
जब इन्वेंटरों द्वारा तैयार किए गए क्वांटिटेटिव वर्कफ्लो का उपयोग किया जा रहा था, तो कई डेवलपरों ने कमेंट सेक्शनों एवं समुदायों में बहुत सारे प्रश्न उठाए। इस लेख में ऐसे ही सामान्य प्रश्नों को संकलित किया गया है; जो पर्यावरण सेटअप, नोड्स के उपयोग, डेटा पढ़ने की प्रक्रिया, एआई (AI) के उपयोग, पुनरावलोकन प्रणाली आदि विभिन्न पहलुओं से संबंधित हैं। इन प्रश्नों के माध्यम से सभी लोगों को जल्दी से समाधान उपलब्ध हो सकेंगे।
1. समस्याएँ जुड़ी पर्यावरण सेटिंगों से
प्रश्न 1: क्यों मेरे वास्तविक ट्रेडिंग अकाउंट पर वर्कफ्लो रणनीतियाँ लागू नहीं हो पा रही हैं?
केवल सबसे नई संस्करण का होस्ट ही वर्कफ्लो चलाने के लिए समर्थन प्रदान करता है। यदि आपके होस्ट का संस्करण पुराना है, तो वर्कफ्लो पॉलिसी शुरू नहीं हो पाएगी; इसलिए आपको अपने होस्ट को तुरंत सबसे नई संस्करण में अपडेट करना आवश्यक है।
प्रश्न 2: वर्कफ्लो कौन-कौन सी प्रोग्रामिंग भाषाओं का समर्थन करता है?
वर्कफ्लो में प्रयोग होने वाले कोड नोड केवल JavaScript का समर्थन करते हैं; Python का समर्थन नहीं किया जाता। यदि आप रणनीतियों को Python में लिखने के आदी हैं, तो उन्हें JS भाषा में परिवर्तित करना आवश्यक होगा। सौभाग्य से, JS एवं Python की मूल तर्क-प्रणाली समान है; अंतर केवल भाषा-व्याकरण संबंधी है।
II. नोड्स का संचालन तंत्र
प्रश्न 3: वर्कफ्लो में स्थित नोड एक साथ ही सक्रिय होते हैं, या फिर क्रमबद्ध रूप से निष्पादित होते हैं?
वर्कफ्लो नोड्स क्रमशः एक-दूसरे से जुड़े होते हैं, इन्हें केवल एक के बाद दूसरे को ही सक्रिय किया जा सकता है; समानांतर रूप से इन्हें चलाया नहीं जा सकता। प्रत्येक नोड केवल तभी शुरू होगा, जब उससे पहले वाला नोड अपना कार्य पूरा कर ले। नीति-तंत्र सेट करते समय इस विशेषता को अवश्य ध्यान में रखना आवश्यक है।
प्रश्न 4: क्यों K-लाइन अपडेट नोड सेट करने के बाद भी वर्कफ्लो लगातार प्रतीक्षा करता रहता है एवं कोई कार्य नहीं करता?
यदि आपने 1 घंटे की अवधि में केली चार्टों के अपडेट होने पर वर्कफ्लो को चालू होने के लिए ट्रिगर सेट किया है, तो वर्कफ्लो पूरे घंटे तक केली चार्टों के बंद होने की प्रतीक्षा करेगा, उसके बाद ही चालू होगा। प्रतीक्षा के दौरान वर्कफ्लो कोई कार्य नहीं करेगा; यह सामान्य ही है। यदि आप चाहते हैं कि प्रतीक्षा के दौरान भी कोई विशेष रणनीति लागू हो, तो आप दूसरा ट्रिगर सेट कर सकते हैं, ताकि आपकी विशेष रणनीति उसी समय लागू हो सके।
III. डेटा पढ़ना एवं चरों को संग्रहीत करना
प्रश्न 5: किसी नोड से आउटपुट डेटा कैसे पढ़ा जाए?
