

この投稿は、Inventor Quant プラットフォームでのデータ調査中に、機械学習技術を取引の問題に適用しようとしたときによく見られる警告や落とし穴を観察したことから着想を得ました。
前回の記事をまだ読んでいない場合は、この記事の前に、Inventor Quantitative Platform 上に構築された自動データ調査環境と取引戦略を開発するための体系的なアプローチに関する前回のガイドを読むことをお勧めします。
アドレスは次のとおりです: https://www.fmz.com/digest-topic/4187 および https://www.fmz.com/digest-topic/4169。
研究環境の整備について
このチュートリアルは、あらゆるスキル レベルの愛好家、エンジニア、データ サイエンティスト向けに設計されています。業界の専門家でもプログラミング初心者でも、必要なスキルは Python プログラミング言語の基本的な理解と、コマンド ライン操作に関する十分な知識だけです。 (データサイエンスプロジェクトを立ち上げることができれば十分です)
- Inventor Quant Hoster をインストールし、Anaconda をセットアップする
Inventor Quantitative Platform FMZ.COM は、主要な主流取引所からの高品質なデータ ソースを提供するだけでなく、データ分析の完了後に自動トランザクションを実行するのに役立つ豊富な API インターフェイスも提供します。このインターフェースセットには、アカウント情報の照会、高値、始値、安値、終値、取引量、さまざまな主流の取引所で一般的に使用されるさまざまなテクニカル分析指標の照会など、特に実際の主要な主流の取引所に接続するための実用的なツールが含まれています。取引プロセス。パブリック API インターフェースは強力な技術サポートを提供します。
上記の機能はすべて、Docker に似たシステムにカプセル化されています。必要なのは、独自のクラウド コンピューティング サービスを購入またはレンタルし、Docker システムを展開することだけです。
Inventor Quantitative Platform の正式名称では、この Docker システムはホスト システムと呼ばれます。
ホストとロボットの展開方法の詳細については、以前の記事を参照してください: https://www.fmz.com/bbs-topic/4140
独自のクラウド コンピューティング サーバー展開ホストを購入したい読者は、この記事を参照してください: https://www.fmz.com/bbs-topic/2848
クラウドコンピューティングサービスとホストシステムを正常に展開したら、最も強力なPythonツールであるAnacondaをインストールします。
この記事で必要なすべての関連プログラム環境 (依存ライブラリ、バージョン管理など) を実現するには、Anaconda を使用するのが最も簡単な方法です。これは、パッケージ化された Python データ サイエンス エコシステムおよび依存関係マネージャーです。
クラウド サービスに Anaconda をインストールするため、クラウド サーバーに Linux システムと Anaconda のコマンド ライン バージョンをインストールすることをお勧めします。
Anacondaのインストール方法については、Anacondaの公式ガイドを参照してください:https://www.anaconda.com/distribution/
経験豊富な Python プログラマーであり、Anaconda を使用する必要性を感じていない場合でも、まったく問題ありません。必要な依存関係のインストールについてはサポートは必要ないと想定し、このセクションをスキップできます。
取引戦略を立てる
取引戦略の最終的な出力は、次の質問に答える必要があります。
-
指示: 資産が安価か、高価か、または適正に評価されているかを判断します。
-
開始条件: 資産価格が安いか高い場合は、ロングまたはショートする必要があります。
-
取引をクローズする: 資産価格が適正であり、その資産にポジションがある場合 (以前の購入または売却)、そのポジションをクローズする必要がありますか?
