

ফ্যাক্টর মডেল ফ্রেমওয়ার্ক
সমৃদ্ধ তত্ত্ব এবং অনুশীলন সহ স্টক মার্কেটের মাল্টি-ফ্যাক্টর মডেলের উপর অসংখ্য গবেষণা প্রতিবেদন রয়েছে। মুদ্রার সংখ্যা, মোট বাজার মূল্য, লেনদেনের পরিমাণ, ডেরিভেটিভস বাজার ইত্যাদি নির্বিশেষে ডিজিটাল মুদ্রা বাজার ফ্যাক্টর গবেষণার জন্য যথেষ্ট। এই নিবন্ধটি মূলত পরিমাণগত কৌশলের নতুনদের জন্য এবং এতে জটিল গাণিতিক নীতি এবং পরিসংখ্যানগত বিশ্লেষণ থাকবে না Binance সাসটেইনেবিলিটির উপর ভিত্তি করে ফিউচার মার্কেটকে ডেটা উৎস হিসেবে ব্যবহার করে, ফ্যাক্টর সূচকের মূল্যায়নের সুবিধার্থে একটি সাধারণ ফ্যাক্টর রিসার্চ ফ্রেমওয়ার্ক তৈরি করা হয়েছে।
একটি ফ্যাক্টরকে একটি সূচক হিসাবে বিবেচনা করা যেতে পারে এবং ফ্যাক্টরটি ক্রমাগত পরিবর্তিত হয় এবং সাধারণত ফ্যাক্টরটি একটি বিনিয়োগের যুক্তি উপস্থাপন করে।
উদাহরণ স্বরূপ: ক্লোজিং প্রাইস ক্লোজ ফ্যাক্টর, এর পিছনে অনুমান হল যে স্টক প্রাইস যত বেশি হবে, ভবিষ্যতের আয় তত বেশি হবে (হয়তো কম) এই ফ্যাক্টর দিয়ে একটি পোর্টফোলিও তৈরি করা আসলে একটি ইনভেস্টমেন্ট মডেল / উচ্চ-মূল্যের স্টক কেনার জন্য নিয়মিত অবস্থানের কৌশল। সাধারণভাবে বলতে গেলে, যে উপাদানগুলি ধারাবাহিকভাবে অতিরিক্ত রিটার্ন তৈরি করতে পারে তাকে প্রায়ই আলফা বলা হয়। উদাহরণ স্বরূপ, বাজার মূলধন ফ্যাক্টর, মোমেন্টাম ফ্যাক্টর ইত্যাদি একাডেমিক এবং ইনভেস্টমেন্ট সার্কেল দ্বারা একবার কার্যকরী ফ্যাক্টর হিসাবে যাচাই করা হয়েছে।
স্টক মার্কেট হোক বা ডিজিটাল কারেন্সি মার্কেট, এটা একটা জটিল সিস্টেম কোন ফ্যাক্টরই ভবিষ্যত রিটার্নের ভবিষ্যদ্বাণী করতে পারে না, কিন্তু এর একটা নির্দিষ্ট ডিগ্রী আছে। কার্যকরী আলফা (বিনিয়োগ মডেল) এবং ধীরে ধীরে অকার্যকর হয়ে পড়ে কারণ বেশি অর্থ বিনিয়োগ করা হয়। কিন্তু এই প্রক্রিয়াটি বাজারে অন্যান্য মডেল তৈরি করবে, এইভাবে নতুন আলফাসের জন্ম দেবে। A-শেয়ার মার্কেটে মার্কেট ক্যাপিটালাইজেশন ফ্যাক্টর ছিল খুব কম বাজার মূলধন সহ 10টি স্টক কিনুন এবং 2007 থেকে শুরু হওয়া দশ বছরের ব্যাকটেস্ট 400 গুণ বেশি রিটার্ন দেবে। , বাজার ছাড়িয়ে গেছে। যাইহোক, 2017 সালে সাদা ঘোড়া স্টক মার্কেট ছোট বাজার মূলধন ফ্যাক্টরের ব্যর্থতাকে প্রতিফলিত করে, এবং মূল্য ফ্যাক্টর পরিবর্তে জনপ্রিয় হয়ে ওঠে। অতএব, আলফা যাচাইকরণ এবং ব্যবহারের মধ্যে ক্রমাগত ওজন করা এবং চেষ্টা করা প্রয়োজন।
আপনি যে কারণগুলি খুঁজছেন তা হল একটি কৌশল তৈরির ভিত্তি।
python
import requests
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import requests, zipfile, io
%matplotlib inline
তথ্য উৎস
2022 এর শুরু থেকে বর্তমান পর্যন্ত Binance USDT চিরস্থায়ী ফিউচারের ঘন্টায় K-লাইন ডেটা এখন পর্যন্ত 150টি মুদ্রা ছাড়িয়েছে। আগেই উল্লেখ করা হয়েছে, ফ্যাক্টর মডেল হল একটি কারেন্সি সিলেকশন মডেল, যা একটি নির্দিষ্ট কারেন্সির পরিবর্তে সমস্ত কারেন্সির জন্য ভিত্তিক। কে-লাইন ডেটার মধ্যে রয়েছে উচ্চ খোলার এবং কম বন্ধের দাম, লেনদেনের সংখ্যা, সক্রিয় কেনার পরিমাণ এবং অন্যান্য ডেটা অবশ্যই, এই ডেটাগুলি সমস্ত কারণের উৎস নয়, যেমন মার্কিন স্টক সূচক, সুদের হার বৃদ্ধির প্রত্যাশা, লাভজনকতা, অন-চেইন ডেটা, সামাজিক নেটওয়ার্কিং মিডিয়া জনপ্রিয়তা ইত্যাদি। অজনপ্রিয় ডেটা উত্সগুলি কার্যকর আলফাকেও উন্মোচিত করতে পারে, তবে মৌলিক ভলিউম এবং মূল্য ডেটা সম্পূর্ণরূপে যথেষ্ট।
python
## 当前交易对
Info = requests.get('https://fapi.binance.com/fapi/v1/exchangeInfo')
