 值)
// 读取数据
_G("变量名")
Pero hay que tener cuidado._GLas variables se mantendrán y no se eliminarán incluso si se reinicia el disco duro. Si se descubre que se han leído datos antiguos erróneos, se necesita una configuración manual._G("变量名",null)Para borrar, o simplemente borrar el disco duro y volver a crearlo.
Q7: ¿Cuándo es necesario usar JSON.stringify?
En el tratamiento de datos complejos, a menudo se requiereJSON.stringifyEste método permite convertir objetos y arrays complejos en cadenas de texto, lo cual es especialmente útil al transmitir datos a un nodo de IA, ya que la IA solo puede entender las entradas en formato de texto.
Transmisión de datos por los nodos de código
Q8: ¿Los nodos de código tienen que devolver datos?
Sí, es un requisito muy importante.returnDevuelve datos para mantener los datos entre los nodos. Incluso si la lógica de tu código no necesita producir ningún dato, devuelve una matriz vacía:
javascript
return {}
Si se olvida el return, los nodos de seguimiento no pueden recibir los datos, lo que interrumpe el flujo de trabajo.
Q9: ¿Cómo se manejan los datos múltiples de la salida de un nodo?
Si un nodo de tu computadora emite varios datos, por ejemplo, 10 noticias, y necesitas procesarlos de forma integrada en lugar de hacerlo por separado, no puedes pasarlos directamente al siguiente nodo, sino que debes usar un nodo de fusión o agregación para integrar varios datos en un paquete.
La ventaja de esto es que la estructura de los datos es clara, lo que facilita el procesamiento de los nodos posteriores. Por ejemplo, para transmitir varias noticias al análisis de la IA, se necesita primero agrupar una matriz, para que la IA pueda ver toda la información a la vez.
V. Configuración y puesta en marcha de los nodos de IA
Q10: ¿Cuál es la primera cosa que se debe revisar cuando hay un error en un nodo de IA?
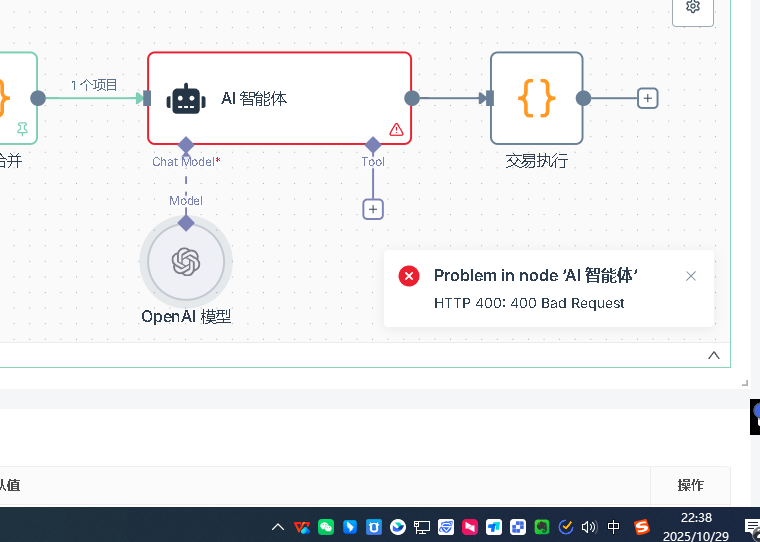
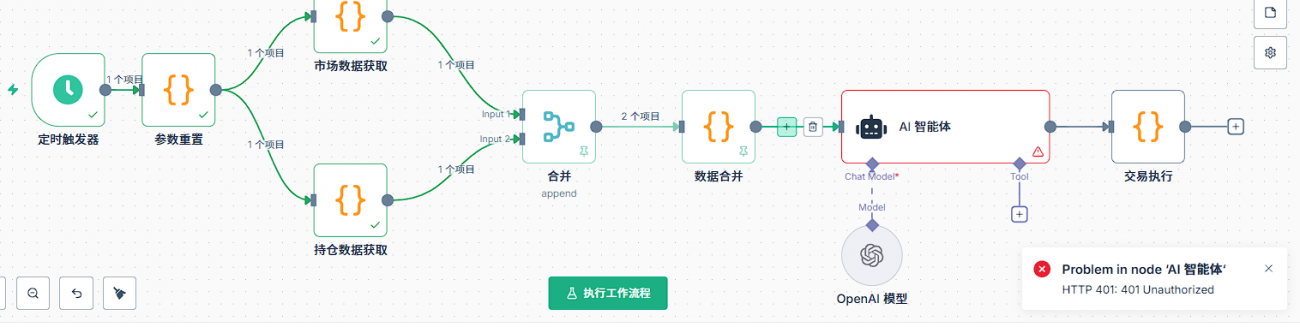
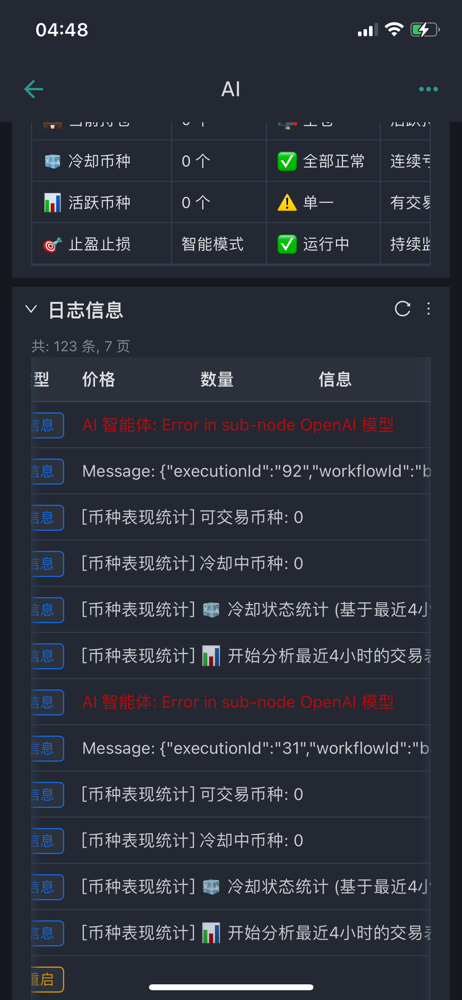
La primera es la configuración básica de los nodos AI. Los nodos AI necesitan agregar un modelo de modelo, en el modelo se debe configurar una credencial. Primero se crea una nueva credencial, la configuración de la credencial incluye dos información clave: clave API y base url. La clave API es la clave que solicita en la plataforma correspondiente, y la base url es la dirección de solicitud de la API.
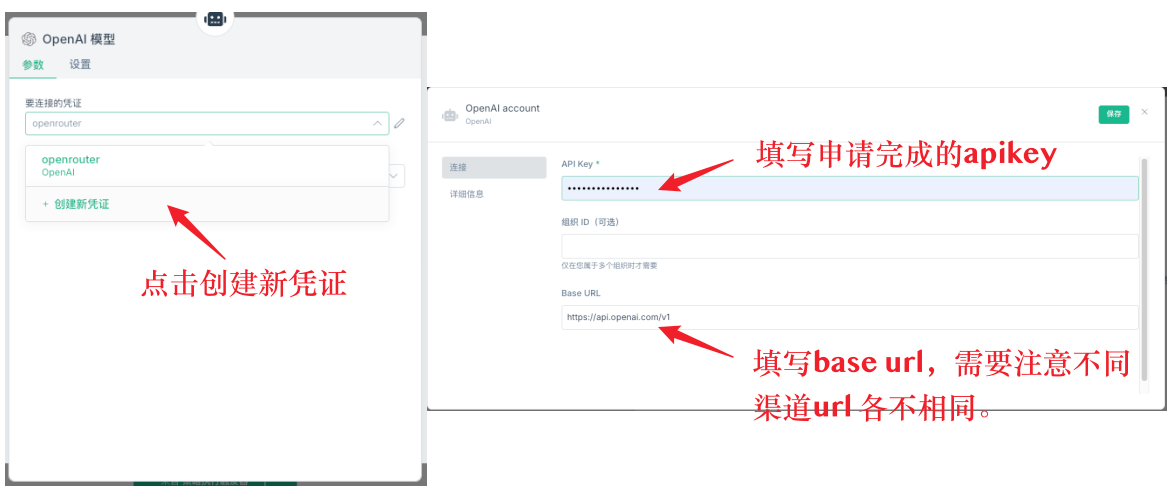
Q11: ¿Cuál es el mejor servicio de API para usar?
