
1. Pendahuluan
Artikel sebelumnya memperkenalkan penggunaan jaringan LSTM untuk memprediksi harga Bitcoin https://www.fmz.com/digest-topic/4035. Seperti yang disebutkan dalam artikel, ini hanyalah proyek kecil untuk berlatih dan membiasakan diri dengan RNN dan pytorch. . Artikel ini akan memperkenalkan penggunaan metode pembelajaran penguatan untuk melatih strategi perdagangan secara langsung. Model pembelajaran penguatan adalah PPO yang bersumber terbuka oleh OpenAI, dan lingkungannya didasarkan pada gaya olahraga. Untuk memudahkan pemahaman dan pengujian, model LSTM PPO dan lingkungan gym pengujian ulang ditulis secara langsung tanpa menggunakan paket yang sudah jadi.
PPO, nama lengkap dari Proximal Policy Optimization, merupakan peningkatan pengoptimalan dari Policy Graident, yaitu gradien kebijakan. Gym juga dirilis oleh OpenAI. Ia dapat berinteraksi dengan jaringan kebijakan dan memberikan umpan balik mengenai keadaan terkini dan imbalan lingkungan. Ia seperti latihan pembelajaran penguatan yang menggunakan model LSTM PPO untuk secara langsung melakukan pembelian, penjualan, atau tidak melakukan operasi berdasarkan informasi pasar Bitcoin. Instruksi diberikan oleh lingkungan pengujian ulang, dan model terus dioptimalkan melalui pelatihan untuk mencapai tujuan profitabilitas strategi.
Membaca artikel ini memerlukan dasar tertentu dalam Python, pytorch, dan pembelajaran penguatan mendalam DRL. Namun tidak masalah jika Anda tidak tahu cara melakukannya. Mudah dipelajari dan memulai dengan kode yang diberikan dalam artikel ini. Artikel ini dibuat oleh FMZ, penemu platform perdagangan kuantitatif mata uang digital (www.fmz.com). Selamat bergabung di grup QQ: 863946592 untuk komunikasi.
2. Data dan referensi pembelajaran
Data harga Bitcoin berasal dari platform perdagangan kuantitatif penemu FMZ: https://www.quantinfo.com/Tools/View/4.html
Artikel tentang penggunaan DRL+gym untuk melatih strategi perdagangan: https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4
Beberapa contoh memulai dengan pytorch: https://github.com/yunjey/pytorch-tutorial
Artikel ini akan langsung menggunakan implementasi singkat model LSTM-PPO ini: https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py
Artikel tentang PPO: https://zhuanlan.zhihu.com/p/38185553
Artikel lainnya tentang DRL: https://www.zhihu.com/people/flood-sung/posts
Mengenai gym, artikel ini tidak perlu menginstalnya, tetapi pembelajaran penguatan sangat umum: https://gym.openai.com/
3.LSTM-PPO
Untuk penjelasan lebih mendalam tentang PPO, Anda dapat mempelajari referensi sebelumnya. Berikut ini hanya pengantar konsep sederhananya. Pada edisi sebelumnya, jaringan LSTM hanya memprediksikan harga. Cara transaksi jual beli berdasarkan harga prediksi ini perlu diimplementasikan secara terpisah. Tentu saja, dapat dibayangkan bahwa akan lebih langsung untuk mengeluarkan tindakan beli dan jual secara langsung. , Kanan? Kebijakan Graident seperti ini. Kebijakan ini dapat memberikan kemungkinan berbagai tindakan berdasarkan informasi lingkungan yang dimasukkan. Kerugian LSTM adalah selisih antara harga prediksi dengan harga aktual, sedangkan kerugian PG adalah -log(p)*Q, di mana p adalah probabilitas suatu tindakan akan dikeluarkan, dan Q adalah nilai tindakan (seperti skor hadiah). Penjelasan intuitifnya adalah jika nilai suatu tindakan lebih tinggi, jaringan akan mengeluarkan probabilitas yang lebih tinggi. untuk mengurangi kerugian. Meskipun PPO jauh lebih rumit, prinsipnya serupa. Kuncinya terletak pada cara mengevaluasi nilai setiap tindakan dengan lebih baik dan cara memperbarui parameter dengan lebih baik.
