
1. Введение
В предыдущей статье было представлено использование сети LSTM для прогнозирования цен Bitcoin https://www.fmz.com/digest-topic/4035. Как упоминалось в статье, это всего лишь небольшой проект для практики и ознакомления с RNN и pytorch . В этой статье будет представлено использование методов обучения с подкреплением для непосредственного обучения торговым стратегиям. Модель обучения с подкреплением представляет собой PPO с открытым исходным кодом от OpenAI, а среда основана на стиле спортзала. Для облегчения понимания и тестирования модель LSTM PPO и среда бэктестинга написаны напрямую, без использования готовых пакетов.
PPO (полное название Proximal Policy Optimization) — это оптимизационное улучшение Policy Graident, то есть градиента политики. Тренажерный зал также выпущен OpenAI. Он может взаимодействовать с сетью политик и получать обратную связь о текущем состоянии и вознаграждении среды. Это похоже на упражнение по обучению с подкреплением, которое использует модель LSTM PPO для непосредственного совершения покупки, продажи или отсутствия операции на основе Рыночная информация о Bitcoin. Инструкции даются средой бэктестинга, и модель постоянно оптимизируется посредством обучения для достижения цели прибыльности стратегии.
Чтение этой статьи требует определенных знаний Python, pytorch и глубокого обучения с подкреплением DRL. Но не беда, если вы не знаете, как это сделать. Легко научиться и начать с кодом, приведенным в этой статье. Эта статья подготовлена FMZ, изобретателем цифровой валютной количественной торговой платформы (www.fmz.com). Добро пожаловать в группу QQ: 863946592 для общения.
2. Данные и учебные материалы
Данные о цене биткоина предоставлены платформой количественной торговли FMZ Generation: https://www.quantinfo.com/Tools/View/4.html.
Статья об использовании DRL+gym для обучения торговым стратегиям: https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4
Несколько примеров начала работы с pytorch: https://github.com/yunjey/pytorch-tutorial
В этой статье будет напрямую использоваться эта короткая реализация модели LSTM-PPO: https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py
Статьи о PPO: https://zhuanlan.zhihu.com/p/38185553
Больше статей о DRL: https://www.zhihu.com/people/flood-sung/posts
Что касается спортзала, то эта статья не требует установки, но обучение с подкреплением очень распространено: https://gym.openai.com/
3.LSTM-PPO
Для более глубокого объяснения PPO вы можете изучить предыдущие ссылки. Здесь просто введение в простую концепцию. В предыдущем выпуске сеть LSTM только предсказывала цену. То, как покупать и продавать транзакции на основе этой предсказанной цены, должно быть реализовано отдельно. Естественно, можно представить, что было бы более прямолинейно напрямую выводить действия покупки и продажи , верно? Политика Graident похожа на это. Она может давать вероятность различных действий на основе входной информации об окружающей среде s. Потеря LSTM — это разница между прогнозируемой ценой и фактической ценой, тогда как потеря PG равна -log(p)*Q, где p — вероятность того, что действие будет выведено, а Q — ценность действия (такая как оценка вознаграждения). Интуитивное объяснение заключается в том, что если ценность действия выше, сеть должна вывести более высокую вероятность чтобы уменьшить потери. Хотя PPO намного сложнее, принцип схож. Ключ в том, как лучше оценить ценность каждого действия и как лучше обновить параметры.
