
Dalam proses menggunakan Inventor Quantify Workflow, banyak pertanyaan yang diajukan oleh para pengembang di kolom komentar dan komunitas. Artikel ini menyusun pertanyaan-pertanyaan yang sering diajukan, meliputi konfigurasi lingkungan, penggunaan node, pembacaan data, panggilan AI, mekanisme pengembalian, dan banyak hal lainnya untuk membantu Anda menemukan solusi dengan cepat.
I. Konfigurasi lingkungan
Q1: Mengapa saya tidak dapat menjalankan strategi workflow di hard disk saya?
Hanya host dengan versi terbaru yang mendukung workflow berjalan. Jika versi host Anda terlalu lama, kebijakan workflow tidak akan dapat dimulai dan perlu diperbarui ke versi terbaru.
Q2: Bahasa pemrograman apa yang didukung oleh alur kerja?
Kode node dari workflow hanya mendukung JavaScript, tidak mendukung Python. Jika Anda terbiasa menulis strategi dengan Python, Anda perlu beralih ke tata bahasa JS. Logika dasar JS dan Python mirip, terutama perbedaan tata bahasa.
2. Mekanisme pengoperasian node
Q3: Apakah node dalam alur kerja dipicu secara bersamaan atau berurutan?
Setiap node harus menunggu node sebelumnya untuk mulai, dan Anda perlu mempertimbangkan ini ketika Anda mengatur mekanisme kebijakan.
Q4: Mengapa setelah Anda mengatur K-line update node, alur kerja menunggu dan tidak dijalankan?
Jika Anda mengatur 1 jam K-line update pemicu, maka alur kerja akan menunggu sampai titik penuh K-line tutup untuk mulai berjalan. Selama menunggu, alur kerja tidak akan melakukan, yang normal. Jika Anda ingin melakukan logika kebijakan yang berbeda selama menunggu, Anda dapat mengatur pemicu kedua untuk melakukan logika kebijakan Anda.
3. Membaca data dan menyimpan variabel
Q5: Bagaimana cara membaca output dari sebuah node?
Penulisan standarnya adalah:
javascript
$node["节点名称"].json
Sintaks ini dapat membaca output JSON dari setiap node. Tetapi ada batasan di sini, hanya dapat membaca data dari node induk yang terhubung secara langsung. Tidak dapat dibaca dengan cara ini jika tidak ada hubungan koneksi langsung antara dua node.
Q6: Bagaimana cara berbagi data antara node yang tidak terhubung secara langsung?
Dapat digunakan_GVariabel global._GMemori FMZ adalah penyimpanan internal global yang disediakan oleh aliran kerja FMZ, yang dapat berbagi data antara setiap node dan setiap aliran.
Cara ini sangat sederhana:
javascript
// 保存数据
_G("变量名", 值)
// 读取数据
_G("变量名")
Namun perlu diperhatikan,_GVariabel akan tetap ada dan tidak akan dihapus bahkan jika hard disk restart. Jika ditemukan kesalahan dalam membaca data lama, pengaturan manual diperlukan_G("变量名",null)Untuk menghapus, atau langsung menghapus hard disk dan membuat ulang.
Q7: Kapan kita perlu menggunakan JSON.stringify?
Dalam menangani data yang kompleks, seringkali diperlukanJSON.stringifyMetode 。 Metode ini dapat mengubah objek dan array yang kompleks menjadi string teks, yang sangat berguna saat mentransfer data ke node AI, karena AI hanya dapat memahami input dalam format teks。
Empat, transmisi data dari node kode
Q8: Apakah node kode harus mengembalikan data?
Ya, ini adalah persyaratan yang sangat penting.returnMengembalikan data agar data tetap ditransmisikan di antara node. Mengembalikan array kosong, bahkan jika logika kode Anda tidak perlu mengekspor data:
javascript
return {}
Jika lupa return, node berikutnya tidak akan menerima data, yang menyebabkan seluruh alur kerja terganggu.
Q9: Bagaimana cara menangani beberapa data yang keluar dari node?
Jika satu node Anda menghasilkan lebih dari satu data, misalnya 10 berita, dan Anda perlu mengintegrasikannya dan tidak mengolahnya secara terpisah, Anda tidak dapat mengirimkannya langsung ke node berikutnya, Anda harus menggunakan penggabungan atau penggabungan, menggabungkan beberapa data ke dalam satu paket.
Manfaat dari cara ini adalah struktur data yang jelas dan mudah untuk diproses oleh node selanjutnya. Misalnya, untuk menyampaikan beberapa berita ke analisis AI, Anda perlu mengelompokkan sebuah array terlebih dahulu, sehingga AI dapat melihat semua informasi sekaligus.
