
1. تعارف
پچھلے مضمون میں Bitcoin کی قیمتوں کا اندازہ لگانے کے لیے LSTM نیٹ ورک کا استعمال متعارف کرایا گیا تھا https://www.fmz.com/digest-topic/4035 جیسا کہ مضمون میں بتایا گیا ہے، یہ RNN اور pytorch سے واقفیت حاصل کرنے کے لیے صرف ایک چھوٹا منصوبہ ہے۔ . یہ مضمون تجارتی حکمت عملیوں کو براہ راست تربیت دینے کے لیے کمک سیکھنے کے طریقوں کے استعمال کو متعارف کرائے گا۔ کمک سیکھنے کا ماڈل اوپن اے آئی کے ذریعہ پی پی او اوپن سورس ہے، اور ماحول جم کے انداز پر مبنی ہے۔ تفہیم اور جانچ کی سہولت کے لیے، LSTM PPO ماڈل اور بیک ٹیسٹنگ جم ماحول براہ راست تیار شدہ پیکجوں کو استعمال کیے بغیر لکھا جاتا ہے۔
PPO، Proximal Policy Optimization کا پورا نام، پالیسی گریڈینٹ یعنی پالیسی گریڈینٹ کی ایک اصلاحی بہتری ہے۔ جیم کو اوپن اے آئی کے ذریعہ بھی جاری کیا گیا ہے اور یہ ماحول کی موجودہ حالت اور انعام کے بارے میں رائے دے سکتا ہے جو کہ LSTM PPO ماڈل کو براہ راست خریدنے، فروخت کرنے یا کوئی آپریشن کرنے کے لیے استعمال کرتا ہے۔ Bitcoin کی مارکیٹ کی معلومات بیک ٹیسٹنگ ماحول کے ذریعہ دی جاتی ہیں، اور حکمت عملی کے منافع کے مقصد کو حاصل کرنے کے لیے ماڈل کو مسلسل تربیت کے ذریعے بہتر بنایا جاتا ہے۔
اس مضمون کو پڑھنے کے لیے Python، pytorch، اور DRL گہری کمک سیکھنے میں ایک خاص بنیاد کی ضرورت ہے۔ لیکن اس سے کوئی فرق نہیں پڑتا اگر آپ نہیں جانتے کہ اسے کیسے کرنا ہے اس مضمون میں دیے گئے کوڈ کے ساتھ سیکھنا اور شروع کرنا آسان ہے۔ یہ مضمون FMZ کی طرف سے تیار کیا گیا ہے، جو کہ ڈیجیٹل کرنسی کوانٹیٹیو ٹریڈنگ پلیٹ فارم (www.fmz.com) کے موجد ہے QQ گروپ میں خوش آمدید: 863946592 مواصلات کے لیے۔
2. ڈیٹا اور سیکھنے کے حوالے
بٹ کوائن کی قیمت کا ڈیٹا FMZ موجد مقداری تجارتی پلیٹ فارم سے آتا ہے: https://www.quantinfo.com/Tools/View/4.html
تجارتی حکمت عملیوں کی تربیت کے لیے DRL+gym کے استعمال سے متعلق ایک مضمون: https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4
pytorch کے ساتھ شروع کرنے کی کچھ مثالیں: https://github.com/yunjey/pytorch-tutorial
