Dự đoán giá Bitcoin theo thời gian thực bằng khung LSTM
 1
1851
1
1851

Lưu ý: Trường hợp này chỉ được sử dụng cho mục đích nghiên cứu và không phải là đề xuất đầu tư.
Dữ liệu giá của Bitcoin dựa trên chuỗi thời gian, do đó, dự đoán giá của Bitcoin chủ yếu được thực hiện bằng mô hình LSTM.
LSTM là một mô hình học sâu đặc biệt phù hợp với dữ liệu theo trình tự thời gian (hoặc dữ liệu có thứ tự thời gian / không gian / cấu trúc, chẳng hạn như phim, câu, v.v.) và là mô hình lý tưởng để dự đoán xu hướng giá của tiền điện tử.
Bài viết này chủ yếu đề cập đến việc kết hợp dữ liệu thông qua LSTM để dự đoán giá Bitcoin trong tương lai.
Thư viện cần import
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout
from matplotlib import pyplot as plt
%matplotlib inline
Phân tích dữ liệu
Tải dữ liệu
Đọc dữ liệu giao dịch hàng ngày của BTC
data = pd.read_csv(filepath_or_buffer="btc_data_day")
Dữ liệu có sẵn, hiện có tổng cộng 1380 dữ liệu, dữ liệu được tạo thành bởi các cột như Date, Open, High, Low, Close, Volume (BTC), Volume (Currency) và Weighted Price. Ngoài cột Date, các cột dữ liệu còn lại là kiểu dữ liệu float64.
data.info()
Hãy xem 10 dòng đầu tiên.
data.head(10)
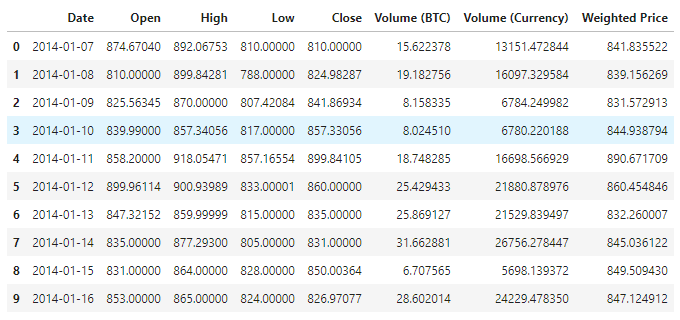
Hình ảnh dữ liệu
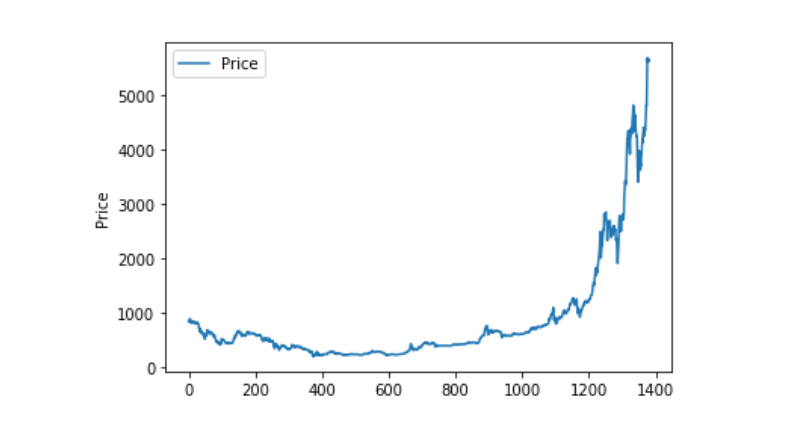
Sử dụng matplotlib để vẽ ra giá cân nặng và xem dữ liệu có phân bố như thế nào. Trong biểu đồ, chúng ta thấy một phần của số 0 và chúng ta cần xác định liệu có bất thường trong số liệu không.
plt.plot(data['Weighted Price'], label='Price')
plt.ylabel('Price')
plt.legend()
plt.show()
Quá trình xử lý dữ liệu bất thường
Chúng ta có thể thấy rằng chúng ta không có dữ liệu nan trong dữ liệu của chúng ta.
data.isnull().sum()
Date 0
Open 0
High 0
Low 0
Close 0
Volume (BTC) 0
Volume (Currency) 0
Weighted Price 0
dtype: int64
Chúng ta có thể thấy rằng chúng ta có một số 0 trong dữ liệu của chúng ta, và chúng ta cần phải xử lý số 0 này.
