
1. Pengenalan
Artikel sebelum ini memperkenalkan penggunaan rangkaian LSTM untuk meramalkan harga Bitcoin https://www.fmz.com/digest-topic/4035 Seperti yang dinyatakan dalam artikel, ia hanyalah projek kecil untuk berlatih dan membiasakan diri dengan RNN dan pytorch . Artikel ini akan memperkenalkan penggunaan kaedah pembelajaran pengukuhan untuk melatih strategi perdagangan secara langsung. Model pembelajaran pengukuhan ialah PPO sumber terbuka oleh OpenAI, dan persekitaran adalah berdasarkan gaya gim. Untuk memudahkan pemahaman dan ujian, model LSTM PPO dan persekitaran gim ujian belakang ditulis secara langsung tanpa menggunakan pakej siap sedia.
PPO, nama penuh Pengoptimuman Dasar Proksimal, ialah penambahbaikan pengoptimuman Kecerunan Dasar. Gim juga dikeluarkan oleh OpenAI Ia boleh berinteraksi dengan rangkaian dasar dan maklum balas keadaan semasa dan ganjaran persekitaran Ia seperti latihan pembelajaran pengukuhan yang menggunakan model LSTM PPO untuk membuat pembelian, penjualan atau tiada operasi secara langsung. maklumat pasaran Bitcoin Arahan diberikan oleh persekitaran ujian belakang, dan model dioptimumkan secara berterusan melalui latihan untuk mencapai matlamat keuntungan strategi.
Membaca artikel ini memerlukan asas tertentu dalam pembelajaran pengukuhan mendalam Python, pytorch dan DRL. Tetapi tidak mengapa jika anda tidak tahu cara melakukannya. Ia adalah mudah untuk belajar dan bermula dengan kod yang diberikan dalam artikel ini. Artikel ini dihasilkan oleh Platform Dagangan Kuantitatif Mata Wang Digital FMZ Inventor (www.fmz.com Selamat datang untuk menyertai kumpulan QQ: 863946592 untuk komunikasi).
2. Data dan rujukan pembelajaran
Data harga Bitcoin datang daripada platform dagangan kuantitatif pencipta FMZ: https://www.quantinfo.com/Tools/View/4.html
Artikel tentang menggunakan DRL+gym untuk melatih strategi perdagangan: https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4
Beberapa contoh untuk bermula dengan pytorch: https://github.com/yunjey/pytorch-tutorial
Artikel ini secara langsung akan menggunakan pelaksanaan ringkas model LSTM-PPO ini: https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py
Artikel tentang PPO: https://zhuanlan.zhihu.com/p/38185553
Lebih banyak artikel tentang DRL: https://www.zhihu.com/people/flood-sung/posts
Mengenai gim, artikel ini tidak perlu memasangnya, tetapi pembelajaran pengukuhan adalah perkara biasa: https://gym.openai.com/
3.LSTM-PPO
Untuk penjelasan yang mendalam tentang PPO, anda boleh mengkaji rujukan sebelum ini. Berikut adalah pengenalan kepada konsep mudah. Dalam keluaran sebelum ini, rangkaian LSTM hanya meramalkan harga Bagaimana untuk membeli dan menjual urus niaga berdasarkan harga yang diramalkan ini perlu dilaksanakan secara berasingan , betul tak? Kecerunan Dasar adalah seperti ini Ia boleh memberikan kebarangkalian pelbagai tindakan berdasarkan input maklumat persekitaran s. Kerugian LSTM ialah perbezaan antara harga ramalan dan harga sebenar, manakala kerugian PG ialah -log(p)*Q, di mana p ialah kebarangkalian tindakan menjadi output, dan Q ialah nilai tindakan (seperti skor ganjaran Penjelasan intuitif ialah jika nilai tindakan lebih tinggi, rangkaian harus mengeluarkan kebarangkalian yang lebih tinggi). untuk mengurangkan kerugian. Walaupun PPO jauh lebih rumit, prinsipnya adalah serupa. Kuncinya terletak pada cara menilai dengan lebih baik nilai setiap tindakan dan cara mengemas kini parameter dengan lebih baik.