یہ مضمون LSTM-PPO ماڈل کے اس مختصر نفاذ کو براہ راست استعمال کرے گا: https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py
پی پی او کے بارے میں مضامین: https://zhuanlan.zhihu.com/p/38185553
DRL کے بارے میں مزید مضامین: https://www.zhihu.com/people/flood-sung/posts
جم کے بارے میں، اس مضمون کو اسے انسٹال کرنے کی ضرورت نہیں ہے، لیکن کمک سیکھنا بہت عام ہے: https://gym.openai.com/
3.LSTM-PPO
PPO کی گہرائی سے وضاحت کے لیے، آپ پچھلے حوالہ جات کا مطالعہ کر سکتے ہیں، یہاں صرف ایک سادہ تصور کا تعارف ہے۔ پچھلے شمارے میں، LSTM نیٹ ورک نے صرف ایک قیمت کی پیشن گوئی کی تھی کہ اس پیشن گوئی کی قیمت کی بنیاد پر لین دین کو الگ سے لاگو کرنے کی ضرورت ہے، قدرتی طور پر یہ تصور کیا جا سکتا ہے کہ یہ خرید و فروخت کی کارروائیوں کو براہ راست نکالے گی۔ ، ٹھیک ہے؟ پالیسی گریڈنٹ اس طرح ہے یہ ان پٹ ماحولیاتی معلومات کی بنیاد پر مختلف کارروائیوں کا امکان دے سکتا ہے۔ LSTM کا نقصان پیش گوئی کی گئی قیمت اور اصل قیمت کے درمیان فرق ہے، جبکہ PG کا نقصان -log(p) ہے۔*Q، جہاں p ایک عمل کے آؤٹ پٹ ہونے کا امکان ہے، اور Q ایکشن کی قدر ہے (جیسے کہ انعام کا سکور) بدیہی وضاحت یہ ہے کہ اگر کسی عمل کی قدر زیادہ ہے، تو نیٹ ورک کو زیادہ امکان پیدا کرنا چاہیے۔ نقصان کو کم کرنے کے لئے. اگرچہ پی پی او بہت زیادہ پیچیدہ ہے، لیکن کلیدی اس بات میں ہے کہ ہر ایکشن کی قدر کا بہتر انداز میں کیسے جائزہ لیا جائے اور پیرامیٹرز کو کس طرح بہتر بنایا جائے۔
LSTM-PPO کا سورس کوڈ ذیل میں دیا گیا ہے، جسے پچھلی معلومات کے ساتھ ملا کر سمجھا جا سکتا ہے:
python
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
#模型的超参数
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # 也可以改为GPU版本
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
#输出各个动作的概率,由于是LSTM网络还要包含hidden层的信息,可以参考上一期文章
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
#价值函数,用于评价当前局面的好坏,所以只有一个输出