Konfigurasi dan Debugging Node AI
Q10: Apa yang harus diperiksa terlebih dahulu jika ada kesalahan pada node AI?
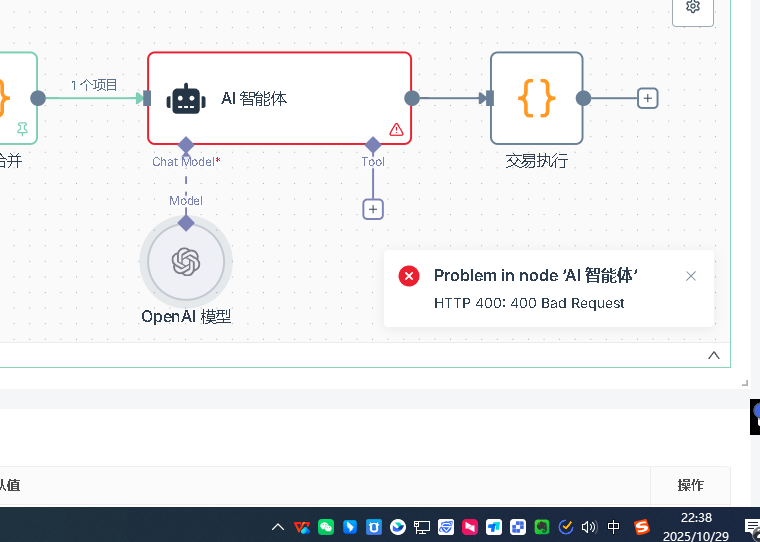
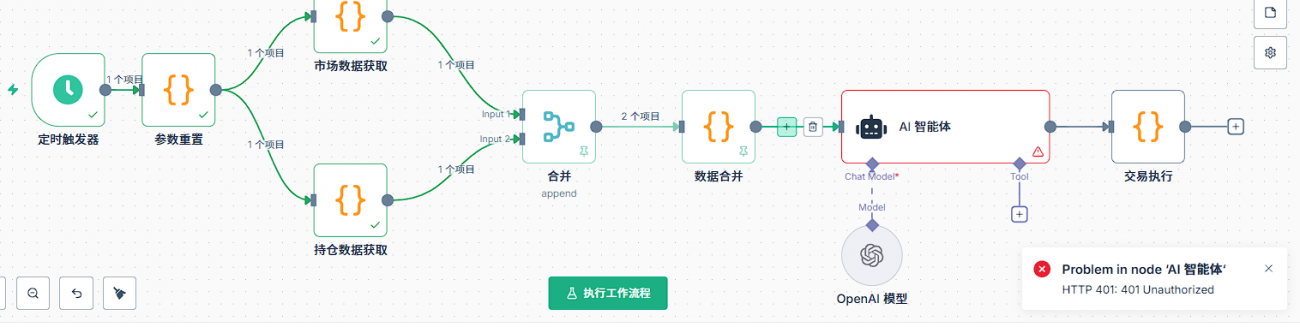
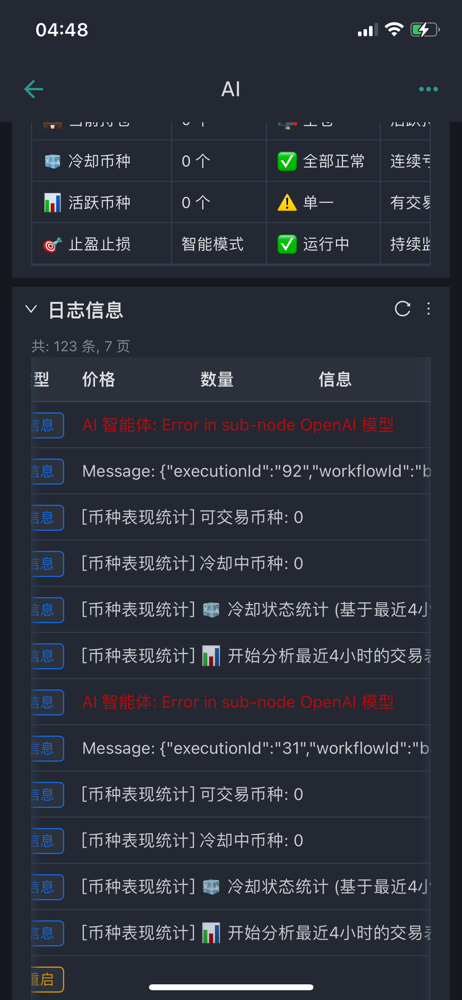
Pertama adalah pengaturan dasar dari node AI. Node AI perlu menambahkan model model, di model harus mengatur kredensial. Pertama membuat kredensial baru, konfigurasi kredensial mencakup dua informasi penting: kunci API dan url dasar. Kunci API adalah kunci yang Anda minta di platform yang sesuai, url dasar adalah alamat permintaan API.
