

पिछले लेख (https://www.fmz.com/digest-topic/4187) में, हमने जोड़ी ट्रेडिंग रणनीतियों को पेश किया और दिखाया कि ट्रेडिंग रणनीतियों को बनाने और स्वचालित करने के लिए डेटा और गणितीय विश्लेषण का उपयोग कैसे किया जाए।
दीर्घ-लघु संतुलित इक्विटी रणनीति, व्यापारिक लक्ष्यों की एक टोकरी पर लागू जोड़ी ट्रेडिंग रणनीति का एक स्वाभाविक विस्तार है। यह विशेष रूप से कई प्रकार और अंतर्संबंधों वाले व्यापारिक बाजारों के लिए उपयुक्त है, जैसे कि डिजिटल मुद्रा बाजार और कमोडिटी वायदा बाजार।
मूलरूप आदर्श
दीर्घ-लघु संतुलित इक्विटी रणनीति में एक ही समय में व्यापारिक लक्ष्यों की एक टोकरी पर दीर्घ और लघु जाना शामिल है। जोड़ी ट्रेडिंग की तरह ही, यह निर्धारित करें कि कौन से निवेश लक्ष्य सस्ते हैं और कौन से महंगे हैं। अंतर यह है कि लॉन्ग-शॉर्ट बैलेंस्ड इक्विटी रणनीति स्टॉक चयन पूल में सभी निवेश लक्ष्यों को रैंक करेगी ताकि यह निर्धारित किया जा सके कि कौन से निवेश लक्ष्य अपेक्षाकृत सस्ते हैं। या महंगे हैं। इसके बाद यह रैंकिंग के आधार पर शीर्ष n निवेशों पर लंबी अवधि के लिए निवेश करेगा, तथा नीचे के n निवेशों पर समान राशि के साथ छोटी अवधि के लिए निवेश करेगा (लंबी अवधि के निवेशों का कुल मूल्य = छोटी अवधि के निवेशों का कुल मूल्य)।
याद कीजिए जब हमने कहा था कि युग्म व्यापार एक बाजार तटस्थ रणनीति है? यही बात दीर्घ-अल्प संतुलित इक्विटी रणनीति के लिए भी सत्य है, क्योंकि दीर्घ और लघु स्थितियों की समान मात्रा यह सुनिश्चित करती है कि रणनीति बाजार तटस्थ रहेगी (बाजार के उतार-चढ़ाव से प्रभावित नहीं होगी)। यह रणनीति सांख्यिकीय रूप से भी मजबूत है; निवेशों को रैंकिंग देकर और कई पोजीशन लेकर, आप अपने रैंकिंग मॉडल को केवल एक बार के जोखिम के बजाय कई जोखिमों के लिए उजागर कर सकते हैं। आप केवल अपनी रैंकिंग योजना की गुणवत्ता पर ही दांव लगा रहे हैं।
रैंकिंग योजना क्या है?
रैंकिंग योजना एक मॉडल है जो प्रत्येक निवेश लक्ष्य को उसके अपेक्षित प्रदर्शन के आधार पर प्राथमिकता प्रदान करती है। ये कारक मूल्य कारक, तकनीकी संकेतक, मूल्य निर्धारण मॉडल या उपरोक्त सभी का संयोजन हो सकते हैं। उदाहरण के लिए, आप प्रवृत्ति-अनुसरण करने वाले निवेशों की सूची को रैंक करने के लिए गति मीट्रिक का उपयोग कर सकते हैं: उच्चतम गति वाले निवेशों से यह अपेक्षा की जाएगी कि वे अच्छा प्रदर्शन करना जारी रखेंगे और उच्चतम रैंकिंग प्राप्त करेंगे; सबसे कम गति वाले निवेशों का प्रदर्शन सबसे खराब होगा और सबसे कम रिटर्न मिलता है।
इस रणनीति की सफलता लगभग पूरी तरह से प्रयुक्त रैंकिंग योजना पर निर्भर करती है, अर्थात, आपकी रैंकिंग योजना उच्च-प्रदर्शन वाले निवेशों को निम्न-प्रदर्शन वाले निवेशों से अलग करने में सक्षम है, जिससे दीर्घ-अल्प निवेश लक्ष्य रणनीति के रिटर्न को बेहतर ढंग से प्राप्त किया जा सके। इसलिए, रैंकिंग योजना विकसित करना बहुत महत्वपूर्ण है।
रैंकिंग योजना कैसे तैयार करें?
