
Dalam proses menggunakan Inventor Quantify Workflow, terdapat banyak soalan yang diajukan oleh banyak pemaju di bahagian komen dan komuniti. Artikel ini mengumpul soalan-soalan yang kerap muncul, merangkumi konfigurasi persekitaran, penggunaan nod, pembacaan data, panggilan AI, mekanisme pengesanan, dan banyak lagi, untuk membantu anda mencari penyelesaian dengan cepat.
I. Masalah konfigurasi persekitaran
Q1: Kenapa sistem saya tidak dapat menjalankan strategi aliran kerja?
Hanya hos yang mempunyai versi terkini yang menyokong aliran kerja yang berjalan. Jika versi hos anda terlalu lama, dasar aliran kerja tidak dapat dimulakan dan perlu diperbaharui dengan versi terkini.
Q2: Apakah bahasa pengaturcaraan yang disokong oleh aliran kerja?
Kod nod aliran kerja hanya menyokong JavaScript, tidak menyokong Python. Jika anda terbiasa menulis strategi dengan Python, anda perlu menukarnya ke sintaks JS. Logik asas JS dan Python adalah serupa, terutamanya perbezaan sintaks.
2. Mekanisme operasi nod
Q3: Adakah nod dalam aliran kerja dipicu secara serentak atau berturut-turut?
Titik aliran kerja adalah bersiri ketat, hanya boleh mencetuskan satu demi satu, tidak berjalan serentak. Setiap titik mesti menunggu titik terdahulu selesai, dan anda perlu mengambil kira ciri ini semasa menetapkan mekanisme dasar.
Q4: Mengapa aliran kerja tidak dijalankan selepas anda menyiapkan nod kemas kini K-Line?
Jika anda menetapkan 1 jam K-Line Update Trigger, maka aliran kerja akan menunggu sehingga titik penuh K-Line Closure untuk mula berjalan. Semasa menunggu, aliran kerja tidak akan dijalankan, yang normal. Jika anda ingin menjalankan logik strategi yang berbeza semasa menunggu, anda boleh menetapkan pemicu kedua untuk menjalankan logik strategi anda.
3. Membaca data dan menyimpan pemboleh ubah
Q5: Bagaimana untuk membaca output data daripada satu nod?
Penulisan standard ialah:
javascript
$node["节点名称"].json
Sintaks ini boleh membaca output JSON dari sebarang nod. Tetapi terdapat batasan di sini, ia hanya boleh membaca data dari nod induk yang bersambung secara langsung. Ia tidak boleh dibaca dengan cara ini jika tidak ada hubungan hubungan langsung antara dua nod.
Q6: Bagaimana untuk berkongsi data antara nod yang tidak berhubung secara langsung?
Boleh digunakan_GVariabel global._GIni adalah penyimpanan dalaman global yang disediakan oleh aliran kerja FMZ, yang boleh berkongsi data antara mana-mana nod, mana-mana aliran.
Ia mudah digunakan:
javascript
// 保存数据
_G("变量名", 值)
// 读取数据
_G("变量名")
Namun, perlu diingat bahawa:_GVariabel akan terus wujud dan tidak akan dipadamkan walaupun pemacu disket dimulakan semula. Jika data lama yang dibaca dengan salah, anda perlu menetapkannya secara manual_G("变量名",null)Untuk menghapuskan, atau untuk mencipta semula cakera keras secara langsung.
Q7: Bilakah anda perlu menggunakan JSON.stringify?
Ia sering digunakan dalam proses data yang rumit.JSON.stringifyKaedah 。 Kaedah ini boleh menukar objek dan array yang rumit ke dalam rentetan teks, yang sangat berguna ketika memindahkan data ke nod AI, kerana AI hanya dapat memahami input dalam format teks 。
4. Penghantaran data oleh nod kod
Q8: Adakah kod kod perlu dikembalikan?
Ya, ia adalah satu keperluan yang sangat penting.returnMengembalikan data, untuk memastikan data terus dihantar antara nod. Walaupun kod anda tidak perlu mengeluarkan sebarang data, ia akan mengembalikan sebuah argumen kosong:
javascript
return {}
Jika anda lupa return, nod seterusnya tidak akan menerima data, menyebabkan keseluruhan aliran kerja terganggu.
Q9: Bagaimana untuk menangani pelbagai data yang dikeluarkan oleh nod?