Ниже приведен исходный код LSTM-PPO, который можно понять в сочетании с предыдущей информацией:
python
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
#模型的超参数
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # 也可以改为GPU版本
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
#输出各个动作的概率,由于是LSTM网络还要包含hidden层的信息,可以参考上一期文章
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
#价值函数,用于评价当前局面的好坏,所以只有一个输出
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
#准备训练数据
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) #同时训练了价值网络和决策网络
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. Среда бэктестинга биткоинов
Следуя формату спортзала, есть метод сброса инициализации, шаговое действие ввода, и возвращаемый результат (следующее состояние, выгода действия, завершено ли оно, дополнительная информация). Вся среда бэктеста составляет всего 60 строк, которые могут быть Изменено вами. Сложная версия, конкретный код:
python
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks #初始的比特币数量
self.initial_balance = initial_balance #初始的资产
self.current_time = 0 #回测的时间位置
self.commission = commission #易手续费
self.done = False #回测是否结束
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) #标准化方法,简单的收益率标准化
self.mode = all_data # 是否为抽样回测模式
self.sample_length = 500 # 抽样长度
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
#action即策略采取的动作,这里将更新账户和计算reward
done = False
if action == 0: #持有
pass
elif action == 1: #买入
buy_value = self.balance*0.5
if buy_value > 1: #余钱不足,不操作账户
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: #卖出
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # 每回合的reward是新增收益
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. Несколько примечательных деталей
Почему на начальном счете есть монеты?
Формула расчета доходности в среде бэктестинга следующая: Текущая доходность = Текущая стоимость счета - Начальная текущая стоимость счета. Это означает, что если цена биткоина падает и стратегия продает монеты, стратегия фактически должна быть вознаграждена, даже если общая стоимость счета уменьшится. Если период бэктестинга длительный, то первоначальный счет может не пострадать сильно, но в начале это все равно будет иметь большое влияние. Расчет относительной доходности гарантирует, что каждая правильная операция получит положительное вознаграждение.
Почему мы исследуем рынок во время обучения?
Общий объем данных составляет более 10 000 К-линий. Если каждый раз запускать полный цикл, это займет много времени, и стратегия каждый раз будет сталкиваться с одной и той же ситуацией, что может привести к переобучению. 500 баров рисуются каждый раз как данные бэктеста. Хотя переобучение все еще возможно, стратегия сталкивается с более чем 10 000 различных возможных стартов.
Что делать, если у вас нет монет или денег?
Эта ситуация не рассматривается в среде бэктеста. Если монета распродана или минимальный объем транзакции не достигнут, выполнение операции продажи в это время фактически эквивалентно выполнению никакой операции. Если цена падает, согласно относительному Метод расчета доходности по-прежнему основан на положительном вознаграждении стратегии. Влияние этой ситуации заключается в том, что когда стратегия определяет, что рынок падает и оставшиеся на счете монеты не могут быть проданы, становится невозможно отличить действия по продаже от отсутствия операции, но это не оказывает никакого влияния на собственное суждение стратегии о рынок.
Зачем возвращать информацию об учетной записи в качестве статуса?
Модель PPO имеет сеть ценностей, используемую для оценки стоимости текущего состояния. Очевидно, если стратегия определяет, что цена будет расти, все состояние будет иметь положительную стоимость только в том случае, если текущий счет содержит биткоины, и наоборот. Таким образом, информация о счетах является важной основой для оценки сети создания стоимости. Обратите внимание, что информация о прошлых действиях не возвращается в виде состояния, что, по моему личному мнению, бесполезно для оценки ценности.
При каких обстоятельствах операция не будет выполнена?
Когда стратегия определяет, что прибыль от купли-продажи не может покрыть комиссию за транзакцию, она должна вернуться к отсутствию действий. Хотя предыдущее описание неоднократно использовало стратегии для определения ценовых трендов, это было сделано только ради простоты понимания. Фактически, эта модель PPO не делает никаких прогнозов о рынке, а только выводит вероятности трех действий.
6. Сбор данных и обучение
Как и в предыдущей статье, данные получены в следующем формате: часовая K-линия торговой пары BTC_USD на бирже Bitfinex с 07.05.2018 по 27.06.2019:
python
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
Поскольку использовалась сеть LSTM, время обучения было очень долгим, поэтому я перешел на версию на GPU, которая была примерно в 3 раза быстрее.
python
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 #记录总收益
profit_list = [] #记录每次训练收益
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. Результаты обучения и анализ
После долгого ожидания:

Сначала давайте взглянем на рыночные тенденции обучающих данных. В целом, первая половина была длительным падением, а вторая половина была сильным отскоком.