Kod sumber LSTM-PPO diberikan di bawah, yang boleh difahami dalam kombinasi dengan maklumat sebelumnya:
python
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
#模型的超参数
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # 也可以改为GPU版本
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
#输出各个动作的概率,由于是LSTM网络还要包含hidden层的信息,可以参考上一期文章
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
#价值函数,用于评价当前局面的好坏,所以只有一个输出
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
#准备训练数据
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) #同时训练了价值网络和决策网络
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. Persekitaran ujian balik Bitcoin
Mengikut format gim, terdapat kaedah pemulaan semula, tindakan input langkah, dan hasil yang dikembalikan ialah (keadaan seterusnya, faedah tindakan, sama ada ia telah selesai, keseluruhan persekitaran ujian belakang hanya 60 baris, yang boleh diubahsuai oleh anda sendiri versi kompleks, kod khusus:
python
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks #初始的比特币数量
self.initial_balance = initial_balance #初始的资产
self.current_time = 0 #回测的时间位置
self.commission = commission #易手续费
self.done = False #回测是否结束
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) #标准化方法,简单的收益率标准化
self.mode = all_data # 是否为抽样回测模式
self.sample_length = 500 # 抽样长度
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
#action即策略采取的动作,这里将更新账户和计算reward
done = False
if action == 0: #持有
pass
elif action == 1: #买入
buy_value = self.balance*0.5
if buy_value > 1: #余钱不足,不操作账户
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: #卖出
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # 每回合的reward是新增收益
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. Beberapa butiran penting
Mengapakah akaun awal mempunyai syiling?
Formula untuk mengira pulangan dalam persekitaran ujian belakang ialah: Pulangan Semasa = Nilai Akaun Semasa - Nilai Semasa Akaun Permulaan. Ini bermakna jika harga Bitcoin jatuh dan strategi menjual syiling, strategi sebenarnya harus diberi ganjaran walaupun jumlah nilai akaun menurun. Jika tempoh ujian belakang adalah panjang, akaun awal mungkin tidak banyak terjejas, tetapi ia masih akan memberi impak yang besar pada permulaannya. Mengira pulangan relatif memastikan setiap operasi yang betul memperoleh ganjaran positif.
Mengapa kami mencuba pasaran semasa latihan?
Jumlah data adalah lebih daripada 10,000 K-lines Jika kitaran penuh dijalankan setiap kali, ia akan mengambil masa yang lama, dan strategi akan menghadapi situasi yang sama setiap kali, yang mungkin membawa kepada overfitting. 500 bar dilukis setiap kali sebagai data backtest Walaupun overfitting masih mungkin, strategi menghadapi lebih daripada 10,000 kemungkinan permulaan yang berbeza.
Apa yang perlu dilakukan jika anda tidak mempunyai syiling atau wang?
Situasi ini tidak dipertimbangkan dalam persekitaran backtest Jika syiling telah habis dijual atau jumlah urus niaga minimum tidak dicapai, melaksanakan operasi jual pada masa ini sebenarnya bersamaan dengan melaksanakan tiada operasi, menurut relatif kaedah pengiraan pulangan, ia masih berdasarkan Ganjaran positif strategi. Kesan daripada keadaan ini ialah apabila strategi menentukan bahawa pasaran jatuh dan baki syiling dalam akaun tidak boleh dijual, adalah mustahil untuk membezakan antara tindakan penjualan dan tiada operasi, tetapi ia tidak mempunyai kesan ke atas pertimbangan strategi itu sendiri. pasaran.
Mengapa mengembalikan maklumat akaun sebagai status?
Model PPO mempunyai rangkaian nilai yang digunakan untuk menilai nilai keadaan semasa Jelas sekali, jika strategi menentukan bahawa harga akan meningkat, seluruh negeri hanya akan mempunyai nilai positif jika akaun semasa memegang Bitcoin, dan sebaliknya. Oleh itu, maklumat akaun adalah asas penting untuk menilai rangkaian nilai. Ambil perhatian bahawa maklumat tindakan lepas tidak dikembalikan sebagai keadaan, yang secara peribadi saya fikir tidak berguna untuk menilai nilai.
Dalam keadaan apakah ia tidak akan kembali beroperasi?
Apabila strategi menentukan bahawa keuntungan daripada membeli dan menjual tidak dapat menampung yuran urus niaga, ia sepatutnya tidak kembali kepada tindakan. Walaupun penerangan sebelum ini berulang kali menggunakan strategi untuk menentukan arah aliran harga, ia hanya untuk memudahkan pemahaman, sebenarnya model PPO ini tidak membuat sebarang ramalan tentang pasaran, tetapi hanya mengeluarkan kebarangkalian tiga tindakan.