symbols = [s['symbol'] for s in Info.json()['symbols']]
symbols = list(filter(lambda x: x[-4:] == 'USDT', [s.split('_')[0] for s in symbols]))
print(symbols)
Out:
python
['BTCUSDT', 'ETHUSDT', 'BCHUSDT', 'XRPUSDT', 'EOSUSDT', 'LTCUSDT', 'TRXUSDT', 'ETCUSDT', 'LINKUSDT',
'XLMUSDT', 'ADAUSDT', 'XMRUSDT', 'DASHUSDT', 'ZECUSDT', 'XTZUSDT', 'BNBUSDT', 'ATOMUSDT', 'ONTUSDT',
'IOTAUSDT', 'BATUSDT', 'VETUSDT', 'NEOUSDT', 'QTUMUSDT', 'IOSTUSDT', 'THETAUSDT', 'ALGOUSDT', 'ZILUSDT',
'KNCUSDT', 'ZRXUSDT', 'COMPUSDT', 'OMGUSDT', 'DOGEUSDT', 'SXPUSDT', 'KAVAUSDT', 'BANDUSDT', 'RLCUSDT',
'WAVESUSDT', 'MKRUSDT', 'SNXUSDT', 'DOTUSDT', 'DEFIUSDT', 'YFIUSDT', 'BALUSDT', 'CRVUSDT', 'TRBUSDT',
'RUNEUSDT', 'SUSHIUSDT', 'SRMUSDT', 'EGLDUSDT', 'SOLUSDT', 'ICXUSDT', 'STORJUSDT', 'BLZUSDT', 'UNIUSDT',
'AVAXUSDT', 'FTMUSDT', 'HNTUSDT', 'ENJUSDT', 'FLMUSDT', 'TOMOUSDT', 'RENUSDT', 'KSMUSDT', 'NEARUSDT',
'AAVEUSDT', 'FILUSDT', 'RSRUSDT', 'LRCUSDT', 'MATICUSDT', 'OCEANUSDT', 'CVCUSDT', 'BELUSDT', 'CTKUSDT',
'AXSUSDT', 'ALPHAUSDT', 'ZENUSDT', 'SKLUSDT', 'GRTUSDT', '1INCHUSDT', 'CHZUSDT', 'SANDUSDT', 'ANKRUSDT',
'BTSUSDT', 'LITUSDT', 'UNFIUSDT', 'REEFUSDT', 'RVNUSDT', 'SFPUSDT', 'XEMUSDT', 'BTCSTUSDT', 'COTIUSDT',
'CHRUSDT', 'MANAUSDT', 'ALICEUSDT', 'HBARUSDT', 'ONEUSDT', 'LINAUSDT', 'STMXUSDT', 'DENTUSDT', 'CELRUSDT',
'HOTUSDT', 'MTLUSDT', 'OGNUSDT', 'NKNUSDT', 'SCUSDT', 'DGBUSDT', '1000SHIBUSDT', 'ICPUSDT', 'BAKEUSDT',
'GTCUSDT', 'BTCDOMUSDT', 'TLMUSDT', 'IOTXUSDT', 'AUDIOUSDT', 'RAYUSDT', 'C98USDT', 'MASKUSDT', 'ATAUSDT',
'DYDXUSDT', '1000XECUSDT', 'GALAUSDT', 'CELOUSDT', 'ARUSDT', 'KLAYUSDT', 'ARPAUSDT', 'CTSIUSDT', 'LPTUSDT',
'ENSUSDT', 'PEOPLEUSDT', 'ANTUSDT', 'ROSEUSDT', 'DUSKUSDT', 'FLOWUSDT', 'IMXUSDT', 'API3USDT', 'GMTUSDT',
'APEUSDT', 'BNXUSDT', 'WOOUSDT', 'FTTUSDT', 'JASMYUSDT', 'DARUSDT', 'GALUSDT', 'OPUSDT', 'BTCUSDT',
'ETHUSDT', 'INJUSDT', 'STGUSDT', 'FOOTBALLUSDT', 'SPELLUSDT', '1000LUNCUSDT', 'LUNA2USDT', 'LDOUSDT',
'CVXUSDT']
python
print(len(symbols))
Out:
153
python
#获取任意周期K线的函数
def GetKlines(symbol='BTCUSDT',start='2020-8-10',end='2021-8-10',period='1h',base='fapi',v = 'v1'):
Klines = []
start_time = int(time.mktime(datetime.strptime(start, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000
end_time = min(int(time.mktime(datetime.strptime(end, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000,time.time()*1000)
intervel_map = {'m':60*1000,'h':60*60*1000,'d':24*60*60*1000}
while start_time < end_time:
mid_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
url = 'https://'+base+'.binance.com/'+base+'/'+v+'/klines?symbol=%s&interval=%s&startTime=%s&endTime=%s&limit=1000'%(symbol,period,start_time,mid_time)
res = requests.get(url)
res_list = res.json()
if type(res_list) == list and len(res_list) > 0:
start_time = res_list[-1][0]+int(period[:-1])*intervel_map[period[-1]]
Klines += res_list
if type(res_list) == list and len(res_list) == 0:
start_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