-
価格帯: 取引が開始される価格(または範囲)
-
数量: 取引された資金の量(例:デジタル通貨の量、商品先物のロット数)
機械学習はこれらの各質問に答えるために使用できますが、この記事の残りの部分では、取引の方向に関する最初の質問に答えることに焦点を当てます。
戦略的アプローチ
戦略を構築するアプローチには 2 種類あり、1 つはモデルベース、もう 1 つはデータ マイニング ベースです。これら 2 つは基本的に反対のアプローチです。
モデルベースの戦略構築では、市場の非効率性のモデルから始めて、数式(価格、収益など)を構築し、より長い期間にわたってその有効性をテストします。モデルは通常、実際の複雑なモデルの簡略化されたバージョンであり、その重要性と長期にわたる安定性を検証する必要があります。通常のトレンドフォロー、平均回帰、裁定取引戦略はこのカテゴリに分類されます。
一方、私たちはまず価格パターンを探し、データマイニング手法のアルゴリズムを使用しようとします。これらのパターンの原因が何であるかは重要ではありません。パターンが将来も繰り返されることだけが確実だからです。これはブラインド分析方法であり、ランダムなパターンから実際のパターンを識別するには厳密な検査が必要です。 「試行錯誤」、「棒グラフパターン」、「特徴量回帰」などがこのカテゴリに属します。
明らかに、機械学習はデータマイニング手法に簡単に適応できます。機械学習を使用してデータマイニングを通じて取引シグナルを作成する方法を見てみましょう。
コード例では、Inventor Quantitative Platform に基づくバックテスト ツールと自動取引 API インターフェイスを使用します。上記のセクションでホストをデプロイし、Anaconda をインストールした後は、必要なデータ サイエンス分析ライブラリと有名な機械学習モデル scikit-learn をインストールするだけです。この部分の詳細については説明しません。
pip install -U scikit-learn
機械学習を使用して取引戦略シグナルを作成する
- データマイニング
始める前に、標準的な機械学習の問題は次のようになります。
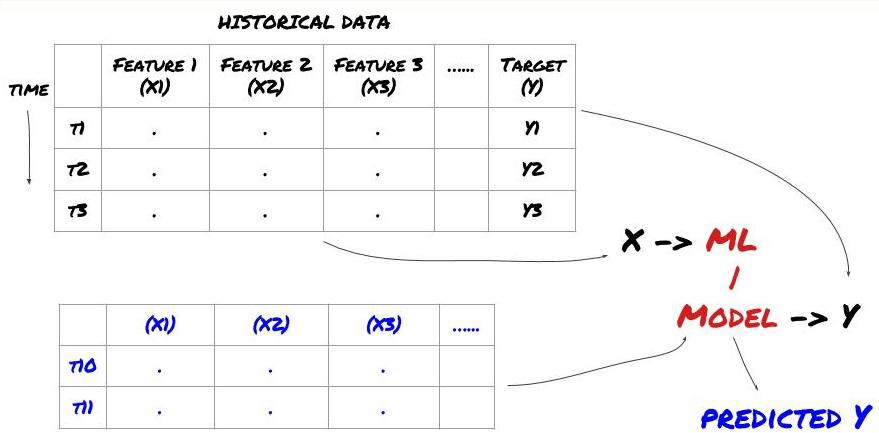
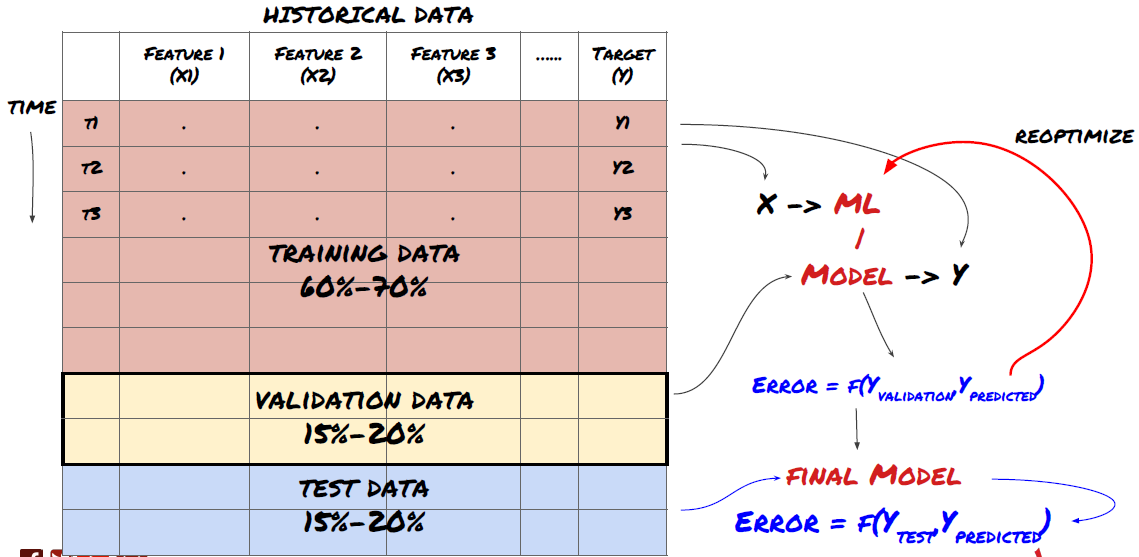
機械学習の問題フレームワーク
作成する機能には、ある程度の予測力 (X) が必要です。ターゲット変数 (Y) を予測し、履歴データを使用して、Y を実際の値にできるだけ近い値で予測できる ML モデルをトレーニングします。最後に、このモデルを使用して、Y が不明な新しいデータに対して予測を行います。これが最初のステップにつながります:
ステップ1: 問題を設定する
- 何を予測したいですか?良い予測とは何でしょうか?予測結果をどのように評価しますか?
つまり、上記のフレームワークでは、Y とは何でしょうか?
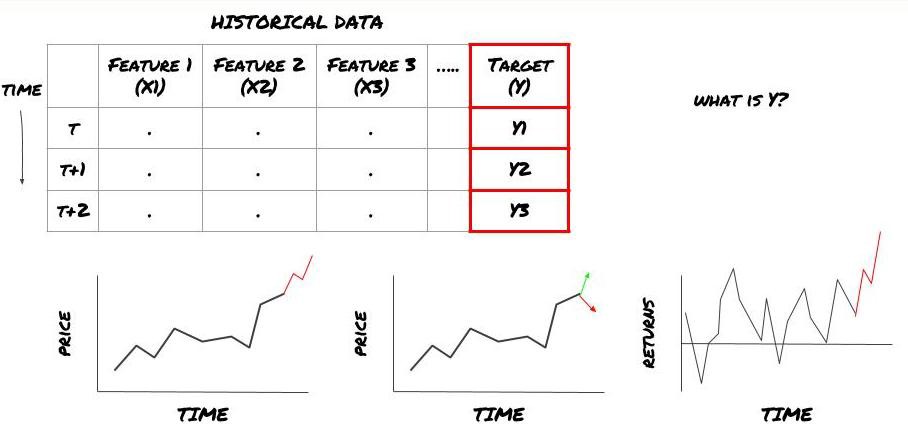
何を予測したいですか?
将来の価格、将来の収益/損益、売買シグナルを予測し、ポートフォリオの配分を最適化し、取引を効率的に実行したいなどお考えですか?
次のタイムスタンプでの価格を予測しようとしているとします。この場合、Y(t) = Price(t+1)となります。これで、過去のデータを使ってフレームワークを完成させることができます
Y(t) はバックテストでのみ分かっていますが、モデルを使用する場合、時刻 t (t+1) の価格は分からないことに注意してください。モデルを使用して予測値 Y(予測値、t) を作成し、それを時刻 t+1 でのみ実際の値と比較します。つまり、Y を予測モデルの機能として使用することはできません。
目標 Y がわかれば、予測を評価する方法も決定できます。これは、データに対して試すさまざまなモデルを区別するために重要です。解決しようとしている問題に応じて、モデルの効率を測定する指標を選択します。たとえば、価格を予測する場合、二乗平均平方根誤差を指標として使用できます。一般的に使用されるいくつかの指標 (移動平均、MACD、分散スコアなど) は Inventor Quant ツールボックスに事前にコーディングされており、API インターフェースを通じてこれらの指標をグローバルに呼び出すことができます。