एक बार जब हमारे पास रैंकिंग योजना तैयार हो जाएगी, तो हम निश्चित रूप से उससे लाभ प्राप्त करना चाहेंगे। ऐसा हम शीर्ष स्तर के निवेशों में लंबी अवधि के लिए तथा निम्नतम स्तर के निवेशों में छोटी अवधि के लिए समान राशि का निवेश करके करते हैं। इससे यह सुनिश्चित होता है कि रणनीति केवल अपनी रैंकिंग की गुणवत्ता के अनुपात में ही धन अर्जित करेगी और "बाजार तटस्थ" होगी।
मान लीजिए कि आप सभी निवेशों को m श्रेणी में रख रहे हैं, आपके पास निवेश करने के लिए n डॉलर हैं, तथा आप कुल 2p (जहाँ m>2p) पोजीशन रखना चाहते हैं। यदि रैंक 1 वाले निवेश से सबसे खराब प्रदर्शन की उम्मीद है, तो रैंक m वाले निवेश से सबसे अच्छा प्रदर्शन की उम्मीद है:
-
आप निवेश लक्ष्यों को इस प्रकार व्यवस्थित करते हैं: 1, ..., p, और लघु 2/2p USD निवेश लक्ष्य
-
आप निवेश लक्ष्यों को इस प्रकार व्यवस्थित करते हैं: m-p,......,m, तथा n/2p डॉलर के निवेश लक्ष्यों पर लंबे समय तक बने रहते हैं
**सूचना:**चूंकि मूल्य वृद्धि के कारण लक्ष्य मूल्य हमेशा n/2p को समान रूप से विभाजित नहीं करेगा, और कुछ लक्ष्यों को पूर्णांक में खरीदा जाना चाहिए, इसलिए कुछ अनिश्चित एल्गोरिदम होंगे, और एल्गोरिदम को यथासंभव इस संख्या के करीब होना चाहिए। n = 100000 और p = 500 के साथ चलने वाली रणनीति के लिए, हम देखते हैं:
n/2p = 100000/1000 = 100
यह 100 से अधिक अंशों वाली कीमतों (जैसे कमोडिटी वायदा बाजार) के लिए बड़ी समस्या पैदा कर सकता है, क्योंकि आप अंशों वाली कीमतों के साथ पोजीशन नहीं खोल सकते हैं (यह समस्या क्रिप्टोकरेंसी बाजार में मौजूद नहीं है)। हम आंशिक मूल्य व्यापार को कम करके या पूंजी बढ़ाकर इसे कम करते हैं।
आइये एक काल्पनिक उदाहरण देखें।
- इन्वेंटर क्वांटिटेटिव प्लेटफॉर्म पर हमारे शोध वातावरण का निर्माण
सबसे पहले, सुचारू रूप से काम करने के लिए, हमें अपने शोध वातावरण का निर्माण करने की आवश्यकता है। इस लेख में, हम शोध वातावरण बनाने के लिए इन्वेंटर क्वांटिटेटिव प्लेटफ़ॉर्म (FMZ.COM) का उपयोग करते हैं, मुख्य रूप से इसलिए कि हम सुविधाजनक और तेज़ API का उपयोग कर सकें इस प्लेटफ़ॉर्म का इंटरफ़ेस और एनकैप्सुलेशन बाद में। पूरा Docker सिस्टम।
इन्वेंटर क्वांटिटेटिव प्लेटफॉर्म के आधिकारिक नाम में, इस डॉकर सिस्टम को होस्ट सिस्टम कहा जाता है।
होस्ट और रोबोट को तैनात करने के तरीके के बारे में अधिक जानकारी के लिए, कृपया मेरा पिछला लेख देखें: https://www.fmz.com/bbs-topic/4140
जो पाठक अपना स्वयं का क्लाउड कंप्यूटिंग सर्वर परिनियोजन होस्ट खरीदना चाहते हैं, वे इस लेख का संदर्भ ले सकते हैं: https://www.fmz.com/bbs-topic/2848
क्लाउड कंप्यूटिंग सेवा और होस्ट सिस्टम को सफलतापूर्वक तैनात करने के बाद, हम सबसे शक्तिशाली पायथन टूल स्थापित करेंगे: एनाकोंडा
इस आलेख के लिए आवश्यक सभी प्रासंगिक प्रोग्राम वातावरण (आश्रित लाइब्रेरीज़, संस्करण प्रबंधन, आदि) को प्राप्त करने के लिए, सबसे आसान तरीका एनाकोंडा का उपयोग करना है। यह एक पैकेज्ड पायथन डेटा विज्ञान पारिस्थितिकी तंत्र और निर्भरता प्रबंधक है।
एनाकोंडा की स्थापना विधि के लिए, कृपया एनाकोंडा की आधिकारिक मार्गदर्शिका देखें: https://www.anaconda.com/distribution/
यह आलेख पाइथन वैज्ञानिक कंप्यूटिंग में दो बहुत लोकप्रिय और महत्वपूर्ण लाइब्रेरीज़, numpy और pandas का भी उपयोग करेगा।
