Eksplorasi Awal Menggunakan Python Crawler di FMZ Crawling Binance Konten Pengumuman
Penulis:Ninabadass, Dibuat: 2022-04-08 15:47:43, Diperbarui: 2022-04-13 10:07:13Eksplorasi Awal Menggunakan Python Crawler di FMZ Crawling Binance Konten Pengumuman
Baru-baru ini, saya melihat melalui Forum dan Digest kami, dan tidak ada informasi yang relevan tentang crawler Python. Berdasarkan semangat pengembangan komprehensif FMZ, saya pergi hanya untuk belajar tentang konsep dan pengetahuan crawler. Setelah belajar tentang hal itu, saya menemukan bahwa masih banyak yang harus dipelajari tentang
Permintaan
Untuk pedagang yang suka trading IPO, mereka selalu ingin mendapatkan informasi daftar platform sesegera mungkin. Jelas tidak realistis untuk secara manual menatap situs web platform sepanjang waktu. Kemudian Anda perlu menggunakan skrip crawler untuk memantau halaman pengumuman platform, dan mendeteksi pengumuman baru untuk diberitahu dan diingatkan pada saat pertama kali.
Eksplorasi Awal
Gunakan program yang sangat sederhana sebagai awal (script crawler yang benar-benar kuat jauh lebih kompleks, jadi luangkan waktu Anda). Logika program sangat sederhana, yaitu, biarkan program terus mengunjungi halaman pengumuman platform, menganalisis konten HTML yang diperoleh, dan mendeteksi apakah konten label yang ditentukan diperbarui.
Implementasi Kode
Anda dapat menggunakan beberapa struktur crawler yang berguna. Mengingat bahwa permintaan sangat sederhana, Anda juga dapat menulis langsung.
Perpustakaan Python yang akan digunakan:requests, yang dapat dianggap sebagai perpustakaan yang digunakan untuk mengakses halaman web.bs4, yang dapat dianggap sebagai perpustakaan yang digunakan untuk menganalisis kode HTML halaman web.
Kode:
from bs4 import BeautifulSoup
import requests
urlBinanceAnnouncement = "https://www.binancezh.io/en/support/announcement/c-48?navId=48" # Binance announcement web page address
def openUrl(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
r = requests.get(url, headers=headers) # use "requests" library to access url, namely the Binance announcement web page address
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # if the access succeeds, return the text of the page content
else:
Log("failed {}".format(url))
def main():
preNews_href = ""
lastNews = ""
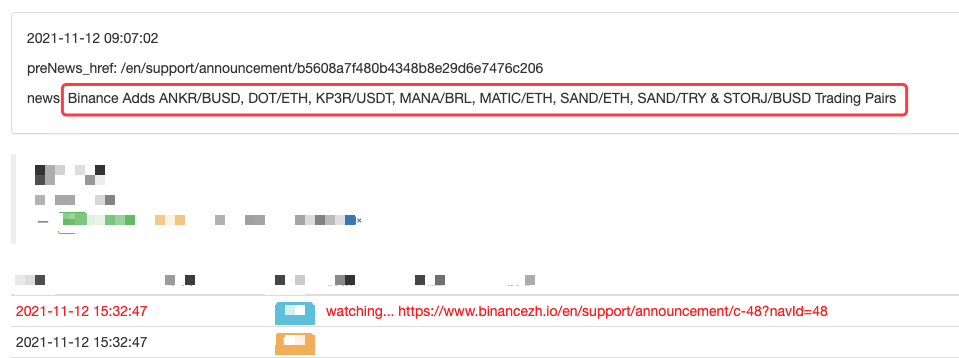
Log("watching...", urlBinanceAnnouncement, "#FF0000")
while True:
ret = openUrl(urlBinanceAnnouncement)
if ret:
soup = BeautifulSoup(ret, 'html.parser') # parse the page text into objects
lastNews_href = soup.find('a', class_='css-1ej4hfo')["href"] # find specified lables, to obtain href
lastNews = soup.find('a', class_='css-1ej4hfo').get_text() # obtain the content in the label
if preNews_href == "":
preNews_href = lastNews_href
if preNews_href != lastNews_href: # the label change detected, namely the new announcement generated
Log("New Cryptocurrency Listing update!") # print the prompt message
preNews_href = lastNews_href
LogStatus(_D(), "\n", "preNews_href:", preNews_href, "\n", "news:", lastNews)
Sleep(1000 * 10)
Operasi
Anda bahkan dapat memperluasnya, seperti mendeteksi pengumuman baru, analisis simbol mata uang baru yang terdaftar, dan pemesanan otomatis perdagangan IPO.
- Menghilangkan pencetakan log
- Batalkan semua pesanan yang belum selesai dalam mata uang saat ini
- Pelancaran Cepat APP Platform Perdagangan Kuantum FMZ
- Membuat Bot Pengendalian Perintah Sederhana dari Cryptocurrency Spot
- FMZ sebagai platform pembayaran
- Kontrak Cryptocurrency Simple Order-Supervising Bot
- Saat menggunakan getdepth untuk mendapatkan timestamp yang sesuai
- Menghilangkan, menyelesaikan
- Masalah nilai muka
- Contoh Desain Strategi dYdX
- Penelitian Desain Strategi Hedge & Contoh Tugas Spot dan Berjangka yang Ditunda
- Situasi terkini dan operasi yang direkomendasikan dari strategi suku bunga pendanaan
- Strategi titik putus rata-rata bergerak ganda untuk berjangka mata uang kripto (Pengajaran)
- Cryptocurrency Spot Multi-Symbol Dual Moving Average Strategy (Pengajaran)
- Realisasi Fisher Indicator dalam JavaScript & Plotting pada FMZ
- Pengelola
- Ulasan TAQ Cryptocurrency 2021 & Strategi Simpel yang Hilang dari Peningkatan 10 Kali
- Cryptocurrency Futures Multi-Symbol ART Strategy (Pengajaran)
- Upgrade! Cryptocurrency Futures Strategi Martingale
- Fungsi Getrecords tidak dapat mengambil K-string diagram dalam satuan detik