Первоначальное изучение применения Python Crawler на FMZ Crawling Binance Содержание объявления
Автор:Нинабадасс., Создано: 2022-04-08 15:47:43, Обновлено: 2022-04-13 10:07:13Первоначальное изучение применения Python Crawler на FMZ Crawling Binance Содержание объявления
Недавно я просмотрел наши форумы и Дайджест, и нет никакой соответствующей информации о сканере Python. Основываясь на духе FMZ всеобъемлющего развития, я просто пошел узнать о концепциях и знаниях сканера. После того, как я узнал об этом, я обнаружил, что еще многое предстоит узнать о
Спрос
Для трейдеров, которые любят торговлю IPO, они всегда хотят получить информацию о листинге платформы как можно скорее. Очевидно, нереально постоянно ручно смотреть на веб-сайт платформы. Затем вам нужно использовать скрипт сканера для мониторинга страницы объявлений платформы и обнаружения новых объявлений, чтобы быть уведомленным и напомненным в первый раз.
Первоначальное исследование
Используйте очень простую программу в качестве начала (действительно мощные скрипты сканеров намного сложнее, поэтому не торопитесь). Логика программы очень проста, то есть позвольте программе непрерывно посещать страницу объявлений платформы, анализировать полученный HTML-контент и обнаруживать, обновляется ли содержание указанного ярлыка.
Внедрение кода
Вы можете использовать некоторые полезные структуры сканера. Учитывая, что требование очень простое, вы также можете писать напрямую.
Библиотеки Python, которые будут использоваться:requests, который можно рассматривать просто как библиотеку, используемую для доступа к веб-страницам.bs4, который можно рассматривать просто как библиотеку, используемую для анализа HTML-кода веб-страниц.
Код:
from bs4 import BeautifulSoup
import requests
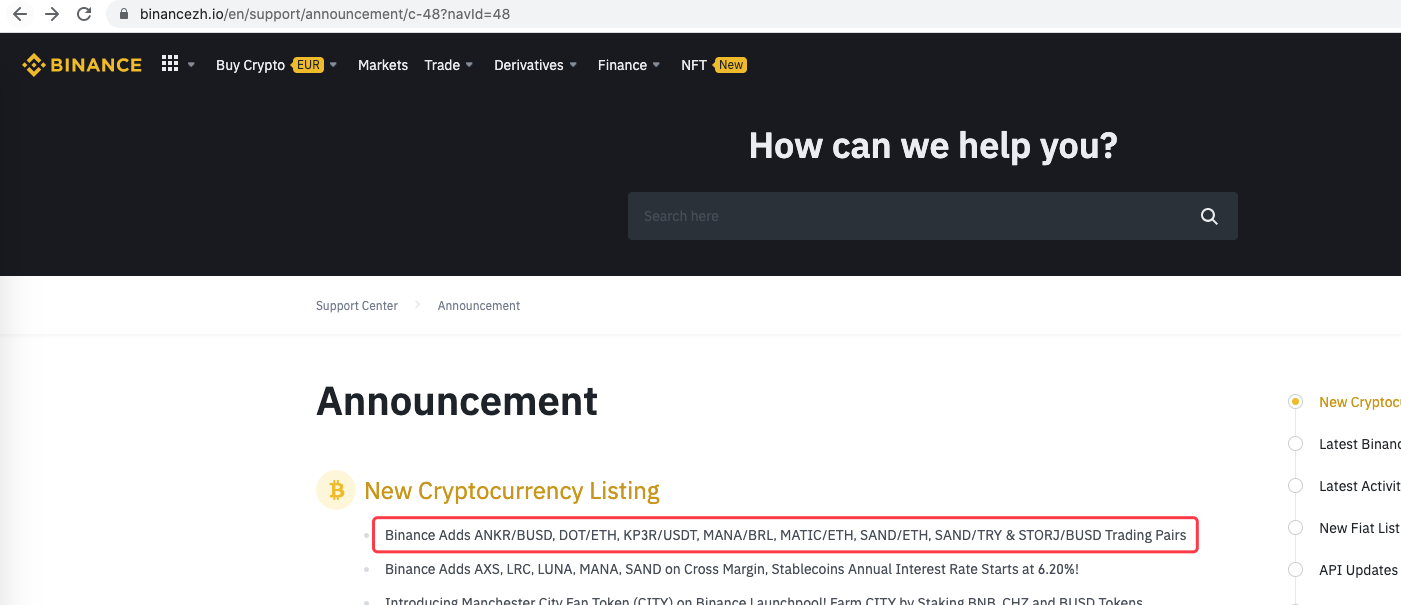
urlBinanceAnnouncement = "https://www.binancezh.io/en/support/announcement/c-48?navId=48" # Binance announcement web page address
def openUrl(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
r = requests.get(url, headers=headers) # use "requests" library to access url, namely the Binance announcement web page address
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # if the access succeeds, return the text of the page content