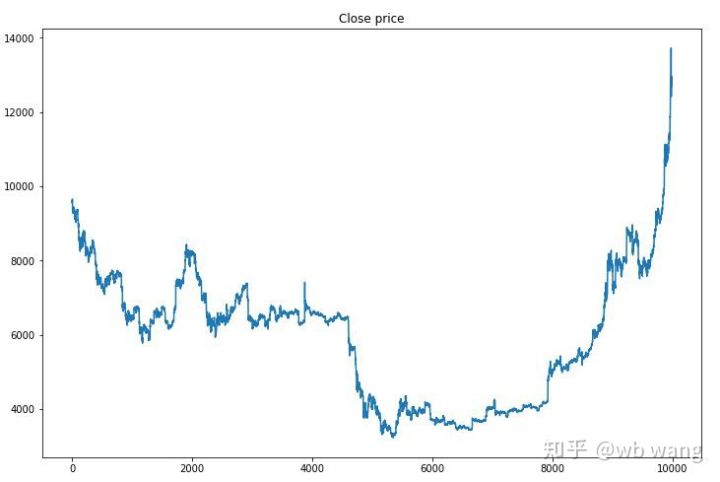
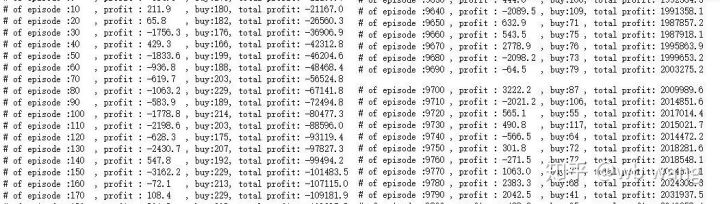
На ранних этапах обучения происходит много операций по покупке, а прибыльных раундов практически нет. К середине периода обучения количество операций по покупке постепенно уменьшалось, а вероятность получения прибыли становилась все больше, однако вероятность убытка все еще оставалась высокой.
Сглаживая доход за раунд, результаты получаются следующими:
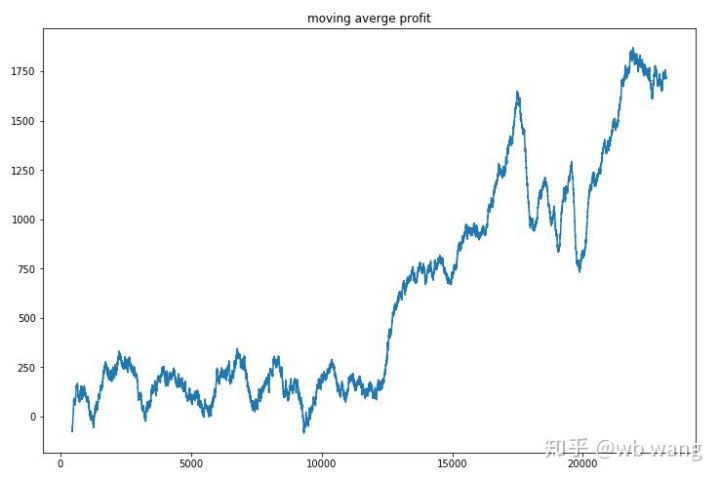
Стратегия быстро избавилась от отрицательных возвратов на ранних этапах, но колебания были большими. Только после 10 000 раундов возвраты начали быстро расти. В целом обучение модели было сложным.
После завершения финального обучения позвольте модели снова запустить все данные, чтобы увидеть, как она работает. В течение этого периода запишите общую рыночную стоимость счета, количество удерживаемых биткойнов, долю стоимости биткойнов и общий доход. .