if mid_time >= end_time:
break
df = pd.DataFrame(Klines,columns=['time','open','high','low','close','amount','end_time','volume','count','buy_amount','buy_volume','null']).astype('float')
df.index = pd.to_datetime(df.time,unit='ms')
return df
python
start_date = '2022-1-1'
end_date = '2022-09-14'
period = '1h'
df_dict = {}
for symbol in symbols:
df_s = GetKlines(symbol=symbol,start=start_date,end=end_date,period=period,base='fapi',v='v1')
if not df_s.empty:
df_dict[symbol] = df_s
python
symbols = list(df_dict.keys())
print(df_s.columns)
Out:
Index(['time', 'open', 'high', 'low', 'close', 'amount', 'end_time', 'volume',
'count', 'buy_amount', 'buy_volume', 'null'],
dtype='object')
প্রাথমিকভাবে কে-লাইন ডেটা থেকে আমরা যে ডেটাতে আগ্রহী তা বের করি: ক্লোজিং প্রাইস, খোলার মূল্য, ট্রেডিং ভলিউম, লেনদেনের সংখ্যা এবং সক্রিয় ক্রয় অনুপাত এই ডেটার উপর ভিত্তি করে প্রয়োজনীয় বিষয়গুলি প্রক্রিয়া করা হয়।
python
df_close = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_open = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_volume = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_buy_ratio = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_count = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
for symbol in df_dict.keys():
df_s = df_dict[symbol]
df_close[symbol] = df_s.close
df_open[symbol] = df_s.open
df_volume[symbol] = df_s.volume
df_count[symbol] = df_s['count']
df_buy_ratio[symbol] = df_s.buy_amount/df_s.amount
df_close = df_close.dropna(how='all')
df_open = df_open.dropna(how='all')
df_volume = df_volume.dropna(how='all')
df_count = df_count.dropna(how='all')
df_buy_ratio = df_buy_ratio.dropna(how='all')
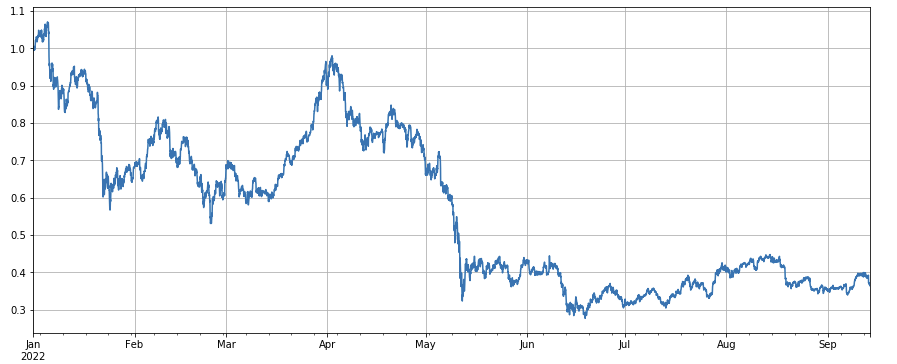
বাজার সূচকের কর্মক্ষমতার একটি ওভারভিউ তুলনামূলকভাবে অন্ধকার বলা যেতে পারে, বছরের শুরু থেকে 60% কমেছে।
python
df_norm = df_close/df_close.fillna(method='bfill').iloc[0] #归一化
df_norm.mean(axis=1).plot(figsize=(15,6),grid=True);
#最终指数收益图
ফ্যাক্টর বৈধতা নির্ধারণ
-
রিগ্রেশন পদ্ধতি
পরবর্তী সময়ের মধ্যে রিটার্নের হার নির্ভরশীল ভেরিয়েবল হিসাবে ব্যবহার করা হয়, যে ফ্যাক্টরটি পরীক্ষা করা হবে সেটি স্বাধীন পরিবর্তনশীল হিসাবে ব্যবহার করা হয় এবং রিগ্রেশনের মাধ্যমে প্রাপ্ত সহগটি ফ্যাক্টরের রিটার্নের হার। রিগ্রেশন সমীকরণ তৈরি করার পরে, আমরা সাধারণত সহগ t মানের পরম গড় মান, 2-এর বেশি সহগ t মানের পরম মানের অনুক্রমের অনুপাত, বার্ষিক ফ্যাক্টর রিটার্ন, বার্ষিক ফ্যাক্টর রিটার্ন অস্থিরতা, ফ্যাক্টর রিটার্নের শার্প অনুপাতকে উল্লেখ করি। এবং অন্যান্য পরামিতি ফ্যাক্টর বৈধতা এবং অস্থিরতা. আপনি একবারে একাধিক কারণের প্রত্যাবর্তন করতে পারেন, বিস্তারিত জানার জন্য দয়া করে বারার ডকুমেন্টেশন দেখুন। -
IC, IR এবং অন্যান্য সূচক
তথাকথিত IC হল ফ্যাক্টর এবং পরবর্তী পিরিয়ডের রিটার্ন রেট এর মধ্যে পারস্পরিক সম্পর্ক সহগ। সাধারণভাবে বলতে গেলে, IR হল IC ক্রম/IC ক্রম-এর আদর্শ বিচ্যুতির গড়। -
অনুক্রমিক রিগ্রেশন