No se recomienda el uso de la API directa de deepseek, ya que la respuesta es más lenta, fácilmente se retrasa, y el límite es limitado. Se recomienda el uso de OpenRouter, que se puede conectar a varios modelos grandes, con mayor estabilidad y velocidad.
Q12: ¿La llamada de la IA tiene un costo?
Sí, las llamadas de IA son costosas, y cada solicitud consume tokens. Si la llamada falla, verifique si el saldo de la cuenta es suficiente. Se recomienda usar modelos baratos en la fase de prueba de la lógica de la estrategia y luego cambiarlos a modelos más potentes para confirmar que la lógica de la estrategia es correcta.
Q13: ¿Cómo se escribe un lenguaje de instrucciones de IA eficaz (prompt)?
Este es un arte que requiere optimización de acuerdo con las características de los diferentes modelos grandes. Por ejemplo, Grok es más agresivo, Claude es más cauteloso, y DeepSeek tiene una tendencia natural a hacer más cosas porque está entrenado con datos de A-share.
6. Estabilidad y control de viento de los modelos de IA
Q14: ¿Los modelos de IA son estables para la toma de decisiones?
Los modelos de IA no son completamente estables. Si bien la IA puede mejorar la calidad de las decisiones estratégicas, también es posible que se produzcan errores de juicio. Diferentes entornos de mercado, diferentes representaciones periodísticas e incluso la misma entrada pueden obtener diferentes salidas en diferentes momentos. Esta incertidumbre es una característica inherente de la IA.
Q15: ¿Qué hay que tener en cuenta al usar estrategias de IA?
Al utilizar la estrategia de IA, asegúrese de agregar estrictas medidas de control de riesgo. Por ejemplo: establezca un límite máximo de pérdidas por transacción individual, establezca un límite máximo para la posición total, agregue una lógica de stop loss stop, no deje que la IA controle completamente los fondos.
La IA debe ser tu herramienta de apoyo a la toma de decisiones, no un objeto de delegación de poder. La vigilancia artificial y el control de riesgos no pueden faltar. A medida que la tecnología de la IA avance, los modelos serán más estables, pero es prudente mantenerse cauteloso en esta etapa.
7. Particularidades de las estrategias de detección de IA
Q16: ¿Las estrategias que incluyen IA pueden ser rastreadas de manera normal?
Las estrategias que incluyen IA tienen una gran peculiaridad en la retroalimentación, que debe entenderse. Las estrategias convencionales pueden retroalimentar al azar con datos históricos, pero las estrategias de IA no pueden hacerlo.
¿Por qué? Porque cada vez que se llama a la IA se consumen tokens y se generan costos reales.
Para proteger los bolsillos, FMZ diseñó un mecanismo: en el modo de retroalimentación, el nodo de la IA solo hace tres llamadas reales, y luego usa los tres datos almacenados. Por lo tanto, los resultados de la retroalimentación son solo una referencia y no representan la calidad de las decisiones reales de la IA.
Q17: ¿Pueden las estrategias de inteligencia artificial rastrear las últimas noticias?
