
Inventorの量化ワークフローを使用する過程で,多くの開発者がコメント欄やコミュニティで多くの疑問を提起しました. この記事は,環境構成,ノード使用,データ読み取り,AI呼び出し,反省メカニズムなどのあらゆる側面をカバーして,これらの高頻度の問題を整理し,迅速な解決策を見つけるのを助けます.
A. 環境配置問題
Q1:なぜ私のリッスンディスクは ワークフロー戦略を実行できないのですか?
最新のバージョンのホストのみが,実行ワークフローをサポートします. あなたのホストのバージョンが古い場合,ワークフローポリシーが起動できません. 最新のバージョンにタイムリーに更新する必要があります.
Q2: ワークフローはどのプログラミング言語をサポートしていますか?
ワークフローのコードノードはJavaScriptのみをサポートし,Pythonはサポートしない.Pythonで書き慣れている場合は,JSの文法に変換する必要があります.JSとPythonの基本的な論理は,主に文法上の違いが共通です.
2 ノードの仕組み
Q3: ワークフローのノードは同時に起動するか,順番に実行されるか?
ワークフローのノードは厳格に連続し,一つ一つに触発され,並行して実行されません.各ノードは,前のノードの実行が完了した後で開始されるのを待つ必要があります.この特性は,ポリシーメカニズムを設定するときに考慮する必要があります.
Q4:Kライン更新ノードが設定された後,なぜワークフローが実行されないまま待機しているのですか?
1時間Kライン更新トリガーを設定すると,ワークフローはKラインのクローズアップの整数点まで待って実行される.待機中にワークフローが実行されないのは正常である.待機中に異なる戦略ロジックを実行したい場合は,第二のトリガーを設定してあなたの戦略ロジックを実行することができます.
3 データの読み取りと変数の保存
Q5:ノードの出力データを読み取るにはどうすればよいですか?
標準的な綴りは:
javascript
$node["节点名称"].json
この文法では任意のノードのJSON出力を読み取ることができます。しかし,ここに制限があります.直接接続された親ノードのデータのみを読み取ることができます。二つのノードの間には直接の接続関係がない場合は,この方法で読み取ることはできません。
Q6: 直接接続されていないノード間のデータ共有はどのように行われますか?
使用可能_Gグローバル変数_GFMZ ワークフローが提供する全局的な内存であり,あらゆるノード,あらゆるフロー間でデータを共有することができる.
簡単な方法があります
javascript
// 保存数据
_G("变量名", 值)
// 读取数据
_G("变量名")
しかし,特に注意してください._Gこの変数は,リッドディスクの再起動しても削除されないまま存在します.古いデータが誤って読み込まれていることが判明した場合は,手動で設定する必要があります._G("变量名",null)削除する,または直接削除し,ディスクを再作成する.
Q7: JSON.stringify はいつ使用されるのでしょうか?
複雑なデータを処理する際にはJSON.stringify方法。この方法は,複雑なオブジェクトと配列をテキスト文字列に変換できます.これは,AIノードにデータを転送する際に特に有用です.なぜならAIはテキスト形式の入力のみを理解できるからです。
4 コードノードのデータ伝送
Q8:コードノードがデータを返さなければならないか?
コードの末尾に,コードの末尾にreturnデータを返して,ノード間でのデータを保持する.あなたのコードロジックは,データを出力する必要がなくても,空の配列を返します.
javascript
return {}
return を忘れる場合,後続のノードはデータを受信できず,全体のワークフローが中断されます.
Q9: ノードからの複数の出力を処理するにはどうすればよいですか?
もし,あなたのあるノードが複数のデータを出力している場合,例えば,10つのニュースを取得している場合,そして,あなたが個々の処理ではなく,統合処理を必要としている場合,その時は,直接次のノードに転送することはできません.結合ノードまたは集積ノードを使用して,複数のデータを一つのデータパケットに統合する必要があります.
データの構造が明確で,後続のノード処理が便利である.例えば,複数のニュースをAI分析に転送するには,最初にアレイを集約する必要があり,AIは一度にすべての情報を参照できます.
5 AIノードの構成とデビュー
Q10:AIノードでエラーが発生した場合は,まず何を見直すべきですか?