এই প্রবন্ধে এই পদ্ধতিটি ব্যবহার করা হবে, যা হল পরীক্ষা করার জন্য ফ্যাক্টরগুলিকে সাজানো, গ্রুপ ব্যাকটেস্টিংয়ের জন্য মুদ্রাগুলিকে N গ্রুপে ভাগ করা এবং অবস্থানগুলি সামঞ্জস্য করার জন্য একটি নির্দিষ্ট সময়কাল ব্যবহার করা। যদি পরিস্থিতি আদর্শ হয়, তাহলে N গ্রুপের মুদ্রার ফলন ভালো একঘেয়েমি দেখাবে, একঘেয়েমিভাবে বৃদ্ধি বা হ্রাস পাবে এবং প্রতিটি গ্রুপের মধ্যে ফলনের ব্যবধান বড় হবে। এই ধরনের কারণগুলি উন্নত বৈষম্যের মধ্যে প্রতিফলিত হয়। যদি প্রথম গ্রুপের রিটার্ন সর্বোচ্চ এবং শেষ গ্রুপের রিটার্ন সর্বনিম্ন হয়, তাহলে প্রথম গ্রুপে দীর্ঘ এবং শেষ গ্রুপে সংক্ষিপ্ত করুন। চূড়ান্ত রিটার্ন হার হল শার্প অনুপাতের একটি রেফারেন্স সূচক।
প্রকৃত ব্যাকটেস্ট অপারেশন
নির্বাচিত মুদ্রাগুলিকে ছোট থেকে বড় পর্যন্ত 3টি গোষ্ঠীতে বাছাই করুন যদি একটি ফ্যাক্টর কার্যকর হয়, প্রতিটি গ্রুপের ফলন তত বেশি, তবে এর অর্থ প্রতিটি হিসাবে মুদ্রা তুলনামূলকভাবে বেশি তহবিল বরাদ্দ করা হয়, যদি লং এবং শর্ট পজিশনের জন্য লিভারেজ দ্বিগুণ করা হয়, এবং প্রথম এবং শেষ গ্রুপগুলি যথাক্রমে 10% হয়, যদি একটি কারেন্সি 2 গুণ বেড়ে যায়, তাহলে রিট্রেসমেন্ট হবে 20%; গ্রুপের সংখ্যা 50, রিট্রেসমেন্ট হল 4%। মুদ্রার বিকেন্দ্রীকরণ কালো রাজহাঁসের ঝুঁকি কমাতে পারে। প্রথম গ্রুপটি দীর্ঘ করুন (সবচেয়ে ছোট ফ্যাক্টর মান সহ) এবং তৃতীয় গ্রুপটি ছোট করুন। যদি ফ্যাক্টর যত বড় হয়, তত বেশি রিটার্ন, আপনি লম্বা এবং ছোট অবস্থানগুলিকে বিপরীত করতে পারেন বা ফ্যাক্টরটিকে একটি ঋণাত্মক সংখ্যা বা পারস্পরিক পরিবর্তন করতে পারেন।
একটি ফ্যাক্টরের ভবিষ্যদ্বাণীমূলক ক্ষমতা সাধারণত চূড়ান্ত ব্যাকটেস্ট রিটার্ন এবং শার্প অনুপাতের উপর ভিত্তি করে মোটামুটিভাবে মূল্যায়ন করা যেতে পারে। এছাড়াও, ফ্যাক্টর এক্সপ্রেশনটি সরল কিনা, গ্রুপিংয়ের আকারের প্রতি সংবেদনশীল কিনা, অবস্থান সমন্বয় ব্যবধানের প্রতি সংবেদনশীল কিনা, ব্যাকটেস্টের প্রাথমিক সময়ের প্রতি সংবেদনশীল কিনা ইত্যাদি বিষয়গুলিও উল্লেখ করা প্রয়োজন।
অবস্থান সামঞ্জস্যের ফ্রিকোয়েন্সি সম্পর্কে, স্টক মার্কেটে প্রায়ই 5 দিন, 10 দিন এবং এক মাসের একটি চক্র থাকে তবে, ডিজিটাল মুদ্রা বাজারের জন্য, এই ধরনের একটি চক্র নিঃসন্দেহে অনেক দীর্ঘ, এবং প্রকৃত বাজারের বাজারটি বাস্তবে পর্যবেক্ষণ করা হয়। সময়, এবং একটি নির্দিষ্ট চক্র অনুসরণ করা হয় আবার পজিশন সামঞ্জস্য করার কোন প্রয়োজন নেই, তাই রিয়েল ট্রেডিংয়ে আমরা রিয়েল টাইমে বা অল্প সময়ের মধ্যে পজিশন সামঞ্জস্য করি।
কিভাবে একটি পজিশন বন্ধ করতে হয় সে সম্পর্কে, সনাতন পদ্ধতি অনুযায়ী, পরের বার সাজানোর সময় পজিশনটি গ্রুপে না থাকলে আপনি সেটি বন্ধ করতে পারেন। যাইহোক, রিয়েল-টাইম পজিশন অ্যাডজাস্টমেন্টের ক্ষেত্রে, কিছু মুদ্রা ঠিক সীমানায় থাকতে পারে এবং পজিশনগুলি সামনে পিছনে বন্ধ হয়ে যেতে পারে। অতএব, এই কৌশলটি গোষ্ঠীকরণের পরিবর্তনের জন্য অপেক্ষা করা ব্যবহার করে এবং তারপরে যখন বিপরীত দিকে একটি অবস্থান খোলার প্রয়োজন হয় তখন অবস্থানটি বন্ধ করে দেয় উদাহরণস্বরূপ, যদি প্রথম গ্রুপটি দীর্ঘ হয়, যখন দীর্ঘ অবস্থায় মুদ্রাগুলি ভাগ করা হয় তৃতীয় গ্রুপ, অবস্থান এই সময়ে বন্ধ এবং সংক্ষিপ্ত হবে. যদি একটি নির্দিষ্ট সময়ের মধ্যে অবস্থান বন্ধ করা হয়, যেমন প্রতিদিন বা প্রতি 8 ঘন্টা, একটি গ্রুপে না থেকে অবস্থান বন্ধ করার পদ্ধতিও ব্যবহার করা যেতে পারে। আপনি আরো চেষ্টা করতে পারেন.
python
#回测引擎
class Exchange:
def __init__(self, trade_symbols, fee=0.0004, initial_balance=10000):
self.initial_balance = initial_balance #初始的资产
self.fee = fee
self.trade_symbols = trade_symbols