else:
Log("failed {}".format(url))
def main():
preNews_href = ""
lastNews = ""
Log("watching...", urlBinanceAnnouncement, "#FF0000")
while True:
ret = openUrl(urlBinanceAnnouncement)
if ret:
soup = BeautifulSoup(ret, 'html.parser') # parse the page text into objects
lastNews_href = soup.find('a', class_='css-1ej4hfo')["href"] # find specified lables, to obtain href
lastNews = soup.find('a', class_='css-1ej4hfo').get_text() # obtain the content in the label
if preNews_href == "":
preNews_href = lastNews_href
if preNews_href != lastNews_href: # the label change detected, namely the new announcement generated
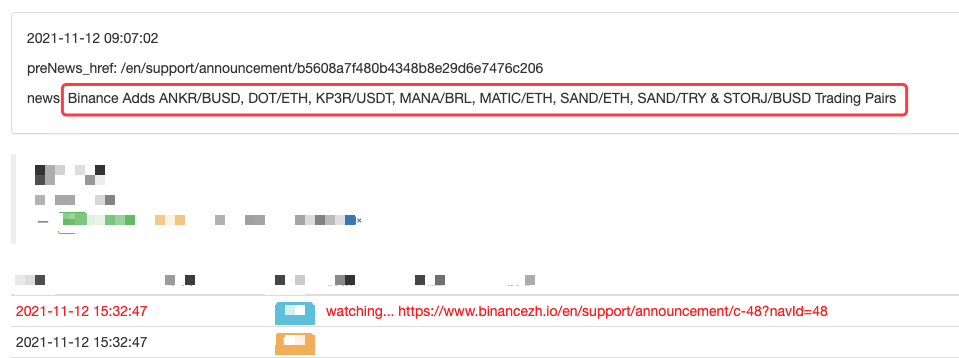
Log("New Cryptocurrency Listing update!") # print the prompt message
preNews_href = lastNews_href
LogStatus(_D(), "\n", "preNews_href:", preNews_href, "\n", "news:", lastNews)
Sleep(1000 * 10)
Операция
Вы даже можете расширить его, например, обнаружение новых объявлений, анализ новых валютных символов и автоматический заказ торговли IPO.
- Отменить печать журнала
- Отменить все незавершенные заказы в текущей валюте
- Быстрый запуск FMZ Quant Trading Platform APP
- Реализовать простой бот контроля за заказами криптовалютного спота
- ФМЗ - платформа для оплаты услуг
- Криптовалютный контракт Простой бот для контроля за заказами
- Если вы хотите получить соответствующий временной пояс, используйте getdepth
- Игнорировано, решено
- Вопрос о номинале
- Пример проектирования стратегии dYdX
- Исследования по разработке стратегии хеджирования и примеры ожидаемых спотовых и фьючерсных ордеров
- Современная ситуация и рекомендуемая стратегия использования ставки финансирования
- Стратегия двойной перемещающейся средней точки прерывания криптовалютных фьючерсов (обучение)
- Стратегия двойной скользящей средней криптовалютной валюты со множественным символом (Teaching)
- Реализация индикатора Фишера в JavaScript и планирование на FMZ
- Хранитель
- 2021 Криптовалютный обзор TAQ и самая простая пропущенная стратегия 10-кратного увеличения
- Фьючерсы на криптовалюты с множественным символом ART-стратегии (обучение)
- Фьючерсы на криптовалюты Мартингейл стратегия
- Функция Getrecords не может получить строку K в секундах