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
#准备训练数据
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) #同时训练了价值网络和决策网络
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. بٹ کوائن بیک ٹیسٹنگ ماحول
جم کے فارمیٹ کے بعد، ایک ری سیٹ شروع کرنے کا طریقہ ہے، قدم ان پٹ ایکشن، اور واپس آنے والا نتیجہ ہے (اگلی حالت، ایکشن کا فائدہ، چاہے یہ ختم ہو جائے، اضافی معلومات) صرف 60 لائنیں ہو سکتی ہیں۔ پیچیدہ ورژن، مخصوص کوڈ:
python
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks #初始的比特币数量
self.initial_balance = initial_balance #初始的资产
self.current_time = 0 #回测的时间位置
self.commission = commission #易手续费
self.done = False #回测是否结束
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) #标准化方法,简单的收益率标准化
self.mode = all_data # 是否为抽样回测模式
self.sample_length = 500 # 抽样长度
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
#action即策略采取的动作,这里将更新账户和计算reward
done = False
if action == 0: #持有
pass
elif action == 1: #买入
buy_value = self.balance*0.5
if buy_value > 1: #余钱不足,不操作账户
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: #卖出
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # 每回合的reward是新增收益
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. کئی قابل ذکر تفصیلات
ابتدائی اکاؤنٹ میں سکے کیوں ہوتے ہیں؟
بیک ٹیسٹنگ ماحول میں ریٹرن کا حساب لگانے کا فارمولا یہ ہے: کرنٹ ریٹرن = کرنٹ اکاؤنٹ ویلیو - ابتدائی اکاؤنٹ کرنٹ ویلیو۔ اس کا مطلب یہ ہے کہ اگر Bitcoin کی قیمت گر جاتی ہے اور حکمت عملی سککوں کو فروخت کرتی ہے، حکمت عملی کو اصل میں انعام دیا جانا چاہئے چاہے کل اکاؤنٹ کی قیمت کم ہو جائے۔ اگر بیک ٹیسٹنگ کی مدت طویل ہے، تو ابتدائی اکاؤنٹ زیادہ متاثر نہیں ہو سکتا، لیکن پھر بھی شروع میں اس کا بڑا اثر پڑے گا۔ متعلقہ منافع کا حساب لگانا اس بات کو یقینی بناتا ہے کہ ہر درست آپریشن مثبت انعام حاصل کرتا ہے۔
ہم تربیت کے دوران مارکیٹ کا نمونہ کیوں لیتے ہیں؟