मानक लिखने का तरीका यह है:
javascript
$node["节点名称"].json
यह व्याकरण किसी भी नोड से प्राप्त होने वाला JSON डेटा पढ़ सकता है। हालाँकि, इसमें एक सीमा है – केवल उन्हीं पिता-नोड्स का डेटा ही पढ़ा जा सकता है जो सीधे उस नोड से जुड़े हुए हैं। यदि दो नोड्स के बीच कोई सीधा संबंध नहीं है, तो इस तरीके से उन नोड्स का डेटा पढ़ा नहीं जा सकता।
प्रश्न 6: ऐसे नोड्स के बीच जो सीधे तौर पर जुड़े नहीं हैं, डेटा कैसे साझा किया जा सकता है?
इसका उपयोग किया जा सकता है।_Gग्लोबल वेरिएबल।_Gयह FMZ वर्कफ्लो द्वारा प्रदान की गई एक सार्वभौमिक मेमोरी सुविधा है; इसके द्वारा किसी भी नोड या किसी भी वर्कफ्लो के बीच डेटा को साझा किया जा सकता है।
इसका उपयोग करना बहुत ही आसान है:
javascript
// 保存数据
_G("变量名", 值)
// 读取数据
_G("变量名")
लेकिन विशेष रूप से ध्यान देने की आवश्यकता है…_Gइनमें उल्लिखित चर हमेशा ही मौजूद रहेंगे; भले ही प्रैक्टिकल ट्रेडिंग सिस्टम दोबारा शुरू हो जाए, तब भी ये चर मिट नहीं जाएँगे। यदि कोई गलत पुराना डेटा पढ़ा जाए, तो उसे मैन्युअल रूप से सेट करना होगा।_G("变量名",null)इसे हटा दें, या फिर सीधे ही मूल डेटा को हटाकर नया डेटा बना लें।
प्रश्न 7: कब JSON.stringify का उपयोग करना आवश्यक होता है?
जब जटिल डेटा को संसाधित करने की आवश्यकता होती है, तो अक्सर इसके लिए कुछ विशेष तरीकों या उपकरणों का उपयोग करना पड़ता है।JSON.stringifyविधि: यह विधि जटिल ऑब्जेक्टों एवं सरणियों को टेक्स्ट स्ट्रिंग में परिवर्तित कर सकती है; ऐसा करना डेटा को AI नोड्स तक पहुँचाने में विशेष रूप से उपयोगी है, क्योंकि AI केवल टेक्स्ट फॉर्मेट में ही इनपुट को समझ सकता है।
IV. डेटा का हस्तांतरण कोड नोडों के माध्यम से
प्रश्न 8: क्या कोड नोड्स को अवश्य ही डेटा वापस करना आवश्यक है?
हाँ, यह एक बहुत ही महत्वपूर्ण आवश्यकता है। कोड नोड्स को अंततः ऐसा ही करना होगा।returnडेटा को वापस करना ही आवश्यक है, ताकि डेटा नोडों के बीच सही तरीके से पहुँच सके। भले ही आपके कोड में किसी भी डेटा को आउटपुट करने की आवश्यकता न हो, फिर भी एक खाली सरणी वापस करनी ही आवश्यक है।
javascript
return {}
यदि “return” करना भूल जाए, तो बाद के नोड्स को डेटा नहीं मिलेगा, जिसके कारण पूरा वर्कफ्लो बाधित हो जाएगा।
प्रश्न 9: नोड द्वारा उत्पन्न होने वाले कई डेटा तत्वों को कैसे संभाला जाए?
