
Многие разработчики задавали много вопросов в комментариях и сообществах в процессе использования рабочего потока для количественного измерения изобретателя. В этом статье собраны эти часто встречающиеся вопросы, охватывающие все аспекты конфигурации среды, использования узлов, чтения данных, вызова ИИ, механизм отслеживания и т. Д., Чтобы помочь вам быстро найти решение.
Вопросы типа конфигурации среды
Q1: Почему мой диск не может запускать стратегию рабочего потока?
Рабочий поток поддерживается только новейшей версией хоста. Если ваша версия хоста устарела, политика рабочего потока не может быть запущена и должна быть своевременно обновлена до последней версии.
Q2: Какие языки программирования поддерживают рабочие потоки?
Кодовые узлы рабочего потока поддерживают только JavaScript, а не Python. Если вы привыкли писать стратегии на Python, вам нужно перейти на JS. Основная логика JS и Python схожа, в основном это грамматические различия.
Второе: механизм работы узла
Q3: В рабочем процессе узлы запускаются одновременно или последовательно?
Рабочие потоки являются строго последовательными, они могут быть запущены только один за другим, а не одновременно. Каждый узел должен ждать, пока выполнение предыдущего узла будет завершено, чтобы начать его, и мы должны учитывать эту особенность при создании механизмов политики.
Q4: Почему после настройки узла обновления K-линии рабочий поток ждет неисполнения?
Если вы настроили 1-часовой триггер обновления K-линии, то рабочий поток будет ждать до завершения K-линии, чтобы начать работу. В течение ожидания рабочий поток не будет выполняться, и это нормально. Если вы хотите во время ожидания выполнять другую логику стратегии, вы можете настроить второй триггер для выполнения вашей логики стратегии.
Читать данные и сохранять переменные
Q5: Как читать выходные данные узла?
Стандартное написание:
javascript
$node["节点名称"].json
Этот синтаксис может читать JSON-вывод из любого узла. Но здесь есть ограничение: можно читать только данные из непосредственно соединенных родительских узлов. Если между двумя узлами нет прямой связи, нельзя читать таким образом.
Q6: Как можно обмениваться данными между непосредственно не связанными узлами?
Доступно_GГлобальные переменные._GЭто глобальное внутреннее хранилище, предоставляемое рабочим потоком FMZ, которое позволяет обмениваться данными между любыми узлами и любыми потоками.
Это очень просто:
javascript
// 保存数据
_G("变量名", 值)
// 读取数据
_G("变量名")
Но особое внимание должно быть уделено:_GПеременные в этом файле сохраняются и не удаляются даже при перезагрузке жесткого диска. Если вы обнаружите, что ошибочно зачитываете старые данные, вам нужно будет установить их вручную._G("变量名",null)Для удаления, или просто для удаления диска, чтобы создать его заново.
Q7: Когда нужно использовать JSON.stringify?
В процессе обработки сложных данных часто требуется использоватьJSON.stringifyМетод . Этот метод позволяет преобразовывать сложные объекты и массивы в текстовые строки, что особенно полезно при передаче данных узлу ИИ, поскольку ИИ понимает только ввод в текстовом формате.
Четвертое: передача данных кодовым узлом
Q8: Должны ли кодовые узлы возвращать данные?
Да, это очень важное требование.returnВозвращает данные, чтобы сохранить передачу данных между узлами. Даже если логика вашего кода не требует вывода каких-либо данных, возвращает пустой массив:
javascript
return {}
Если забыть return, то последующие узлы не смогут получить данные, что приведет к прерыванию всего рабочего потока.
Q9: Как обрабатывать многочисленные данные, выходящие из узлов?
Если один из ваших узлов выводит много данных, например, получает 10 новостей, и вам нужно обрабатывать их в комплексе, а не отдельно, тогда это не может быть передано непосредственно следующему узлу, необходимо использовать объединенный узел или агрегированный узел, чтобы объединить несколько данных в пакет.
Преимущество этого заключается в четкой структуре данных и удобстве последующей обработки узлов. Например, для передачи нескольких новостей в анализ ИИ необходимо сначала объединить их в один массив, чтобы ИИ мог видеть всю информацию за один раз.
Конфигурация и дебютирование узлов ИИ
Q10: Что следует проверить в случае ошибки в узле ИИ?