Kode sumber LSTM-PPO diberikan di bawah ini, yang dapat dipahami dalam kombinasi dengan informasi sebelumnya:
python
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
#模型的超参数
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # 也可以改为GPU版本
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
#输出各个动作的概率,由于是LSTM网络还要包含hidden层的信息,可以参考上一期文章
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
#价值函数,用于评价当前局面的好坏,所以只有一个输出
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
#准备训练数据
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) #同时训练了价值网络和决策网络
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. Lingkungan pengujian ulang Bitcoin
Mengikuti format gym, ada metode inisialisasi reset, tindakan input langkah, dan hasil yang dikembalikan adalah (status berikutnya, manfaat tindakan, apakah sudah selesai, informasi tambahan). Seluruh lingkungan backtest hanya 60 baris, yang dapat dimodifikasi sendiri. Versi kompleks, kode spesifik:
python
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks #初始的比特币数量
self.initial_balance = initial_balance #初始的资产
self.current_time = 0 #回测的时间位置
self.commission = commission #易手续费
self.done = False #回测是否结束
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) #标准化方法,简单的收益率标准化
self.mode = all_data # 是否为抽样回测模式
self.sample_length = 500 # 抽样长度
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
#action即策略采取的动作,这里将更新账户和计算reward
done = False
if action == 0: #持有
pass
elif action == 1: #买入
buy_value = self.balance*0.5
if buy_value > 1: #余钱不足,不操作账户
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: #卖出
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # 每回合的reward是新增收益
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. Beberapa detail penting
Mengapa akun awal memiliki koin?
Rumus untuk menghitung laba dalam lingkungan pengujian ulang adalah: Laba Saat Ini = Nilai Akun Saat Ini - Nilai Akun Saat Ini Awal. Artinya, jika harga Bitcoin turun dan strategi tersebut menjual koin, strategi tersebut seharusnya tetap dihargai meskipun nilai total akun menurun. Kalau periode pengujian ulang panjang, akun awal mungkin tidak terlalu terpengaruh, tetapi tetap akan berdampak besar di awal. Perhitungan keuntungan relatif memastikan bahwa setiap operasi yang benar akan memperoleh imbalan positif.
Mengapa kami mengambil sampel pasar selama pelatihan?
Jumlah total data lebih dari 10.000 K-lines. Jika siklus penuh dijalankan setiap waktu, akan memakan waktu lama, dan strategi akan menghadapi situasi yang sama persis setiap waktu, yang dapat menyebabkan overfitting. 500 batang digambar setiap kali sebagai data uji ulang. Meskipun overfitting masih mungkin terjadi, strategi ini menghadapi lebih dari 10.000 kemungkinan awal yang berbeda.
Apa yang harus dilakukan jika Anda tidak memiliki koin atau uang?
Situasi ini tidak dipertimbangkan dalam lingkungan backtest. Jika koin telah terjual habis atau volume transaksi minimum tidak tercapai, menjalankan operasi penjualan saat ini sebenarnya setara dengan tidak menjalankan operasi apa pun. Jika harga turun, menurut relatif metode perhitungan pengembalian masih berdasarkan pada imbalan positif dari strategi tersebut. Dampak dari situasi ini adalah ketika strategi menentukan bahwa pasar sedang jatuh dan koin yang tersisa di akun tidak dapat dijual, tidak mungkin untuk membedakan antara tindakan penjualan dan tidak ada operasi, tetapi tidak berdampak pada penilaian strategi itu sendiri. pasar.
Mengapa mengembalikan informasi akun sebagai status?
Model PPO memiliki jaringan nilai yang digunakan untuk mengevaluasi nilai kondisi terkini. Jelas, jika strategi menentukan bahwa harga akan naik, seluruh kondisi hanya akan memiliki nilai positif jika akun berjalan memiliki Bitcoin, dan sebaliknya. Oleh karena itu, informasi akun merupakan dasar penting untuk menilai jaringan nilai. Perhatikan bahwa informasi tindakan masa lalu tidak dikembalikan sebagai status, yang menurut saya pribadi tidak berguna untuk menilai nilai.
Dalam keadaan apa tidak akan ada operasi lagi?
Bila strategi menentukan bahwa laba dari pembelian dan penjualan tidak dapat menutupi biaya transaksi, strategi tersebut harus kembali tidak mengambil tindakan apa pun. Meskipun uraian sebelumnya berulang kali menggunakan strategi untuk menentukan tren harga, hal itu hanya demi kemudahan pemahaman. Faktanya, model PPO ini tidak membuat prediksi apa pun tentang pasar, tetapi hanya menghasilkan probabilitas dari tiga tindakan.