उपरोक्त बुनियादी काम के लिए, आप मेरे पिछले लेख को भी देख सकते हैं, जिसमें एनाकोंडा वातावरण और दो लाइब्रेरीज़ numpy और pandas को सेट अप करने का तरीका बताया गया है। विवरण के लिए, कृपया देखें: https://www.fmz.com/digest- विषय/4169
हम यादृच्छिक निवेश और यादृच्छिक कारक उत्पन्न करते हैं और उन्हें रैंक करते हैं। आइए हम यह मान लें कि हमारा भावी रिटर्न वास्तव में इन कारक मूल्यों पर निर्भर करता है।
import numpy as np
import statsmodels.api as sm
import scipy.stats as stats
import scipy
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
## PROBLEM SETUP ##
# Generate stocks and a random factor value for them
stock_names = ['stock ' + str(x) for x in range(10000)]
current_factor_values = np.random.normal(0, 1, 10000)
# Generate future returns for these are dependent on our factor values
future_returns = current_factor_values + np.random.normal(0, 1, 10000)
# Put both the factor values and returns into one dataframe
data = pd.DataFrame(index = stock_names, columns=['Factor Value','Returns'])
data['Factor Value'] = current_factor_values
data['Returns'] = future_returns
# Take a look
data.head(10)
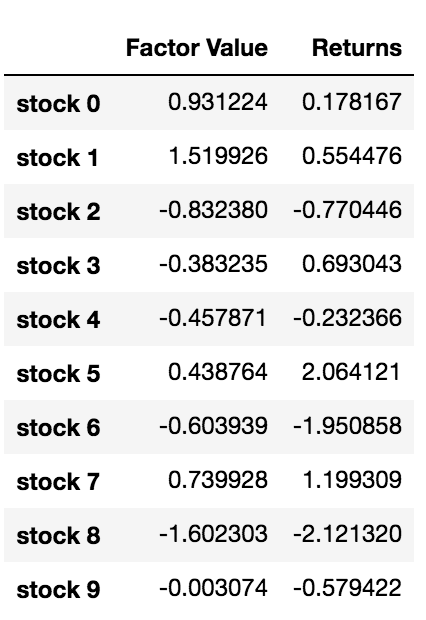
अब जब हमारे पास कारक मूल्य और रिटर्न हैं, तो हम देख सकते हैं कि क्या होता है यदि हम कारक मूल्यों के आधार पर निवेशों को रैंक करते हैं और फिर लंबी और छोटी स्थिति खोलते हैं।
# Rank stocks
ranked_data = data.sort_values('Factor Value')
# Compute the returns of each basket with a basket size 500, so total (10000/500) baskets
number_of_baskets = int(10000/500)
basket_returns = np.zeros(number_of_baskets)
for i in range(number_of_baskets):
start = i * 500
end = i * 500 + 500
basket_returns[i] = ranked_data[start:end]['Returns'].mean()
# Plot the returns of each basket
plt.figure(figsize=(15,7))
plt.bar(range(number_of_baskets), basket_returns)
plt.ylabel('Returns')
plt.xlabel('Basket')
plt.legend(['Returns of Each Basket'])
plt.show()
हमारी रणनीति निवेश लक्ष्यों की टोकरी में पहले स्थान पर स्थित निवेश पर लंबे समय तक बने रहने और दसवें स्थान पर स्थित निवेश लक्ष्य पर कम समय तक बने रहने की है। इस रणनीति के लाभ इस प्रकार हैं:
basket_returns[number_of_baskets-1] - basket_returns[0]
परिणाम है: 4.172
उच्च प्रदर्शन वाले निवेशों को निम्न प्रदर्शन वाले निवेशों से अलग करने के लिए अपना पैसा हमारे रैंकिंग मॉडल पर लगाएं।
इस लेख के शेष भाग में हम चर्चा करेंगे कि रैंकिंग योजनाओं का मूल्यांकन कैसे किया जाए। रैंकिंग-आधारित मध्यस्थता से पैसा कमाने का लाभ यह है कि यह बाजार की अव्यवस्था से प्रभावित नहीं होता, बल्कि इसका लाभ उठाया जा सकता है।
आइये एक वास्तविक दुनिया का उदाहरण लें।
हम S&P 500 में विभिन्न क्षेत्रों के 32 स्टॉकों का डेटा लोड करते हैं और उन्हें रैंक करने का प्रयास करते हैं।
from backtester.dataSource.yahoo_data_source import YahooStockDataSource
from datetime import datetime
startDateStr = '2010/01/01'
endDateStr = '2017/12/31'
cachedFolderName = '/Users/chandinijain/Auquan/yahooData/'
dataSetId = 'testLongShortTrading'
instrumentIds = ['ABT','AKS','AMGN','AMD','AXP','BK','BSX',
'CMCSA','CVS','DIS','EA','EOG','GLW','HAL',