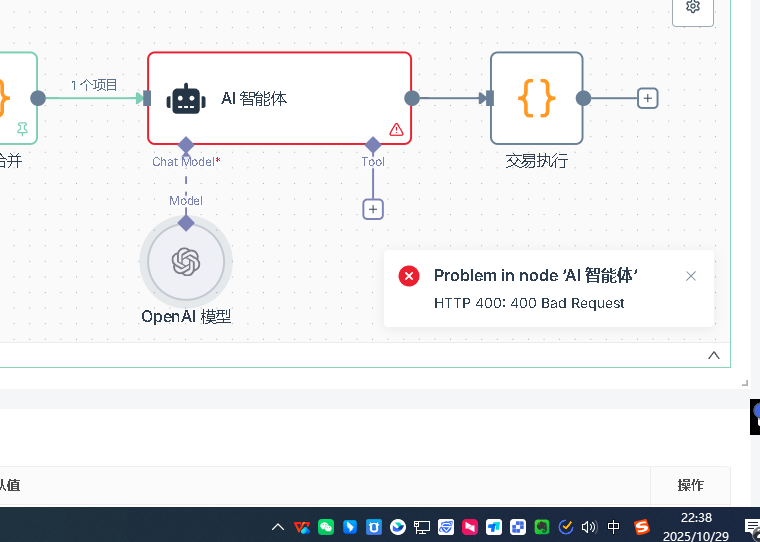
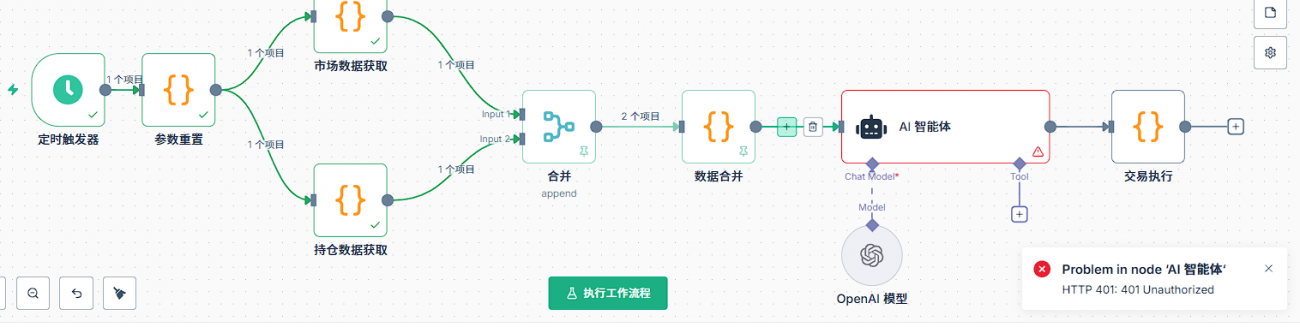
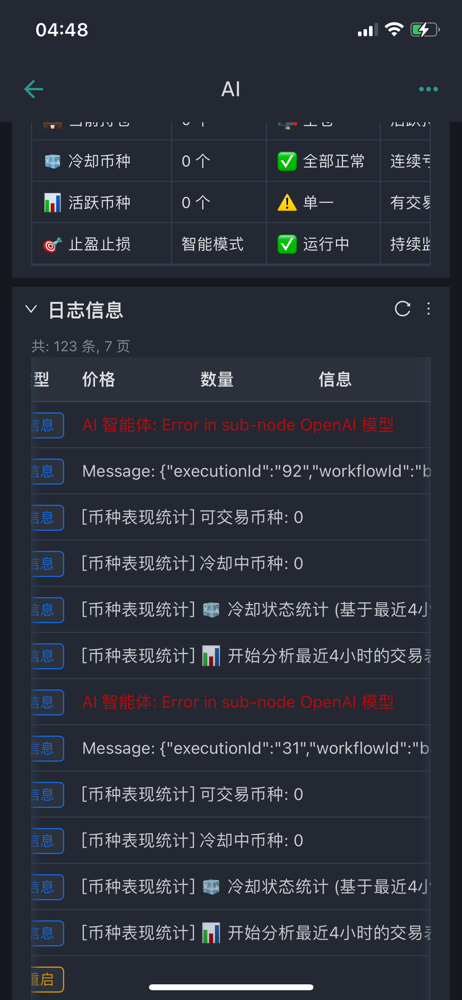
Первое, что нужно сделать, это установить базовые настройки для узлов ИИ. Для узлов ИИ необходимо добавить модели модели, в которых необходимо установить учетные данные. Первое, что нужно сделать, это создать новые учетные данные, которые должны содержать две ключевые данные: API-key и base url. API-key - это ключ, который вы запросили на соответствующей платформе, а base url - это адрес запроса API.