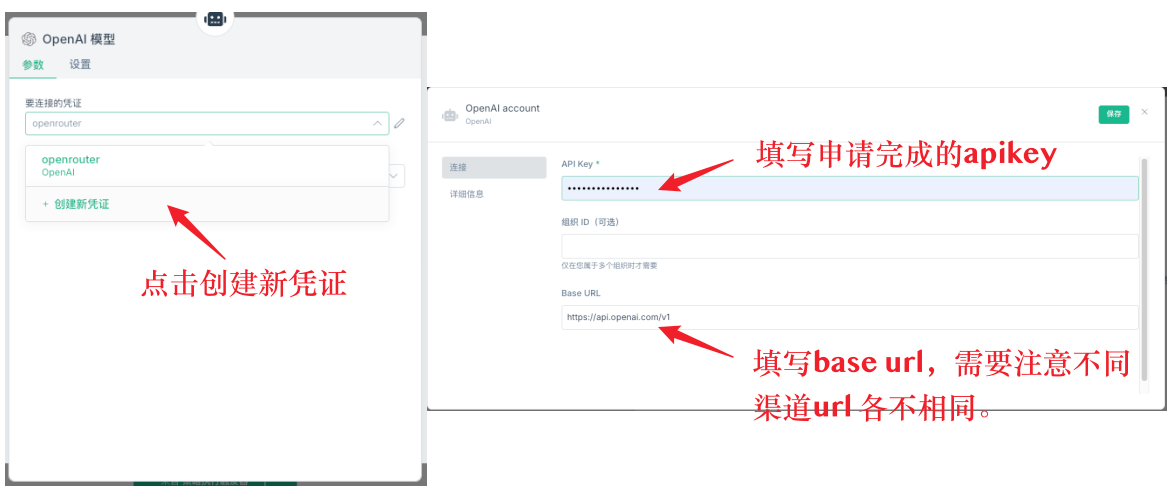
Q11: Layanan API mana yang lebih baik untuk digunakan?
Tidak disarankan untuk menggunakan API langsung dari deepseek, karena responsnya lebih lambat, mudah terlewat, dan kapasitasnya terbatas. Disarankan untuk menggunakan OpenRouter, yang dapat terhubung ke berbagai model besar, stabilitas dan kecepatan lebih baik.
Q12: Apakah ada biaya untuk menggunakan AI?
Ya, panggilan AI mahal dan setiap permintaan akan menghabiskan token. Jika panggilan gagal, periksa apakah saldo akun cukup. Disarankan untuk menggunakan model murah pada tahap pengujian logika strategi dan kemudian beralih ke model yang lebih kuat setelah memastikan logika strategi benar.
Q13: Bagaimana cara menulis instruksi AI yang efektif?
Ini adalah seni yang perlu dioptimalkan sesuai dengan karakteristik model besar yang berbeda. Misalnya, Grok lebih agresif, Claude lebih berhati-hati, dan DeepSeek memiliki kecenderungan alami untuk melakukan lebih banyak karena dilatih dengan data saham A. Memahami karakteristik ini dapat membantu menulis prompt yang lebih efektif.
6. Stabilitas dan kontrol angin model AI
Q14: Apakah model AI stabil dalam pengambilan keputusan?
Model AI belum sepenuhnya stabil. Meskipun AI dapat meningkatkan kualitas keputusan strategi, namun AI sendiri juga dapat membuat kesalahan. Lingkungan pasar yang berbeda, presentasi berita yang berbeda, dan bahkan masukan yang sama dapat menghasilkan output yang berbeda pada waktu yang berbeda. Ketidakpastian ini adalah karakteristik AI.
Q15: Apa yang perlu diperhatikan saat menggunakan strategi AI?
Ketika menggunakan strategi AI, pastikan untuk menambahkan langkah-langkah pengendalian risiko yang ketat. Misalnya: menetapkan batas kerugian maksimum untuk setiap transaksi, menetapkan batas atas posisi total, menambahkan logika stop loss, jangan biarkan AI sepenuhnya mengendalikan dana.
AI harus menjadi alat bantu dalam pengambilan keputusan Anda, bukan menjadi objek yang ditugaskan sepenuhnya. Pemantauan buatan dan pengendalian risiko tidak akan pernah hilang.
7. Keistimewaan dari strategi AI untuk mendeteksi
Q16: Apakah strategi yang melibatkan AI dapat dilacak?
Strategi yang melibatkan AI memiliki spesialisasi yang sangat besar dalam pengetesan ulang, yang harus dipahami dengan baik. Strategi konvensional dapat melakukan pengetesan ulang acak dengan data historis, tetapi strategi AI tidak dapat melakukannya.