'HD','LOW','KO','LLY','MCD','MET','NEM',
'PEP','PG','M','SWN','T','TGT',
'TWX','TXN','USB','VZ','WFC']
ds = YahooStockDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds,
startDateStr=startDateStr,
endDateStr=endDateStr,
event='history')
price = 'adjClose'
आइए रैंकिंग के आधार के रूप में एक महीने की अवधि में सामान्यीकृत गति सूचक का उपयोग करें
## Define normalized momentum
def momentum(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0) / dataDf.iloc[-1]
## Load relevant prices in a dataframe
data = ds.getBookDataByFeature()[‘Adj Close’]
#Let's load momentum score and returns into separate dataframes
index = data.index
mscores = pd.DataFrame(index=index,columns=assetList)
mscores = momentum(data, 30)
returns = pd.DataFrame(index=index,columns=assetList)
day = 30
अब हम अपने स्टॉक के व्यवहार का विश्लेषण करेंगे और देखेंगे कि हमारे द्वारा चुने गए रैंकिंग कारकों के भीतर हमारा स्टॉक बाजार में कैसा प्रदर्शन करता है।
डेटा का विश्लेषण करें
स्टॉक व्यवहार
आइए देखें कि हमारे द्वारा चयनित स्टॉक की टोकरी हमारे रैंकिंग मॉडल में कैसा प्रदर्शन करती है। ऐसा करने के लिए, आइए सभी स्टॉक के लिए एक सप्ताह के अग्रिम रिटर्न की गणना करें। इसके बाद हम प्रत्येक स्टॉक के 1-सप्ताह के अग्रिम रिटर्न का पिछले 30-दिन के मोमेंटम के साथ सहसंबंध देख सकते हैं। जो स्टॉक सकारात्मक सहसंबंध दर्शाते हैं वे प्रवृत्ति का अनुसरण करने वाले होते हैं, और जो स्टॉक नकारात्मक सहसंबंध दर्शाते हैं वे माध्य प्रतिवर्ती होते हैं।
# Calculate Forward returns
forward_return_day = 5
returns = data.shift(-forward_return_day)/data -1
returns.dropna(inplace = True)
# Calculate correlations between momentum and returns
correlations = pd.DataFrame(index = returns.columns, columns = [‘Scores’, ‘pvalues’])
mscores = mscores[mscores.index.isin(returns.index)]
for i in correlations.index:
score, pvalue = stats.spearmanr(mscores[i], returns[i])
correlations[‘pvalues’].loc[i] = pvalue
correlations[‘Scores’].loc[i] = score
correlations.dropna(inplace = True)
correlations.sort_values(‘Scores’, inplace=True)
l = correlations.index.size
plt.figure(figsize=(15,7))
plt.bar(range(1,1+l),correlations[‘Scores’])
plt.xlabel(‘Stocks’)
plt.xlim((1, l+1))
plt.xticks(range(1,1+l), correlations.index)
plt.legend([‘Correlation over All Data’])
plt.ylabel(‘Correlation between %s day Momentum Scores and %s-day forward returns by Stock’%(day,forward_return_day));
plt.show()
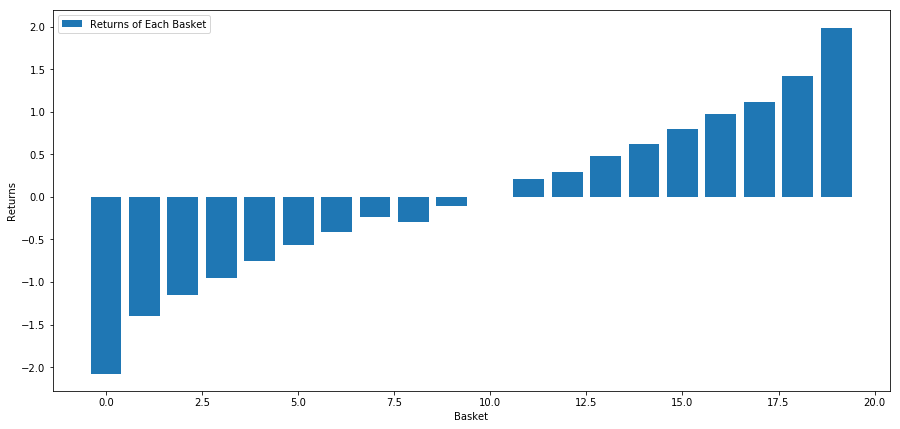
हमारे सभी स्टॉक का मतलब कुछ हद तक वापस आ जाता है! (स्पष्टतः हमारा चुना हुआ ब्रह्मांड इसी तरह काम करता है) इससे हमें पता चलता है कि यदि कोई स्टॉक गति विश्लेषण में उच्च स्थान पर है, तो हमें उम्मीद करनी चाहिए कि अगले सप्ताह उसका प्रदर्शन खराब रहेगा।
मोमेंटम स्कोर रैंकिंग और रिटर्न के बीच सहसंबंध
इसके बाद, हमें अपने रैंकिंग स्कोर और बाजार के समग्र अग्रिम रिटर्न के बीच सहसंबंध को देखने की आवश्यकता है, अर्थात, अपेक्षित रिटर्न की भविष्यवाणी और हमारे रैंकिंग कारकों के बीच संबंध। क्या उच्च सहसंबंध स्तर खराब सापेक्ष रिटर्न की भविष्यवाणी कर सकते हैं, या इसके विपरीत?
