
De nombreuses questions ont été posées par les développeurs dans les commentaires et la communauté lors de l'utilisation du flux de travail de quantification des inventeurs. Cet article rassemble ces questions fréquentes, couvrant les aspects de la configuration de l'environnement, de l'utilisation des nœuds, de la lecture des données, de l'appel de l'IA, des mécanismes de rétroaction, etc., pour vous aider à trouver rapidement des solutions.
Les problèmes de type de configuration environnementale
Q1: Pourquoi mon disque dur ne peut-il pas exécuter la stratégie de flux de travail ?
La politique de flux de travail ne peut pas être lancée si la version de votre hôte est trop ancienne et doit être mise à jour rapidement.
Q2: Quels sont les langages de programmation pris en charge par le workflow ?
Les nœuds de code du workflow ne supportent que JavaScript, pas Python. Si vous êtes habitué à écrire des stratégies en Python, vous devez passer à la grammaire JS.
Deuxième mécanisme de fonctionnement du nœud
Q3: Les nœuds du flux de travail sont-ils déclenchés simultanément ou exécutés successivement ?
Les nœuds du flux de travail sont strictement en série, ils ne peuvent être déclenchés qu'un à la fois et ne fonctionnent pas en parallèle. Chaque nœud doit attendre que l'exécution du nœud précédent soit terminée pour commencer, ce qui est une caractéristique à prendre en compte lors de la mise en place des mécanismes de stratégie.
Q4: Pourquoi le flux de travail n'est-il pas exécuté après la mise en place du nœud de mise à jour de la ligne K?
Si vous avez configuré un déclencheur de mise à jour de ligne K d'une heure, le workflow attendra le point de clôture de ligne K pour commencer à fonctionner. Pendant l'attente, le workflow ne s'exécutera pas, ce qui est normal. Si vous souhaitez exécuter une logique de stratégie différente pendant l'attente, vous pouvez configurer un deuxième déclencheur pour exécuter votre logique de stratégie.
3/ Lire les données et conserver les variables
Q5: Comment lire les données de sortie d'un nœud ?
L'orthographe standard est la suivante:
javascript
$node["节点名称"].json
Cette syntaxe peut lire les sorties JSON de n'importe quel nœud. Cependant, avec une restriction, elle ne peut lire que les données des nœuds parents directement connectés. Elle ne peut pas être lue de cette manière si il n'y a pas de relation de connexion directe entre les deux nœuds.
Q6: Comment les données peuvent-elles être partagées entre des nœuds qui ne sont pas directement connectés ?
À utiliser_GVariable mondiale_GLe flux de travail FMZ est une mémoire interne globale qui permet de partager des données entre n'importe quel nœud et n'importe quel flux.
L'utilisation est simple:
javascript
// 保存数据
_G("变量名", 值)
// 读取数据
_G("变量名")
Mais attention particulière !_GLes variables restent présentes et ne sont pas supprimées même si le disque est redémarré. Si des erreurs sont détectées dans les anciennes données, il faut les régler manuellement._G("变量名",null)Pour effacer ou recréer directement le disque dur.
Q7: Quand est-ce que j'ai besoin d'utiliser JSON.stringify ?
Il est souvent nécessaire d'utiliserJSON.stringifyCette méthode permet de convertir des objets et des ensembles complexes en chaînes de texte, ce qui est particulièrement utile pour transmettre des données à un nœud d'IA, car l'IA ne peut comprendre que les entrées en format texte.
Quatrièmement, le transfert de données des nœuds de code.
Q8: Les nœuds de code doivent-ils renvoyer des données ?
Oui, c'est une exigence très cruciale.returnRetourner des données pour que les données restent transmises entre les nœuds. Même si votre logique de code n'a pas besoin d'envoyer de données, retourner un tableau vide:
javascript
return {}
Si vous oubliez le retour, le nœud de suivi ne peut pas recevoir de données, ce qui entraîne l'interruption de l'ensemble du flux de travail.
Q9: Comment gérer les données multiples des sorties d'un nœud ?
Si un de vos nœuds produit plusieurs données, par exemple 10 nouvelles, et que vous avez besoin de les traiter ensemble plutôt que séparément, vous ne pouvez pas les transmettre directement au nœud suivant, vous devez utiliser un nœud de fusion ou un nœud d'agrégation pour intégrer plusieurs données dans un paquet de données.