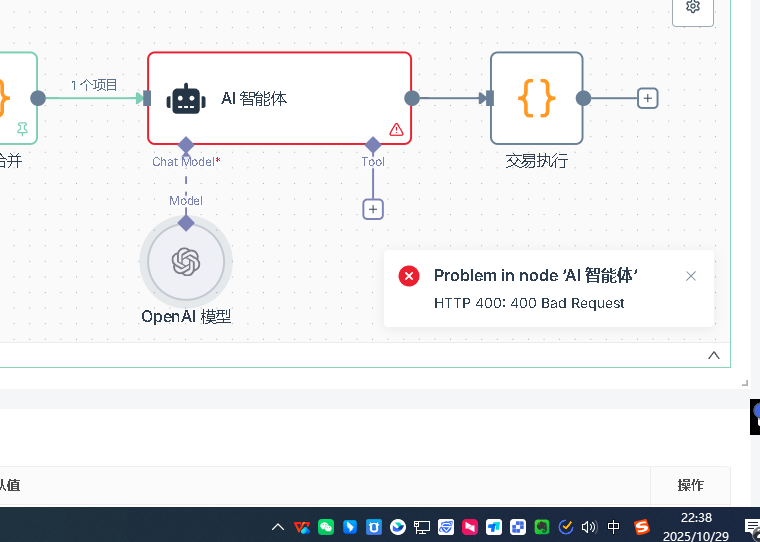
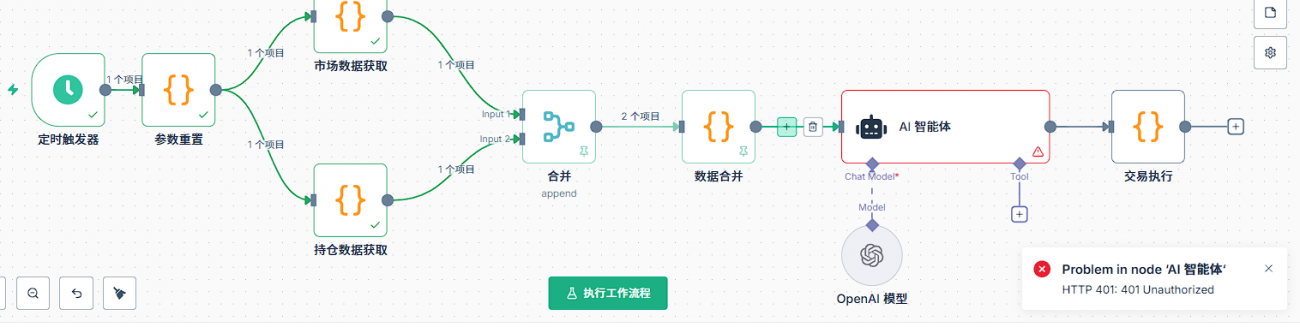
まず,AIノードの基本設定である。AIノードはモデルモデルを追加し,モデルに証明書を設定する必要があります。まず,新しい証明書を作成し,証明書の構成には2つの重要な情報が含まれます:API keyとbase url。API keyは,対応するプラットフォームであなたが申請した鍵であり,base urlはAPIのリクエストアドレスである。特に,異なるチャネルのbase urlは異なるので,例えばOpenRouter,DeepSeek,または他の代理サービスでは,それらのbase urlは必ず異なるので,記入する必要があります。
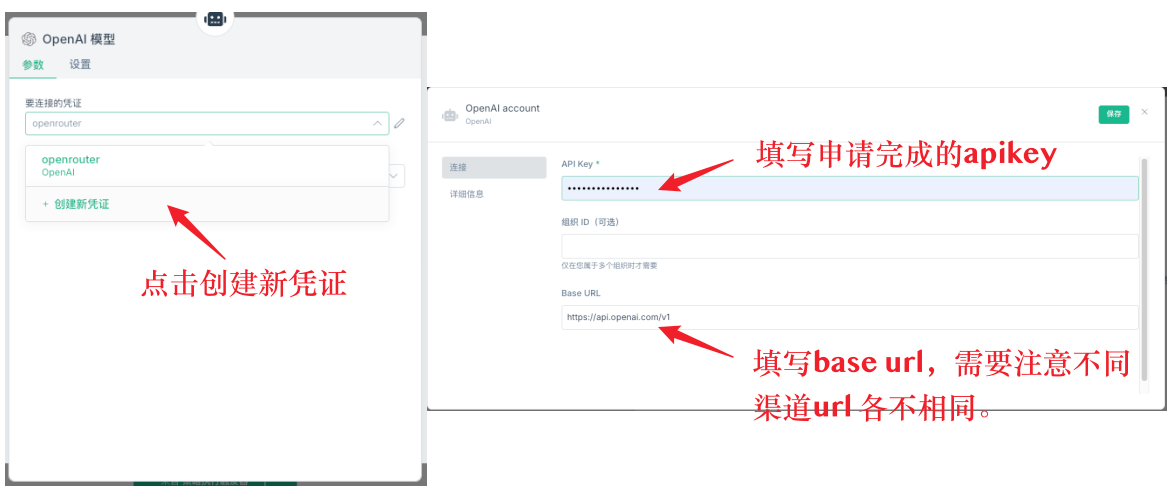
Q11: どのAPIを使うのが良いですか?
deepseekの直線APIを使用することは推奨されません. 応答が遅いため超時になりやすく,額が制限されています. OpenRouterを使用することをお勧めします.
Q12:AIの呼び出しには費用がかかりますか?
はい,AI呼び出しは費用がかかり,各リクエストでトークンが消費されます. 呼び出しが失敗した場合,アカウントの余剰が充足しているかどうかを確認してください. 戦略ロジックテストの段階で安いモデルを使用し,戦略ロジックが正しいことを確認した後,より強力なモデルに変更することをお勧めします.
Q13: 効果的なAI指令文 ((prompt) を書くにはどうすればよいですか?