ऐसा करने के लिए, हम सभी स्टॉक के लिए 30-दिवसीय गति और 1-सप्ताह के अग्रिम रिटर्न के बीच दैनिक सहसंबंध की गणना करते हैं।
correl_scores = pd.DataFrame(index = returns.index.intersection(mscores.index), columns = [‘Scores’, ‘pvalues’])
for i in correl_scores.index:
score, pvalue = stats.spearmanr(mscores.loc[i], returns.loc[i])
correl_scores[‘pvalues’].loc[i] = pvalue
correl_scores[‘Scores’].loc[i] = score
correl_scores.dropna(inplace = True)
l = correl_scores.index.size
plt.figure(figsize=(15,7))
plt.bar(range(1,1+l),correl_scores[‘Scores’])
plt.hlines(np.mean(correl_scores[‘Scores’]), 1,l+1, colors=’r’, linestyles=’dashed’)
plt.xlabel(‘Day’)
plt.xlim((1, l+1))
plt.legend([‘Mean Correlation over All Data’, ‘Daily Rank Correlation’])
plt.ylabel(‘Rank correlation between %s day Momentum Scores and %s-day forward returns’%(day,forward_return_day));
plt.show()
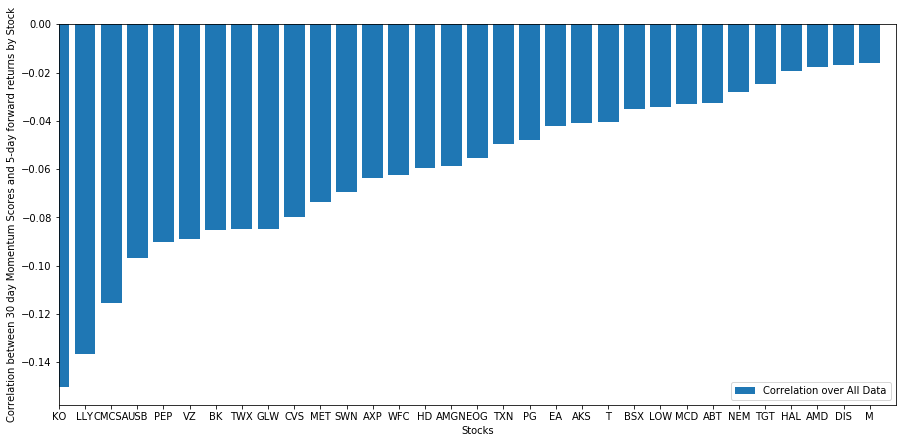
दैनिक सहसंबंध काफी शोरगुल वाला है, लेकिन बहुत हल्का है (जो कि अपेक्षित है क्योंकि हमने कहा था कि सभी स्टॉक औसत पर लौट आएंगे)। हम एक माह के अग्रिम रिटर्न के औसत मासिक सहसंबंध को भी देखते हैं।
monthly_mean_correl =correl_scores['Scores'].astype(float).resample('M').mean()
plt.figure(figsize=(15,7))
plt.bar(range(1,len(monthly_mean_correl)+1), monthly_mean_correl)
plt.hlines(np.mean(monthly_mean_correl), 1,len(monthly_mean_correl)+1, colors='r', linestyles='dashed')
plt.xlabel('Month')
plt.xlim((1, len(monthly_mean_correl)+1))
plt.legend(['Mean Correlation over All Data', 'Monthly Rank Correlation'])
plt.ylabel('Rank correlation between %s day Momentum Scores and %s-day forward returns'%(day,forward_return_day));
plt.show()
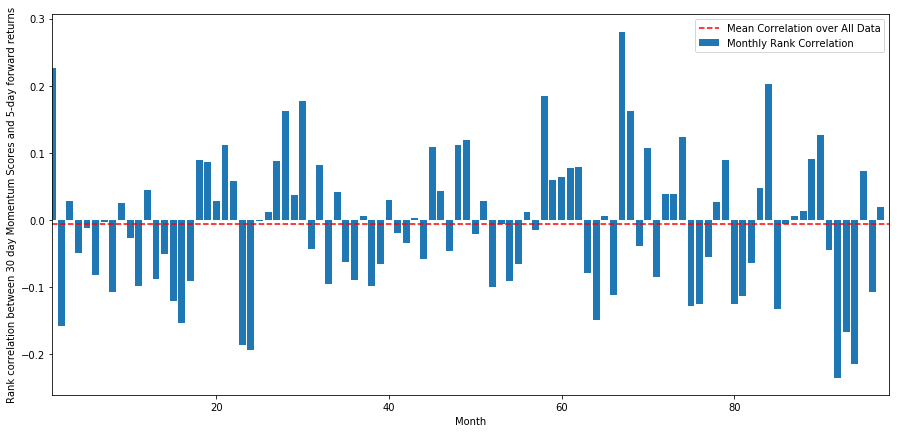
हम देख सकते हैं कि औसत सहसंबंध फिर से थोड़ा नकारात्मक है, लेकिन महीने दर महीने इसमें भी काफी बदलाव होता है।
स्टॉक रिटर्न की औसत बास्केट
हमने अपनी रैंकिंग से लिए गए स्टॉक की एक टोकरी के लिए रिटर्न की गणना की है। यदि हम सभी स्टॉक को क्रमित करें और फिर उन्हें n समूहों में विभाजित करें, तो प्रत्येक समूह का औसत रिटर्न क्या होगा?
पहला कदम एक ऐसा फंक्शन बनाना है जो प्रत्येक महीने दिए गए प्रत्येक बास्केट के लिए औसत रिटर्न और रैंकिंग फैक्टर देगा।
def compute_basket_returns(factor, forward_returns, number_of_baskets, index):
data = pd.concat([factor.loc[index],forward_returns.loc[index]], axis=1)
# Rank the equities on the factor values
data.columns = ['Factor Value', 'Forward Returns']
data.sort_values('Factor Value', inplace=True)
# How many equities per basket
equities_per_basket = np.floor(len(data.index) / number_of_baskets)
basket_returns = np.zeros(number_of_baskets)
# Compute the returns of each basket
for i in range(number_of_baskets):
start = i * equities_per_basket
if i == number_of_baskets - 1:
# Handle having a few extra in the last basket when our number of equities doesn't divide well
end = len(data.index) - 1
else:
end = i * equities_per_basket + equities_per_basket
# Actually compute the mean returns for each basket
#s = data.index.iloc[start]
