大脑中的支持向量机
 0
2106
0
2106
大脑中的支持向量机
支持向量机(SVM)是一种重要的机器学习分类器, 它巧妙的运用非线性变换把低维的特征投影到高维,可以执行比较复杂的分类任务(升维打击)。 SWM看似使用了一个数学上的玄技,实则是恰巧符合了大脑编码的机理, 我们可以从2013年的一篇nature论文读起,理解机器学习和大脑工作原理的深层联系(表面的联系是运用机器学习研究大脑)。 论文名称: The importance of mixed selectivity in complex cognitive tasks (by Omri Barak al. )
- #### SVM
这种惊人的联系可以从哪里看出来呢?首先我们来谈谈神经编码的本质: 动物接受到一定信号并根据它做出一定的行为,一个是把外界信号转化为神经电信号,另一个是把神经电信号转化为决策信号,前一个过程叫做编码(encoding),后一个过程叫做解码(decoding)。 而神经编码的真实目的正是之后解码来做决策。因此, 用机器学习的眼光看解码, 最简单的方法就是看做一个分类器, 甚至是一个logistic model这样的线性分类器 , 把输入信号根据一定特征分类分别对待。比如看到老虎逃跑,看到兔子吃掉。当然, 有时候解码也在做回归, 比如当神经信号最后转化为运动, 你需要把神经信号转化为动作幅度的连续变量。 那么好了, 这里已经明显看到了神经编码和机器学习的联系, 神经编码的本质是重新表征信号,从而使得分类或回归容易进行。 机器学习的一大类问题本质其实是模仿了自然, 正如同大多数时候人类如果一件事情做得很好,那往往是仿效了大自然的机制。
那么我们就来看看神经编码是怎样进行的, 首先神经元基本可以看做一个根据外电压调整电阻和电容的RC电路, 当外信号足够大, 就会导通, 否则闭合,通过在一定时间里放电的频率来表征一个信号。而我们谈编码,往往是对时间做一个离散化处理, 认为在一个小的时间窗口里, 这个放电率是不变的,这样一个神经网络在这个时间窗口里的细胞放电率排在一起就可以看做一个N维的向量, N是神经元的个数, 这个N维向量,我们姑且叫它编码向量 , 它可以表达动物看到的图像,或听到的声音, 会引起相应的皮层神经网络的相应- 即外界信号的表征。 注意此处我们先不研究深度网络。
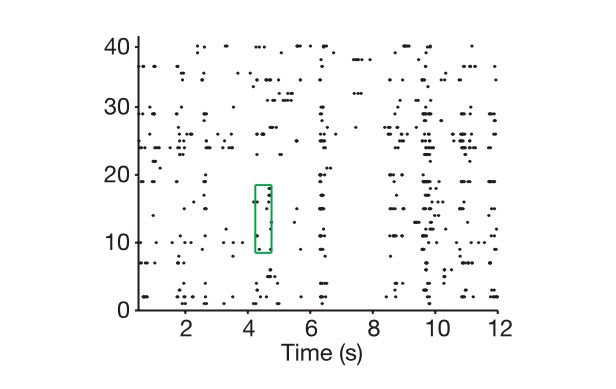
图: 纵轴是细胞 , 横轴是时间, 图中表现了我们是如何提取神经编码的
当然N维向量和神经编码的真实维度是有区别的, 如何定义神经编码的真实维度? 首先, 我们进入这个N维向量所标记的N维空间,然后我们给出所有可能的任务组合, 比如给你看一千张图片假设这些图片代表了整个世界, 把每一次我们得到的神经编码标记为这个空间的一个点, 最后我们利用向量代数的思维看这一千个点构成的子空间的维度, 即认定为神经表征的真实维度。 我假设所有的点都其实在这个N维空间的一条线上, 那么这个表征是一维的,相应的如果所有的点都在高维空间的一个二维平面上, 则它就是二维的。 科学家的发现是, 神经编码的维度通常非常高, 当然它不能高于N,如果神经编码的维度很低, 就没有必要用那么多神经元了。
除了编码的真实维度外,我们还有一个概念就是外信号的真实维度,这里的信号是指神经网络所表达的外部信号,当然你要重述外界信号的所有细节那是一个无限的问题,然而我们分类和决策的根据从来都是关键特征,是一个降维的过程, 这也是PCA的思想。这里我们可以把真实任务里的关键变量看做任务的真实维度, 比如说你要控制一个手臂的运动, 你通常只需要控制关节的旋转角度,如果把它看做一个刚体力学问题, 维度大概不会高于10个,我们叫它K。 即使是你要分辨人脸这样的问题, 问题的维度依然远低于神经元的个数。
那么科学家就面临一个核心问题, 为什么要用比真实问题维度高很多的编码维度和神经元个数来解决这个问题? 这不是一种浪费吗?