self.account = {'USDT':{'realised_profit':0, 'unrealised_profit':0, 'total':initial_balance, 'fee':0, 'leverage':0, 'hold':0}}
for symbol in trade_symbols:
self.account[symbol] = {'amount':0, 'hold_price':0, 'value':0, 'price':0, 'realised_profit':0,'unrealised_profit':0,'fee':0}
def Trade(self, symbol, direction, price, amount):
cover_amount = 0 if direction*self.account[symbol]['amount'] >=0 else min(abs(self.account[symbol]['amount']), amount)
open_amount = amount - cover_amount
self.account['USDT']['realised_profit'] -= price*amount*self.fee #扣除手续费
self.account['USDT']['fee'] += price*amount*self.fee
self.account[symbol]['fee'] += price*amount*self.fee
if cover_amount > 0: #先平仓
self.account['USDT']['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount #利润
self.account[symbol]['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount
self.account[symbol]['amount'] -= -direction*cover_amount
self.account[symbol]['hold_price'] = 0 if self.account[symbol]['amount'] == 0 else self.account[symbol]['hold_price']
if open_amount > 0:
total_cost = self.account[symbol]['hold_price']*direction*self.account[symbol]['amount'] + price*open_amount
total_amount = direction*self.account[symbol]['amount']+open_amount
self.account[symbol]['hold_price'] = total_cost/total_amount
self.account[symbol]['amount'] += direction*open_amount
def Buy(self, symbol, price, amount):
self.Trade(symbol, 1, price, amount)
def Sell(self, symbol, price, amount):
self.Trade(symbol, -1, price, amount)
def Update(self, close_price): #对资产进行更新
self.account['USDT']['unrealised_profit'] = 0
self.account['USDT']['hold'] = 0
for symbol in self.trade_symbols:
if not np.isnan(close_price[symbol]):
self.account[symbol]['unrealised_profit'] = (close_price[symbol] - self.account[symbol]['hold_price'])*self.account[symbol]['amount']
self.account[symbol]['price'] = close_price[symbol]
self.account[symbol]['value'] = abs(self.account[symbol]['amount'])*close_price[symbol]
self.account['USDT']['hold'] += self.account[symbol]['value']
self.account['USDT']['unrealised_profit'] += self.account[symbol]['unrealised_profit']
self.account['USDT']['total'] = round(self.account['USDT']['realised_profit'] + self.initial_balance + self.account['USDT']['unrealised_profit'],6)
self.account['USDT']['leverage'] = round(self.account['USDT']['hold']/self.account['USDT']['total'],3)
#测试因子的函数
def Test(factor, symbols, period=1, N=40, value=300):
e = Exchange(symbols, fee=0.0002, initial_balance=10000)
res_list = []
index_list = []
factor = factor.dropna(how='all')
for idx, row in factor.iterrows():
if idx.hour % period == 0:
buy_symbols = row.sort_values().dropna()[0:N].index
sell_symbols = row.sort_values().dropna()[-N:].index
prices = df_close.loc[idx,]
index_list.append(idx)
for symbol in symbols:
if symbol in buy_symbols and e.account[symbol]['amount'] <= 0:
e.Buy(symbol,prices[symbol],value/prices[symbol]-e.account[symbol]['amount'])