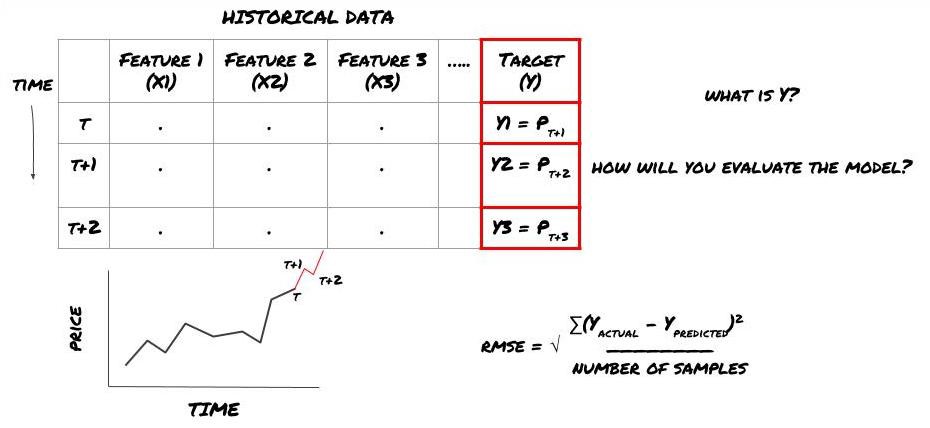
将来の価格を予測するための ML フレームワーク
実証するために、仮想投資対象の将来の期待基準値を予測する予測モデルを作成します。
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
これは回帰問題なので、RMSE (Root Mean Squared Error) でモデルを評価します。評価基準として総利益も使用します
注: RMSEに関する数学的な知識については、Baidu百科事典の関連コンテンツを参照してください。
- 私たちの目標は、予測値を可能な限り Y に近づけるモデルを作成することです。
ステップ2: 信頼できるデータを収集する
目の前の問題を解決するのに役立つデータを収集して整理する
ターゲット変数 Y の予測力を高めるには、どのようなデータを考慮する必要がありますか?価格を予測する場合は、目標価格データ、目標取引量データ、関連目標の類似データ、目標指数レベルなどの市場全体の指標、その他の関連資産の価格などを使用できます。
このデータに対するデータ アクセス権限を設定し、データが正確であることを確認し、欠落データ (非常に一般的な問題) を解決する必要があります。また、モデルに偏りが生じないように、データが偏りがなく、すべての市場状況を適切に表していることを確認してください(たとえば、勝ち/負けのシナリオの数が同じ)。配当、ポートフォリオの分割、継続などのデータをクリーンアップする必要がある場合もあります。
Inventor Quantitative Platform (FMZ.COM) をご利用の場合、Google、Yahoo、NSE、Quandl から無料でグローバルデータにアクセスできます。また、CTP や Yisheng などの国内商品先物、Binance、OKEX、Huobi、BitMex からの詳細データにもアクセスできます。 Inventor Quantitative Platform は、投資ターゲットの分割や詳細な市場データなどのデータを事前にクリーンアップしてフィルタリングし、定量分析担当者が理解しやすい形式で戦略開発者に提示します。
本稿では便宜上、仮想投資対象「MQK」として以下のデータを使用します。また、Auquan's Toolboxという非常に便利な定量ツールも使用します。詳細については、https://github.com/Auquanを参照してください。 / auquan-toolbox-python
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
上記のコードにより、Auquan の Toolbox はデータをダウンロードし、データ フレーム ディクショナリに読み込みました。ここで、好みの形式でデータを準備する必要があります。関数 ds.getBookDataByFeature() は、機能ごとに 1 つのデータ フレームを含むデータ フレームの辞書を返します。すべての機能を備えた株式の新しいデータフレームを作成します。
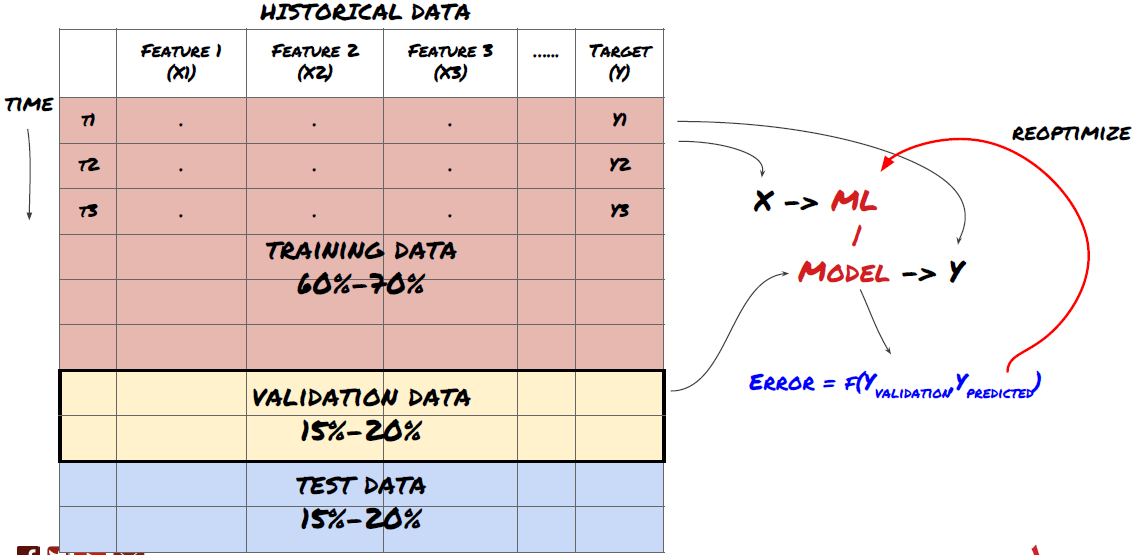
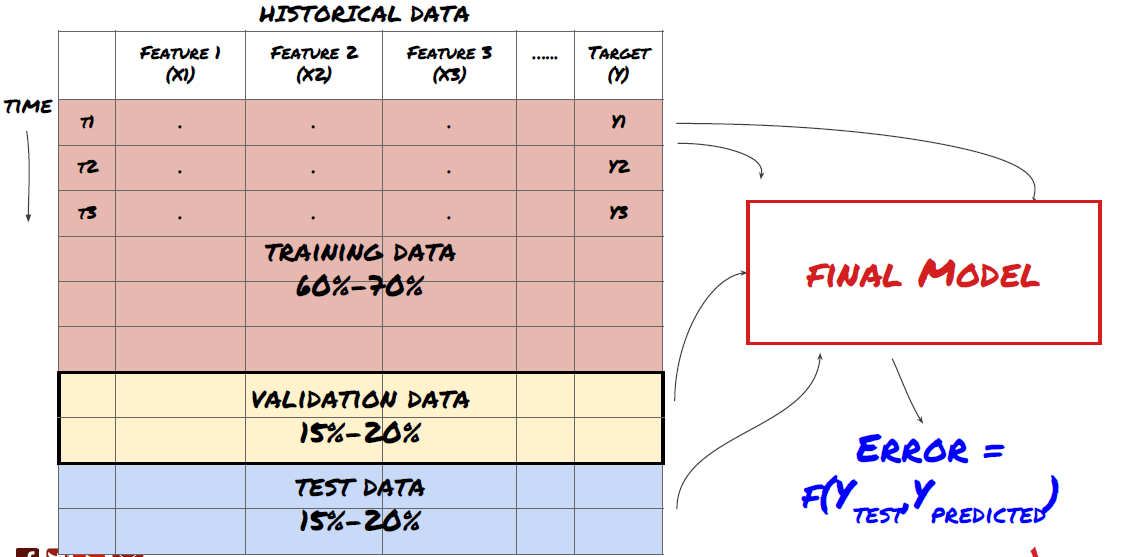
ステップ3: データを分割する
- データからトレーニングセットを作成し、これらのセットを相互検証してテストする
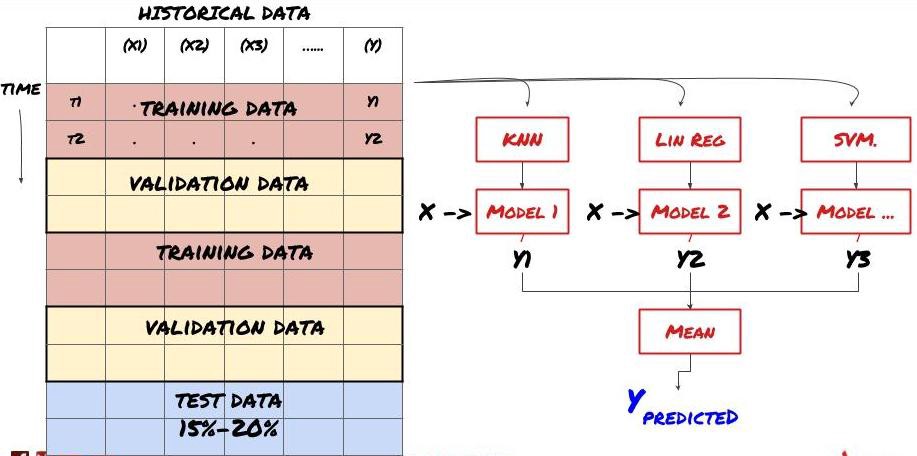
これは非常に重要なステップです! 先に進む前に、モデルをトレーニングするためのトレーニング データセットと、モデルのパフォーマンスを評価するためのテスト データセットにデータを分割する必要があります。推奨される割合は、トレーニングセット60~70%、テストセット30~40%です。
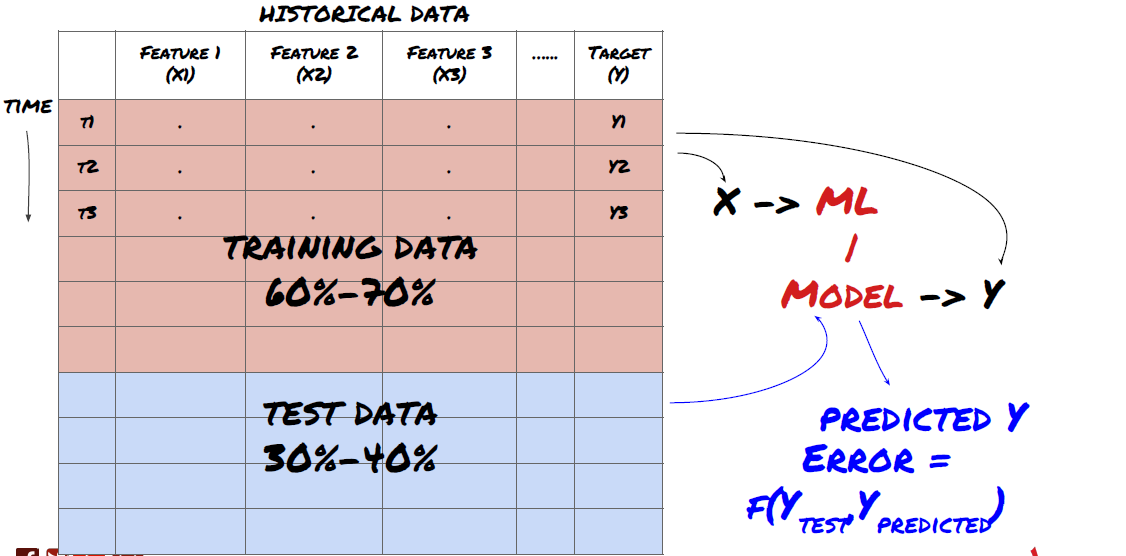
データをトレーニングセットとテストセットに分割する