而计算神经科学和机器学习一起告诉我们, 神经表征的高维特性正是其所具备的强大学习能力的基础。编码维度越高, 学习能力越强。 注意此处我们甚至没有开始涉及深度网络。 为什么这么说呢?这里我们说神经编码的机制用到了类似SVM的原理, 当我们把一个低维度的信号投射到高维, 我们就可以做越多的classification,即使是一个线性的分类器,你也可以解决无数问题,到底如何做到的? 它又如何和SVM支持向量机原理相通?
注意此处讨论的神经编码主要指高级神经中枢的神经编码,比如文中讨论的前额叶Prefrontal Cortex(PFC),因为低级神经中枢的编码规律并不太涉及分类和决策。
PFC代表的高级脑区
神经编码的奥秘也正是从神经元个数N, 和真实问题维度K的关系(这种差距足可以达到200倍)揭示的。为什么看似冗余的神经元个数可以带来质的飞跃? 首先, 我们假设当我们的编码维度等于真实任务中关键变量的维度的时候,我们使用一个线性分类器将不能处理非线性的分类问题 (假设你要从西瓜中分离出西瓜子,你不能用一个线性边界把西瓜籽从西瓜中剔除出去),这也是在深度学习和SVM没有进入机器学习的时候我们难以解决的典型问题。 用SVM对这类问题的核心解法被称作重新表征, 即把我们的向量从原有坐标系变换到一套新的更高维度的坐标系来表示 , 这时候我们就可以用分割超平面的方法(依然是线性分类器)来进行模式识别和分类,这样即使西瓜子镶嵌在瓜瓤里, 我也可以给它炒出去。如果你没明白,请看下图:
SVM(支持向量机):
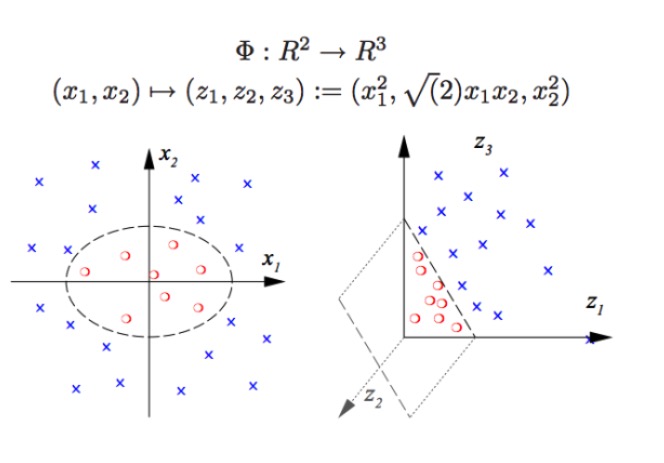
SVM可以进行非线性的分类,例如把图中的红色点和蓝色点隔开,用线性边界我们是无法把红点和蓝点分开的(左图), 因此SVM用的方法正是升高维度。而单纯增加变量的个数是不行的,比如把(x1,x2)映射到(x1,x2, x1+x2)系统其实还是二维的线性空间(画个图的话就是红色的点和蓝色的点还是在一个平面上), 只有使用了非线性函数(x1^2, x1*x2, x2^2)我们才有了实质性的低维度到高维度的跨越, 这时候你就把蓝色的点抛到了空中, 然后你在空中画出一个平面, 就把蓝色的点和红色的点分开啦,如右图。
事实上, 真实神经网络所做的事情正是类似的。 如此一个线性的分类器(解码器)所能进行的分类种类大大增加, 也就是说我们得到了比先前强很多的模式识别能力。此处, 高维即高能, 高维打击是真理啊。