6. Pemerolehan data dan latihan
Seperti dalam artikel sebelumnya, data diperoleh dalam format berikut: K-line satu jam pasangan dagangan BTC_USD di bursa Bitfinex dari 2018/5/7 hingga 2019/6/27:
python
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
Oleh kerana rangkaian LSTM digunakan, masa latihan adalah sangat lama, jadi saya menukar kepada versi GPU, iaitu kira-kira 3 kali lebih pantas.
python
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 #记录总收益
profit_list = [] #记录每次训练收益
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. Keputusan latihan dan analisis
Selepas menunggu lama:

Pertama, mari kita lihat arah aliran pasaran data latihan Secara umumnya, separuh pertama adalah penurunan yang panjang, dan separuh kedua adalah lantunan yang kuat.
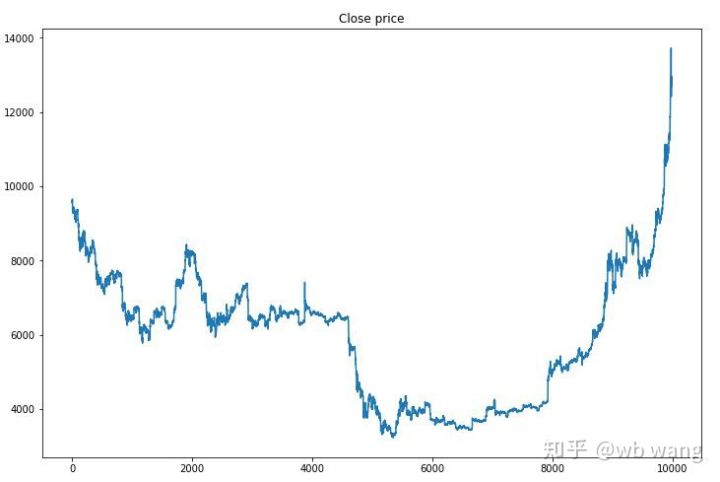
Terdapat banyak operasi pembelian pada peringkat awal latihan, dan pada dasarnya tiada pusingan yang menguntungkan. Menjelang pertengahan tempoh latihan, bilangan operasi pembelian secara beransur-ansur menurun, dan kebarangkalian keuntungan menjadi lebih besar dan lebih besar, tetapi masih terdapat kemungkinan kerugian yang tinggi.
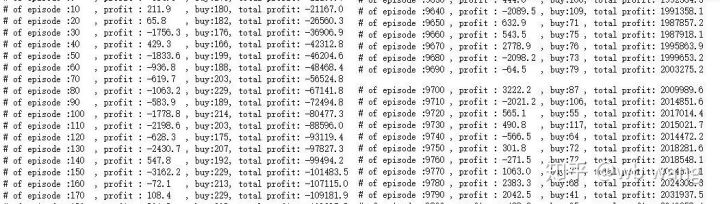
Melicinkan hasil setiap pusingan, keputusannya adalah seperti berikut:
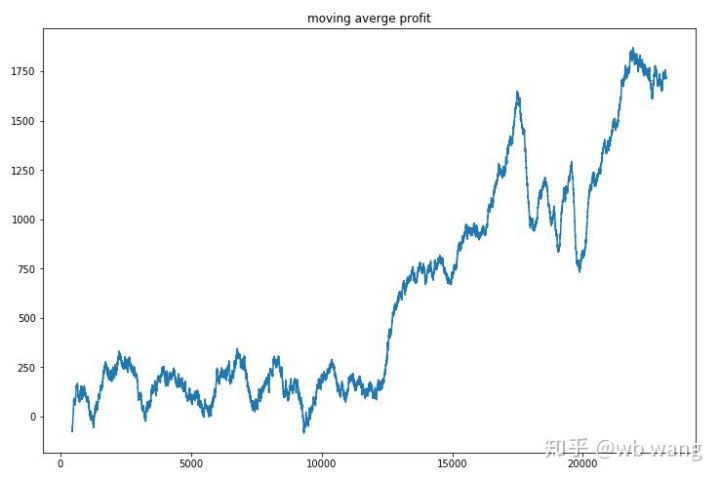
Strategi ini dengan cepat menyingkirkan pulangan negatif pada peringkat awal, tetapi turun naik adalah besar. Ia tidak sampai 10,000 pusingan bahawa pulangan mula berkembang pesat.
Selepas latihan akhir selesai, biarkan model menjalankan semua data sekali lagi untuk melihat prestasinya Dalam tempoh ini, rekod jumlah nilai pasaran akaun, bilangan bitcoin yang dipegang, perkadaran nilai bitcoin dan jumlah pendapatan. .