#e = data.index.iloc[end]
basket_returns[i] = data.iloc[int(start):int(end)]['Forward Returns'].mean()
return basket_returns
इस स्कोर के आधार पर स्टॉकों की रैंकिंग करते समय हम प्रत्येक बास्केट के लिए औसत रिटर्न की गणना करते हैं। इससे हमें लंबे समय तक उनके संबंधों का अच्छा अंदाजा मिल जाएगा।
number_of_baskets = 8
mean_basket_returns = np.zeros(number_of_baskets)
resampled_scores = mscores.astype(float).resample('2D').last()
resampled_prices = data.astype(float).resample('2D').last()
resampled_scores.dropna(inplace=True)
resampled_prices.dropna(inplace=True)
forward_returns = resampled_prices.shift(-1)/resampled_prices -1
forward_returns.dropna(inplace = True)
for m in forward_returns.index.intersection(resampled_scores.index):
basket_returns = compute_basket_returns(resampled_scores, forward_returns, number_of_baskets, m)
mean_basket_returns += basket_returns
mean_basket_returns /= l
print(mean_basket_returns)
# Plot the returns of each basket
plt.figure(figsize=(15,7))
plt.bar(range(number_of_baskets), mean_basket_returns)
plt.ylabel('Returns')
plt.xlabel('Basket')
plt.legend(['Returns of Each Basket'])
plt.show()
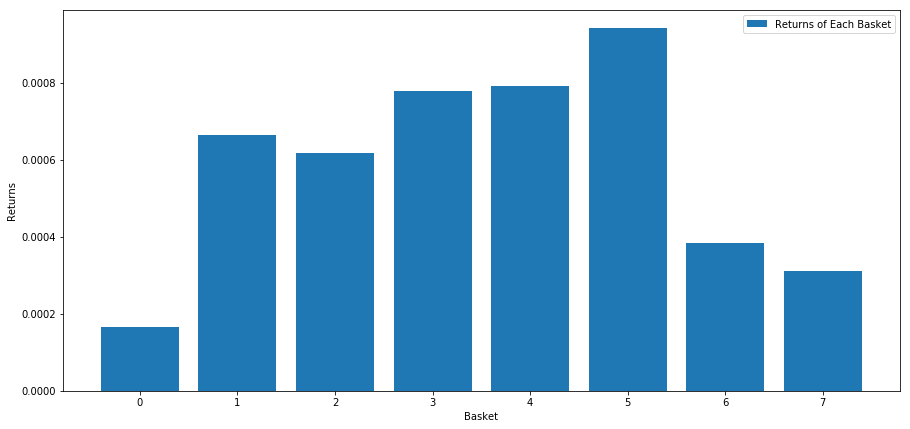
ऐसा लगता है कि हम उच्च प्रदर्शन करने वालों को निम्न प्रदर्शन करने वालों से अलग करने में सक्षम हैं।
प्रसार (आधार) स्थिरता
बेशक, ये सिर्फ औसत रिश्ते हैं। यह समझने के लिए कि संबंध कितना सुसंगत है और क्या हम समझौता करने के लिए तैयार हैं, हमें समय के साथ इसके प्रति अपना दृष्टिकोण और रवैया बदलना चाहिए। इसके बाद, हम पिछले दो वर्षों के उनके मासिक प्रसार (आधार) पर नजर डालेंगे। हम और अधिक परिवर्तन देख सकते हैं तथा यह निर्धारित करने के लिए आगे विश्लेषण कर सकते हैं कि क्या यह गति स्कोर व्यापार योग्य है।
total_months = mscores.resample('M').last().index
months_to_plot = 24
monthly_index = total_months[:months_to_plot+1]
mean_basket_returns = np.zeros(number_of_baskets)
strategy_returns = pd.Series(index = monthly_index)
f, axarr = plt.subplots(1+int(monthly_index.size/6), 6,figsize=(18, 15))
for month in range(1, monthly_index.size):
temp_returns = forward_returns.loc[monthly_index[month-1]:monthly_index[month]]
temp_scores = resampled_scores.loc[monthly_index[month-1]:monthly_index[month]]
for m in temp_returns.index.intersection(temp_scores.index):
basket_returns = compute_basket_returns(temp_scores, temp_returns, number_of_baskets, m)
mean_basket_returns += basket_returns
strategy_returns[monthly_index[month-1]] = mean_basket_returns[ number_of_baskets-1] - mean_basket_returns[0]
mean_basket_returns /= temp_returns.index.intersection(temp_scores.index).size
r = int(np.floor((month-1) / 6))
c = (month-1) % 6
axarr[r, c].bar(range(number_of_baskets), mean_basket_returns)
axarr[r, c].xaxis.set_visible(False)
axarr[r, c].set_title('Month ' + str(month))
plt.show()
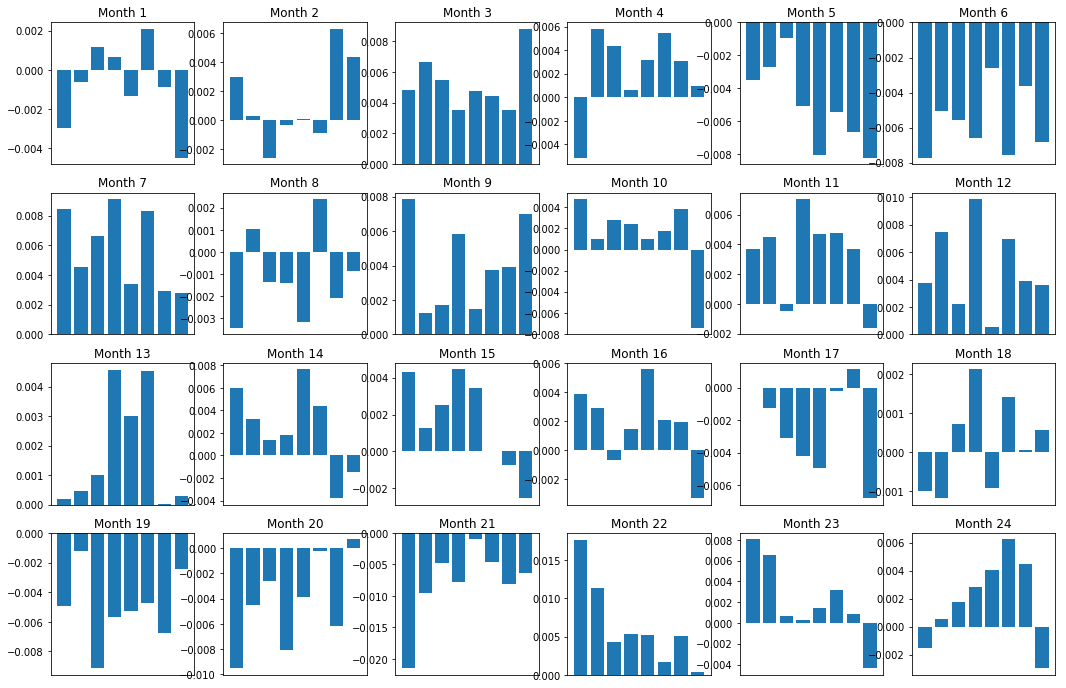
plt.figure(figsize=(15,7))
plt.plot(strategy_returns)
plt.ylabel(‘Returns’)
plt.xlabel(‘Month’)
plt.plot(strategy_returns.cumsum())