Jika satu nod anda mengeluarkan banyak data, contohnya 10 berita, dan anda perlu memprosesnya secara bersepadu dan bukannya secara berasingan, anda tidak boleh terus memindahkannya ke nod seterusnya, anda perlu menggunakan nod penggabungan atau penggabungan untuk menggabungkan banyak data ke dalam satu paket.
Manfaatnya ialah struktur data yang jelas dan mudah untuk diproses oleh nod seterusnya. Sebagai contoh, untuk menyampaikan pelbagai berita kepada analisis AI, anda perlu mengumpul satu array terlebih dahulu, supaya AI dapat melihat semua maklumat sekaligus.
5. Konfigurasi dan pengendalian nod AI
Q10: Apabila terdapat kesilapan pada nod AI, apa yang perlu diperiksa terlebih dahulu?
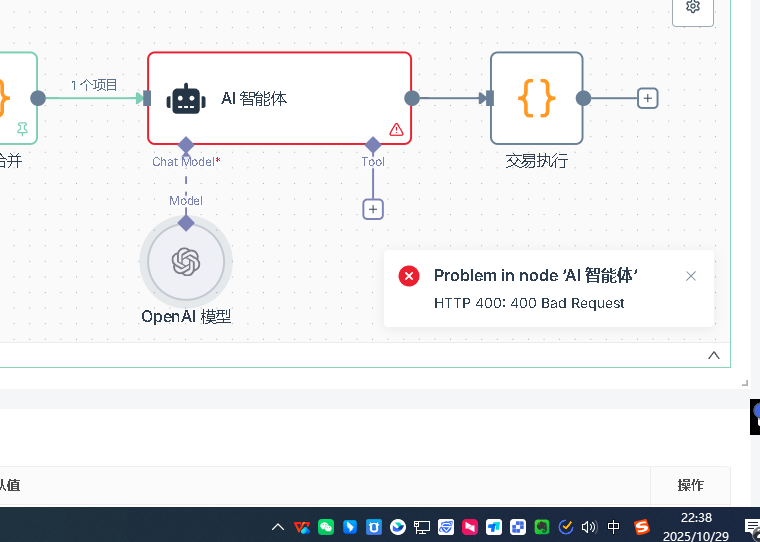
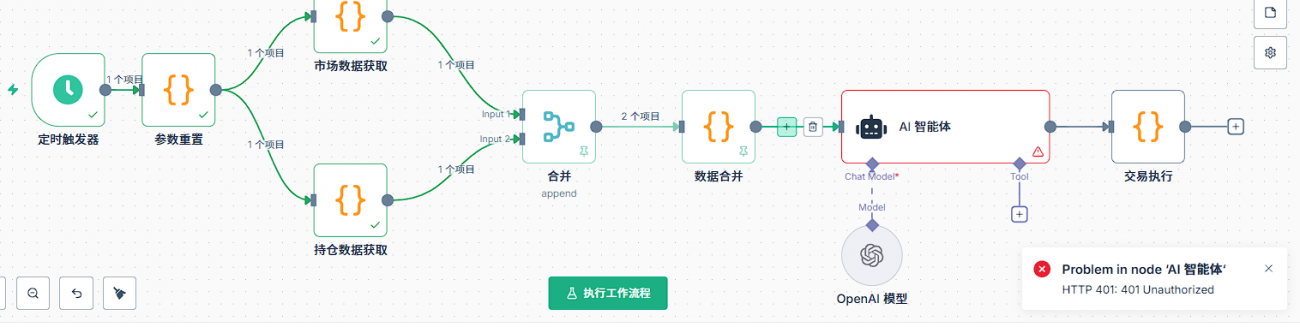
Pertama adalah tetapan asas untuk nod AI. Pada nod AI perlu menambah model model, dan kelayakan mesti ditetapkan dalam model. Pertama, cipta kelayakan baru, konfigurasi kelayakan terdiri daripada dua maklumat penting: kunci API dan url asas. Kunci API adalah kunci yang anda minta di platform yang bersangkutan, url asas adalah alamat permintaan API.