यदि किसी नोड से कई डेटा आउटपुट के रूप में प्राप्त होते हैं, जैसे कि 10 समाचार, और आपको उन सभी डेटा को अलग-अलग नहीं, बल्कि एक साथ ही संसाधित करने की आवश्यकता है, तो उन डेटा को सीधे अगले नोड तक नहीं भेजा जा सकता। ऐसी स्थिति में “मर्ज नोड” या “एग्रीगेट नोड” का उपयोग करके उन सभी डेटा को एक ही डेटा पैकेट में संयोजित करना आवश्यक है।
इस तरह करने का फायदा यह है कि डेटा संरचना स्पष्ट रहती है, जिससे बाद में अन्य नोड्स द्वारा डेटा का प्रसंस्करण आसान हो जाता है। उदाहरण के लिए, यदि कई समाचारों को AI के विश्लेषण हेतु भेजना है, तो पहले उन सभी समाचारों को एक सूची में संग्रहीत कर लेना आवश्यक है; ताकि AI एक ही बार में सभी जानकारियों को देख सके।
5. AI नोड्स का कॉन्फ़िगरेशन एवं डीबगिंग
प्रश्न 10: यदि AI नोड में कोई त्रुटि आ जाती है, तो सबसे पहले किस बात की जाँच करनी चाहिए?
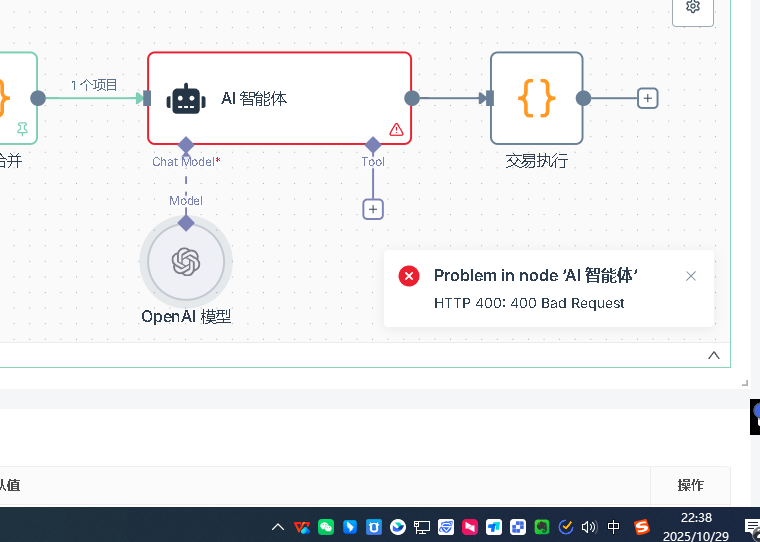
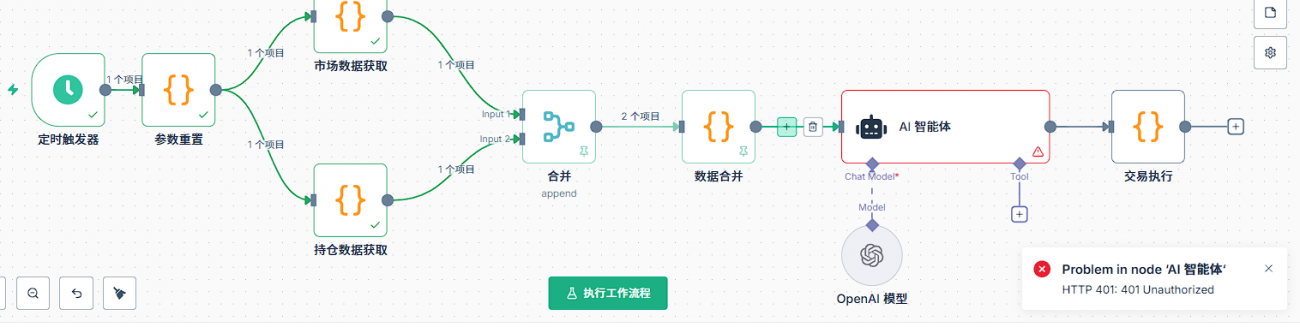
सबसे पहले, AI नोड की बुनियादी सेटिंग्स करनी होंगी। AI नोड में “मॉडल” जोड़ना आवश्यक है, एवं उस “मॉडल” में प्रमाण-पत्र (क्रेडेंशियल) अवश्य सेट किए जाने चाहिए। सबसे पहले एक नया प्रमाण-पत्र बनाएँ; इस प्रमाण-पत्र की कॉन्फ़िगरेशन में दो महत्वपूर्ण जानकारियाँ शामिल हैं – API कीवर्ड एवं बेस URL। API कीवर्ड वह