plt.legend([‘Monthly Strategy Returns’,’Cumulative Strategy Returns’])
plt.show()
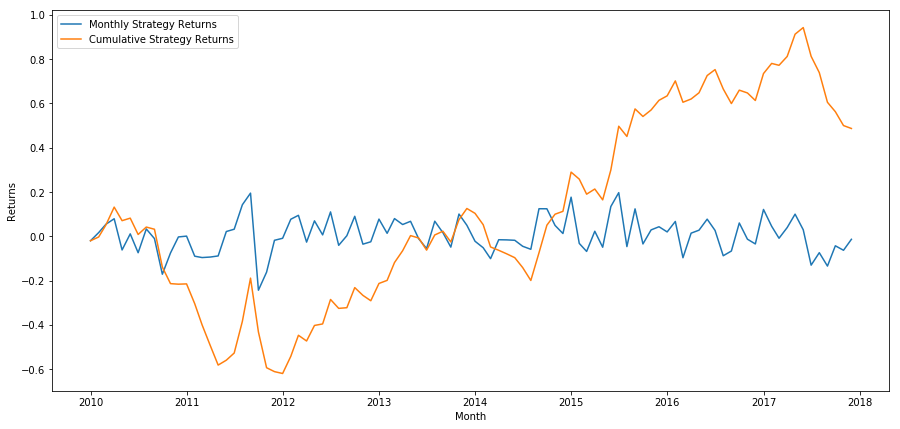
अंत में, आइए देखें कि यदि हम प्रत्येक महीने अंतिम बास्केट में लंबे समय तक और पहली बास्केट में कम समय तक निवेश करते हैं तो हमें कितना रिटर्न मिलेगा (यह मानते हुए कि प्रत्येक सुरक्षा के लिए समान पूंजी आवंटन है)
total_return = strategy_returns.sum()
ann_return = 100*((1 + total_return)**(12.0 /float(strategy_returns.index.size))-1)
print('Annual Returns: %.2f%%'%ann_return)
वार्षिक रिटर्न: 5.03%
हम देखते हैं कि हमारे पास एक बहुत ही कमजोर रैंकिंग योजना है जो केवल उच्च प्रदर्शन वाले स्टॉक को कम प्रदर्शन वाले स्टॉक से मामूली रूप से अलग करती है। इसके अलावा, इस रैंकिंग योजना में कोई स्थिरता नहीं है और यह महीने-दर-महीने व्यापक रूप से बदलती रहती है।
सही रैंकिंग योजना ढूँढना
दीर्घ-अल्प संतुलित इक्विटी रणनीति को क्रियान्वित करने के लिए, आपको वास्तव में केवल रैंकिंग योजना निर्धारित करने की आवश्यकता है। उसके बाद सब कुछ यांत्रिक है। एक बार जब आपके पास दीर्घ-अल्प संतुलित इक्विटी रणनीति तैयार हो जाती है, तो आप बिना ज्यादा कुछ बदले विभिन्न रैंकिंग कारकों को बदल सकते हैं। यह आपके विचारों को शीघ्रता से दोहराने का एक बहुत ही सुविधाजनक तरीका है, तथा हर बार पूरे कोड में बदलाव करने की चिंता नहीं करनी पड़ती।
रैंकिंग योजना लगभग किसी भी मॉडल से आ सकती है। यह कोई मूल्य-आधारित कारक मॉडल नहीं है, यह एक मशीन लर्निंग तकनीक भी हो सकती है जो एक महीने पहले ही रिटर्न की भविष्यवाणी कर देती है और उसके आधार पर उन्हें रैंक कर देती है।
रैंकिंग योजनाओं का चयन और मूल्यांकन
रैंकिंग योजना दीर्घ-लघु संतुलित इक्विटी रणनीति का लाभ है और यह सबसे महत्वपूर्ण घटक भी है। एक अच्छी रैंकिंग योजना का चयन एक व्यवस्थित परियोजना है और इसका कोई सरल उत्तर नहीं है।
एक अच्छा प्रारंभिक बिंदु यह है कि आप विद्यमान ज्ञात प्रौद्योगिकियों को चुनें और देखें कि क्या आप उच्च रिटर्न पाने के लिए उनमें थोड़ा संशोधन कर सकते हैं। हम यहां कुछ प्रारंभिक बिंदुओं पर चर्चा करेंगे:
-
क्लोन करें और समायोजित करेंकोई ऐसी बात चुनें जिस पर अक्सर चर्चा होती है और देखें कि क्या आप उसे अपने फायदे के लिए थोड़ा संशोधित कर सकते हैं। आमतौर पर, सार्वजनिक कारकों में अब ट्रेडिंग सिग्नल नहीं होंगे क्योंकि उन्हें बाजार से पूरी तरह से बाहर कर दिया गया है। हालाँकि, कभी-कभी वे आपको सही दिशा में ले जा सकते हैं।
-
मूल्य निर्धारण मॉडलकोई भी मॉडल जो भविष्य के रिटर्न की भविष्यवाणी करता है, एक कारक हो सकता है और आपके ट्रेडिंग लक्ष्यों की रैंकिंग के लिए इसका उपयोग किया जा सकता है। आप किसी भी जटिल मूल्य निर्धारण मॉडल को लेकर उसे रैंकिंग योजना में परिवर्तित कर सकते हैं।
-
**मूल्य-आधारित कारक (तकनीकी संकेतक)**मूल्य-आधारित कारक, जैसे कि हमने आज चर्चा की है, प्रत्येक इक्विटी के ऐतिहासिक मूल्य के बारे में जानकारी लेते हैं और इसका उपयोग कारक मूल्य उत्पन्न करने के लिए करते हैं। उदाहरणार्थ चल औसत सूचक, गति सूचक या अस्थिरता सूचक।
-
प्रतिगमन और गतियह ध्यान देने योग्य है कि कुछ कारकों का मानना है कि एक बार कीमतें एक दिशा में बढ़ जाती हैं, तो वे ऐसा करना जारी रखती हैं। कुछ कारक इसके ठीक विपरीत हैं। दोनों ही अलग-अलग समय-सीमाओं और परिसंपत्तियों पर मान्य मॉडल हैं, और यह अध्ययन करना महत्वपूर्ण है कि अंतर्निहित व्यवहार गति या प्रतिगमन आधारित है।