6. Akuisisi data dan pelatihan
Seperti pada artikel sebelumnya, data diperoleh dalam format berikut: garis K satu jam dari pasangan perdagangan BTC_USD di bursa Bitfinex dari 2018/5/7 hingga 2019/6/27:
python
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
Karena jaringan LSTM digunakan, waktu pelatihannya sangat lama, jadi saya beralih ke versi GPU, yang sekitar 3 kali lebih cepat.
python
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 #记录总收益
profit_list = [] #记录每次训练收益
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. Hasil dan analisis pelatihan
Setelah penantian yang lama:

Pertama, mari kita lihat tren pasar dari data pelatihan. Secara umum, paruh pertama merupakan penurunan yang panjang, dan paruh kedua merupakan pemulihan yang kuat.
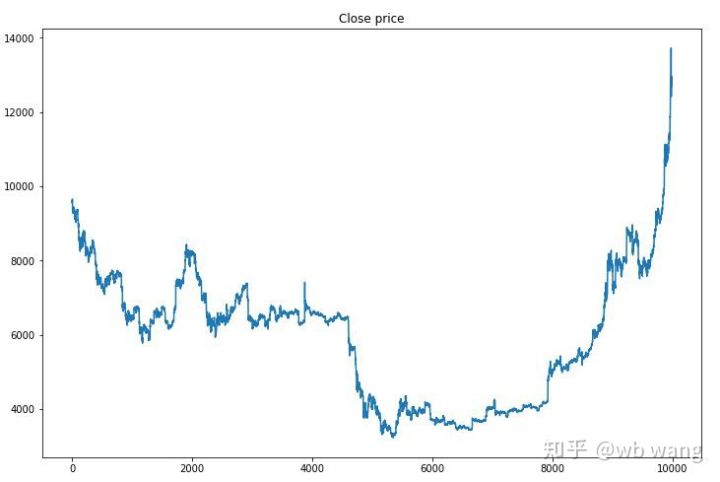
Ada banyak operasi pembelian di tahap awal pelatihan, dan pada dasarnya tidak ada putaran yang menguntungkan. Pada pertengahan periode pelatihan, jumlah operasi pembelian berangsur-angsur menurun dan kemungkinan memperoleh keuntungan makin besar, tetapi kemungkinan mengalami kerugian masih tinggi.
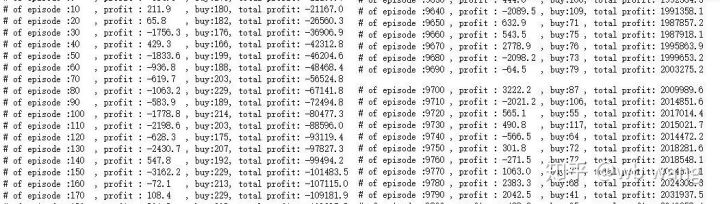
Dengan menghaluskan pendapatan per putaran, hasilnya adalah sebagai berikut:
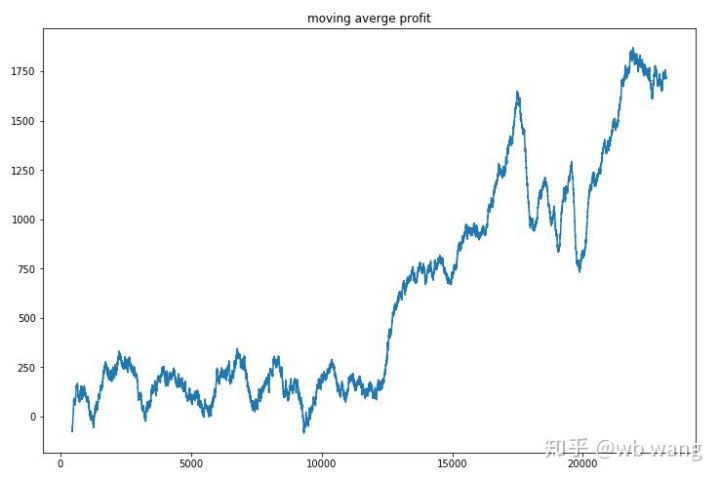
Strategi ini dengan cepat menghilangkan hasil negatif pada tahap awal, tetapi fluktuasinya besar. Hasil baru mulai tumbuh dengan cepat setelah 10.000 putaran. Secara umum, pelatihan model sulit.
Setelah pelatihan akhir selesai, biarkan model menjalankan semua data lagi untuk melihat bagaimana kinerjanya. Selama periode ini, catat total nilai pasar akun, jumlah bitcoin yang dimiliki, proporsi nilai bitcoin, dan total pendapatan. .