トレーニング データはモデル パラメータを評価するために使用されるため、モデルがこのトレーニング データに過剰適合し、トレーニング データによってモデルのパフォーマンスが誤認される可能性があります。個別のテスト データを保持せず、すべてのデータをトレーニングに使用すると、新しい未知のデータに対してモデルがどの程度うまく機能するかがわかりません。これは、トレーニングされた ML モデルがライブ データで失敗する主な理由の 1 つです。つまり、利用可能なすべてのデータでトレーニングを行い、トレーニング データのメトリックに注目しますが、モデルはトレーニングに使用されていないライブ データに対しては意味のある予測を行うことができません。
データをトレーニング、検証、テストセットに分割する
このアプローチには問題があります。トレーニング データで繰り返しトレーニングし、テスト データでパフォーマンスを評価し、パフォーマンスに満足するまでモデルを最適化すると、テスト データがトレーニング データの一部として暗黙的に含められます。最終的に、このトレーニング データとテスト データのセットではモデルのパフォーマンスが良好になるかもしれませんが、新しいデータを適切に予測できるという保証はありません。
この問題に対処するには、別の検証データセットを作成します。これで、データでトレーニングし、検証データでパフォーマンスを評価し、パフォーマンスに満足するまで最適化し、最後にテスト データでテストできるようになります。この方法では、テスト データが汚染されることはなく、モデルを改善するためにテスト データの情報を使用することもありません。
テスト データでパフォーマンスを確認したら、戻ってモデルをさらに最適化しないでください。モデルが良好な結果を出していないことがわかった場合は、モデルを完全に破棄して最初からやり直してください。推奨される分割は、トレーニング データ 60%、検証データ 20%、テスト データ 20% です。
私たちの問題では、3 つのデータセットが利用可能であり、1 つをトレーニング セットとして、2 つ目を検証セットとして、3 つ目をテスト セットとして使用します。
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
これらそれぞれに、次の5つの基準値の平均として定義される目標変数Yを追加します。
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
ステップ4: 特徴エンジニアリング
データの挙動を分析し、予測力のある特徴を作成する
これからプロジェクトの実際の建設が始まります。特徴選択の黄金律は、予測力はモデルからではなく、主に特徴から得られるというものです。モデルの選択よりも機能の選択の方がパフォーマンスに大きな影響を与えることがわかります。機能選択に関する注意事項:
-
ターゲット変数との関係を調査せずに、多数の特徴を恣意的に選択しないでください。
-
ターゲット変数との関連性がほとんどないか全くない場合、過剰適合につながる可能性がある
-
選択した特徴は互いに高い相関関係にある可能性があり、その場合、少数の特徴でもターゲットを説明できる可能性があります。
-
私は通常、直感的に理解できる特徴をいくつか作成し、ターゲット変数がこれらの特徴とどのように相関しているか、またそれらが互いにどのように相関しているかを調べて、どの特徴を使用するかを決定します。
-
また、最大情報係数 (MIC) に基づいて候補機能をランク付けしたり、主成分分析 (PCA) やその他の方法を実行したりすることもできます。
特徴変換/正規化:
ML モデルは正規化によってパフォーマンスが向上する傾向があります。ただし、時系列データを扱う場合、データの将来の範囲が不明であるため、正規化は困難です。データが正規化された範囲外にあるため、モデルが間違っている可能性があります。しかし、ある程度の定常性を強制することは可能です。
-
スケーリング: 標準偏差または四分位範囲で特徴量を分割する
-
中央揃え: 現在の値から過去の平均値を引く
-
正規化: 上記の 2 つのルックバック期間 (x - 平均) / 標準偏差
-