L'avantage de cette approche est que la structure des données est claire et que les nœuds de suivi sont faciles à traiter. Par exemple, pour transmettre plusieurs nouvelles à l'analyse de l'IA, il faut d'abord regrouper un tableau, afin que l'IA puisse voir toutes les informations à la fois.
Cinquièmement, configuration et démarrage des nœuds d'IA
Q10: Quelles sont les premières choses à vérifier en cas d'erreur d'un nœud d'IA ?
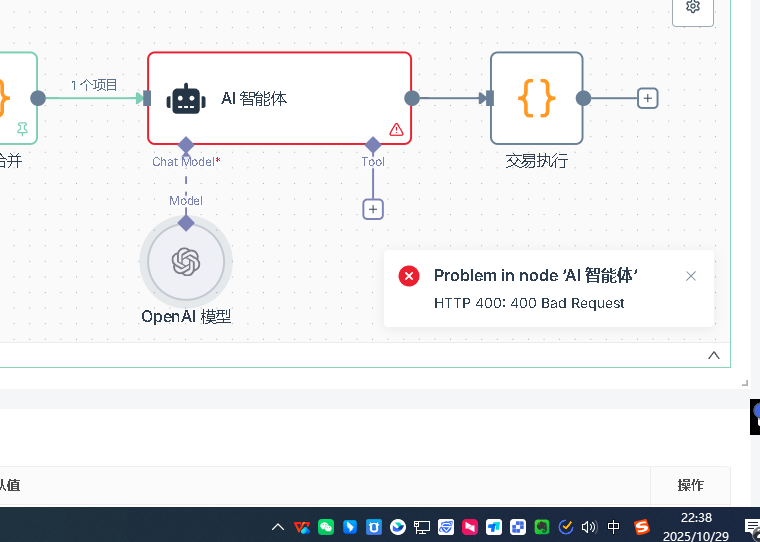
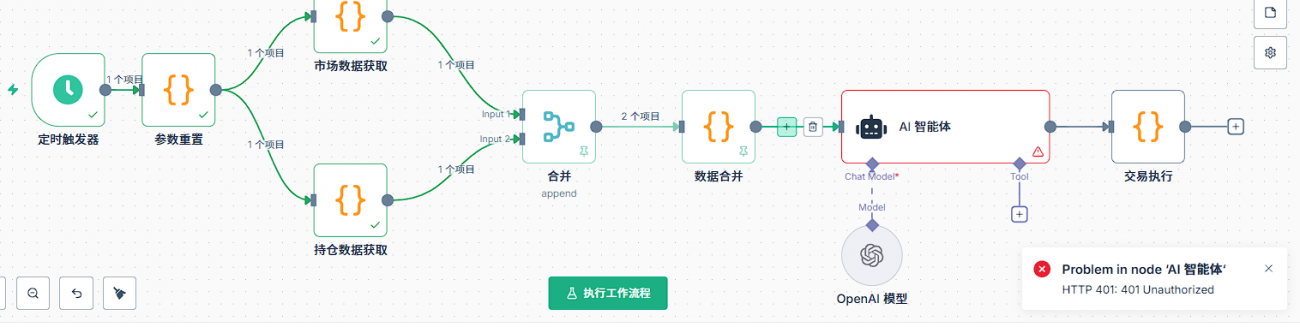
Tout d'abord, il faut ajouter un modèle de modèle, dans le modèle doit être configuré les accréditations. Tout d'abord, créer de nouveaux accréditations, la configuration des accréditations comprend deux informations clés: clé API et base url. La clé API est la clé que vous demandez à la plate-forme correspondante, l'url de base est l'adresse de demande de l'API.