Pertama ialah jumlah nilai pasaran Jumlah hasil adalah serupa, jadi saya tidak akan menyiarkannya di sini.
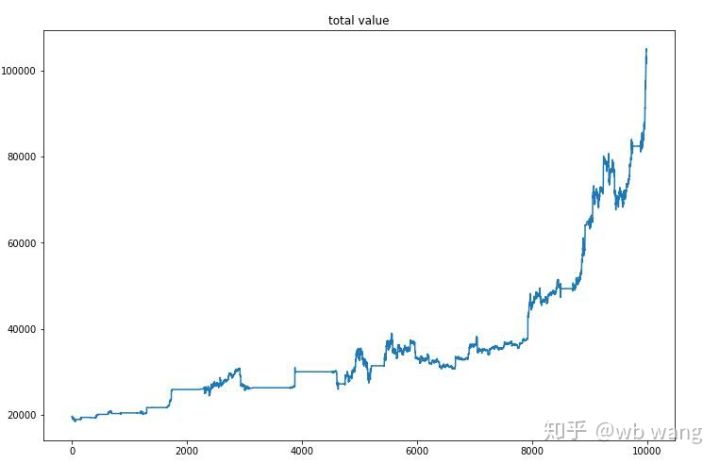
Jumlah nilai pasaran meningkat secara perlahan semasa pasaran menurun awal dan juga mengikuti kenaikan semasa pasaran kenaikan harga kemudian, tetapi masih terdapat kerugian berkala.
Akhir sekali, mari kita lihat perkadaran kedudukan Paksi kiri graf ialah perkadaran kedudukan, dan paksi kanan ialah situasi pasaran rendah dalam pasaran beruang awal, dan kekerapan kedudukan adalah sangat tinggi apabila pasaran berada di bawah. Kita juga dapat melihat bahawa model itu tidak belajar untuk memegang jawatan untuk masa yang lama dan sentiasa menjual dengan cepat.
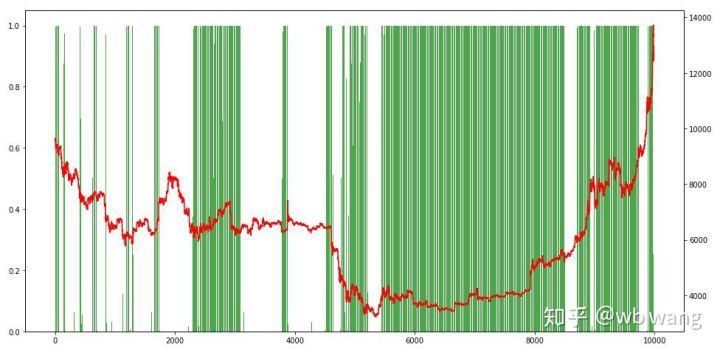
8. Menguji analisis data
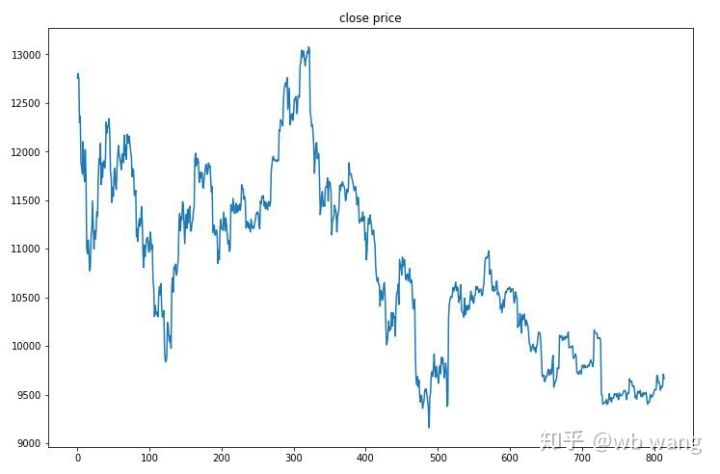
Data ujian diperolehi daripada pasaran Bitcoin sejam dari 2019/6/27 hingga sekarang. Seperti yang dapat dilihat dari angka itu, harga telah turun daripada $13,000 pada awalnya kepada lebih daripada $9,000 hari ini, yang merupakan ujian yang hebat untuk model itu.