Mengapa? Karena setiap kali AI dipanggil akan menghabiskan token, menghasilkan biaya yang sebenarnya. Jika Anda mempertimbangkan data sejarah selama satu tahun, Anda mungkin harus memanggil AI ribuan kali, dan biayanya akan sangat mahal.
Untuk melindungi dompet Anda, FMZ telah merancang sebuah mekanisme: dalam mode pengembalian, node AI hanya akan benar-benar memanggil tiga kali, dan kemudian menggunakan data cache tiga kali tersebut.
Q17: Apakah strategi AI yang menggunakan berita terbaru dapat dilacak?
Jika strategi Anda memanggil informasi berita terbaru, pengembalian tidak masuk akal. Karena Anda menggunakan data K-line masa lalu, tetapi membaca berita saat ini, keduanya tidak cocok sama sekali, pengembalian tidak masuk akal.
Q18: Lalu bagaimana cara menguji strategi AI?
Metode yang disarankan adalah: melakukan pengujian lapangan dengan modal kecil, siklus kecil, mengamati kualitas keputusan AI dan kinerja strategi selama beberapa waktu, mengkonfirmasi stabilitas dan kemudian meningkatkan dana secara bertahap.
Konfigurasi HTTP dan MCP
Q19: Bagaimana jika node HTTP tidak dapat mengakses data?
HTTP node dan MCP node biasanya digunakan untuk mendapatkan data eksternal, tetapi banyak layanan API membutuhkan kunci untuk mengaksesnya. Jika Anda mengkonfigurasi permintaan HTTP tetapi tidak dapat memperoleh data, periksa apakah Anda memerlukan kunci API dan apakah informasi otentikasi dikonfigurasi dengan benar. Beberapa API juga memiliki batasan frekuensi permintaan, dan jika panggilan terlalu sering, aliran akan dibatasi atau bahkan diblokir.
Q20: Bagaimana cara meningkatkan stabilitas akses data eksternal?
MCP node lebih kuat dan dapat terhubung ke berbagai layanan data terstruktur, tetapi konfigurasi juga lebih rumit. Perlu mengatur dengan benar titik akhir layanan, metode otentikasi, parameter permintaan, dll. Disarankan untuk menggunakan node HTTP untuk menguji apakah API dapat diakses dengan benar, mengkonfirmasi format data dan kemudian mengintegrasikannya ke dalam alur kerja.
Selain itu, untuk meningkatkan stabilitas, Anda dapat menambahkan mekanisme retest kegagalan ke node ini. Mulailah retest di pengaturan node, atur jumlah dan interval retest, sehingga masalah jaringan sementara tidak menyebabkan seluruh alur kerja gagal.
9. Masalah kompatibilitas kode
Q21: Apakah FMZ workflow dan kode n8n dapat digunakan bersama?
Inventor workflow dibuat berdasarkan n8n open source framework, tetapi kode keduanya tidak dapat digunakan secara langsung satu sama lain. Jika Anda menemukan kode workflow n8n secara online, menempelkannya langsung ke FMZ tidak akan berfungsi dan perlu diubah sesuai dengan API dan spesifikasi node FMZ. Sebaliknya, kode workflow FMZ juga tidak dapat digunakan secara langsung pada n8n.
Perbedaan utama adalah: FMZ melakukan modifikasi khusus pada beberapa node, parameter dan format output berbeda. Jika Anda memindahkan kode, Anda perlu memeriksa konfigurasi dan panggilan fungsi setiap node dengan cermat untuk memastikan bahwa itu sesuai dengan spesifikasi platform target.
Meringkaskan
Ini adalah jawaban atas pertanyaan umum yang diajukan oleh para penemu dalam mengukur alur kerja. Kami telah membahas berbagai aspek dari konfigurasi lingkungan, mekanisme node, pembacaan data, spesifikasi kode, panggilan AI hingga pengujian umpan balik, yang merupakan masalah yang sering terjadi dalam pertempuran nyata. Dengan pengetahuan ini, Anda akan memiliki lebih sedikit hambatan dalam mengembangkan alur kerja.
Tapi trading kuantitatif adalah proses pembelajaran yang terus menerus, masalah baru akan terus muncul. Jangan putus asa, lihat dulu dokumen resmi FMZ, cari diskusi di komunitas, banyak masalah yang pernah dialami sebelumnya. Jika tidak dapat diselesaikan, Anda dapat mengajukan lamaran kerja di platform dan bertanya kepada insinyur.
Ingatlah bahwa masalah adalah guru terbaik, dan setiap kali Anda memecahkannya, Anda akan lebih memahami alur kerja. Semoga FAQ ini dapat membantu Anda dengan lebih lancar menggunakan strategi pengembangan alur kerja kuantitatif!


- 1