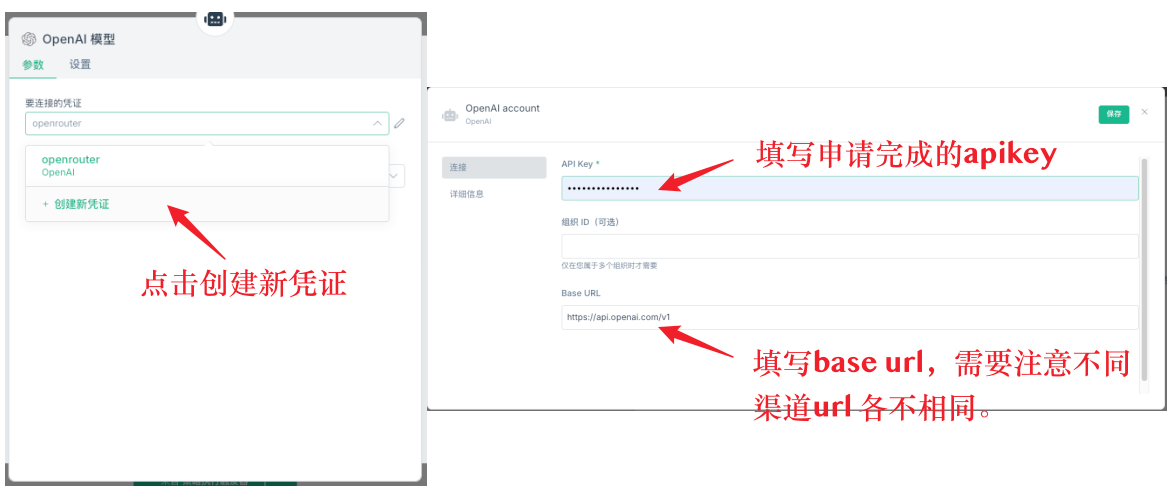
Q11: Quelle est la meilleure API à utiliser ?
L'utilisation de l'API directe de deepseek n'est pas recommandée, car la réponse est plus lente et peut être retardée, et les limites sont limitées. Il est recommandé d'utiliser OpenRouter, qui peut se connecter à divers modèles de grande taille, pour une meilleure stabilité et une meilleure vitesse.
Q12: Est-ce que cela coûte cher de faire appel à une IA ?
Oui, les appels d'IA coûtent de l'argent et consomment des tokens à chaque demande. En cas d'échec de l'appel, il est recommandé d'utiliser un modèle moins cher pour tester la logique de la stratégie et de le remplacer par un modèle plus puissant après avoir vérifié que la logique de la stratégie est correcte.
Q13: Comment écrire un langage de commande de l'IA efficace ?
C'est un art qui nécessite d'optimiser en fonction des caractéristiques des différents grands modèles. Grok est plus radical, Claude est plus prudent, DeepSeek a une tendance naturelle à faire plus parce qu'il a été formé avec des données de stock A. Comprendre ces caractéristiques permet d'écrire des prompts plus efficaces.
Sixièmement, la stabilité des modèles d'IA et le contrôle du vent
Q14: Les modèles d'IA sont-ils stables dans leur prise de décision ?
Les modèles d'IA ne sont pas encore totalement stables. Bien que l'IA puisse améliorer la qualité des décisions stratégiques, elle peut aussi être mal interprétée. Différents environnements de marché, différentes présentations médiatiques et même les mêmes entrées peuvent obtenir des sorties différentes à différents moments. Cette incertitude est inhérente à l'IA.
Q15: À quoi faut-il faire attention lorsque vous utilisez une stratégie d'IA ?
Lorsque vous utilisez une stratégie d'IA, assurez-vous d'ajouter des mesures de contrôle du risque strictes. Par exemple: définissez un seuil de perte maximal pour chaque transaction, définissez un plafond de position totale, ajoutez une logique de stop-loss-stop, ne laissez pas l'IA contrôler complètement les fonds.
L'IA devrait être votre outil de prise de décision, et non un objet de délégation absolue. La surveillance artificielle et le contrôle des risques ne peuvent jamais être absents.
7 - La spécificité de la détection stratégique de l'IA
Q16: Est-ce que les stratégies qui incluent l'IA peuvent être retracées normalement ?
Les stratégies qui incluent l'IA ont une grande spécificité dans le repérage, ce qui doit être compris. Les stratégies conventionnelles peuvent être repérées au hasard avec des données historiques, mais les stratégies AI ne le peuvent pas.
Pourquoi ? Parce que chaque appel à l'IA consomme des tokens, ce qui entraîne des coûts réels. Si vous utilisez les données historiques d'une année, vous devrez peut-être faire des milliers d'appels à l'IA, ce qui est très coûteux.