-
मौलिक कारक (मूल्य-आधारित): यह पीई, लाभांश आदि जैसे मौलिक मूल्यों के संयोजन का उपयोग कर रहा है। मौलिक मूल्य में किसी कंपनी के बारे में वास्तविक दुनिया के तथ्यों से संबंधित जानकारी शामिल होती है और इसलिए यह कई मायनों में कीमत से अधिक शक्तिशाली हो सकती है।
अंततः, भविष्यवक्ता विकसित करना एक हथियार दौड़ है, जहां आप एक कदम आगे रहने की कोशिश कर रहे हैं। फैक्टरों को बाजार से बाहर निकाल दिया जाता है और उनका एक जीवनकाल होता है, इसलिए आपको यह निर्धारित करने के लिए लगातार काम करना चाहिए कि आपके फैक्टरों में कितना क्षय हुआ है और उनके स्थान पर कौन से नए फैक्टरों का उपयोग किया जा सकता है।
अन्य विचार
- पुनर्संतुलन आवृत्ति
प्रत्येक रैंकिंग प्रणाली थोड़ी अलग समयावधि में रिटर्न की भविष्यवाणी करती है। मूल्य-आधारित माध्य प्रत्यावर्तन कुछ दिनों में पूर्वानुमानित हो सकता है, जबकि मूल्य-आधारित कारक मॉडल कुछ महीनों में पूर्वानुमानित हो सकता है। रणनीति को क्रियान्वित करने से पहले मॉडल द्वारा पूर्वानुमानित समय-सीमा का निर्धारण करना तथा सांख्यिकीय रूप से उसका सत्यापन करना बहुत महत्वपूर्ण है। आप निश्चित रूप से अपनी पुनर्संतुलन आवृत्ति को अनुकूलित करने की कोशिश करके ओवरफिट नहीं करना चाहते हैं; आप अनिवार्य रूप से एक ऐसा पाएंगे जो बेतरतीब ढंग से दूसरों से बेहतर प्रदर्शन करता है। एक बार जब आप अपनी रैंकिंग योजना की भविष्यवाणी के अनुसार समय क्षितिज निर्धारित कर लेते हैं, तो लगभग उसी आवृत्ति पर पुनर्संतुलन करने का प्रयास करें ताकि अपने मॉडल से अधिकतम लाभ उठाएं.
- पूंजी क्षमता और लेनदेन लागत
प्रत्येक रणनीति में न्यूनतम और अधिकतम पूंजी आवश्यकता होती है, न्यूनतम सीमा आमतौर पर लेनदेन लागत द्वारा निर्धारित होती है।
बहुत अधिक स्टॉक का व्यापार करने से लेनदेन लागत बहुत अधिक हो जाएगी। मान लीजिए कि आप 1,000 शेयर खरीदना चाहते हैं, तो प्रत्येक पुनर्संतुलन पर कई हजार डॉलर की लागत आएगी। आपका पूंजी आधार इतना ऊंचा होना चाहिए कि लेनदेन लागत आपकी रणनीति द्वारा उत्पन्न रिटर्न का एक छोटा सा हिस्सा हो। उदाहरण के लिए, यदि आपकी पूंजी 100,000 डॉलर है और आपकी रणनीति प्रति माह 1% ($1000) कमाती है, तो वह सारा रिटर्न लेनदेन लागत में खत्म हो जाएगा। 1,000 से अधिक शेयरों पर लाभ कमाने के लिए इस रणनीति को चलाने के लिए आपको लाखों डॉलर की पूंजी की आवश्यकता होगी।
न्यूनतम परिसंपत्ति सीमा मुख्य रूप से कारोबार किए गए स्टॉक की संख्या पर निर्भर करती है। हालांकि, अधिकतम क्षमता भी बहुत अधिक है, और लंबी-छोटी संतुलित इक्विटी रणनीतियाँ अपनी बढ़त खोए बिना सैकड़ों मिलियन डॉलर का व्यापार करने में सक्षम हैं। यह सच है क्योंकि रणनीति को अपेक्षाकृत कम बार पुनर्संतुलित किया जाता है। कुल परिसंपत्ति राशि को कारोबार किए गए शेयरों की संख्या से विभाजित करने पर प्रति शेयर बहुत कम डॉलर मूल्य मिलेगा, और आपको अपने ट्रेडिंग वॉल्यूम से बाजार को प्रभावित करने की चिंता करने की ज़रूरत नहीं है। मान लीजिए आप 1,000 शेयरों का व्यापार करते हैं, तो यह 100,000,000 डॉलर होगा। यदि आप प्रत्येक माह अपने सम्पूर्ण पोर्टफोलियो को पुनर्संतुलित करते हैं, तो आप प्रति शेयर प्रति माह केवल $100,000 का ही व्यापार करेंगे, जो कि अधिकांश प्रतिभूतियों के लिए महत्वपूर्ण बाजार हिस्सेदारी के लिए पर्याप्त नहीं है।
- 1