कुंजी है जो आपने संबंधित प्लेटफॉर्म पर आवेदन करके प्राप्त की है, जबकि बेस URL API का अनुरोध-पता है। ध्यान दें कि विभिन्न चैनलों के लिए बेस URL अलग-अलग होता है; जैसे कि OpenRouter, DeepSeek, या कोई अन्य प्रॉक्सी सेवा – इन सभी के लिए बेस URL अलग-अलग होता है, इसलिए इसे सही ढंग से दर्ज करना आवश्यक है।
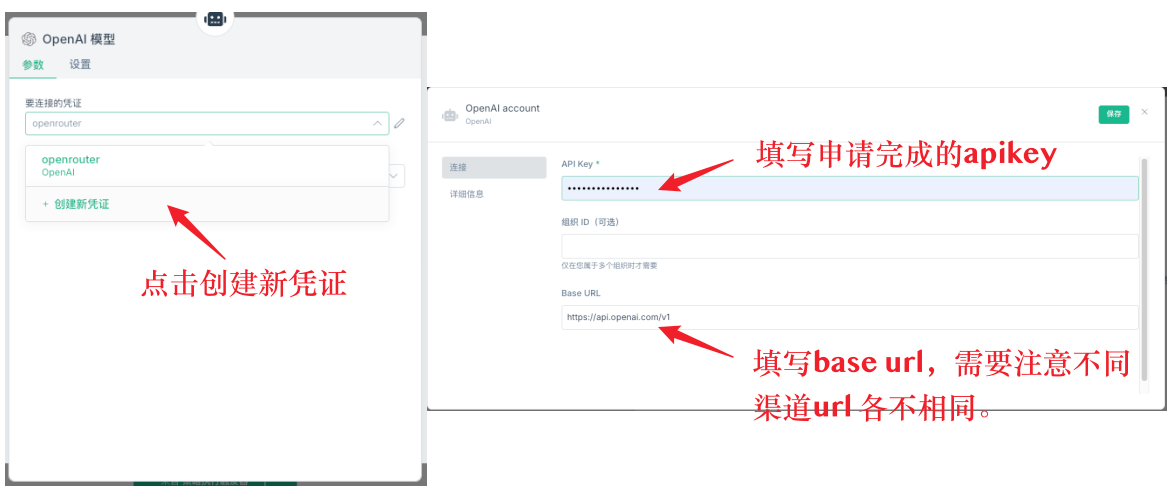
प्रश्न 11: कौन-सी API सेवा उपयोग करना बेहतर होगा?
deepseek के सीधे API का उपयोग करने की सलाह नहीं दी जाती है, क्योंकि इसकी प्रतिक्रिया धीमी होती है एवं टाइमआउट होने की संभावना अधिक होती है; साथ ही, इसकी सुविधाओं की सीमाएँ भी होती हैं। OpenRouter का उपयोग करना बेहतर होगा, क्योंकि यह विभिन्न बड़े मॉडलों से जुड़ सकता है, एवं इसकी स्थिरता एवं गति दोनों ही बेहतर हैं।
प्रश्न 12: क्या AI के उपयोग से कोई शुल्क लगेगा?
हाँ, AI कॉल करने में खर्च होता है; प्रत्येक अनुरोध के दौरान टोकन खपत हो जाते हैं। यदि कॉल विफल हो जाए, तो अपने खाते में पर्याप्त राशि है या नहीं, इसकी जाँच करें। सलाह दी जाती है कि पहले टेस्टिंग के दौरान सस्ते मॉडलों का उपयोग करें; जब यह सुनिश्चित हो जाए कि रणनीति का तर्क सही है, तब ही अधिक शक्तिशाली मॉडलों का उपयोग शुरू करें।
प्रश्न 13: कैसे एक प्रभावी AI-निर्देश (प्रॉम्प्ट) तैयार किया जाए?
