
여러 프로그래밍 거래 모델의 매개변수를 최적화하는 방법에 대해 이야기해 보겠습니다.
-
파라미터 고원 및 파라미터 고원
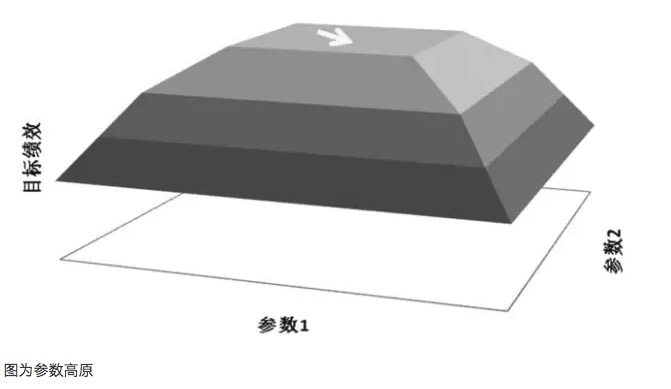
변수 최적화에서 중요한 원칙은 변수 고원 (parameter highlands) 을 추구하는 것이다. 변수 고원 (parameter highlands) 이란, 더 넓은 변수 범위가 존재한다는 것을 의미하며, 모델은 이 변수 범위 내에서 더 좋은 효과를 얻을 수 있다. 일반적으로 고원 (high plains) 의 중심으로 근사정체 분포형을 형성한다. 그리고 변수 고원 (parameter islands) 이란, 변수 값이 아주 작은 범위 안에 있을 때만, 모델의 성능이 더 좋아지는 것을 의미하며, 변수가 그 값에서 벗어날 때 모델의 성능은 눈에 띄게 변한다.
-
그래프로 표시
매개 변수 고원 도표와 매개 변수 독도 도표의 예로, 어떤 거래 모델 안에 두 개의 매개 변수, 각각 매개 변수 1과 매개 변수 2가 있다고 가정하면, 두 개의 매개 변수에 대한 이동 테스트를 한 후, 3차 성과 도표를 얻는다. 좋은 매개 변수 분포는 매개 변수 고원 도표가 되어야 하며, 매개 변수 설정이 편향되어 있더라도, 모델의 수익성 성과가 여전히 보장될 수 있다. 이러한 매개 변수 안정성이 강하여, 모델이 미래의 실무에서 다양한 종류의 상황에 직면할 때, 강한 대응력을 갖는다. 그러나 매개 변수 고원 도표와 같은 매개 변수 이동 후의 성과가, 매개 변수 이동이 작은 때, 모델의 수익성 성과가 크게 변하면, 이러한 매개 변수 적응 성능이 좋지 않아 실제 거래에서 변화하는 시장 환경에 대처하기 어려운 경우가 많다.
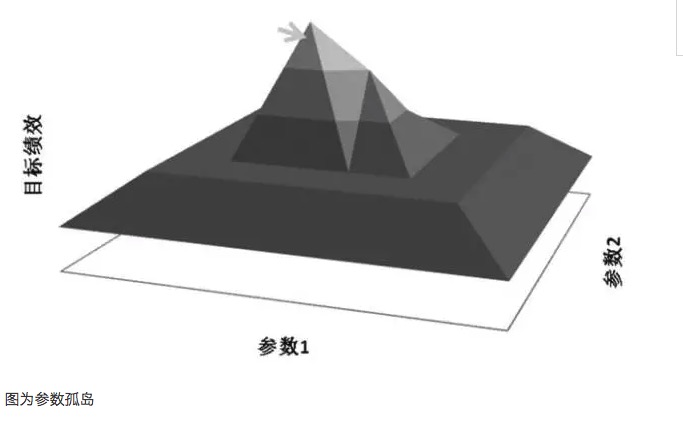
일반적으로, 만약 근접한 변수 시스템의 성능이 최우수 변수보다 훨씬 떨어지면, 이 최우수 변수는 과잉합의 결과일 가능성이 있으며, 수학적으로 기묘한 해법이라고 볼 수 있다. 수학적으로 기묘한 것은 불안정하며, 미래의 불확실한 상황에서 시장 특성이 변하면 최우수 변수가 최우수 변수로 변할 수 있다.
지나친 적합성은 선택된 표본과 관련이 있으며, 선택된 표본이 시장의 전체 특성을 나타내지 못하고, 테스트 결과를 긍정적 인 기대값에 도달시키기 위해만 파라미터를 조정하는 경우, 이러한 방법은 의심할 여지없이 자기 기만이며, 얻은 파라미터 값은 지나치게 적합 한 유효하지 않은 파라미터 값입니다. 예를 들어, 파라미터 지나친 적합성을 분석하여 거래 모델은 각각 35과 63의 값에서 수익률 급증 현상을 나타냅니다. 모델의 대응 지표가 35과 63을 선택하면 모델의 수익은 완벽하게 보이지만 실제로는 전형적인 파라미터 독도 섬 효과입니다.
