
Giải thích đầy đủ về ưu điểm và nhược điểm của ba loại chính và sáu thuật toán chính của máy học
Trong học máy, mục tiêu là dự đoán (prediction) hoặc tập hợp (clustering). Bài viết này tập trung vào dự đoán. Dự đoán là quá trình dự đoán giá trị của một biến đầu ra từ một tập hợp các biến đầu vào. Ví dụ, với một tập hợp các đặc điểm về một ngôi nhà, chúng ta có thể dự đoán giá bán của nó.
Sau khi hiểu được điều này, chúng ta hãy xem các thuật toán nổi bật và được sử dụng nhiều nhất trong học máy. Chúng ta chia các thuật toán này thành 3 loại: mô hình tuyến tính, mô hình dựa trên cây và mạng thần kinh, tập trung vào 6 thuật toán được sử dụng thường xuyên:
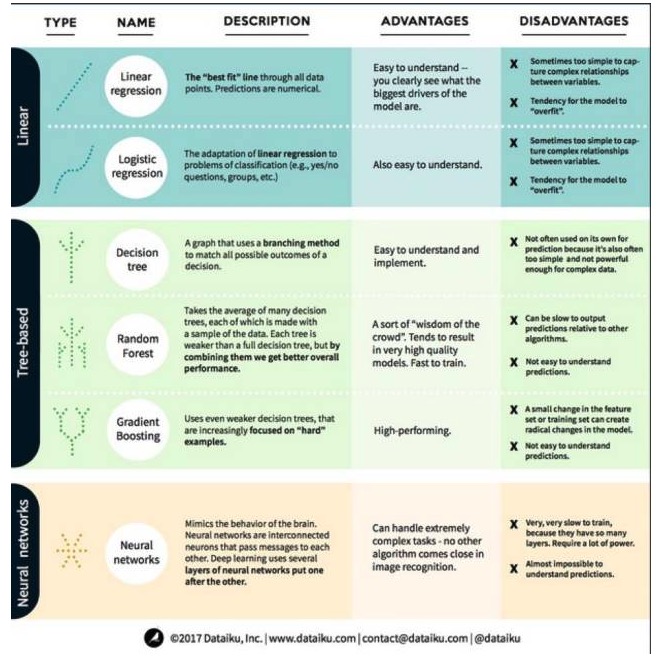
Một, thuật toán mô hình tuyến tính: mô hình tuyến tính sử dụng các công thức đơn giản để tìm ra một hàng phù hợp nhất của các hàm thông qua một tập hợp các điểm dữ liệu. Phương pháp này có từ hơn 200 năm trước và được sử dụng rộng rãi trong lĩnh vực thống kê và học máy. Do tính đơn giản của nó, nó rất hữu ích cho thống kê.
-
1. Phục hồi tuyến tính
Phản hồi tuyến tính, hay chính xác hơn là Phản hồi phân đôi tối thiểu, là hình thức tiêu chuẩn nhất của mô hình tuyến tính. Đối với các vấn đề hồi quy, Phản hồi tuyến tính là mô hình tuyến tính đơn giản nhất. Nhược điểm của nó là mô hình dễ bị quá phù hợp, nghĩa là mô hình hoàn toàn thích nghi với dữ liệu đã được đào tạo và hy sinh khả năng phổ biến cho dữ liệu mới.
Một nhược điểm khác của các mô hình tuyến tính là vì chúng rất đơn giản, chúng không dễ dàng dự đoán hành vi phức tạp hơn khi các biến đầu vào không độc lập.
-
2. logic regression
Logical regression là sự thích nghi của regression tuyến tính với các vấn đề phân loại. Logical regression có những nhược điểm tương tự như regression tuyến tính. Hàm logic rất tốt cho các vấn đề phân loại vì nó giới thiệu hiệu ứng giá trị mốc.
B. Thuật toán mô hình cây
-
1. Cây quyết định
Cây quyết định là một biểu đồ cho mỗi kết quả có thể của quyết định sử dụng phương pháp phân nhánh. Ví dụ, bạn quyết định đặt món salad, quyết định đầu tiên của bạn có thể là loại rau, sau đó là món ăn, sau đó là loại salad. Chúng ta có thể thể hiện tất cả các kết quả có thể trong một cây quyết định.
Để đào tạo cây quyết định, chúng ta cần sử dụng tập dữ liệu đào tạo và tìm ra thuộc tính nào có lợi nhất cho mục tiêu. Ví dụ, trong trường hợp sử dụng phát hiện gian lận, chúng ta có thể thấy rằng thuộc tính có ảnh hưởng lớn nhất đến dự đoán rủi ro gian lận là quốc gia. Sau khi phân nhánh với thuộc tính đầu tiên, chúng ta có hai tập hợp con, điều này là đúng nhất nếu chúng ta chỉ biết thuộc tính đầu tiên. Tiếp theo, chúng ta tìm ra thuộc tính tốt thứ hai có thể phân nhánh cho cả hai tập hợp con, phân chia lại, và lặp đi lặp lại cho đến khi đủ thuộc tính đáp ứng nhu cầu của mục tiêu.
-
2. Rừng ngẫu nhiên
Rừng ngẫu nhiên là trung bình của nhiều cây quyết định, trong đó mỗi cây quyết định được đào tạo với một mẫu dữ liệu ngẫu nhiên. Mỗi cây trong rừng ngẫu nhiên yếu hơn một cây quyết định hoàn chỉnh, nhưng đặt tất cả các cây lại với nhau, chúng ta có thể có hiệu suất tổng thể tốt hơn do lợi thế của sự đa dạng.
Rừng ngẫu nhiên là một thuật toán rất phổ biến trong học máy ngày nay. Rừng ngẫu nhiên rất dễ đào tạo và hoạt động khá tốt. Nhược điểm của nó là dự đoán đầu ra của rừng ngẫu nhiên có thể chậm so với các thuật toán khác, vì vậy khi cần dự đoán nhanh, có thể không chọn rừng ngẫu nhiên.
-
3/ Tăng độ
GradientBoosting, giống như rừng ngẫu nhiên, cũng bao gồm các cây quyết định lười biếng. Sự khác biệt lớn nhất giữa gradientBoosting và rừng ngẫu nhiên là trong gradientBoosting, cây được đào tạo một lần một. Mỗi cây sau được đào tạo chủ yếu bởi các cây trước nhận ra dữ liệu sai. Điều này làm cho gradientBoosting ít chú ý đến các tình huống dễ dự đoán hơn là các tình huống khó khăn.
Đào tạo thang cấp cũng nhanh chóng và hoạt động rất tốt. Tuy nhiên, những thay đổi nhỏ trong tập dữ liệu đào tạo có thể làm thay đổi mô hình một cách cơ bản, do đó kết quả có thể không phải là khả thi nhất.
Mạng thần kinh là một hiện tượng sinh học bao gồm các tế bào thần kinh liên kết với nhau trong não để trao đổi thông tin với nhau. Ý tưởng này hiện được áp dụng cho lĩnh vực học máy, được gọi là ANN (mạng thần kinh nhân tạo).
Tóm tắt từ Big Data Land
- 1