Во-первых, это общая рыночная стоимость. Общая выручка схожа, поэтому я не буду ее здесь публиковать:
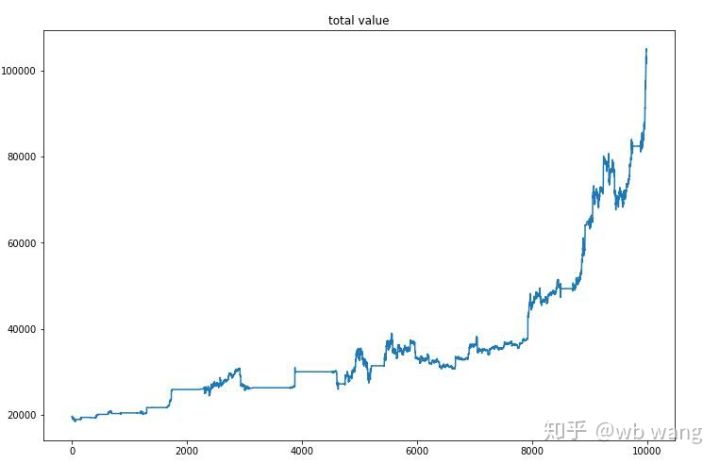
Общая рыночная стоимость медленно росла в течение раннего медвежьего рынка и также продолжала расти в течение более позднего бычьего рынка, однако периодические потери все еще имели место.
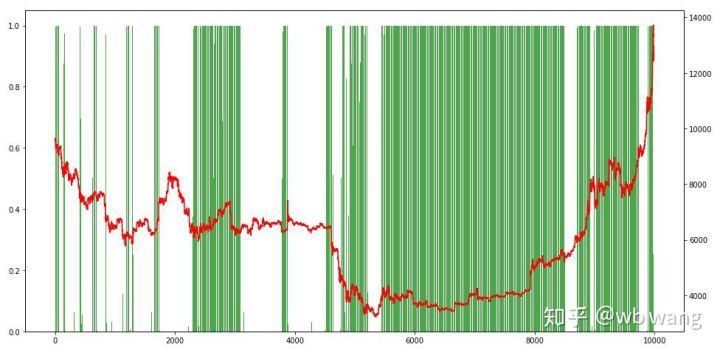
Наконец, давайте посмотрим на пропорцию позиций. Левая ось графика — пропорция позиций, а правая — ситуация на рынке. Можно предварительно определить, что модель переобучена. Частота позиций была низкой на раннем медвежьем рынке, а частота позиций была очень высокой на дне рынка. Мы также видим, что модель не научилась удерживать позиции долгое время и всегда быстро продает.
8. Анализ тестовых данных
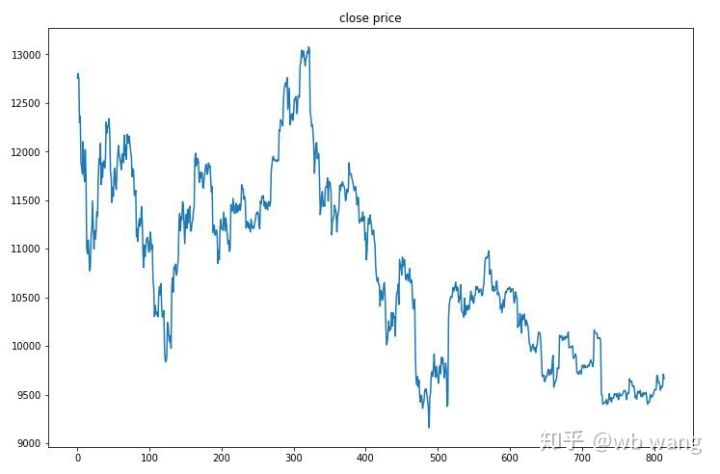
Тестовые данные были получены с часового рынка биткоинов с 27.06.2019 по настоящее время. Как видно на рисунке, цена снизилась с 13 000 долларов в начале до более чем 9 000 долларов на сегодняшний день, что является отличным испытанием для модели.