那么,神经编码的高维度是如何得到的呢? 光神经元的个数多是没有用的。 因为学过线性代数的我们知道, 如果我们有数量庞大的N个神经元, 而每个神经元的放电率只与K个关键特征线性相关,那么我们最后表征的维度只会等于问题本身的维度, 你的N个神经元毫无作用(多出的神经元都是前K个神经元的线性组合)。如果要突破这点, 你就必须有与K个特征非线性相关的神经元, 这里我们叫做非线性混合型神经元, 这类的神经元的表征十分复杂, 而其原理正类似于SVM中包含非线性项的核函数。有了这些非线性的神经元, 神经编码的维度才可以突破任务特征的维度,
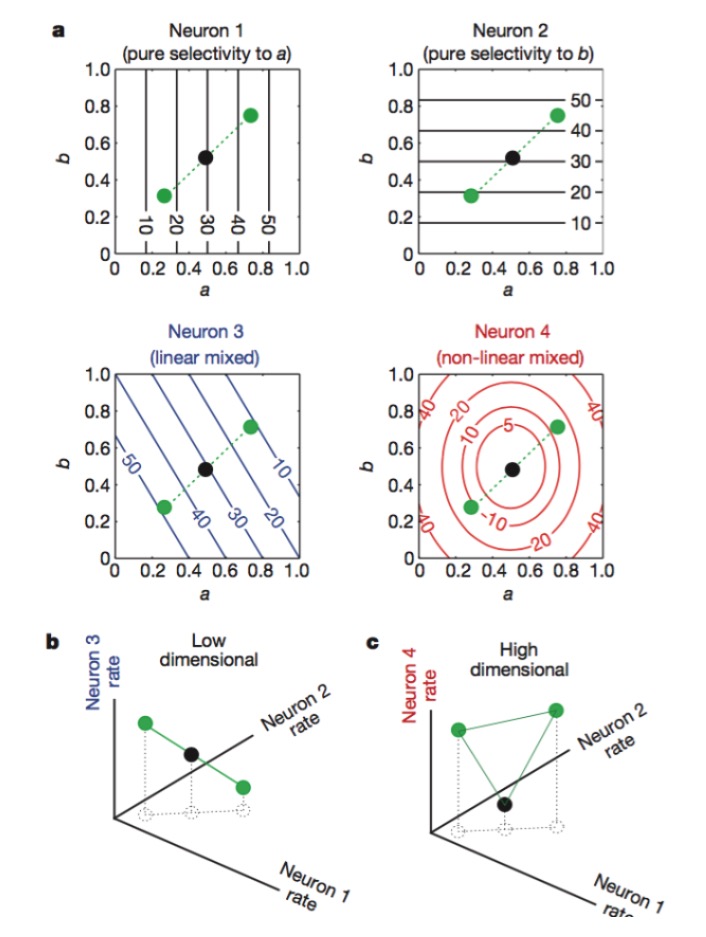
图: 神经元1和2分别只对特征a和b敏感, 3对特征a和b的线性混合敏感, 而4对特征的非线性混合敏感。 最终只有神经元1,2,4的组合使得神经编码维度升高(下图)。
这种编码的官方叫法是混合编码(mixed selectivity),在人们没有发现这种编码的原理的时候我们觉得这是不可理解的, 因为它是神经网络对某种信号的响应显得乱糟糟的。在周边神经系统里,神经元的作用如同传感器,对信号的不同特征进行提取和模式识别。每个神经细胞的功能都是相当特定的,比如视网膜的rods和cones就负责接收光子,而之后由Gangelion cell继续进行编码,每个神经元就好像是一个个被专业训练的哨兵。 而在高级脑区, 这种清晰的分工难以见到,我们发现同一个神经元可能对各种特征敏感,而且这种敏感还不是线性的。 它们更像是对各种任务都想掺和一下的万金油,这种很难找到线性可分的专业分工的现象, 在我们对机器学习中的SVM方法做了对比后才清晰起来。 原来, 这正是对原有的信号做了非线性变换(如果x1是一个特征, x2是一个特征,这种神经元可能就是x1^2+x2^2),而使得神经编码的维度得以高于信号特征空间维度的办法。
大自然的每个细节都内藏玄机,大量冗余和混合编码这看似不专业的做法,看似混乱的信号,最终得到了更好的计算能力。有了这个原理之后, 我们可以轻易的处理一些这样的task:
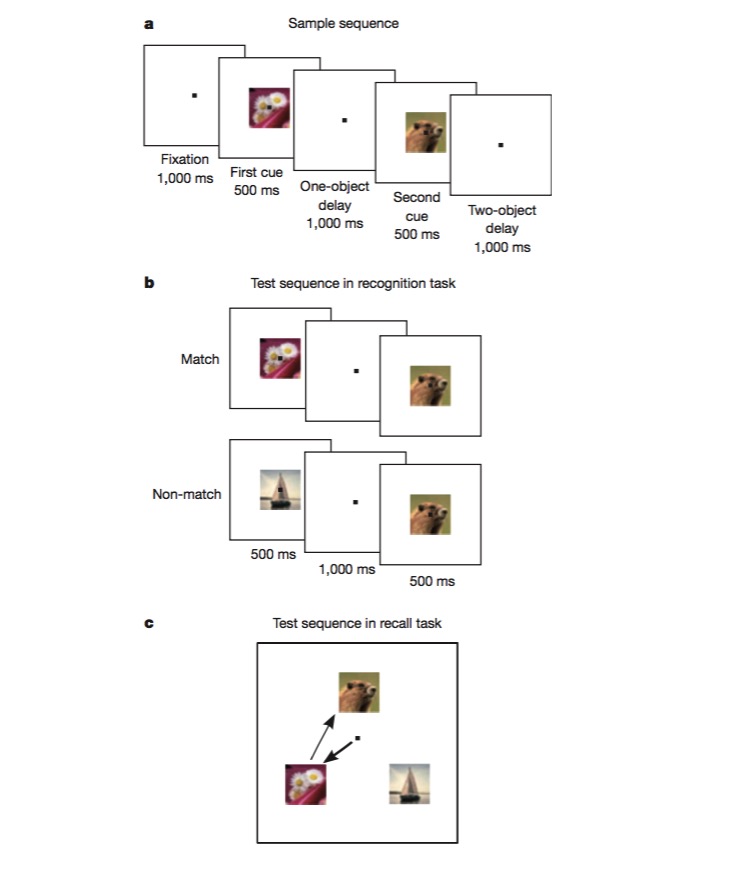