यह एक कला है, जिसे विभिन्न बड़े मॉडलों की विशेषताओं के अनुसार अनुकूलित करने की आवश्यकता होती है। उदाहरण के लिए, Grok अपेक्षाकृत अधिक आक्रामक है, जबकि Claude अधिक सावधान रहता है; DeepSeek को चूँकि A-शेयर डेटा का उपयोग करके प्रशिक्षित किया गया है, इसलिए यह स्वाभाविक रूप से खरीदारी की ओर झुकाव रखता है। इन विशेषताओं को समझने से ही अधिक प्रभावी प्रॉम्प्ट तैयार किए जा सकते हैं।
छह, एआई मॉडलों की स्थिरता एवं जोखिम प्रबंधन
प्रश्न 14: क्या एआई मॉडलों द्वारा लिए गए निर्णय स्थिर होते हैं?
वर्तमान में, एआई मॉडल पूरी तरह से स्थिर नहीं हैं। हालाँकि एआई रणनीतियों के निर्णयों की गुणवत्ता में सुधार कर सकता है, लेकिन इसमें भी गलतियाँ हो सकती हैं। अलग-अलग बाजार परिस्थितियाँ, अलग-अलग समाचार रिपोर्टें, यहाँ तक कि एक ही इनपुट के अलग-अलग समयों पर अलग-अलग परिणाम प्राप्त हो सकते हैं। यह अनिश्चितता एआई की स्वाभाविक विशेषता है।
प्रश्न 15: AI रणनीतियों का उपयोग करते समय किन बातों पर ध्यान देना आवश्यक है?
जब AI रणनीतियों का उपयोग किया जाता है, तो अवश्य ही सख्त जोखिम नियंत्रण उपाय लागू किए जाने चाहिए। उदाहरण के लिए: प्रत्येक लेन-देन में होने वाले अधिकतम नुकसान की सीमा निर्धारित करना, कुल होल्डिंग की सीमा तय करना, नुकसान रोकने एवं लाभ अर्जित करने संबंधी तंत्र लागू करना आदि; ताकि AI को पूरी तरह से धनराशि पर नियंत्रण न दिया जाए।
AI को आपके निर्णय लेने में मदद करने वाला एक साधन होना चाहिए, न कि ऐसा साधन जिस पर पूरी तरह भरोसा किया जा सके। मानवीय निगरानी एवं जोखिम नियंत्रण हमेशा ही आवश्यक रहेंगे। जैसे-जैसे AI तकनीक विकसित होती जाएगी, इसके मॉडल और अधिक स्थिर होते जाएंगे; लेकिन फिलहाल सावधान रहना ही एक बुद्धिमानीपूर्ण निर्णय होगा।
सात, एआई रणनीतियों के पुनर्मूल्यांकन में विशेषताएँ
प्रश्न 16: क्या ऐसी रणनीतियाँ जिनमें एआई (AI) का उपयोग किया गया है, सामान्य तरीके से परीक्षण की जा सकती हैं?
ऐसी रणनीतियाँ जिनमें एआई का उपयोग किया गया हो, पुनरावलोकन (रिट्रीट स्टडी) के दृष्टिकोण से काफी विशेष होती हैं; इस बात को अवश्य स्पष्ट रूप से समझ लेना आवश्यक है। सामान्य रणनीतियों का पुनरावलोकन ऐतिहासिक आंकड़ों के आधार पर आसानी से किया जा सकता है, लेकिन एआई-आधारित रणनीतियों का ऐसा नहीं हो सकता।
क्यों? क्योंकि हर बार जब AI का उपयोग किया जाता है, तो टोकन खर्च होते हैं, जिससे वास्तविक लागत उत्पन्न होती है। यदि आप एक वर्ष के इतिहासिक डेटा का उपयोग करके परीक्षण करते हैं, तो संभवतः हजारों बार AI का उपयोग करना पड़ेगा, जिससे लागत बहुत अधिक हो जाएगी।
FMZ ने सभी लोगों के पैसों की सुरक्षा हेतु एक तरह की व्यवस्था तैयार की है: पुनरावलोकन मोड में, AI नोड केवल तीन बार ही वास्तविक रूप से कार्य करता है, एवं बाद में हमेशा इन ही तीन बार के कैश डेटा का उपयोग किया जाता है। इसलिए, पुनरावलोकन के परिणाम केवल एक संदर्भ ही हैं; वे वास्तविक AI निर्णयों की गुणवत्ता का प्रतिनिधित्व नहीं कर सकते।
प्रश्न 17: क्या नवीनतम समाचारों का उपयोग करने वाली AI रणनीतियों का पुनर्मूल्यांकन किया जा सकता है?