(data == 0).astype(int).any()
Date False
Open True
High True
Low True
Close True
Volume (BTC) True
Volume (Currency) True
Weighted Price True
dtype: bool
data['Weighted Price'].replace(0, np.nan, inplace=True)
data['Weighted Price'].fillna(method='ffill', inplace=True)
data['Open'].replace(0, np.nan, inplace=True)
data['Open'].fillna(method='ffill', inplace=True)
data['High'].replace(0, np.nan, inplace=True)
data['High'].fillna(method='ffill', inplace=True)
data['Low'].replace(0, np.nan, inplace=True)
data['Low'].fillna(method='ffill', inplace=True)
data['Close'].replace(0, np.nan, inplace=True)
data['Close'].fillna(method='ffill', inplace=True)
data['Volume (BTC)'].replace(0, np.nan, inplace=True)
data['Volume (BTC)'].fillna(method='ffill', inplace=True)
data['Volume (Currency)'].replace(0, np.nan, inplace=True)
data['Volume (Currency)'].fillna(method='ffill', inplace=True)
(data == 0).astype(int).any()
Date False
Open False
High False
Low False
Close False
Volume (BTC) False
Volume (Currency) False
Weighted Price False
dtype: bool
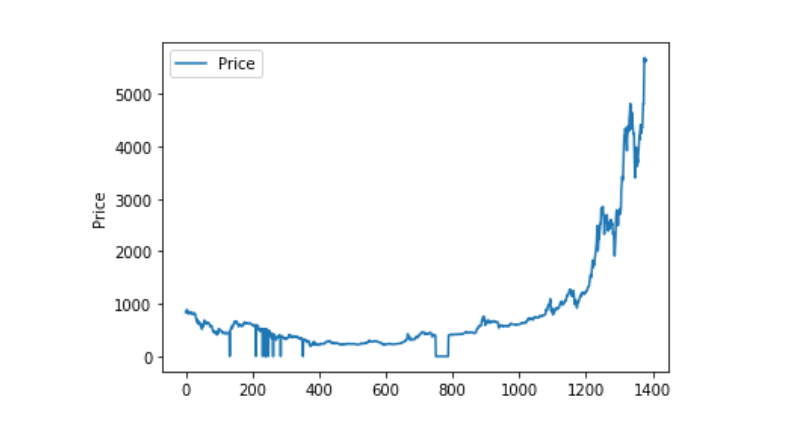
Và khi chúng ta nhìn vào sự phân bố của các dữ liệu, chúng ta thấy rằng các đường cong này rất liên tục.
plt.plot(data['Weighted Price'], label='Price')
plt.ylabel('Price')
plt.legend()
plt.show()
Phân chia tập dữ liệu đào tạo và tập dữ liệu thử nghiệm
Định dạng dữ liệu thành 0-1
data_set = data.drop('Date', axis=1).values
data_set = data_set.astype('float32')
mms = MinMaxScaler(feature_range=(0, 1))
data_set = mms.fit_transform(data_set)
Phân chia tập dữ liệu thử nghiệm và tập dữ liệu đào tạo bằng 2:8
ratio = 0.8
train_size = int(len(data_set) * ratio)
test_size = len(data_set) - train_size
train, test = data_set[0:train_size,:], data_set[train_size:len(data_set),:]
Tạo tập dữ liệu đào tạo và tập dữ liệu thử nghiệm với 1 ngày làm khoảng thời gian cửa sổ để tạo tập dữ liệu đào tạo và tập dữ liệu thử nghiệm của chúng tôi.