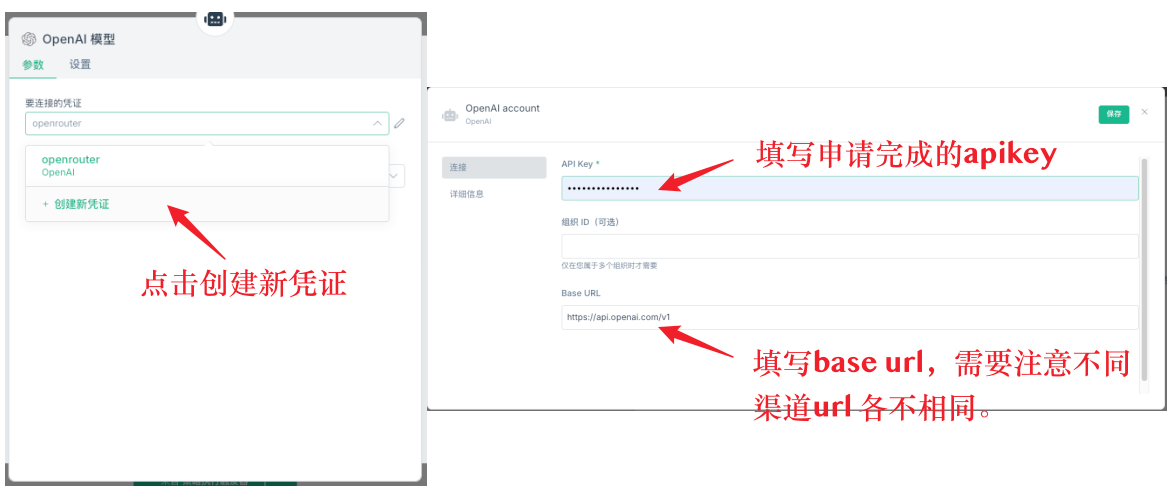
Q11: Какой сервис API лучше использовать?
Не рекомендуется использовать прямой API deepseek, так как ответ медленный, легко задерживается, а объем ограничен. Рекомендуется использовать OpenRouter, который может подключаться к различным крупным моделям, для большей стабильности и скорости.
Q12: Есть ли плата за использование ИИ?
Да, вызовы ИИ стоят денег, и каждый запрос потребляет токены. В случае неудачи вызова необходимо проверить наличие достаточного баланса на счету. Рекомендуется использовать дешевую модель на этапе тестирования логики стратегии, чтобы убедиться, что логика стратегии правильная, а затем перейти на более мощную модель.
Q13: Как написать эффективный инструктивный язык для искусственного интеллекта?
Это искусство, которое требует оптимизации в соответствии с характеристиками различных макромоделей. Например, Грок более радикален, Клод более осторожен, DeepSeek имеет естественную склонность к многообразию из-за обучения A-долевым данным. Понимание этих характеристик позволяет писать более эффективные запросы.
Шестое: стабильность и ветроуправление модели ИИ
Q14: Стабильность принятия решений в модели ИИ?
Модели ИИ пока не полностью устойчивы. Хотя ИИ может повысить качество принятия решений в стратегии, он также может привести к ошибочным выводам. Различные рыночные условия, разные пресс-релизы и даже тот же ввод могут получать разные выводы в разное время. Эта неопределенность является присущей ИИ.
Q15: Что следует учитывать при использовании стратегий ИИ?
При использовании стратегии ИИ обязательно добавляйте строгие меры контроля риска. Например, установите максимальный лимит убытков на одну сделку, установите верхний предел общего положения, включите логику остановки убытков, не позволяйте ИИ полностью контролировать средства.
ИИ должен быть вашим инструментом для принятия решений, а не объектом полномочных полномочий. Искусственный контроль и контроль риска всегда не могут отсутствовать. По мере развития технологий ИИ модели становятся все более стабильными, но на данном этапе разумно быть осторожным.
Особенности отслеживания стратегий ИИ
Q16: Можно ли отследить стратегию, включающую ИИ?