Si tu estrategia invoca la información de noticias más reciente, la retroalimentación no tiene más sentido. Porque usas datos de líneas K del pasado, pero lees noticias actuales, y las dos no coinciden en absoluto, por lo que la retroalimentación no tiene sentido.
Q18: Entonces, ¿cómo se debe probar una estrategia de IA?
El método recomendado es: realizar pruebas de campo con un pequeño capital y un pequeño ciclo, observar la calidad de la decisión de la IA y el rendimiento de la estrategia durante un período de tiempo, y aumentar gradualmente el capital después de confirmar la estabilidad. Para la estrategia de IA, la verificación en el campo es mucho más importante que la revisión histórica.
Configuración de los nodos HTTP y MCP
Q19: ¿Qué pasa si el nodo HTTP no puede obtener datos?
Los nodos HTTP y MCP se usan generalmente para obtener datos externos, pero muchos servicios de API requieren claves para acceder a ellos. Si ha configurado una solicitud HTTP pero no obtiene datos, compruebe si necesita una clave de API y si la información de autenticación está configurada correctamente. Algunas API también tienen restricciones de frecuencia de solicitud, que se limitan o incluso bloquean si se llama con demasiada frecuencia.
Q20: ¿Cómo mejorar la estabilidad de la obtención de datos externos?
Los nodos MCP son más potentes y se pueden conectar a varios servicios de datos estructurados, pero también son más complejos de configurar. Se requiere la configuración correcta de los puntos finales de servicio, métodos de autenticación, parámetros de solicitud, etc. Se recomienda probar la accesibilidad de la API con los nodos HTTP para confirmar el formato de los datos y luego integrarlos en el flujo de trabajo.
Además, para mejorar la estabilidad, se puede agregar un mecanismo de repetición de fallos a estos nodos. Iniciar el repetición en la configuración del nodo, configurar el número de repeticiones y el intervalo de tiempo de repetición, de modo que un problema de red temporal no cause el fracaso de todo el flujo de trabajo.
9. Problemas de compatibilidad de código
Q21: ¿Pueden usarse el código de FMZ y el de n8n?
El flujo de trabajo de los inventores está basado en el marco de código abierto de n8n y está personalizado para ser utilizado, pero el código de los dos no se puede copiar directamente entre sí. Si encuentras el código de flujo de trabajo de n8n en la red, pegarlo directamente a FMZ no funcionará, y será necesario modificarlo según la API y la especificación de los nodos de FMZ. A su vez, el código de flujo de trabajo de FMZ no se puede usar directamente en n8n.
Las principales diferencias son: FMZ ha hecho modificaciones personalizadas en algunos nodos, los parámetros y el formato de salida son diferentes. Si se quiere migrar el código, se debe examinar cuidadosamente la configuración y la invocación de funciones de cada nodo para garantizar que cumpla con las especificaciones de la plataforma de destino.
Resumir
Estas son las respuestas a las preguntas comunes de los inventores sobre la cuantificación de flujos de trabajo. Cubrimos todos los aspectos de la configuración del entorno, los mecanismos de nodos, la lectura de datos, la especificación de código, las llamadas de IA y las pruebas de retroalimentación, que son problemas de alta frecuencia en la batalla real.
Sin embargo, el comercio cuantitativo es un proceso de aprendizaje continuo, y siempre surgen nuevos problemas. Si tiene problemas, no se desanime, consulte los documentos oficiales de FMZ, busque en las discusiones de la comunidad, ya que muchos problemas han sido encontrados por otros. Si no puede resolverlo, puede enviar una solicitud de trabajo a los ingenieros de la plataforma.
Recuerde: las preguntas son los mejores maestros, y cada vez que resuelva una pregunta, su comprensión del flujo de trabajo se profundizará. ¡Espero que esta FAQ ayude a todos a usar mejor las estrategias de desarrollo de flujo de trabajo de forma cuantitativa!


- 1