従来の正規化: データを -1 から +1 の範囲に正規化し、ルックバック期間 (x-min)/(max-min) 内で再中心化します。
過去の移動平均、標準偏差、参照期間の最大値または最小値を使用するため、特徴の正規化された値は、異なる時点での異なる実際の値を表すことに注意してください。たとえば、特徴の現在の値が 5 で、30 期間の実行平均が 4.5 の場合、中央揃え後に 0.5 に変換されます。その後、30 期間の移動平均が 3 になると、値 3.5 は 0.5 になります。これがモデルが間違っている理由かもしれません。したがって、正規化は難しいので、実際にモデルのパフォーマンスを向上させるものは何なのか(もしあれば)を把握する必要があります。
問題の最初の反復では、混合パラメータを使用して多数の機能を作成しました。後で機能の数を減らすことができるかどうかを確認します
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
ステップ5: モデルの選択
選択した問題に適した統計/MLモデルを選択する
モデルの選択は、問題がどのように定式化されるかによって異なります。教師あり学習問題(特徴マトリックス内の各ポイント X がターゲット変数 Y にマッピングされる)を解決していますか、それとも教師なし学習問題(マッピングは提供されず、モデルは未知のパターンを学習しようとします)を解決していますか?回帰問題(将来の実際の価格を予測する)を解決していますか、それとも分類問題(将来の価格の方向(増加/減少)のみを予測する)を解決していますか。

教師あり学習と教師なし学習

回帰または分類
一般的な教師あり学習アルゴリズムのいくつかは、始める際に役立ちます。
-
LinearRegression(パラメータ、回帰)
-
ロジスティック回帰(パラメータ、分類)
-
K近傍法(KNN)アルゴリズム(インスタンスベース、回帰)
-
SVM、SVR(パラメータ、分類、回帰)
-
決定木
-
決定フォレスト
線形回帰やロジスティック回帰などの単純なモデルから始めて、必要に応じてそこからより複雑なモデルを構築することをお勧めします。また、モデルをブラックボックスとして盲目的に使用するのではなく、モデルの背後にある数学を読むことをお勧めします。
ステップ 6: トレーニング、検証、最適化 (ステップ 4 ~ 6 を繰り返す)
トレーニングデータセットと検証データセットを使用してモデルをトレーニングおよび最適化します
これで、モデルを構築する準備が整いました。この段階では、実際にはモデルとモデル パラメータを反復処理するだけです。トレーニング データでモデルをトレーニングし、検証データでそのパフォーマンスを測定してから、戻って最適化、再トレーニング、評価を行います。モデルのパフォーマンスに満足できない場合は、別のモデルを使用してみてください。満足のいくモデルが完成するまで、このフェーズを数回繰り返します。
気に入ったモデルが見つかったら、次のステップに進みます。
デモ問題では、まず単純な線形回帰から始めましょう。
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
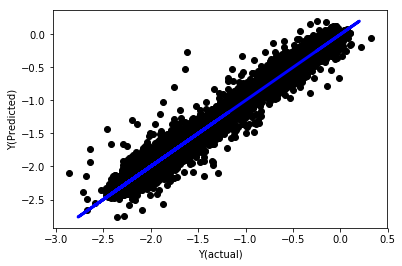
正規化なしの線形回帰
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
モデル係数を見てください。それぞれが異なる基準で判断されるため、実際に比較したり、どれが重要かを言うことはできません。正規化して同じスケールにし、定常性も確保してみましょう。
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
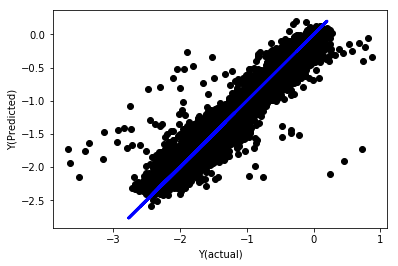
正規化線形回帰
Mean squared error: 0.05
Variance score: 0.90
このモデルは以前のモデルより改善されているわけではありませんが、劣っているわけでもありません。これで、実際に係数を比較して、どれが実際に重要であるかを確認できます。
係数を見てみましょう
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