在这个任务中, 猴子首先被训练分辨一个图像是否和之前的相同(recognition),之后被训练判断两个不同图像出现的顺序(recall)。猴子要完成这样的任务要能够对任务的不同侧面进行编码, 比如任务类型(recall or recognition), 图片种类等, 而这正是绝佳的测试是否有混合非线性编码机制存在的实验。实验中证实了大量神经元确实对混合特征敏感,而且存在非线性(比如说同样是对花朵进行编码, 神经元放电强度会取决于任务是recall还是recognition,特征之间不独立) 。 混合编码使得神经编码具有高维表征的特性,从而让这些包含多个侧面的任务的解码和处理得心应手。
看过这篇文章, 我们懂得了设计神经网络如果引入一些非线性的单元会大大提高模式识别能力, 以及SVM恰好是应用了这点,处理掉非线性的分类问题。 而计算神经科学与机器学习, 犹如一枚硬币的两面。
我们研究脑区的功能, 先要用机器学习的方法处理数据, 比如用PCA找到问题的关键维度, 之后又要用机器学习模式识别的思维理解神经编码和解码, 最终我们如果得到了一些新的灵感, 我们又可以改进机器学习的方法。 对于大脑还是机器学习算法, 最终最重要的都是得到信息最恰当的表征方法, 而有了好的表征,做什么都容易了。 这正是机器学习从线性逻辑回归到支持向量机到深度学习的一步步进化过程, 或许这也是大脑得以进化, 我们得以对世界具有越来越高的把控能力的过程。 抑或许进化的本来目的是更清楚的分清谁是老虎谁是羊,谁可以吃谁可以睡, 而在此过程中, 却发展出对世界本身步步深入的理解,以及对理解本身的热爱。
转载自 知乎 许铁-巡洋舰科技
- 求出的macd,请 @小小梦 看下
- 评价算法交易表现的指标---夏普比率
- 一种新型的网格交易法则
- 感觉韭菜都被你们割了 我还是持币好了
- 系统地学习正则表达式(一):基础篇
- Python 朴素贝叶斯 应用
- 螺纹钢、铁矿石比值交易策略的应用分析
- 要如何分析期权的波动率?
- 程序化在期权的应用
- 时间与周期
- 聊聊做市商和对赌
- 世上最深的路,就是你的套路:深挖套利江湖的那些“坑”
- 读《概率统计超入门》及《万万没想到之最简单概率论的五个智慧》
- 资金管理三部曲:格局为先
- 能用加法赚钱,我绝不用乘法
- 常用机器学习与数据挖掘相关术语
- 不预测,只对价格变动做出反映
- 阿里云linux主机运行托管者,主机重启了,如何找回原来的托管者呢?
- 高波動代表高風險?價值投資的風險定義跟你想得不一樣
- 我想问问虚拟货币实盘的话可以支持哪些平台哪些币交易