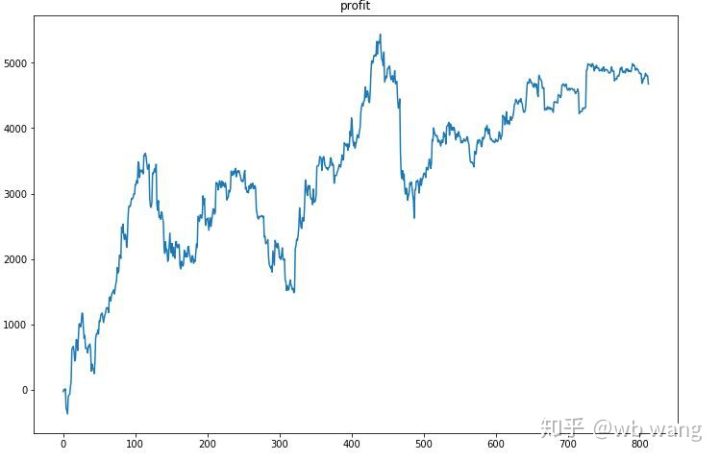
Прежде всего, конечная относительная доходность оказалась неудовлетворительной, но и потерь не было.
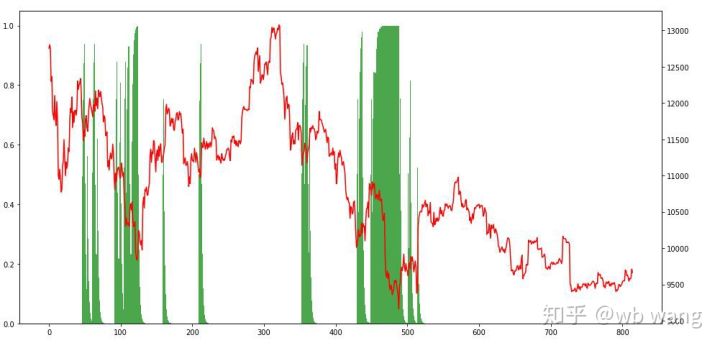
Глядя на позиции, мы можем предположить, что модель склонна покупать после резкого падения и продавать после отскока. Рынок биткоинов в последнее время колебался очень мало, и модель находилась в короткой позиции.
9. Резюме
В этой статье используется метод глубокого обучения с подкреплением PPO для обучения автоматического торгового робота Bitcoin и делаются некоторые выводы. Из-за ограниченного времени, в модели еще есть некоторые области, которые можно улучшить. Приглашаются все желающие к обсуждению. Самый большой урок заключается в том, что стандартизация данных — правильный метод. Не используйте такие методы, как масштабирование, иначе модель быстро запомнит взаимосвязь между ценой и рыночными условиями и впадет в переобучение. После нормализации скорость изменения становится относительными данными, что затрудняет запоминание моделью ее взаимосвязи с рынком и заставляет ее находить связь между скоростью изменения и подъемами и падениями.
Предыдущие статьи:
Некоторые публичные стратегии обмена на платформе FMZ Inventor Quantitative Platform: https://zhuanlan.zhihu.com/p/64961672
Курс количественной торговли цифровой валютой от NetEase Cloud Classroom, всего 20 юаней: https://study.163.com/course/courseMain.htm?courseId=1006074239&share=2&shareId=400000000602076
Я опубликовал высокочастотную стратегию, которая когда-то была очень прибыльной: https://www.fmz.com/bbs-topic/1211


profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.current_time,4]) 有bug
应该是:profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.start,4])
profit = self.value - (self.initial_balance+self.initial_stocksself.df.iloc[self.current_time,4]) 有bug
应该是:profit = self.value - (self.initial_balance+self.initial_stocksself.df.iloc[self.start,4])




GPU版
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class PPO(nn.Module):
def __init__(self):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(8,64)
self.lstm = nn.LSTM(64,32)
self.fc_pi = nn.Linear(32,3)
self.fc_v = nn.Linear(32,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 64)
x, lstm_hidden = self.lstm(x, hidden )
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 64)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float).to(device), torch.tensor(a_lst).to(device).to(device), \
torch.tensor(r_lst).to(device), torch.tensor(s_prime_lst, dtype=torch.float).to(device), \
torch.tensor(done_lst, dtype=torch.float).to(device), torch.tensor(prob_a_lst).to(device)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.to(device).detach(), h2.to(device).detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.cpu().detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float).to(device)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach())
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
- 1