Pertama adalah total nilai pasar. Total pendapatannya mirip, jadi saya tidak akan mempostingnya di sini:
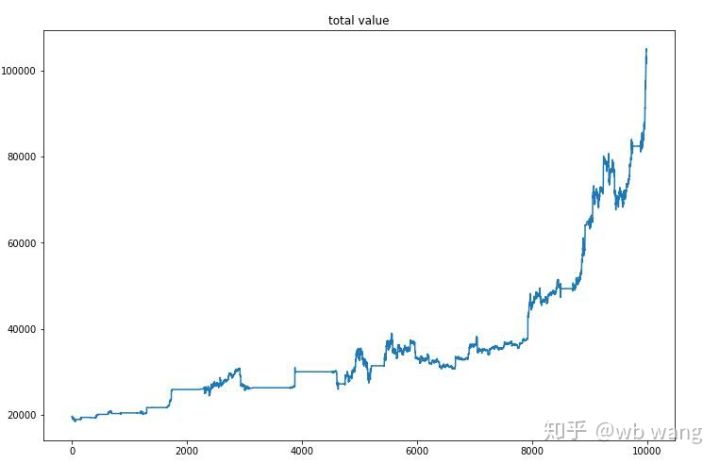
Nilai pasar total meningkat perlahan selama pasar melemah di awal dan juga meningkat seiring dengan kenaikan selama pasar menguat berikutnya, tetapi masih ada kerugian berkala.
Terakhir, mari kita lihat proporsi posisi. Sumbu kiri grafik adalah proporsi posisi, dan sumbu kanan adalah situasi pasar. Dapat ditentukan terlebih dahulu bahwa model telah mengalami overfitting. Frekuensi posisi adalah rendah pada awal pasar melemah, dan frekuensi posisi sangat tinggi pada bagian bawah pasar. Kita juga dapat melihat bahwa model tersebut belum belajar untuk menahan posisi dalam waktu lama dan selalu menjual dengan cepat.
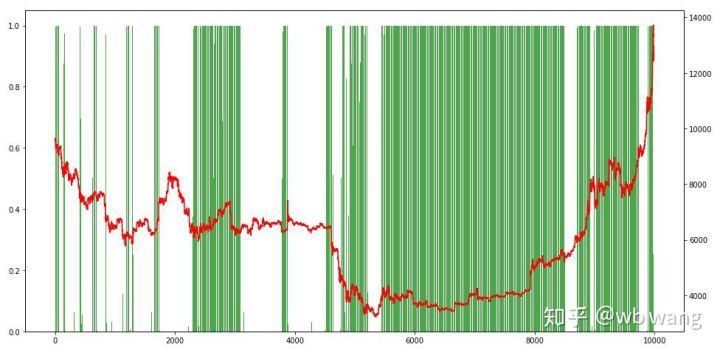
8. Analisis data uji
Data uji diperoleh dari pasar Bitcoin satu jam dari 2019/6/27 hingga saat ini. Seperti yang terlihat pada gambar, harganya telah turun dari $13.000 pada awalnya menjadi lebih dari $9.000 saat ini, yang merupakan pengujian hebat bagi model tersebut.
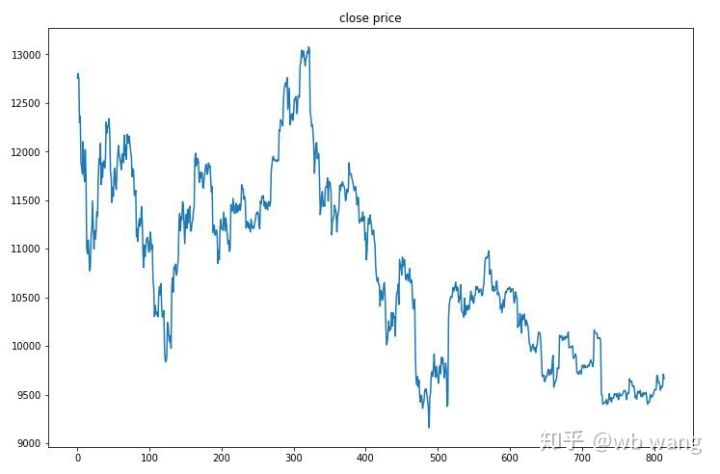
Pertama-tama, hasil relatif akhir tidak memuaskan, tetapi tidak ada kerugian juga.