ڈیٹا کی کل مقدار 10,000 K-لائنز سے زیادہ ہے اگر ہر بار ایک مکمل سائیکل چلایا جاتا ہے، تو اس میں کافی وقت لگے گا، اور حکمت عملی کو ہر بار بالکل اسی صورت حال کا سامنا کرنا پڑے گا، جس کی وجہ سے اوور فٹنگ ہو سکتی ہے۔ 500 بارز ہر بار بیک ٹیسٹ ڈیٹا کے طور پر تیار کیے جاتے ہیں اگرچہ اوور فٹنگ ابھی بھی ممکن ہے، حکمت عملی کو 10,000 سے زیادہ مختلف ممکنہ آغاز کا سامنا ہے۔
اگر آپ کے پاس سکے یا پیسے نہ ہوں تو کیا کریں؟
اگر سکہ فروخت ہو چکا ہو یا کم از کم لین دین کا حجم نہ ہو تو اس صورت حال پر غور نہیں کیا جاتا ہے، اس وقت فروخت کا عمل انجام دینے کے مترادف ہے اگر قیمت گر جاتی ہے۔ واپسی کے حساب کتاب کا طریقہ، یہ اب بھی حکمت عملی کے مثبت اجر پر مبنی ہے۔ اس صورت حال کا اثر یہ ہوتا ہے کہ جب حکمت عملی یہ طے کرتی ہے کہ مارکیٹ گر رہی ہے اور اکاؤنٹ میں موجود باقی سکے فروخت نہیں کیے جا سکتے، تو فروخت کے عمل اور کوئی آپریشن کے درمیان فرق کرنا ناممکن ہے، لیکن اس کا حکمت عملی کے اپنے فیصلے پر کوئی اثر نہیں پڑتا۔ مارکیٹ
اکاؤنٹ کی معلومات کو اسٹیٹس کے طور پر کیوں واپس کریں؟
PPO ماڈل میں ایک ویلیو نیٹ ورک ہے جو موجودہ حالت کی قدر کا اندازہ لگانے کے لیے استعمال کیا جاتا ہے، ظاہر ہے، اگر حکمت عملی یہ طے کرتی ہے کہ قیمت بڑھنے والی ہے، تو پوری ریاست کو صرف اس صورت میں مثبت قدر حاصل ہوگی جب موجودہ اکاؤنٹ میں Bitcoin ہو، اور اس کے برعکس۔ لہذا، اکاؤنٹ کی معلومات ویلیو نیٹ ورک کو جانچنے کے لیے ایک اہم بنیاد ہے۔ نوٹ کریں کہ ماضی کی کارروائی کی معلومات ریاست کے طور پر واپس نہیں کی جاتی ہیں، جو میں ذاتی طور پر سوچتا ہوں کہ قدر کے تعین کے لیے بیکار ہے۔
کن حالات میں یہ کوئی آپریشن نہیں کرے گا؟
جب حکمت عملی اس بات کا تعین کرتی ہے کہ خرید و فروخت سے حاصل ہونے والا منافع لین دین کی فیس کو پورا نہیں کر سکتا، تو اسے کوئی کارروائی نہیں کرنی چاہیے۔ اگرچہ پچھلی تفصیل میں قیمت کے رجحانات کا تعین کرنے کے لیے بار بار حکمت عملیوں کا استعمال کیا گیا تھا، لیکن یہ صرف سمجھنے میں آسانی کے لیے تھا، یہ PPO ماڈل مارکیٹ کے بارے میں کوئی پیشین گوئی نہیں کرتا، بلکہ صرف تین کارروائیوں کے امکانات کو ظاہر کرتا ہے۔