Необходимо понимать, что стратегии, включающие ИИ, имеют большую специфику в отслеживании. Обычные стратегии могут использовать исторические данные для случайного отслеживания, но стратегии ИИ не могут.
Почему? Потому что каждый вызов ИИ потребляет токены, что приводит к реальным расходам. Если вы используете исторические данные за год, вы можете использовать тысячи вызовов ИИ, что будет очень дорого.
FMZ разработал механизм, чтобы защитить ваши кошельки: в режиме обратной измерения, ИИ-узлы будут использовать только три реальных вызова, а затем будут использовать данные с их кэша. Таким образом, результаты обратной измерения являются лишь отсылкой и не могут представлять истинное качество принятия решений ИИ.
Q17: Искусственный интеллект может отслеживать новости с помощью стратегий, основанных на последних новостях?
Если ваша стратегия призывает последние новости, то обратная связь не имеет смысла, потому что вы используете данные прошлых K-линий, но читаете текущие новости, и эти два времени совершенно не совпадают, поэтому обратная связь не имеет смысла.
Q18: Как же тогда тестировать стратегию ИИ?
Рекомендуемый метод заключается в следующем: тестирование на практике с небольшим количеством денег, с небольшими циклами, наблюдение за качеством принятия решений и эффективностью стратегии ИИ в течение некоторого времени, после подтверждения стабильности и постепенного увеличения финансирования. Для стратегии ИИ проверка на практике гораздо важнее, чем историческая проверка.
Конфигурация узлов HTTP и MCP
Q19: Что делать, если HTTP-узел не может получить данные?
HTTP-ноты и MCP-ноты обычно используются для получения внешних данных, но многие API-сервисы требуют ключа для доступа. Если вы сконфигурировали HTTP-запросы, но не получаете данных, проверьте, требуется ли API-ключ, правильно ли настроена информация об аутентификации. Некоторые API также ограничены частотой запросов, и если их вызвать слишком часто, то они будут ограничены или даже заблокированы.
Вопрос 20: Как повысить стабильность получения внешних данных?
MCP-узлы более мощные и могут подключаться к различным услугам структурированных данных, но их конфигурация также более сложная. Необходимо правильно настроить конечные точки сервиса, методы аутентификации, параметры запросов и т. Д. Рекомендуется сначала использовать HTTP-узлы для тестирования API на нормальный доступ, подтвердить формат данных, а затем интегрировать их в рабочий поток.
Кроме того, для повышения стабильности, можно добавить к этим узлам механизм повторной попытки с неудачей. В настройках узла запускается повторная попытка, устанавливается количество повторных попыток и интервал времени, так что временные проблемы с сетью не приводят к неудаче всего рабочего потока.
Проблемы совместимости кода
Q21: Можно ли использовать FMZ-процесс и код n8n?
Рабочий поток Inventor был разработан на основе открытого программного обеспечения n8n, но его код не может быть использован непосредственно друг на друга. Если вы найдете код рабочего потока n8n в Интернете, его непосредственное вставление в FMZ не будет работать, и его нужно будет изменить в соответствии с API и спецификациями узлов FMZ. В свою очередь, код рабочего потока FMZ не может быть использован непосредственно на n8n.
Основные отличия заключаются в том, что FMZ сделал настройки для некоторых узлов, параметры и формат вывода отличаются. Если вы хотите перенести код, вам нужно тщательно проверить конфигурацию и вызовы функций каждого узла, чтобы убедиться, что он соответствует спецификациям целевой платформы.
Подвести итог
Это ответы на часто задаваемые вопросы разработчиков по количественным рабочим потокам. Мы охватываем все аспекты от конфигурации среды, узловых механизмов, чтения данных, спецификации кода, вызова ИИ до тестирования обратной связи, которые являются частыми проблемами в реальной жизни.
Но квантовый трейдинг - это процесс постоянного обучения, новые проблемы будут появляться постоянно. Не отчаивайтесь, сначала ознакомьтесь с официальными документами FMZ, поищите дискуссии в сообществе, многие проблемы уже встречались с другими людьми.
Помните: проблемы - лучшие учителя, и с каждым решением проблемы вы будете понимать рабочий процесс еще глубже. Надеюсь, что эта FAQ поможет вам более эффективно использовать стратегию количественной разработки рабочего процесса!


- 1