यदि आपकी रणनीति में नवीनतम समाचार जानकारियों का उपयोग किया गया है, तो पुनरावलोकन प्रक्रिया पूरी तरह अर्थहीन हो जाती है। क्योंकि आप पुराने कैंडल डेटा का उपयोग कर रहे हैं, जबकि वर्तमान समाचार ही पढ़ रहे हैं; इन दोनों के बीच समय में पूरी तरह मेल नहीं है, इसलिए ऐसे पुनरावलोकन परिणामों का कोई मतलब ही नहीं है।
प्रश्न 18: तो AI रणनीतियों का परीक्षण कैसे किया जाना चाहिए?
सुझाए गए तरीके यह हैं: कम राशि एवं छोटे चक्रों में वास्तविक बाजार में परीक्षण करें, एक निश्चित समय तक एआई के निर्णयों की गुणवत्ता एवं रणनीतियों के प्रदर्शन को देखें; जब यह स्थिर पाया जाए, तब ही धीरे-धीरे राशि बढ़ाएँ। एआई रणनीतियों के लिए, वास्तविक बाजार में परीक्षण, ऐतिहासिक डेटा के आधार पर किए गए परीक्षणों से कहीं अधिक महत्वपूर्ण है।
आठ, HTTP एवं MCP नोड्स का कॉन्फ़िगरेशन
प्रश्न 19: यदि HTTP नोड को डेटा प्राप्त न हो, तो क्या करना चाहिए?
HTTP नोड एवं MCP नोड आमतौर पर बाहरी डेटा प्राप्त करने हेतु उपयोग में आते हैं; लेकिन कई API सेवाओं तक पहुँच हेतु कुंजी की आवश्यकता होती है। यदि आपने HTTP अनुरोध कॉन्फ़िगर कर लिया है, लेकिन फिर भी डेटा प्राप्त नहीं हो रहा है, तो यह जाँच लें कि क्या API कुंजी की आवश्यकता है, एवं प्रमाणीकरण संबंधी जानकारियाँ क्या सही ढंग से कॉन्फ़िगर की गई हैं। कुछ API में अनुरोधों की आवृत्ति पर भी सीमाएँ होती हैं; यदि बहुत बार अनुरोध किए जाएँ, तो ऐसी सेवाओं पर प्रतिबंध लग सकता है, या उनका उपयोग ही असंभव हो सकता है।
प्रश्न 20: बाहरी डेटा प्राप्त करने की प्रक्रिया को कैसे अधिक स्थिर बनाया जा सकता है?
MCP नोड और भी शक्तिशाली है, एवं यह विभिन्न संरचित डेटा सेवाओं से जुड़ सकता है; लेकिन इसकी कॉन्फ़िगरेशन प्रक्रिया भी अधिक जटिल है। सर्वर एंडपॉइंट, प्रमाणीकरण विधियाँ, अनुरोध पैरामीटर आदि को सही ढंग से सेट करना आवश्यक है। सलाह दी जाती है कि पहले HTTP नोड का उपयोग करके यह जाँच लें कि API ठीक से काम कर रहा है या नहीं; डेटा फॉर्मेट की पुष्टि हो जाने के बाद ही इसे वर्कफ्लो में शामिल करें।
इसके अलावा, स्थिरता बढ़ाने हेतु इन नोड्स में विफलता की स्थिति में पुनः प्रयास करने की सुविधा जोड़ी जा सकती है। नोड सेटिंग्स में “पुनः प्रयास” का विकल्प चालू करके, पुनः प्रयासों की संख्या एवं अंतराल समय निर्धारित कर देना चाहिए; ताकि अस्थायी नेटवर्क समस्याओं के कारण पूरा वर्कफ्लो विफल न हो जाए।
9. कोड संगतता से जुड़ी समस्याएँ
प्रश्न 21: क्या FMZ वर्कफ्लो एवं n8n के कोड आपस में उपयोग किए जा सकते हैं?