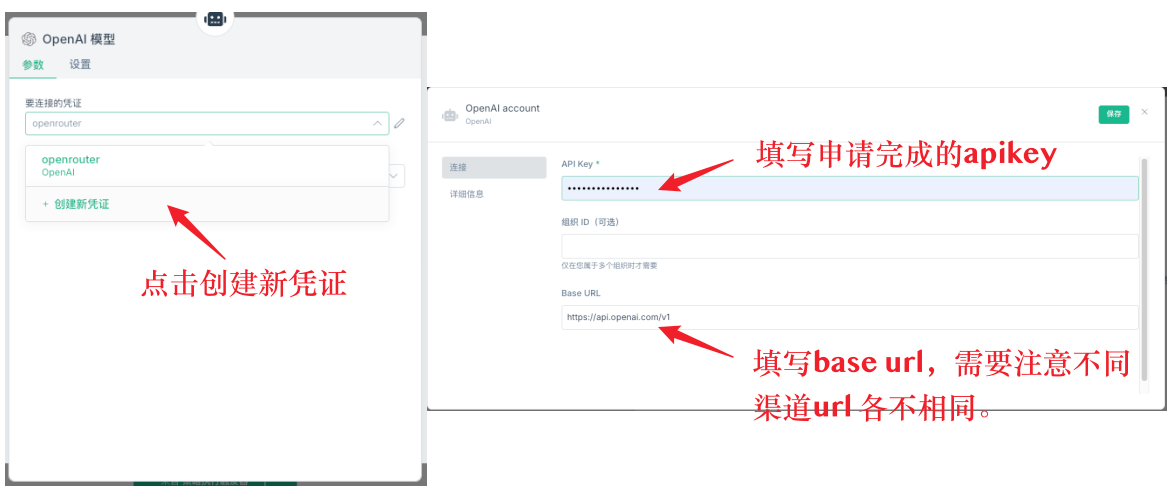
Q11: Perkhidmatan API mana yang lebih baik?
Tidak disyorkan untuk menggunakan API langsung Deepseek, kerana tindak balasnya lambat dan mudah terlewat, dan jumlahnya terhad. Disyorkan untuk menggunakan OpenRouter, yang dapat menyambung pelbagai model besar, kestabilan dan kelajuan yang lebih baik.
Q12: Adakah AI akan dikenakan kos?
Ya, panggilan AI adalah kos dan setiap permintaan akan menggunakan token. Jika panggilan gagal, periksa kecukupan baki akaun. Ia disyorkan untuk menggunakan model murah pada peringkat logik ujian strategi dan kemudian menukarnya kepada model yang lebih kuat setelah memastikan logik strategi betul.
Q13: Bagaimana untuk menulis arahan AI yang berkesan?
Ini adalah seni yang perlu dioptimumkan mengikut ciri-ciri model besar yang berbeza. Contohnya, Grok lebih agresif, Claude lebih berhati-hati, DeepSeek mempunyai kecenderungan semulajadi untuk melakukan lebih banyak kerana dilatih dengan data saham A. Memahami ciri-ciri ini dapat menulis arahan yang lebih berkesan.
6. Kestabilan dan kawalan angin model AI
Q14: Apakah model AI stabil dalam membuat keputusan?
Model AI belum sepenuhnya stabil. Walaupun AI dapat meningkatkan kualiti keputusan strategi, ia juga boleh membuat kesalahan. Persekitaran pasaran yang berbeza, penyampaian berita yang berbeza, dan bahkan input yang sama mungkin mendapat output yang berbeza pada masa yang berbeza. Ketidakpastian ini adalah ciri khas AI.
Q15: Apa yang perlu diperhatikan semasa menggunakan strategi AI?
Apabila menggunakan strategi AI, pastikan untuk menambah langkah-langkah kawalan risiko yang ketat. Contohnya: menetapkan had kerugian maksimum untuk setiap perdagangan, menetapkan had maksimum untuk kedudukan keseluruhan, menambahkan logik stop loss, jangan biarkan AI mengawal sepenuhnya dana.
AI harus menjadi alat bantu keputusan anda dan bukan objek yang ditugaskan sepenuhnya. Pemantauan buatan dan kawalan risiko tidak boleh hilang.
7. Keistimewaan pengesanan semula strategi AI
Q16: Adakah strategi yang melibatkan AI dapat dikesan semula?
Strategi yang mengandungi AI mempunyai keanehan yang besar dalam pengesanan semula, dan ini mesti difahami. Strategi biasa boleh mengesan semula data sejarah secara tidak sengaja, tetapi strategi AI tidak.
Kenapa? kerana setiap kali menggunakan AI akan memakan token dan menjana kos sebenar. Jika anda menggunakan data sejarah setahun, anda mungkin memerlukan ribuan kali menggunakan AI, dan kosnya sangat tinggi.