if symbol in sell_symbols and e.account[symbol]['amount'] >= 0:
e.Sell(symbol,prices[symbol], value/prices[symbol]+e.account[symbol]['amount'])
e.Update(prices)
res_list.append([e.account['USDT']['total'],e.account['USDT']['hold']])
return pd.DataFrame(data=res_list, columns=['total','hold'],index = index_list)
সাধারণ ফ্যাক্টর পরীক্ষা
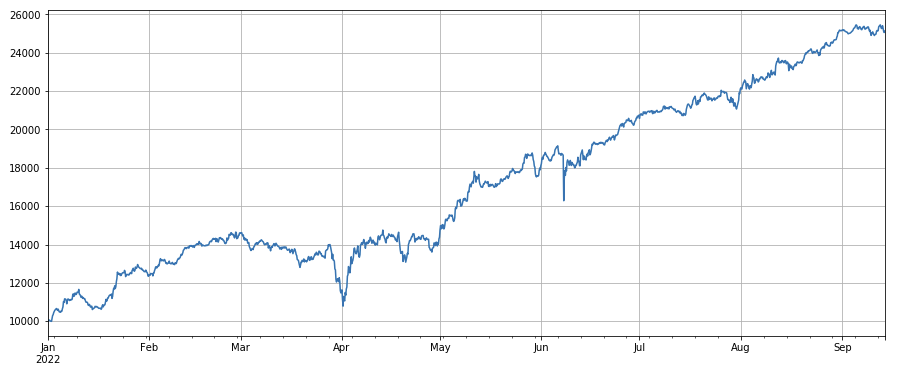
ভলিউম ফ্যাক্টর: কম ট্রেডিং ভলিউম সহ কয়েনগুলিকে ছোট করুন এবং উচ্চ ট্রেডিং ভলিউম সহ কয়েনগুলি খুব ভাল, যা দেখায় যে জনপ্রিয় কয়েনগুলি পড়ে যাওয়ার দিকে ঝুঁকছে৷
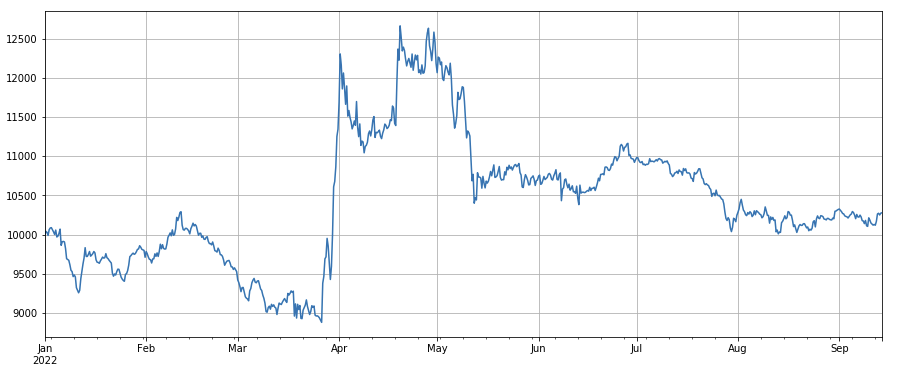
লেনদেন মূল্য ফ্যাক্টর: কম মূল্যের মুদ্রায় দীর্ঘ যান এবং উচ্চ-মূল্যের মুদ্রার প্রভাব গড়।
লেনদেন ফ্যাক্টর সংখ্যা: কর্মক্ষমতা লেনদেন ভলিউম অনুরূপ. এটা স্পষ্টভাবে লক্ষ্য করা যায় যে ট্রেডিং ভলিউম ফ্যাক্টর এবং লেনদেনের সংখ্যার মধ্যে পারস্পরিক সম্পর্ক অনেক বেশি সংশ্লেষিত মাল্টি-ফ্যাক্টর এই ফ্যাক্টরটি বিবেচনায় নেওয়া দরকার।
3h ভরবেগ ফ্যাক্টর: (df_close - df_close.shift(3))/df_close.shift(3)। অর্থাৎ, ফ্যাক্টরের 3-ঘন্টা বৃদ্ধি ব্যাকটেস্ট ফলাফল দেখায় যে 3-ঘন্টা বৃদ্ধির সুস্পষ্ট রিগ্রেশন বৈশিষ্ট্য রয়েছে, অর্থাৎ, যা বেড়েছে তার পরে কমার সম্ভাবনা বেশি। সামগ্রিক কর্মক্ষমতা ঠিক আছে, কিন্তু রিট্রেসমেন্ট এবং দোলনের দীর্ঘ সময়ও রয়েছে।
24ঘন্টা মোমেন্টাম ফ্যাক্টর: 24ঘন্টা পজিশন রিব্যালেন্সিং সাইকেলের ফলাফল খারাপ নয়, রিটার্ন 3ঘন্টা মোমেন্টামের মতো এবং রিট্রেসমেন্ট ছোট।
ট্রেডিং ভলিউম পরিবর্তনের ফ্যাক্টর: df_volume.rolling(24).mean()/df_volume.rolling(96).mean(), যা গত 1 দিনে ট্রেডিং ভলিউমের সাথে গত 3 দিনের ট্রেডিং ভলিউমের অনুপাত, এবং অবস্থান প্রতি 8 ঘন্টা সমন্বয় করা হয়. ব্যাকটেস্ট ফলাফল তুলনামূলকভাবে ভাল পারফর্ম করেছে এবং রিট্রেসমেন্ট তুলনামূলকভাবে কম ছিল, যা দেখায় যে যারা সক্রিয় ট্রেডিং ভলিউম রয়েছে তারা পতনের দিকে বেশি ঝুঁকছে।
লেনদেন সংখ্যা পরিবর্তনের ফ্যাক্টর: df_count.rolling(24).mean() / df_count.rolling(96).mean(), যা গত দিনে লেনদেনের সংখ্যা এবং গত তিন দিনের লেনদেনের সংখ্যার অনুপাত। . প্রতি ৮ ঘন্টা অন্তর অবস্থানটি সমন্বয় করা হয়। . ব্যাকটেস্টের ফলাফল তুলনামূলকভাবে ভালো এবং রিট্রেসমেন্ট তুলনামূলকভাবে কম, যা দেখায় যে লেনদেনের সংখ্যা বাড়ার সাথে সাথে বাজার আরও সক্রিয়ভাবে পতনের দিকে ঝুঁকছে।
একক লেনদেন মান পরিবর্তন ফ্যাক্টর:
-(df_volume.rolling(24).mean()/df_count.rolling(24).mean())/(df_volume.rolling(24).mean()/df_count.rolling(96).mean())
, অর্থাৎ, গত 1 দিনে লেনদেনের মূল্যের সাথে গত 3 দিনের লেনদেনের মূল্যের অনুপাত এবং প্রতি 8 ঘন্টায় অবস্থানটি সামঞ্জস্য করা হয়৷ এই ফ্যাক্টরটি ভলিউম ফ্যাক্টরের সাথেও খুব বেশি সম্পর্কযুক্ত।
সক্রিয় লেনদেনের অনুপাত পরিবর্তনের ফ্যাক্টর: df_buy_ratio.rolling(24).mean()/df_buy_ratio.rolling(96).mean(), অর্থাৎ, মোট ট্রেডিং ভলিউমের সাথে শেষ দিনে সক্রিয় ক্রয়ের পরিমাণের অনুপাত এবং অনুপাত। গত তিন দিনে লেনদেনের মূল্য, প্রতি 8 ঘন্টায় অবস্থানগুলি সামঞ্জস্য করুন। এই ফ্যাক্টরের পারফরম্যান্স গ্রহণযোগ্য এবং ট্রেডিং ভলিউম ফ্যাক্টরের সাথে সামান্য সম্পর্ক আছে।
অস্থিরতা ফ্যাক্টর: (df_close/df_open).rolling(24).std(), কম অস্থিরতার সাথে মুদ্রায় দীর্ঘ সময় চলার একটি নির্দিষ্ট প্রভাব রয়েছে।