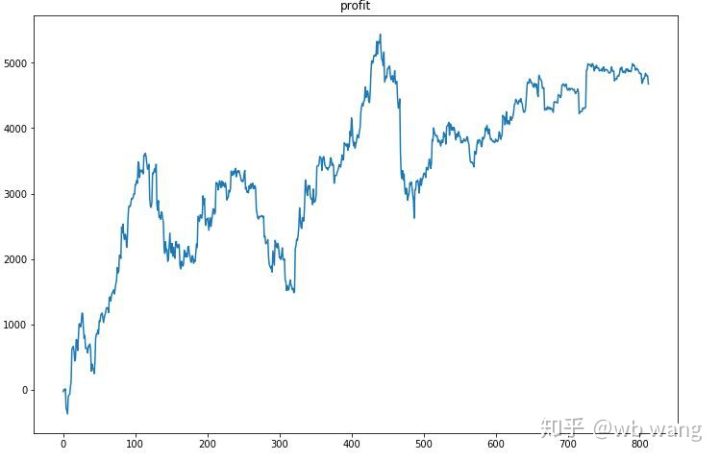
Pertama sekali, pulangan relatif akhir tidak memuaskan, tetapi tidak ada kerugian sama ada.
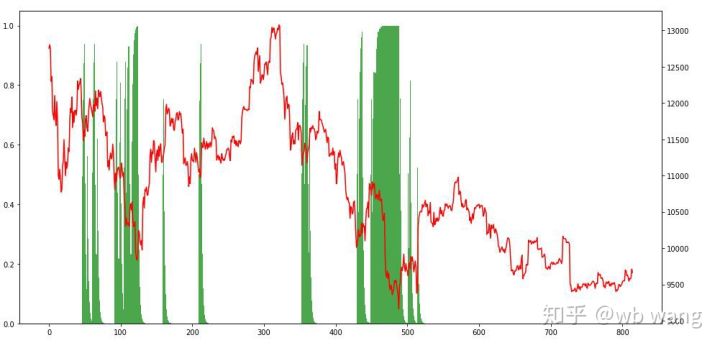
Melihat kepada kedudukan, kita boleh meneka bahawa model itu cenderung untuk membeli selepas penurunan mendadak dan menjual selepas lantunan Pasaran Bitcoin telah turun naik dengan sangat sedikit sejak kebelakangan ini, dan model itu berada dalam kedudukan pendek.
9. Rumusan
Artikel ini menggunakan kaedah pembelajaran pengukuhan mendalam PPO untuk melatih robot dagangan automatik Bitcoin dan memperoleh beberapa kesimpulan. Oleh kerana masa yang terhad, masih terdapat beberapa bahagian yang boleh diperbaiki dalam model. Semua orang dialu-alukan untuk berbincang. Pengajaran terbesar ialah penyeragaman data adalah kaedah yang betul Jangan gunakan kaedah seperti penskalaan, jika tidak model akan cepat mengingati hubungan antara harga dan keadaan pasaran dan jatuh ke dalam pemasangan berlebihan. Selepas normalisasi, kadar perubahan menjadi data relatif, yang menyukarkan model untuk mengingati hubungannya dengan pasaran dan memaksanya mencari hubungan antara kadar perubahan dan naik dan turun.
Artikel sebelumnya:
Beberapa perkongsian strategi awam di Platform Kuantitatif FMZ Inventor: https://zhuanlan.zhihu.com/p/64961672
Kursus perdagangan kuantitatif mata wang digital NetEase Cloud Classroom, hanya 20 yuan: https://study.163.com/course/courseMain.htm?courseId=1006074239&share=2&shareId=400000000602076
Saya telah membuat umum strategi frekuensi tinggi yang pernah sangat menguntungkan: https://www.fmz.com/bbs-topic/1211


profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.current_time,4]) 有bug
应该是:profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.start,4])
profit = self.value - (self.initial_balance+self.initial_stocksself.df.iloc[self.current_time,4]) 有bug
应该是:profit = self.value - (self.initial_balance+self.initial_stocksself.df.iloc[self.start,4])




GPU版
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class PPO(nn.Module):
def __init__(self):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(8,64)
self.lstm = nn.LSTM(64,32)
self.fc_pi = nn.Linear(32,3)
self.fc_v = nn.Linear(32,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 64)
x, lstm_hidden = self.lstm(x, hidden )
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 64)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float).to(device), torch.tensor(a_lst).to(device).to(device), \
torch.tensor(r_lst).to(device), torch.tensor(s_prime_lst, dtype=torch.float).to(device), \
torch.tensor(done_lst, dtype=torch.float).to(device), torch.tensor(prob_a_lst).to(device)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.to(device).detach(), h2.to(device).detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.cpu().detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float).to(device)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach())
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
- 1