6. ڈیٹا کا حصول اور تربیت
جیسا کہ پچھلے مضمون میں ہے، ڈیٹا درج ذیل فارمیٹ میں حاصل کیا گیا ہے: BTC_USD ٹریڈنگ جوڑی کی ایک گھنٹے کی K-line Bitfinex ایکسچینج پر 2018/5/7 سے 2019/6/27 تک:
python
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
چونکہ LSTM نیٹ ورک استعمال کیا گیا تھا، تربیت کا وقت بہت طویل تھا، اس لیے میں نے GPU ورژن میں تبدیل کیا، جو تقریباً 3 گنا تیز تھا۔
python
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 #记录总收益
profit_list = [] #记录每次训练收益
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. تربیت کے نتائج اور تجزیہ
طویل انتظار کے بعد:

سب سے پہلے، ٹریننگ ڈیٹا کے مارکیٹ کے رجحانات پر ایک نظر ڈالیں، عام طور پر، پہلا نصف ایک طویل کمی تھی، اور دوسرا نصف ایک مضبوط ریباؤنڈ تھا۔
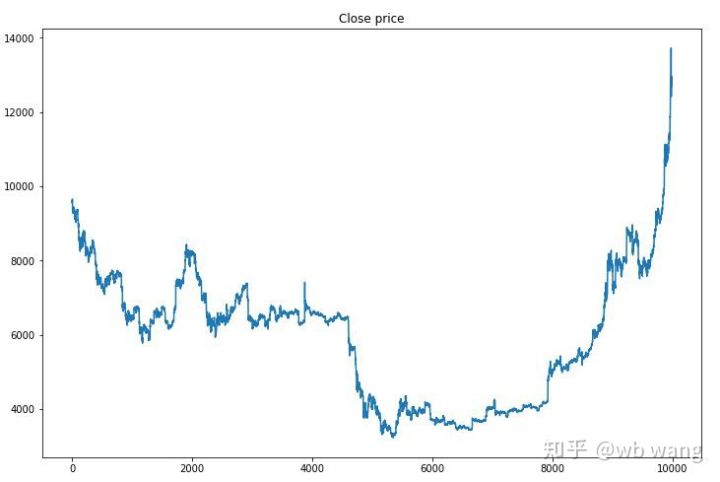
تربیت کے ابتدائی مراحل میں بہت زیادہ خریداری کی کارروائیاں ہوتی ہیں، اور بنیادی طور پر کوئی منافع بخش دور نہیں ہوتا ہے۔ تربیتی مدت کے وسط تک، خریداری کی کارروائیوں کی تعداد بتدریج کم ہوتی گئی اور منافع کا امکان زیادہ سے زیادہ ہوتا گیا، لیکن پھر بھی نقصان کا امکان بہت زیادہ تھا۔
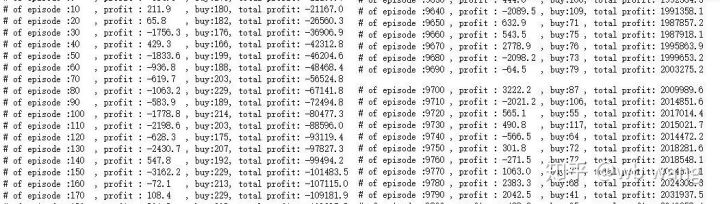
فی راؤنڈ آمدنی کو ہموار کرتے ہوئے، نتائج درج ذیل ہیں:
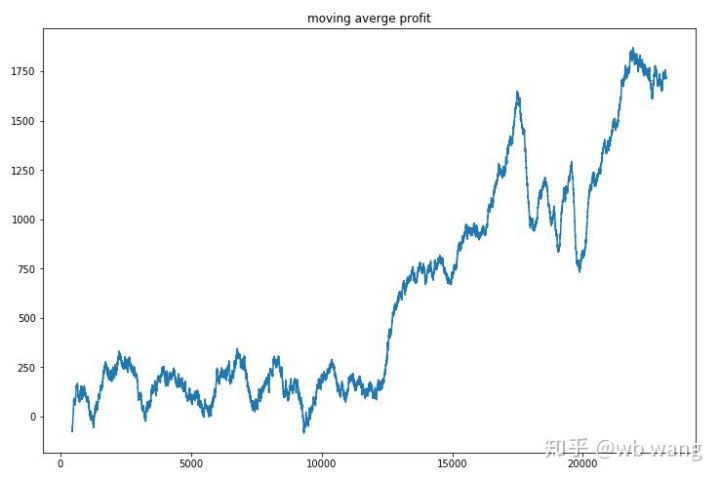
اس حکمت عملی نے ابتدائی مراحل میں منفی ریٹرن سے چھٹکارا حاصل کیا، لیکن اتار چڑھاؤ بڑے تھے جب تک کہ 10,000 راؤنڈز تیزی سے بڑھنے لگے، ماڈل کی تربیت مشکل تھی۔
حتمی تربیت مکمل ہونے کے بعد، ماڈل کو تمام ڈیٹا کو دوبارہ چلانے دیں تاکہ یہ معلوم ہو سکے کہ اس کی کارکردگی کیسی ہے، اکاؤنٹ کی کل مارکیٹ ویلیو، رکھے گئے بٹ کوائنز کی تعداد، بٹ کوائن کی قیمت کا تناسب، اور کل آمدنی ریکارڈ کریں۔ .
سب سے پہلے کل مارکیٹ ویلیو ہے، اس لیے میں اسے یہاں پوسٹ نہیں کروں گا:
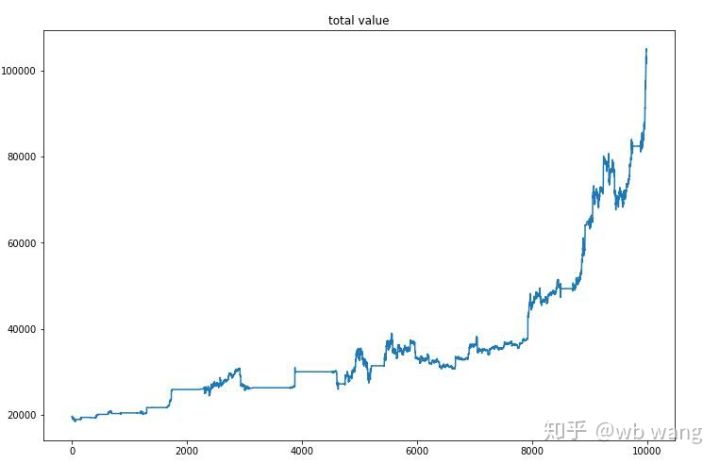