ট্রেডিং ভলিউম এবং ক্লোজিং প্রাইসের মধ্যে পারস্পরিক সম্পর্ক ফ্যাক্টর: df_close.rolling(96).corr(df_volume) গত 4 দিনের ক্লোজিং দামের সাথে ট্রেডিং ভলিউমের একটি পারস্পরিক সম্পর্ক রয়েছে এবং সামগ্রিক পারফরম্যান্স ভাল।
এখানে শুধুমাত্র ভলিউম এবং মূল্যের উপর ভিত্তি করে কিছু ফ্যাক্টর তালিকাভুক্ত করা হয়েছে। আপনি বিখ্যাত ALPHA101 ফ্যাক্টর নির্মাণ পদ্ধতি উল্লেখ করতে পারেন: https://github.com/STHSF/alpha101।
python
#成交量
factor_volume = df_volume
factor_volume_res = Test(factor_volume, symbols, period=4)
factor_volume_res.total.plot(figsize=(15,6),grid=True);
python
#成交价
factor_close = df_close
factor_close_res = Test(factor_close, symbols, period=8)
factor_close_res.total.plot(figsize=(15,6),grid=True);
python
#成交笔数
factor_count = df_count
factor_count_res = Test(factor_count, symbols, period=8)
factor_count_res.total.plot(figsize=(15,6),grid=True);
python
print(df_count.corrwith(df_volume).mean())
0.9671246744996017
python
#3小时动量因子
factor_1 = (df_close - df_close.shift(3))/df_close.shift(3)
factor_1_res = Test(factor_1,symbols,period=1)
factor_1_res.total.plot(figsize=(15,6),grid=True);
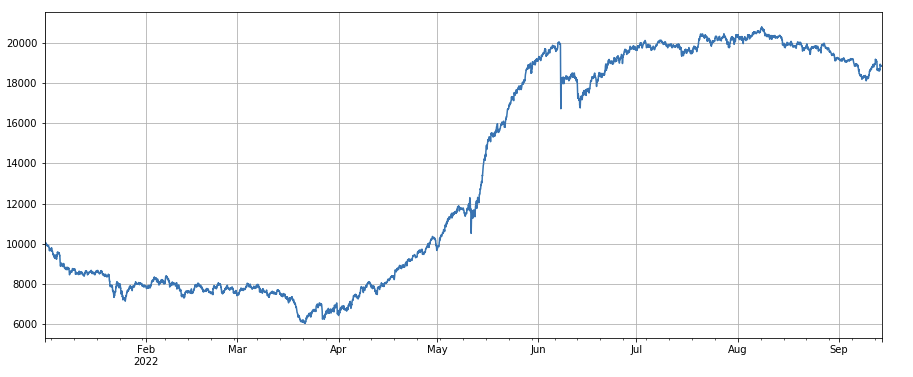
python
#24小时动量因子
factor_2 = (df_close - df_close.shift(24))/df_close.shift(24)
factor_2_res = Test(factor_2,symbols,period=24)
tamenxuanfactor_2_res.total.plot(figsize=(15,6),grid=True);
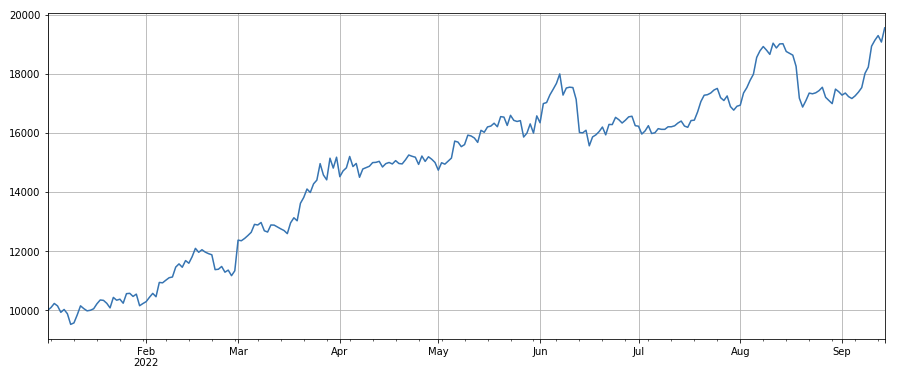
python
#成交量因子
factor_3 = df_volume.rolling(24).mean()/df_volume.rolling(96).mean()
factor_3_res = Test(factor_3, symbols, period=8)
factor_3_res.total.plot(figsize=(15,6),grid=True);
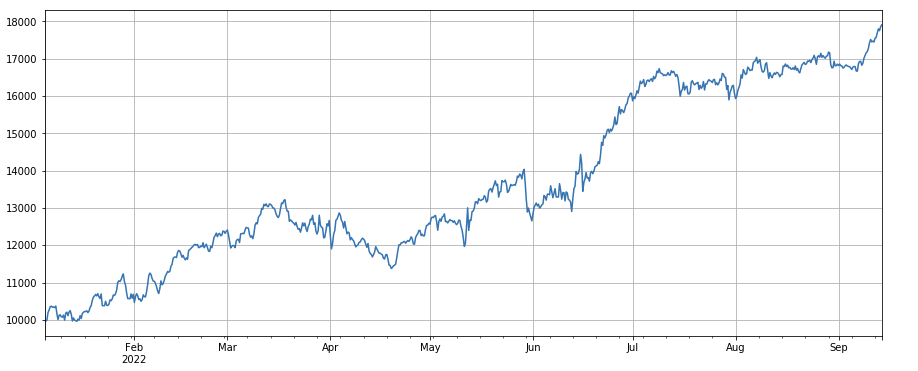
python
#成交笔数因子
factor_4 = df_count.rolling(24).mean()/df_count.rolling(96).mean()
factor_4_res = Test(factor_4, symbols, period=8)
factor_4_res.total.plot(figsize=(15,6),grid=True);
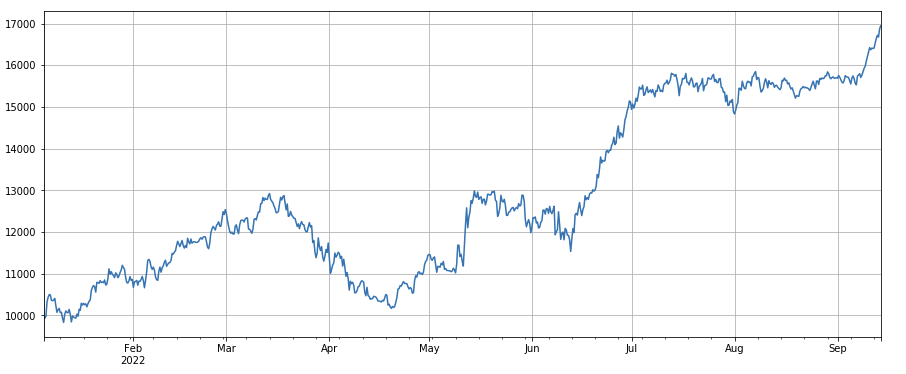
python
#因子相关性
print(factor_4.corrwith(factor_3).mean())
0.9707239580854841
python
#单笔成交价值因子
factor_5 = -(df_volume.rolling(24).mean()/df_count.rolling(24).mean())/(df_volume.rolling(24).mean()/df_count.rolling(96).mean())
factor_5_res = Test(factor_5, symbols, period=8)
factor_5_res.total.plot(figsize=(15,6),grid=True);
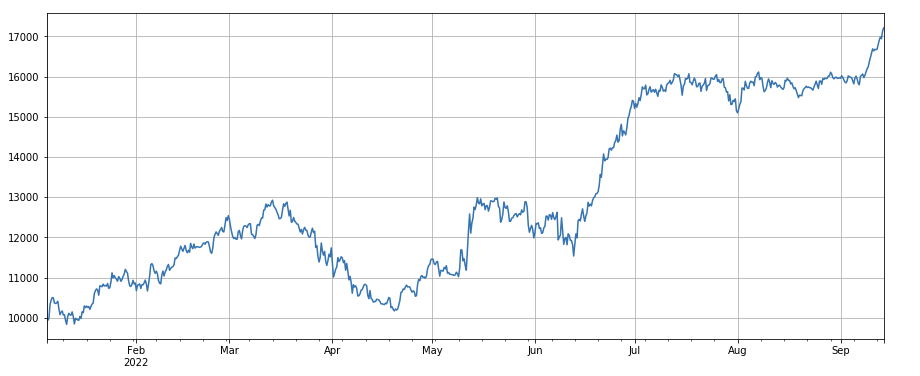
python
print(factor_4.corrwith(factor_5).mean())
0.861206620552479
python
#主动成交比例因子
factor_6 = df_buy_ratio.rolling(24).mean()/df_buy_ratio.rolling(96).mean()
factor_6_res = Test(factor_6, symbols, period=4)
factor_6_res.total.plot(figsize=(15,6),grid=True);
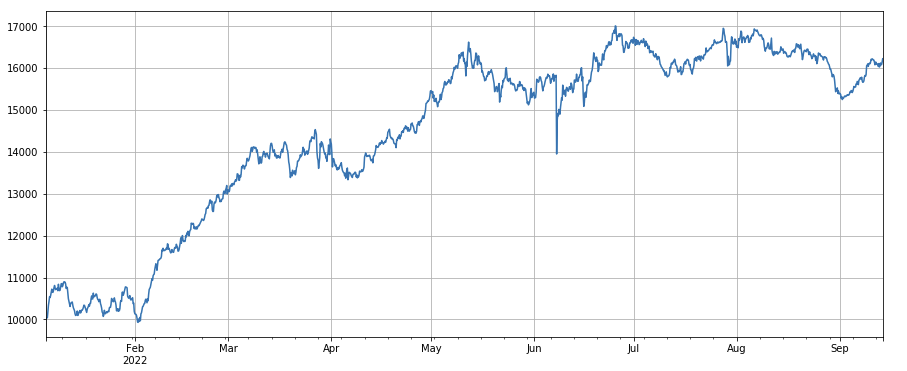
python
print(factor_3.corrwith(factor_6).mean())
0.1534572192503726
python
#波动率因子
factor_7 = (df_close/df_open).rolling(24).std()
factor_7_res = Test(factor_7, symbols, period=2)
factor_7_res.total.plot(figsize=(15,6),grid=True);
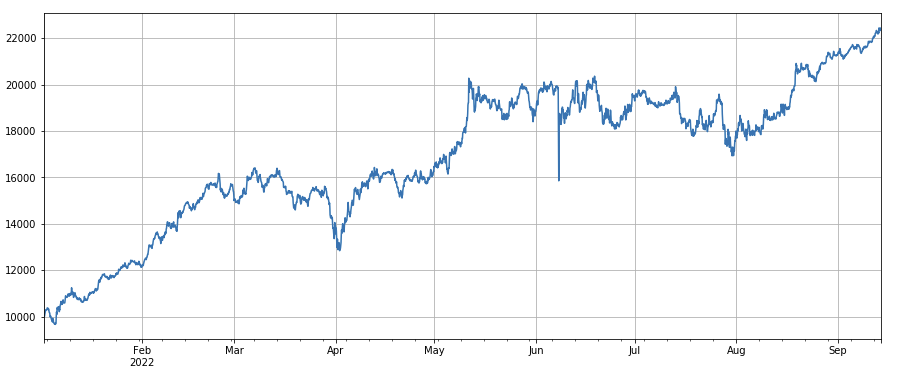
python
#成交量和收盘价相关性因子
factor_8 = df_close.rolling(96).corr(df_volume)
factor_8_res = Test(factor_8, symbols, period=4)
factor_8_res.total.plot(figsize=(15,6),grid=True);
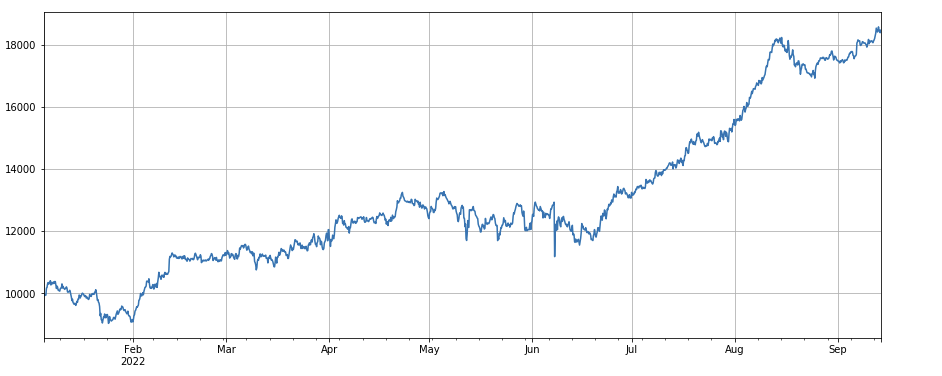