これは,異なる大きなモデルの特性に応じて最適化する必要がある芸術である.例えば,Grokはより激進的であり,Claudeはより慎重であり,DeepSeekはA股データで訓練されたため,自然に多作業する傾向がある.これらの特性を理解することで,より効果的なプロンプトを書き出すことができる.
6 AIモデル安定性と風力制御
Q14:AIモデルは安定しているのでしょうか?
AIモデルは,まだ完全に安定していない.AIは,戦略の意思決定の質を向上させることができるが,それ自体が誤判を起こす可能性もある.異なる市場環境,異なる報道表現,同じインプットは,異なる時に異なる出力を得ることができる.この不確実性は,AIの固有の特性である.
Q15:AIの戦略では注意すべきことは何ですか?
AI戦略を使用する際には,厳格なリスク管理措置を加える必要があります.例えば,単一取引の最大損失額を設定し,総ポジションの上限を設定し,ストップ・ストップ・ロジックを追加し,AIに資金を完全にコントロールさせないようにしてください.
人工知能は,あなたの意思決定の補助ツールであり,支配権の委託の対象ではありません. 人工知能の監視とリスク管理は,常に必要不可欠です. 人工知能の技術が進歩するにつれて,モデルはますます安定するでしょうが,現段階では慎重に選択することは賢明です.
7 AI戦略の特異性
Q16:AIを活用した戦略は,正常な追跡が可能ですか?
AIを含む策略は,反測の上で非常に特殊であり,この点を理解しなければならない.通常の策略は,歴史的データで随意に反測することができるが,AI策略はできない.
なぜ? なぜなら,AIを呼び出すたびにトークンが消費され,実際の費用が発生するからです.
FMZは,皆さんの財布を守るため,このメカニズムを設計しました:反測モードでは,AIノードは3回しか実際の呼び出しを行わず,この3回のキャッシュデータを使用します.したがって,反測結果は参照にすぎず,真のAI意思決定の質を代表することはできません.
Q17:最新のニュースを利用したAI戦略は 追跡できるのでしょうか?
もし,あなたの戦略が最新のニュース情報を呼び出した場合,反省はさらに不合理になります. なぜなら,あなたは過去のK線データを使っているのに,現在のニュースを読んでいるからです.
Q18:AI戦略をテストするにはどうすればよいですか?
推奨される方法は,小さな資金で,小さな周期で実地テストを行い,AIの意思決定の質と戦略のパフォーマンスをしばらく観察し,安定した後に徐々に資金を増やすことです.AI戦略にとって,実地検証は,歴史の追溯よりもはるかに重要です.
8 HTTPとMCPのノードの配置
Q19:HTTPのノードがデータを取得できない場合はどうしますか?
HTTP ノードとMCP ノードは,通常,外部データを取得するために使用されますが,多くのAPI サービスは,アクセスするためにキーが必要です. HTTP 要求を設定したのに,データを取得できない場合は,API キーが必要かどうかを確認し,認証情報が正しく設定されているかどうかを確認してください.
Q20:外部データ取得の安定性を高めるにはどうすればいいですか?
MCPノードはより強力で,さまざまな構造化データサービスに接続できますが,設定もより複雑です.サービスの端点,認証方法,要求パラメータなどを正しく設定する必要があります.まず,HTTPノードを使用してAPIが正常にアクセスできるかテストし,データフォーマットを確認した後,ワークフローに統合することをお勧めします.
また,安定性を高めるために,これらのノードに失敗再試行機構を追加できます.ノード設定で再試行を開始し,再試行回数と間隔時間を設定します.そうすると,一時的なネットワークの問題が全体のワークフローを失敗に導かないでしょう.
9 コードの互換性について
Q21:FMZのワークフローとn8nのコードは互換性があるのでしょうか?
発明者ワークフローは,n8nのオープンソース・フレームワークをベースに量化カスタマイズされているが,両者のコードは,直接互いを複製して使用できない.もしあなたがネット上でn8nのワークフローのコードを見つけ,直接FMZにペーストすると,動作しないので,FMZのAPIとノード仕様に従って変更する必要がある.逆に,FMZのワークフローのコードは,n8nにも直接使用できない.
主な違いは,FMZが特定のノードにカスタマイズされた改造を行い,パラメータと出力フォーマットが異なることです.コードを移行する場合は,各ノードの配置と関数呼び出しを注意深く調べ,ターゲットプラットフォームの仕様に適合することを確認する必要があります.
要約する
これは,発明者によるワークフローの量化に関するよくある質問の答えです. 環境構成,ノードメカニズム,データ読み取り,コード規範,AIの呼び出しから,フィードバックテストまでの様々な側面をカバーしています.
しかし,量子取引は学習の過程であり,新しい問題が生じ続けます. 問題が発生した場合,落ち込まないように,FMZの公式文書を閲覧し,コミュニティ内の議論を検索してください.多くの問題は,以前にも発生しています.
覚えておいてください:問題は最高の教師です. 解決する問題ごとに, ワークフローの理解が深まります. このFAQが,ワークフロー開発の量化戦略を よりうまく活用できるように役立つことを願っています!


- 1