結果は次のとおりです。
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
一部の特徴は他の特徴と比較して係数が高く、予測力がより強くなる可能性が高いことがはっきりとわかります。
さまざまな機能間の相関関係を見てみましょう。
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
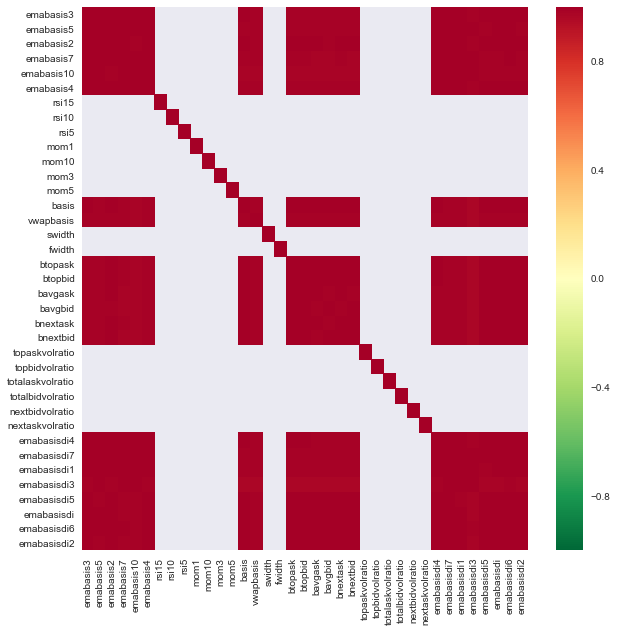
特徴間の相関関係
濃い赤色の領域は相関性の高い変数を示します。もう一度いくつかの機能を作成/変更して、モデルを改善してみましょう。
たとえば、他の機能の単なる線形結合である emabasisdi7 などの機能を簡単に破棄できます。
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
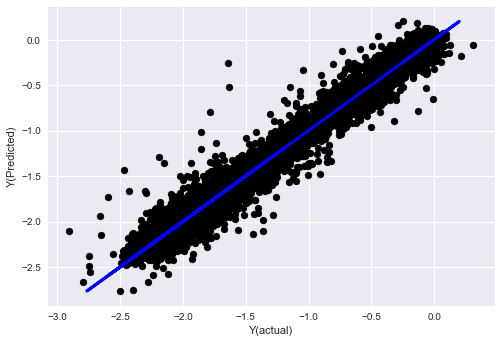
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
モデルのパフォーマンスに変化はなく、ターゲット変数を説明するためにいくつかの機能が必要なだけです。上記の機能をさらに試したり、新しい組み合わせなどを試して、モデルを改善できる点を確認することをお勧めします。
より複雑なモデルを試して、モデルの変更によってパフォーマンスが向上するかどうかを確認することもできます。
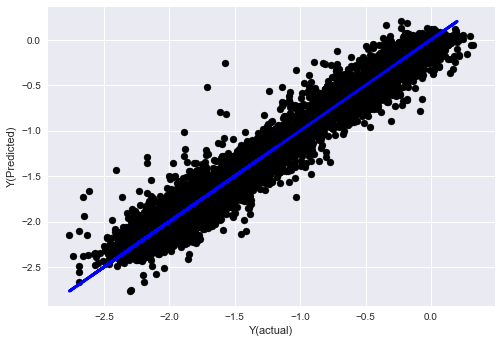
- K近傍法(KNN)アルゴリズム
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
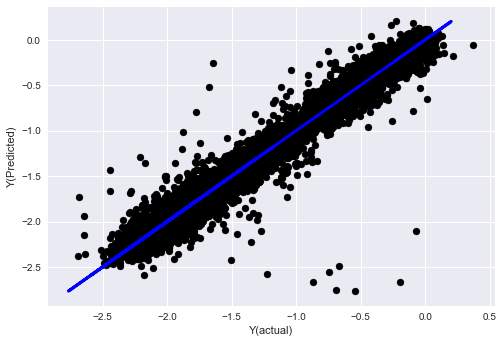
- SVR
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- 決定木
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
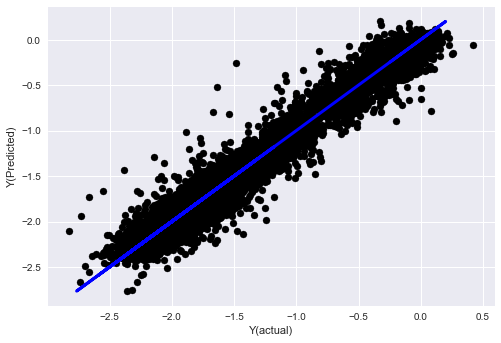
ステップ7: テストデータをバックテストする
実際のサンプルデータでパフォーマンスを確認する
(未変更の)テストデータセットでのバックテストパフォーマンス
これは重大な瞬間です。最後のステップでは、最初に取っておいてこれまで触れていなかったテスト データに対して最終的な最適化モデルを実行します。
これにより、ライブ取引を開始したときに、新しいデータや見たことのないデータに対してモデルがどのように機能するかについて現実的な予想が得られます。したがって、モデルのトレーニングや検証に使用されていないクリーンなデータセットがあることを確認する必要があります。
テスト データのバックテスト結果が気に入らない場合は、モデルを破棄して最初からやり直してください。決してモデルを再度最適化しないでください。過剰適合につながります。 (このデータセットは汚染されているため、新しいテスト データセットを作成することも推奨されます。モデルを破棄するときに、データセットについて暗黙的に何かがわかっていることになります)。
ここではAuquanのツールボックスを使用します
import backtester
from backtester.features.feature import Feature
from backtester.trading_system import TradingSystem
from backtester.sample_scripts.fair_value_params import FairValueTradingParams
class Problem1Solver():
def getTrainingDataSet(self):
return "trainingData1"
def getSymbolsToTrade(self):
return ['MQK']
def getCustomFeatures(self):