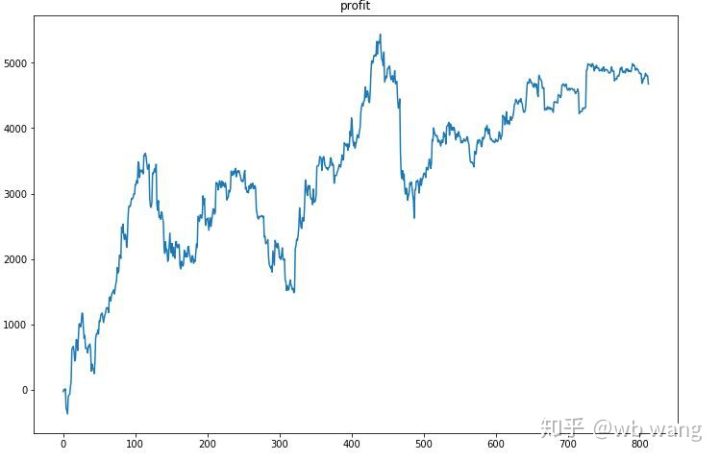
Melihat posisi tersebut, kita dapat menebak bahwa model tersebut cenderung membeli setelah penurunan tajam dan menjual setelah rebound. Pasar Bitcoin hanya berfluktuasi sangat sedikit akhir-akhir ini, dan model tersebut berada dalam posisi short.
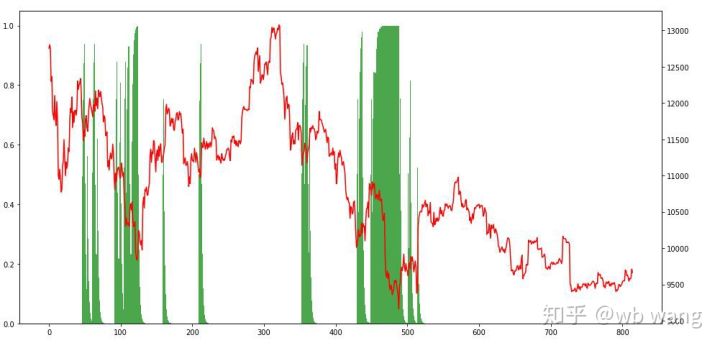
9. Ringkasan
Artikel ini menggunakan metode pembelajaran penguatan mendalam PPO untuk melatih robot perdagangan otomatis Bitcoin dan memperoleh beberapa kesimpulan. Karena keterbatasan waktu, masih ada beberapa hal yang dapat ditingkatkan dalam model ini. Semua orang dipersilakan untuk berdiskusi. Pelajaran terbesarnya adalah bahwa standarisasi data adalah metode yang tepat. Jangan gunakan metode seperti penskalaan, jika tidak, model akan cepat mengingat hubungan antara harga dan kondisi pasar dan jatuh ke dalam overfitting. Setelah normalisasi, laju perubahan menjadi data relatif, yang membuat model sulit mengingat hubungannya dengan pasar dan memaksanya menemukan hubungan antara laju perubahan dan naik turun.
Artikel sebelumnya:
Beberapa strategi publik yang dibagikan di Platform Kuantitatif FMZ Inventor: https://zhuanlan.zhihu.com/p/64961672
Kursus perdagangan kuantitatif mata uang digital NetEase Cloud Classroom, hanya 20 yuan: https://study.163.com/course/courseMain.htm?courseId=1006074239&share=2&shareId=400000000602076
Saya telah mempublikasikan strategi frekuensi tinggi yang dulunya sangat menguntungkan: https://www.fmz.com/bbs-topic/1211


profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.current_time,4]) 有bug
应该是:profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.start,4])
profit = self.value - (self.initial_balance+self.initial_stocksself.df.iloc[self.current_time,4]) 有bug
应该是:profit = self.value - (self.initial_balance+self.initial_stocksself.df.iloc[self.start,4])




GPU版
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class PPO(nn.Module):
def __init__(self):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(8,64)
self.lstm = nn.LSTM(64,32)
self.fc_pi = nn.Linear(32,3)
self.fc_v = nn.Linear(32,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 64)
x, lstm_hidden = self.lstm(x, hidden )
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 64)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float).to(device), torch.tensor(a_lst).to(device).to(device), \
torch.tensor(r_lst).to(device), torch.tensor(s_prime_lst, dtype=torch.float).to(device), \
torch.tensor(done_lst, dtype=torch.float).to(device), torch.tensor(prob_a_lst).to(device)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.to(device).detach(), h2.to(device).detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.cpu().detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float).to(device)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach())
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
- 1