오버피트와 변수 최적화의 주요 모순은 모델 변수 최적화가 얻을 수 있는 최우수 변수는 이미 일어난 역사적 데이터 샘플에 기초한 것일 뿐이며, 미래 행보는 역동적으로 변화하며, 역사 행태에 비해 유사성과 변동성이 있다. 모델 설계자는 모델이 역사적으로 가장 잘 수행한 변수를 찾을 수 있지만, 이 변수는 미래의 모델의 실제 응용에서 반드시 가장 잘 수행하는 것은 아니며, 더욱이 역사적으로 가장 잘 수행하는 모델 변수는 미래의 모델 전투에서 매우 나쁜 성능을 발휘할 수 있으며, 심지어 큰 손실을 초래할 수도 있다. 예를 들어, 역사적으로 큰 흐름을 잡을 수 있는 변수를 뽑은 모델이 있지만, 이러한 변수 값을 설정한 모델은 모델이 미래의 전투에서도 그렇게 잘 수행할 수 있다는 것을 의미하지 않으며, 이 역사적으로 가장 좋은 변수 값은 미래의 모델 전투에 적용되는 데 아무런 도움이 되지 않는다.
또한, 변수 고원과 변수 섬은 거래 횟수와 더 많은 관계가 있다. 모델의 거래 횟수가 적으면, 종종 적절한 변수 지점을 찾을 수 있으므로, 모델이 여러 거래 중 모두 수익을 올릴 수 있다. 이 변수 최적화 후의 모델이 수익을 얻는 것은 강한 우연성을 나타낸다. 모델의 거래 횟수가 많으면, 모델이 수익을 얻는 우연성은 떨어지며, 더 많은 수익의 필연성과 규칙성을 나타낸다. 또한, 변수 고원도 존재한다. 이 변수 최적화 모델은 변수 최적화의 목적이 있는 곳이다.
-
변수를 최적화하는 방법
파라미터 고원 및 파라미터 섬을 이해 한 후, 최적화 파라미터의 방법은 매우 중요하게 나타납니다, 특히 모델에 여러 개의 파라미터가 존재 할 때, 종종 한 파라미터의 값이 다른 파라미터 고원의 분포에 영향을 미칩니다. 그렇다면 어떻게 파라미터 배열을 최적화합니까?
한 가지 방법은 단계적 수렴법이다. 즉, 먼저 한 파라미터를 개별적으로 최적화하여 최적의 값을 얻으면 고정되고, 그 다음에는 다른 파라미터를 최적화하여 최적의 값을 얻으면 고정된다. 이렇게 순환하여, 최적의 결과가 변하지 않는다. 예를 들어, 평형 교차 거래 모델에서, 두 개의 독립된 파라미터는 각각 평균 짧은 주기 N1과 긴 주기 N2이다. 먼저 N2를 1으로 고정시키고, N1의 1에서 100의 수학적 범위에서 테스트 필터를 통해 최적의 값을 찾으며, 최종적으로 최적의 값을 8으로 고정한다.
또 다른 방법은 강력한 계산 기능을 갖춘 프로그래밍 소프트웨어 설계 플랫폼을 사용하여 목표 함수와 변수 배열 사이의 분포를 직접 계산하고, 다차원 차이를 찾는 분포를 정의하여, 차이의 절대값이 <unk>값 범위에 해당하는 다차원 크기의 최대, 다차원 내 절단 반지름의 최고를 가장 안정적인 변수 값으로 선택한다.
변수 최적화 방법 이외에 데이터 샘플링도 중요한 요소이다. 트렌드 추적을 거래 아이디어로 사용하는 모델은 트렌드 상황이 발생했을 때 더 잘 작동하며, 높은 판매와 낮은 구매를 거래 아이디어로 사용하는 전략은 오스컬레이션 상황에서 더 잘 작동한다. 따라서, 변수 최적화 할 때, 수익을 고려하기 위해 거래 아이디어에 맞는 행동을 적절히 제거하고 손실을 고려하기 위해 전략에 맞지 않는 행동 데이터를 추가해야합니다.
주식 지수 선물의 예로, 상장 초기인 2010년과 극단적인 대부시장 상황이 발생한 2014년 후반까지 주식 지수 선물은 단방향이다. 의심의 여지없이, 모든 트렌드 모델은 좋은 효과를 얻을 수 있다. 그러나, 우리가 이러한 극단적인 운동 데이터도 샘플에 넣고 변수 최적화를 한다면, 얻어지는 모델 변수는 반드시 최선일 수 없다.
예를 들어, 어떤 모델에 두 개의 매개 변수가 있다고 가정해 봅시다. 매개 변수 A의 테스트 결과는 일방적인 상황 시점에서는 매우 잘 작동하며 다른 시점에서는 일반적으로 작동합니다. 다른 매개 변수 B의 테스트 결과는 일방적인 상황 시점에서는 매개 변수 A보다 덜 효과적이며 다른 시점에서는 매개 변수 A보다 더 잘 작동하며 각 시점 간의 분포는 매개 변수 A보다 균등합니다. 매개 변수 A가 전체 샘플 데이터에서 테스트된 리스크 수익과 같은 통합 지표가 매개 변수 B보다 높더라도 매개 변수 B를 선택하는 경향이 있습니다. 매개 변수 B는 상대적으로 더 안정적이며 특정 샘플에 의존하지 않습니다.
결론적으로, 프로그램 거래 모델을 구축할 때, 한쪽으로는, 변수 최적화를 통해 모델을 개선할 수 있으며, 가격 변동 모형에 더 잘 적응하도록 하여 투자 수익을 향상시킬 수 있다. 다른 한편으로는, 변수 최적화에 과도한 적합성을 방지하여, 시장 상황 변화에 대한 모델의 적합성을 크게 감소시킬 수 있다.
[프로그래밍 트레이더]
- 1