return {'my_custom_feature': MyCustomFeature}
def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\
coeff[4] * basis['MQK'] + coeff[5] * totalaskvol['MQK']+\
coeff[6] * totalbidvol['MQK']
newdf.fillna(emabasis5,inplace=True)
return newdf
problem1Solver = Problem1Solver()
tsParams = FairValueTradingParams(problem1Solver)
tradingSystem = TradingSystem(tsParams)
tradingSystem.startTrading(onlyAnalyze=False,
shouldPlot=True,
makeInstrumentCsvs=False)
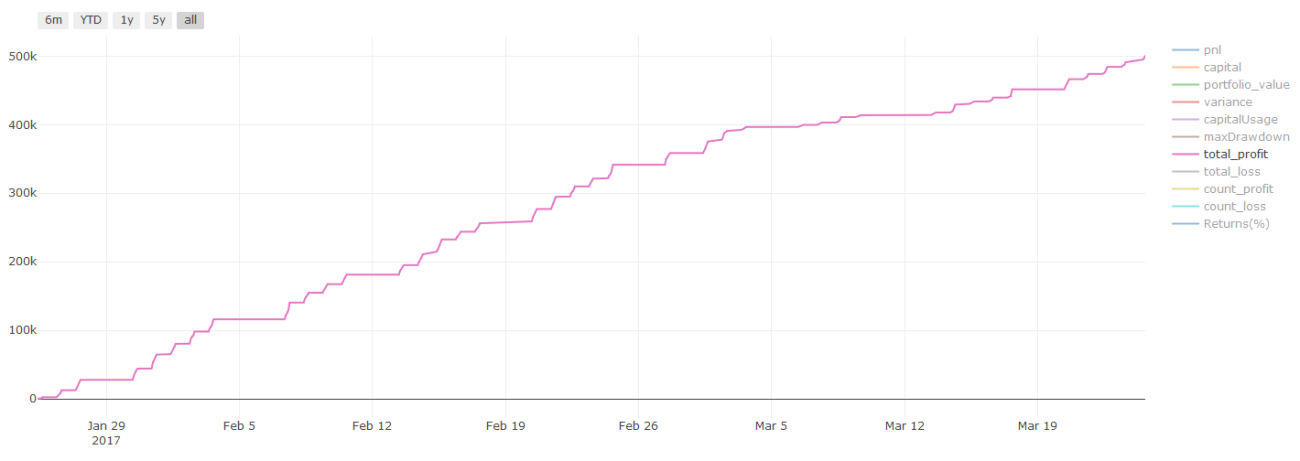
バックテストの結果、Pnlは米ドルで計算されます(Pnlには取引コストやその他の手数料は含まれません)
ステップ8: モデルを改善するその他の方法
ローリング検証、アンサンブル学習、バギングとブースティング
より多くのデータを収集したり、より優れた機能を作成したり、より多くのモデルを試したりする以外にも、改善するために試すことができることがいくつかあります。
1. ローリング検証
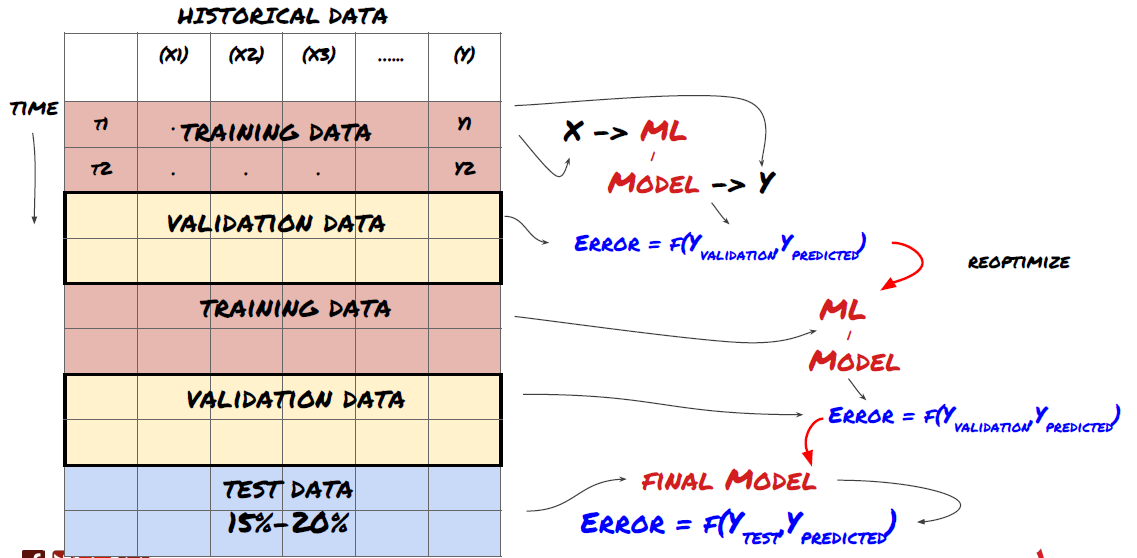
ローリング検証
市場の状況が一定に保たれることはめったにありません。たとえば、1 年分のデータがあり、1 月から 8 月までのデータをトレーニングに使用し、9 月から 12 月までのデータをモデルのテストに使用すると、非常に特殊な市場条件のセットをトレーニングすることになるかもしれません。おそらく、今年の前半には市場のボラティリティはなかったが、9 月に極端なニュースによって市場が急上昇したのでしょう。モデルはこのパターンを学習できず、不適切な予測結果を出すことになります。
1 月から 2 月にトレーニング、3 月に検証、4 月から 5 月に再トレーニング、6 月に検証というように、検証を段階的に進めていく方が良いかもしれません。
2. アンサンブル学習
アンサンブル学習
一部のモデルは、特定のシナリオの予測には適していますが、他のシナリオや特定の状況の予測では大幅に過剰適合する可能性があります。エラーと過剰適合を減らす 1 つの方法は、さまざまなモデルのアンサンブルを使用することです。予測は多くのモデルによる予測の平均となり、異なるモデルの誤差は相殺または削減される可能性があります。一般的なアンサンブル手法としては、バギングとブースティングがあります。
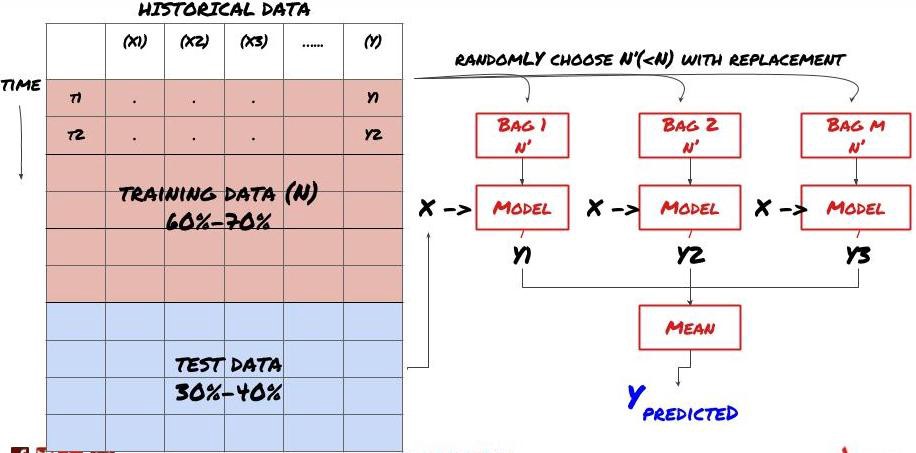
Bagging
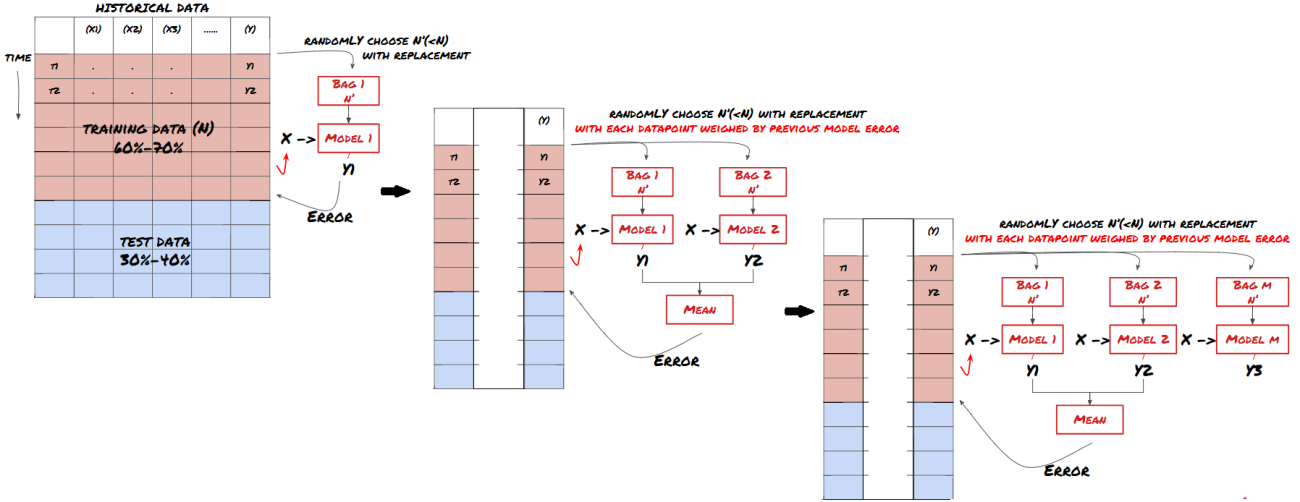
Boosting
簡潔にするために、これらの方法については省略しますが、それらに関する詳細情報はオンラインで見つけることができます。
私たちの問題にアンサンブル法を試してみましょう
basis_y_pred_ensemble = (basis_y_trees + basis_y_svr +
basis_y_knn + basis_y_regr)/4
Mean squared error: 0.02
Variance score: 0.95
これまでに多くの知識と情報を蓄積してきました。簡単に振り返ってみましょう。
-
問題を解決する
-
信頼できるデータの収集とデータのクリーニング
-
データをトレーニング、検証、テストセットに分割する
-
機能を作成し、その動作を分析する
-
行動に基づいて適切なトレーニングモデルを選択する
-
トレーニングデータを使用してモデルをトレーニングし、予測を行う
-
検証セットのパフォーマンスを確認し、再度最適化する
-
テストセットで最終的なパフォーマンスを検証する
かなりワクワクしますよね? でも、まだ終わりではありません。これで、信頼できる予測モデルができただけです。私たちが戦略で本当に望んでいたものを覚えていますか?したがって、まだ必要ありません:
-
取引の方向性を特定するための予測モデルベースのシグナルを開発する
-
オープンポジションとクローズポジションを特定するための具体的な戦略を立てる
-
ポジションと価格を識別する実行システム
上記のすべてには、Inventor Quantitative Platform (FMZ.COM) の使用が必要です。Inventor Quantitative Platform には、高度にカプセル化された完全な API インターフェースと、グローバルに呼び出し可能な注文およびトランザクション機能があるため、一つずつ接続して追加します。異なる取引所のAPIインターフェース、Inventor Quantitative Platformの戦略スクエアには、成熟した完全な代替戦略がたくさんあります。この記事の機械学習方法を使用すると、特定の戦略がより強力になります。ストラテジースクエアはこちら:https://www.fmz.com/square
取引コストに関する重要な注意事項: モデルは、選択した資産をいつロングまたはショートするかを教えてくれます。ただし、手数料/取引コスト/利用可能な取引量/ストップロスなどは考慮されません。取引コストにより、利益のある取引が損失に変わることがよくあります。たとえば、価格が 0.05 ドル上昇すると予想される資産は買いですが、この取引を行うために 0.10 ドルを支払う必要がある場合、最終的に 0.05 ドルの純損失が発生します。上記の素晴らしい利益グラフは、ブローカー手数料、取引所手数料、スプレッドを考慮すると、実際には次のようになります。
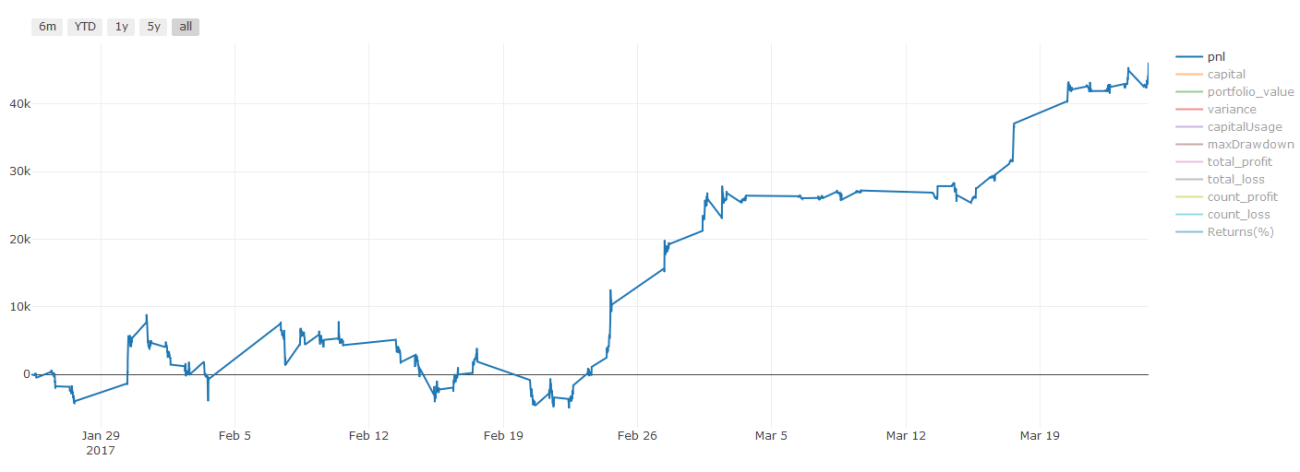
取引手数料とスプレッドを差し引いたバックテスト結果、損益はUSD
取引手数料とスプレッドが当社の損益の 90% 以上を占めています。これらについては、今後の記事で詳しく説明します。
最後に、よくある落とし穴をいくつか見てみましょう。
すべきこと、すべきでないこと
-
全力で過剰適合を避けてください。
-
すべてのデータポイントの後に再トレーニングしないでください。これは、機械学習開発でよくある間違いです。データポイントごとにモデルを再トレーニングする必要がある場合、そのモデルはあまり良いものではない可能性があります。つまり、定期的に、意味がある限り頻繁に再トレーニングする必要がある(例えば、日中予測を行う場合は毎週末に)
-
バイアス、特に先読みバイアスを避けてください。これはモデルが機能しないもう 1 つの理由です。将来の情報を使用していないことを確認してください。ほとんどの場合、これはターゲット変数 Y をモデルの機能として使用しないことを意味します。バックテスト中に使用できますが、実際にモデルを実行するときには使用できず、モデルが役に立たなくなります。
-
データマイニングの偏りに注意してください。データが適合するかどうかを判定するために、一連のモデリングを実行しようとしているため、特別な理由がない場合は、ランダムなパターンと発生する可能性のある実際のパターンを区別するために厳密なテストを実行するようにしてください。 。たとえば、上昇傾向のパターンは線形回帰によって十分に説明されますが、より大きなランダム ウォークの小さな一部である可能性があります。
過剰適合を避ける
これは非常に重要なので、もう一度言及する必要があると感じています。
-
過剰適合は取引戦略における最も危険な罠である
-
複雑なアルゴリズムは、バックテストでは非常に優れたパフォーマンスを発揮するかもしれませんが、新しい未知のデータでは悲惨な結果になることがあります。このアルゴリズムは、データの傾向を実際に明らかにすることはなく、実際の予測力はありません。見るデータに非常に適しています
-
システムをできるだけシンプルに保ってください。データを説明するために多くの複雑な特徴が必要であると感じた場合は、過剰適合している可能性があります。
-
利用可能なデータをトレーニング データとテスト データに分割し、モデルを実際の取引に使用する前に、必ず実際のサンプル データでパフォーマンスを検証してください。



- 1