ابتدائی بیئر مارکیٹ کے دوران کل مارکیٹ ویلیو میں آہستہ آہستہ اضافہ ہوا اور بعد میں بیل مارکیٹ کے دوران بھی اضافہ برقرار رہا، لیکن پھر بھی وقفے وقفے سے نقصانات ہوتے رہے۔
آخر میں، ہم پوزیشنوں کے تناسب پر ایک نظر ڈالتے ہیں، اور دائیں محور میں پوزیشنوں کا تناسب ہے، یہ ابتدائی طور پر طے کیا جا سکتا ہے کہ پوزیشنوں کی فریکوئنسی کتنی تھی۔ ابتدائی ریچھ کی مارکیٹ میں کم، اور جب مارکیٹ نیچے تھی تو پوزیشنوں کی تعدد بہت زیادہ تھی۔ ہم یہ بھی دیکھ سکتے ہیں کہ ماڈل نے طویل عرصے تک عہدوں پر رہنا نہیں سیکھا ہے اور ہمیشہ تیزی سے فروخت ہوتا ہے۔
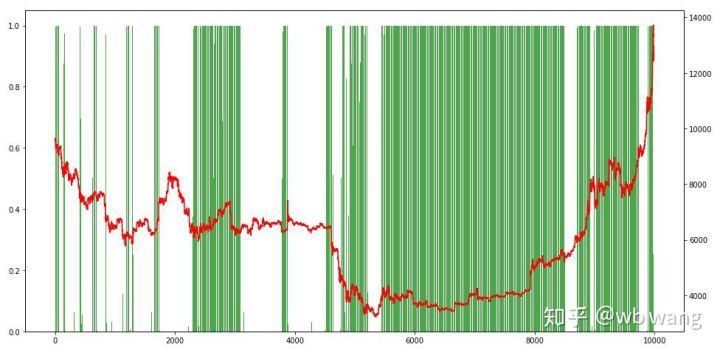
8. ٹیسٹ ڈیٹا تجزیہ
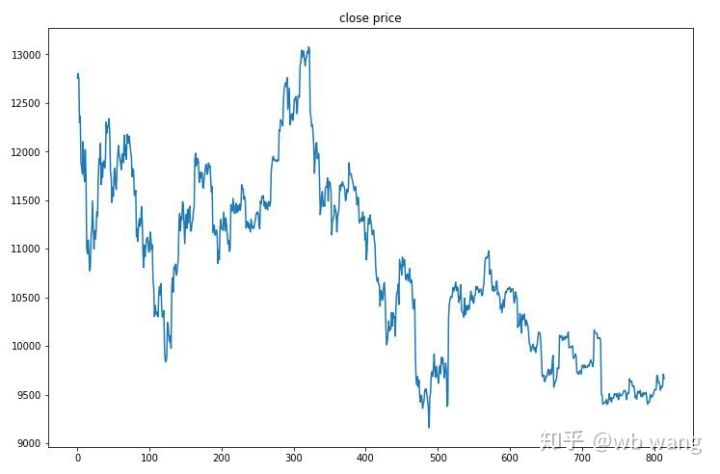
ٹیسٹ ڈیٹا 2019/6/27 سے اب تک ایک گھنٹے کے بٹ کوائن مارکیٹ سے حاصل کیا گیا تھا۔ جیسا کہ اعداد و شمار میں دیکھا جا سکتا ہے، قیمت شروع میں $13,000 سے گر کر آج $9,000 سے زیادہ ہوگئی ہے، جو کہ ماڈل کے لیے ایک بہترین امتحان ہے۔
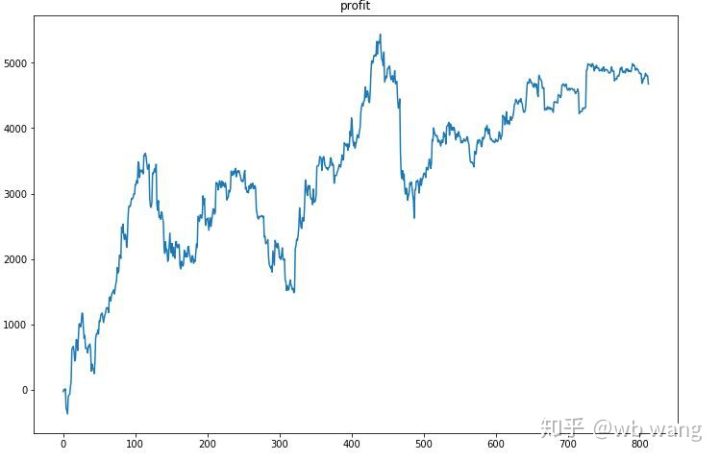
سب سے پہلے، حتمی رشتہ دار واپسی تسلی بخش نہیں تھی، لیکن کوئی نقصان بھی نہیں تھا۔
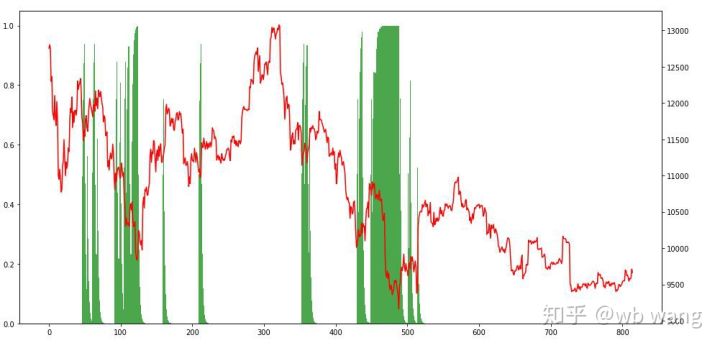
پوزیشنز کو دیکھ کر، ہم اندازہ لگا سکتے ہیں کہ ماڈل تیزی سے گرنے کے بعد خریدتا ہے اور حالیہ دنوں میں، بٹ کوائن مارکیٹ میں بہت کم اتار چڑھاؤ آیا ہے اور ماڈل مختصر پوزیشن میں ہے۔
9. خلاصہ
یہ مضمون بِٹ کوائن آٹومیٹک ٹریڈنگ روبوٹ کو تربیت دینے اور کچھ نتائج اخذ کرنے کے لیے گہری کمک سیکھنے کے طریقہ PPO کا استعمال کرتا ہے۔ محدود وقت کی وجہ سے، اب بھی کچھ ایسے شعبے ہیں جن کو ماڈل میں بہتر بنایا جا سکتا ہے۔ سب سے بڑا سبق یہ ہے کہ ڈیٹا کی معیاری کاری درست طریقہ ہے جیسے کہ اسکیلنگ کے طریقے استعمال نہ کریں، ورنہ ماڈل قیمت اور مارکیٹ کے حالات کے درمیان تعلق کو جلدی سے یاد رکھے گا اور اوور فٹنگ میں پڑ جائے گا۔ نارملائزیشن کے بعد، تبدیلی کی شرح متعلقہ ڈیٹا بن جاتی ہے، جو ماڈل کے لیے مارکیٹ کے ساتھ اپنے تعلق کو یاد رکھنا مشکل بناتا ہے اور اسے تبدیلی کی شرح اور عروج و زوال کے درمیان تعلق تلاش کرنے پر مجبور کرتا ہے۔
پچھلے مضامین:
FMZ Inventor Quantitative پلیٹ فارم پر کچھ عوامی حکمت عملی کا اشتراک: https://zhuanlan.zhihu.com/p/64961672
NetEase کلاؤڈ کلاس روم کا ڈیجیٹل کرنسی مقداری تجارتی کورس، صرف 20 یوآن: https://study.163.com/course/courseMain.htm?courseId=1006074239&share=2&shareId=40000000060207
میں نے ایک اعلی تعدد حکمت عملی کو عام کیا ہے جو کبھی بہت منافع بخش تھا: https://www.fmz.com/bbs-topic/1211


profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.current_time,4]) 有bug
应该是:profit = self.value - (self.initial_balance+self.initial_stocks * self.df.iloc[self.start,4])
profit = self.value - (self.initial_balance+self.initial_stocksself.df.iloc[self.current_time,4]) 有bug
应该是:profit = self.value - (self.initial_balance+self.initial_stocksself.df.iloc[self.start,4])




GPU版
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class PPO(nn.Module):
def __init__(self):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(8,64)
self.lstm = nn.LSTM(64,32)
self.fc_pi = nn.Linear(32,3)
self.fc_v = nn.Linear(32,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 64)
x, lstm_hidden = self.lstm(x, hidden )
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 64)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float).to(device), torch.tensor(a_lst).to(device).to(device), \
torch.tensor(r_lst).to(device), torch.tensor(s_prime_lst, dtype=torch.float).to(device), \
torch.tensor(done_lst, dtype=torch.float).to(device), torch.tensor(prob_a_lst).to(device)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.to(device).detach(), h2.to(device).detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.cpu().detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float).to(device)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach())
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
- 1