মাল্টি-ফ্যাক্টর সংশ্লেষণ
ক্রমাগত নতুন কার্যকরী ফ্যাক্টর আবিষ্কার করা অবশ্যই কৌশল নির্মাণ প্রক্রিয়ার সবচেয়ে গুরুত্বপূর্ণ অংশ, কিন্তু একটি ভাল ফ্যাক্টর সংশ্লেষণ পদ্ধতি ছাড়া, একটি চমৎকার একক আলফা ফ্যাক্টর তার সর্বাধিক ভূমিকা পালন করতে পারে না। সাধারণ মাল্টি-ফ্যাক্টর সংশ্লেষণ পদ্ধতি অন্তর্ভুক্ত:
সমান ওজন পদ্ধতি: সংশ্লেষিত করার জন্য সমস্ত উৎপাদককে সমান ওজনে যোগ করে নতুন সংশ্লেষিত উৎপাদক তৈরি করা হয়।
ঐতিহাসিক ফ্যাক্টর রিটার্ন ওয়েটিং পদ্ধতি: সংশ্লেষিত হওয়া সমস্ত ফ্যাক্টর একটি নতুন সংশ্লেষিত ফ্যাক্টর পাওয়ার জন্য ওজন হিসাবে সাম্প্রতিক সময়ের মধ্যে ঐতিহাসিক ফ্যাক্টর রিটার্ন হারের গাণিতিক গড় অনুসারে যোগ করা হয়। এই পদ্ধতিতে ভাল কাজ করে এমন ফ্যাক্টরগুলির ওজন বেশি।
IC_IR ওয়েটিং পদ্ধতিকে সর্বাধিক করুন: একটি ঐতিহাসিক সময়ের মধ্যে যৌগিক ফ্যাক্টরের গড় IC মানকে পরবর্তী সময়ের মধ্যে যৌগিক ফ্যাক্টরের IC মানের অনুমান হিসাবে ব্যবহার করুন এবং ঐতিহাসিক IC মানের কোভেরিয়েন্স ম্যাট্রিক্সকে অনুমান হিসাবে ব্যবহার করুন পরবর্তী পিরিয়ডে কম্পোজিট ফ্যাক্টরের অস্থিরতা IC_IR অনুযায়ী IC-এর প্রত্যাশিত মানের সাথে IC-এর আদর্শ বিচ্যুতি দ্বারা বিভক্ত, সর্বোত্তম ওজন দ্রবণ যা কম্পোজিট ফ্যাক্টর IC_IRকে সর্বাধিক করে তোলে।
প্রিন্সিপাল কম্পোনেন্ট অ্যানালাইসিস (PCA) পদ্ধতি: PCA হল ডেটা ডাইমেনশ্যালিটি কমানোর একটি সাধারণ পদ্ধতি।
এই নিবন্ধটি ম্যানুয়ালি ফ্যাক্টর কার্যকারিতা ওজনের উল্লেখ করবে। অনুগ্রহ করে উপরে প্রবর্তিত পদ্ধতি পড়ুন:ae933a8c-5a94-4d92-8f33-d92b70c36119.pdf
একটি একক ফ্যাক্টর পরীক্ষা করার সময় ক্রম নির্ধারণ করা হয়, কিন্তু মাল্টি-ফ্যাক্টর সংশ্লেষণের জন্য সম্পূর্ণ ভিন্ন ডেটা একত্রে একত্রিত করা প্রয়োজন, তাই সমস্ত কারণকে প্রমিত করা দরকার এবং চরম মান এবং অনুপস্থিত মানগুলি সাধারণত সরানো দরকার। এখানে আমরা df_volume\factor_1\factor_7\factor_6\factor_8 সংশ্লেষণ ব্যবহার করি।
python
#标准化函数,去除缺失值和极值,并且进行标准化处理
def norm_factor(factor):
factor = factor.dropna(how='all')
factor_clip = factor.apply(lambda x:x.clip(x.quantile(0.2), x.quantile(0.8)),axis=1)
factor_norm = factor_clip.add(-factor_clip.mean(axis=1),axis ='index').div(factor_clip.std(axis=1),axis ='index')
return factor_norm
df_volume_norm = norm_factor(df_volume)
factor_1_norm = norm_factor(factor_1)
factor_6_norm = norm_factor(factor_6)
factor_7_norm = norm_factor(factor_7)
factor_8_norm = norm_factor(factor_8)
python
factor_total = 0.6*df_volume_norm + 0.4*factor_1_norm + 0.2*factor_6_norm + 0.3*factor_7_norm + 0.4*factor_8_norm
factor_total_res = Test(factor_total, symbols, period=8)
factor_total_res.total.plot(figsize=(15,6),grid=True);
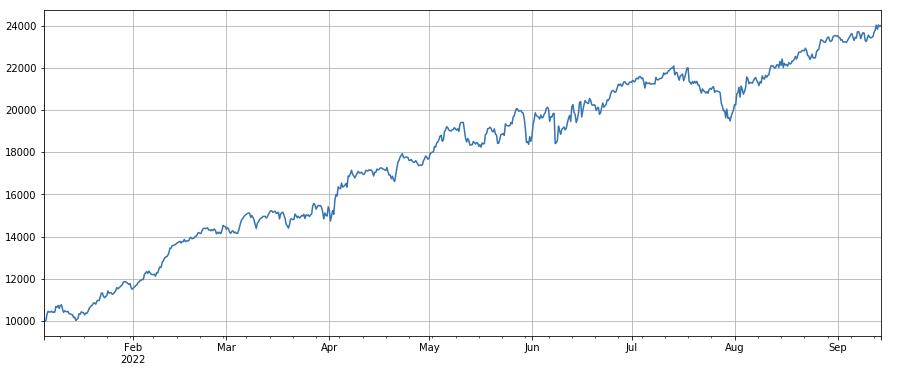
সারসংক্ষেপ
এই নিবন্ধটি একক ফ্যাক্টরগুলির পরীক্ষা পদ্ধতির পরিচয় দেয় এবং এটি বহু-ফ্যাক্টর সংশ্লেষণের পদ্ধতিকেও প্রবর্তন করে, তবে নিবন্ধে উল্লিখিত প্রতিটি বিন্দুতে প্রসারিত করা যেতে পারে গভীরতা, এবং বিভিন্ন কারণগুলিকে গভীরভাবে বিশ্লেষণ করা যেতে পারে এই ধরণের কৌশল গবেষণাকে আলফা ফ্যাক্টরগুলির অন্বেষণে পরিণত করার জন্য ফ্যাক্টর পদ্ধতি ব্যবহার করে ট্রেডিং ধারণাগুলির যাচাইকরণকে অনেক বেশি গতি দিতে পারে৷ তথ্য রেফারেন্স জন্য উপলব্ধ.
আসল ঠিকানা: https://www.fmz.com/robot/486605










- 1