
Una explicación completa de las ventajas y desventajas de las tres categorías principales y los seis algoritmos principales del aprendizaje automático.
En el aprendizaje automático, el objetivo es la predicción o el clustering. El enfoque de este artículo es la predicción. La predicción es el proceso de estimar el valor de una variable de salida a partir de un conjunto de variables de entrada. Por ejemplo, dado un conjunto de características sobre una casa, podemos predecir su precio de venta.
Con esto en mente, veamos algunos de los algoritmos más destacados y usados en el aprendizaje automático. Los dividimos en 3 categorías: modelos lineales, modelos basados en árboles y redes neuronales, con un enfoque en los 6 algoritmos más usados:
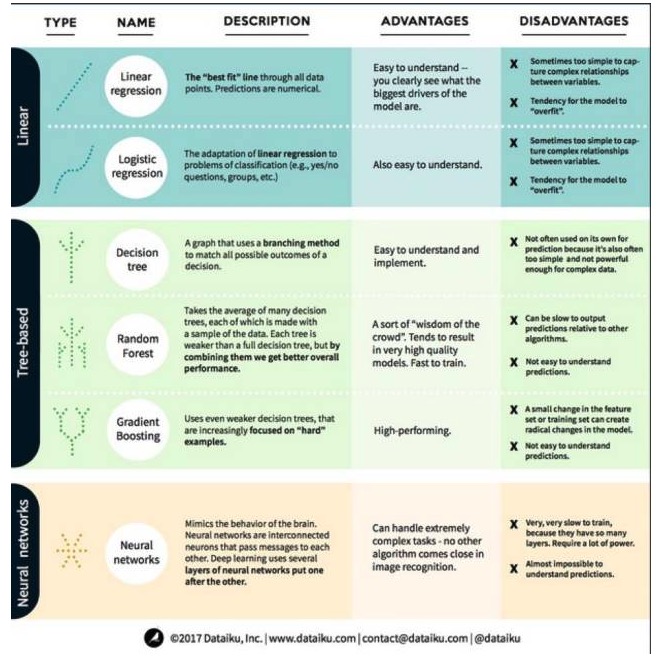
Un algoritmo de modelo lineal: un modelo lineal utiliza una fórmula simple para encontrar la línea de la queja que mejor se ajusta a la queja a través de un conjunto de puntos de datos. Este método se remonta a más de 200 años atrás y ha sido ampliamente utilizado en los campos de la estadística y el aprendizaje automático.
-
Regresión lineal
La regresión lineal, o más exactamente la regresión de la cuadrícula mínima, es la forma más estándar de un modelo lineal. Para problemas de regresión, la regresión lineal es el modelo lineal más simple. Su desventaja es que el modelo es fácilmente sobreadaptado, es decir, el modelo se adapta completamente a los datos que se han entrenado, a expensas de la capacidad de generalización a nuevos datos. Por lo tanto, la regresión lineal en el aprendizaje automático (y la regresión lógica de la que hablaremos a continuación) suele ser una forma de regresión ortogonal, lo que significa que el modelo tiene un cierto castigo para evitar la sobreadaptación.
Otro inconveniente de los modelos lineales es que, debido a su gran simplicidad, no son fáciles de predecir el comportamiento de las variables más complejas cuando las entradas no son independientes.
-
2. Regresión lógica
La regresión lógica es la adaptación de la regresión lineal a problemas de clasificación. La regresión lógica tiene las mismas desventajas que la regresión lineal. La función lógica es muy buena para problemas de clasificación porque introduce un efecto de umbral.
Segundo, el algoritmo de modelo de árbol.
-
1 Árboles de decisión
Un árbol de decisiones es un gráfico que muestra cada resultado posible de una decisión usando un método de ramificación. Por ejemplo, si decides pedir una ensalada, tu primera decisión puede ser la variedad de verduras, luego la de platos, y luego la de la ensalada. Podemos representar todos los resultados posibles en un árbol de decisiones.
Para entrenar un árbol de decisión, necesitamos usar un conjunto de datos de entrenamiento y encontrar la propiedad que sea más útil para el objetivo. Por ejemplo, en un caso de uso de detección de fraude, podemos encontrar que la propiedad que tiene el mayor impacto en la predicción del riesgo de fraude es el país. Después de ramificar con la primera propiedad, obtenemos dos subconjuntos, que serían los más predecibles si solo supiéramos la primera propiedad. Luego, encontramos la segunda mejor propiedad para ramificar con estos dos subconjuntos, dividiéndolos nuevamente, y así sucesivamente, hasta que el uso de suficientes propiedades satisfaga la necesidad del objetivo.
-
2 El bosque al azar
El bosque aleatorio es el promedio de muchos árboles de decisión, en los que cada árbol de decisión se entrena con una muestra de datos aleatoria. Cada árbol en el bosque aleatorio es más débil que un árbol de decisión completo, pero si se ponen todos los árboles juntos, se obtiene un mejor rendimiento general debido a la ventaja de la diversidad.
El bosque aleatorio es un algoritmo muy popular en el aprendizaje automático de hoy en día. El bosque aleatorio es fácil de entrenar y se desempeña bastante bien. Su desventaja es que la predicción de la salida del bosque aleatorio puede ser lenta en comparación con otros algoritmos, por lo que es posible que no se elija el bosque aleatorio cuando se necesita una predicción rápida.
-
3 - El aumento de la escala
El GradientBoosting, como el bosque aleatorio, también está formado por árboles de decisión de la jerarquía de la jerarquía de la jerarquía. La mayor diferencia entre el GradientBoosting y el bosque aleatorio es que en el GradientBoosting, los árboles se entrenan uno tras otro.
El entrenamiento de escalado también es rápido y funciona muy bien. Sin embargo, pequeños cambios en el conjunto de datos de entrenamiento pueden provocar cambios fundamentales en el modelo, por lo que los resultados que produce pueden no ser los más viables.
Las redes neuronales son fenómenos biológicos que se componen de neuronas interconectadas que intercambian información entre sí en el cerebro. La idea se aplica ahora al campo del aprendizaje automático, conocido como ANN (red neuronal artificial). El aprendizaje profundo es una red neuronal de capas superpuestas.
El sitio web de Big Data dice:
- 1