FMZ merancang satu mekanisme untuk melindungi dompet anda: dalam mod pengemasan semula, nod AI hanya akan memanggil tiga kali sebenar, dan kemudian menggunakan data simpanan tiga kali tersebut. Oleh itu, keputusan pengemasan semula hanyalah rujukan dan tidak mewakili kualiti keputusan AI yang sebenar.
Q17: Adakah strategi AI yang menggunakan berita terkini dapat dikesan?
Jika strategi anda memanggil berita terkini, pengembalian tidak masuk akal. Kerana anda menggunakan data K-line masa lalu, tetapi membaca berita semasa, kedua-duanya tidak sepadan, pengembalian tidak masuk akal.
Q18: Bagaimana anda boleh menguji strategi AI?
Kaedah yang disyorkan adalah: Uji ujian dengan modal kecil, kitaran kecil, perhatikan kualiti keputusan AI dan prestasi strategi untuk beberapa waktu, pastikan ia stabil dan kemudian meningkatkan dana secara beransur-ansur. Untuk strategi AI, pengesahan dalam talian lebih penting daripada pengesanan semula sejarah.
Konfigurasi nod HTTP dan MCP
Q19: Bagaimana jika nod HTTP tidak dapat mengakses data?
HTTP dan MCP biasanya digunakan untuk mendapatkan data luaran, tetapi banyak perkhidmatan API memerlukan kunci untuk mengaksesnya. Jika anda mengkonfigurasi permintaan HTTP tetapi tidak dapat memperoleh data, periksa sama ada kunci API diperlukan dan maklumat pengesahan dikonfigurasi dengan betul. Sesetengah API juga mempunyai had frekuensi permintaan, dan jika panggilan terlalu kerap, aliran akan dibatasi atau bahkan diblokir.
Q20: Bagaimana untuk meningkatkan kestabilan pengambilan data luaran?
Titik MCP lebih kuat dan boleh disambungkan ke pelbagai perkhidmatan data berstruktur, tetapi konfigurasi juga lebih rumit. Perlu menetapkan titik akhir perkhidmatan, kaedah pengesahan, parameter permintaan, dan sebagainya dengan betul. Disarankan untuk menggunakan titik HTTP untuk menguji API untuk akses normal, mengesahkan format data dan kemudian mengintegrasikannya ke dalam aliran kerja.
Selain itu, untuk meningkatkan kestabilan, anda boleh menambah mekanisme retest kegagalan ke nod ini. Buka retest dalam tetapan nod, atur bilangan dan selang waktu retest, supaya masalah rangkaian sementara tidak menyebabkan keseluruhan aliran kerja gagal.
9. Masalah keserasian kod
Q21: Adakah FMZ workflow dan kod n8n boleh digunakan bersama?
Aliran kerja pencipta adalah berdasarkan rangka kerja sumber terbuka n8n yang dikesan secara kuantitatif, tetapi kod kedua-duanya tidak boleh digunakan secara langsung antara satu sama lain. Jika anda mencari kod aliran kerja n8n di web, menampalkannya secara langsung ke FMZ tidak akan berfungsi, dan perlu diubah mengikut spesifikasi API dan nod FMZ. Sebaliknya, kod aliran kerja FMZ tidak boleh digunakan secara langsung pada n8n.
Perbezaan utama adalah: FMZ melakukan perubahan khusus pada beberapa nod, parameter dan format output berbeza. Jika kod dipindahkan, konfigurasi dan panggilan fungsi setiap nod perlu diperiksa dengan teliti untuk memastikan ia sesuai dengan spesifikasi platform sasaran.
ringkaskan
Di atas adalah jawapan kepada soalan-soalan yang sering dibincangkan oleh pencipta mengenai aliran kerja kuantitatif. Kami merangkumi pelbagai aspek dari konfigurasi persekitaran, mekanisme nod, membaca data, kod spesifikasi, panggilan AI hingga ujian umpan balik, yang merupakan isu-isu yang kerap berlaku dalam peperangan. Dengan pengetahuan ini, anda akan dapat mengurangkan banyak halangan semasa membangunkan aliran kerja.
Tetapi perdagangan kuantitatif adalah proses pembelajaran yang berterusan, dan masalah baru akan terus muncul. Jika anda menghadapi masalah, jangan putus asa, lihat dokumen rasmi FMZ, cari perbincangan dalam komuniti, banyak masalah yang pernah dihadapi oleh orang sebelumnya.
Ingat: Soalan adalah guru yang terbaik, setiap kali anda menyelesaikan satu soalan, anda akan mendapat pemahaman yang lebih mendalam tentang aliran kerja.


- 1