आविष्कारक वर्कफ्लो, n8n ओपनसोर्स फ्रेमवर्क के आधार पर ही तैयार किया गया है; लेकिन दोनों कोडों को सीधे-सीधे एक-दूसरे के स्थान पर उपयोग में नहीं लाया जा सकता। यदि आप इंटरनेट पर n8n का वर्कफ्लो कोड प्राप्त करते हैं, तो उसे सीधे FMZ में पेस्ट करने से यह चल नहीं पाएगा; इसे FMZ के API एवं नोड स्पेसिफिकेशन के अनुसार ही संशोधित करना आवश्यक है। इसी प्रकार, FMZ का वर्कफ्लो कोड भी सीधे n8n पर उपयोग में नहीं लाया जा सकता।
मुख्य अंतर यह है कि FMZ ने कुछ नोड्स पर विशेष बदलाव किए हैं; इन नोड्स पर प्रयोग में आने वाले पैरामीटर एवं आउटपुट फॉर्मेट भी अलग-अलग हैं। यदि कोड को स्थानांतरित करना है, तो प्रत्येक नोड की कॉन्फ़िगरेशन एवं फंक्शन कॉलों की ध्यानपूर्वक जाँच करना आवश्यक है, ताकि यह सुनिश्चित हो सके कि सब कुछ लक्षित प्लेटफॉर्म के मानकों के अनुरूप है।
सारांश
यही वे सामान्य प्रश्न हैं जिनके उत्तर आविष्कारकों द्वारा कार्यप्रवाहों को मात्रात्मक रूप से विन्यासित करने संबंधी प्रक्रिया में दिए गए हैं। हमने पर्यावरण कॉन्फ़िगरेशन, नोड्स की कार्यप्रणाली, डेटा पढ़ने की प्रक्रिया, कोड स्टैंडर्ड, एआई का उपयोग, तथा पुनरावलोकन परीक्षणों तक के सभी पहलुओं पर चर्चा की है; ये सभी वास्तविक अनुभवों में आम रूप से आने वाली समस्याएँ हैं। इन ज्ञान-बिंदुओं को समझ लेने से, आपको विकास प्रक्रिया में बहुत कम दिक्कतों का सामना करना पड़ेगा।
लेकिन क्वांटिटेटिव ट्रेडिंग एक निरंतर सीखने की प्रक्रिया है, एवं लगातार नई समस्याएँ उत्पन्न होती रहती हैं। समस्याओं का सामना करते समय हतोत्साहित न हों; पहले FMZ के आधिकारिक दस्तावेज़ों को देखें, एवं समुदाय में हो रही चर्चाओं को भी पढ़ें। बहुत सी समस्याएँ पहले ही अन्य लोगों द्वारा हल की जा चुकी हैं। यदि फिर भी कोई समस्या हल न हो, तो प्लेटफॉर्म पर एक विनंति दर्ज करके इंजीनियरों से पूछ सकते हैं। सभी लोगों को कमेंट सेक्शन में अपने अनुभव साझा करने की भी अनुमति है; ताकि अन्य क्वांटिटेटिव ट्रेडरों के साथ अनुभवों का आदान-प्रदान किया जा सके।
याद रखें: समस्याएं ही सबसे अच्छे शिक्षक होती हैं; हर समस्या को हल करने पर, आपकी वर्कफ्लो संबंधी जानकारी और भी गहरी हो जाती है। उम्मीद है कि यह FAQ सभी को वर्कफ्लो का उपयोग करके मात्रात्मक रणनीतियाँ विकसित करने में अधिक सहायता करेगा!


- 1