Pour protéger le portefeuille, FMZ a conçu un mécanisme: dans le mode de rétroanalyse, les nœuds d'IA n'appellent réellement que trois fois et utilisent ensuite les données cachées de ces trois fois. Les résultats de la rétroanalyse sont donc une référence et ne représentent pas la qualité réelle des décisions de l'IA.
Q17: Est-ce que les stratégies d'intelligence artificielle utilisant les dernières nouvelles peuvent être retracées ?
Si votre stratégie fait appel à l'information de l'actualité, la rétrospective n'a pas plus de sens. Parce que vous utilisez les données du passé de la ligne K, mais que vous lisez l'actualité du moment, et que les deux ne correspondent pas du tout, la rétrospective n'a pas de sens.
Q18: Alors, comment tester une stratégie d'IA ?
La méthode recommandée est la suivante: tester en terrain avec peu de fonds, à petites périodes, observer la qualité des décisions et la performance des stratégies d'IA pendant un certain temps, puis augmenter progressivement les fonds après confirmation de la stabilité. Pour les stratégies d'IA, la vérification en terrain est bien plus importante que la revue historique.
La configuration des nœuds HTTP et MCP
Q19: Que faire si le nœud HTTP ne parvient pas à accéder aux données ?
Les nœuds HTTP et MCP sont généralement utilisés pour obtenir des données externes, mais de nombreux services API nécessitent des clés pour y accéder. Si vous avez configuré une demande HTTP mais que vous n'obtenez pas de données, vérifiez si vous avez besoin d'une clé API et si les informations d'authentification sont correctement configurées. Certaines API ont également des restrictions de fréquence de demande, et si elles sont appelées trop souvent, le flux est limité ou même bloqué.
Q20: Comment améliorer la stabilité de l'accès aux données externes ?
Les nœuds MCP sont plus puissants et peuvent être connectés à divers services de données structurées, mais leur configuration est également plus complexe. Il est nécessaire de configurer correctement les points d'extrémité des services, les méthodes d'authentification, les paramètres de demande, etc. Il est recommandé de tester l'API avec un nœud HTTP pour vérifier l'accès normal et d'intégrer le format de données dans le flux de travail.
En outre, pour améliorer la stabilité, un mécanisme de retest de défaillance peut être ajouté à ces nœuds. Le redémarrage est activé dans les paramètres du nœud, en réglant le nombre de répétitions et l'intervalle entre les répétitions, de sorte qu'un problème de réseau temporaire ne provoque pas l'échec du flux de travail entier.
Neuf, problèmes de compatibilité avec le code
Q21: Est-ce que le flux de travail FMZ et le code n8n peuvent être utilisés ensemble ?
Le flux de travail Inventor est basé sur le framework open source n8n et est personnalisé, mais le code des deux ne peut pas être utilisé directement l'un par rapport à l'autre. Si vous trouvez le code du flux de travail n8n en ligne, le collage direct sur FMZ ne fonctionnera pas et nécessitera des modifications en fonction de l'API et des spécifications des nœuds de FMZ.
Les principales différences sont les suivantes: FMZ a fait des modifications sur mesure pour certains nœuds, les paramètres et les formats de sortie sont différents. Si le code doit être migré, la configuration et les appels de fonctions de chaque nœud doivent être soigneusement examinés pour s'assurer qu'ils sont conformes aux spécifications de la plate-forme cible.
Résumer
Voici les réponses aux questions fréquemment posées par les inventeurs pour quantifier leur flux de travail. Nous avons couvert les aspects de la configuration de l'environnement, les mécanismes de nœud, la lecture de données, la spécification du code, les appels à l'IA et les tests de rétroaction, qui sont des problèmes fréquents dans la vie réelle.
Mais le trading quantitatif est un processus d'apprentissage continu, de nouveaux problèmes apparaissent sans cesse. Si vous rencontrez des problèmes, ne vous découragez pas, consultez d'abord la documentation officielle de FMZ, recherchez les discussions dans la communauté, de nombreux problèmes ont déjà été rencontrés.
N'oubliez pas: les problèmes sont les meilleurs professeurs, et à chaque fois que vous les résolvez, votre compréhension du flux de travail s'approfondit.


- 1