def create_dataset(data):
window = 1
label_index = 6
x, y = [], []
for i in range(len(data) - window):
x.append(data[i:(i + window), :])
y.append(data[i + window, label_index])
return np.array(x), np.array(y)
train_x, train_y = create_dataset(train)
test_x, test_y = create_dataset(test)
Xác định mô hình và đào tạo
Lần này chúng ta dùng một mô hình đơn giản, mô hình này có cấu trúc như sau 1. LSTM2. Dense。
Input Shape có kích thước là ((batch_size, time steps, features)). Trong đó, giá trị time steps là khoảng thời gian của cửa sổ thời gian khi nhập dữ liệu, ở đây chúng tôi sử dụng 1 ngày làm cửa sổ thời gian, và dữ liệu của chúng tôi là dữ liệu ngày, vì vậy ở đây bước thời gian của chúng tôi là 1.
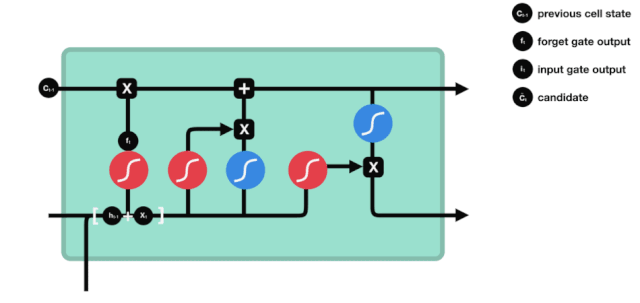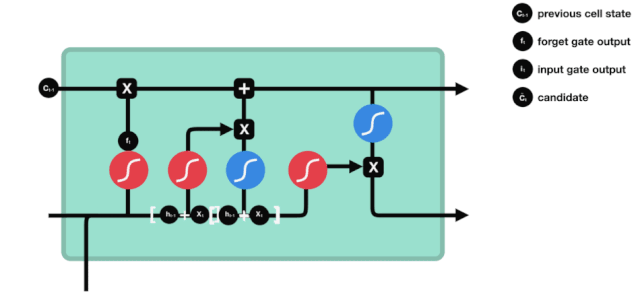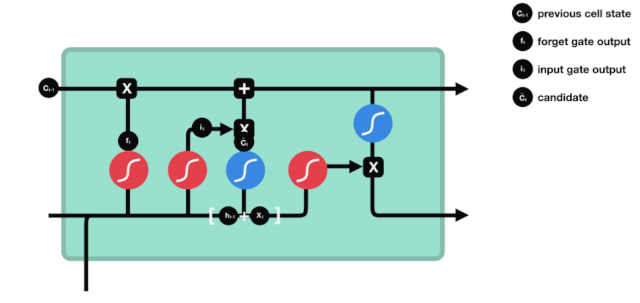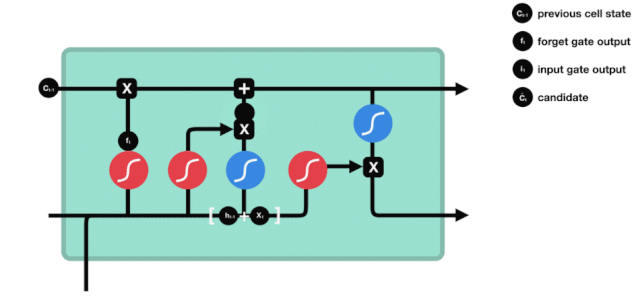
Bộ nhớ ngắn hạn dài (LSTM) là một loại RNN đặc biệt, chủ yếu là để giải quyết các vấn đề biến mất độ bậc và nổ độ bậc trong quá trình đào tạo chuỗi dài.
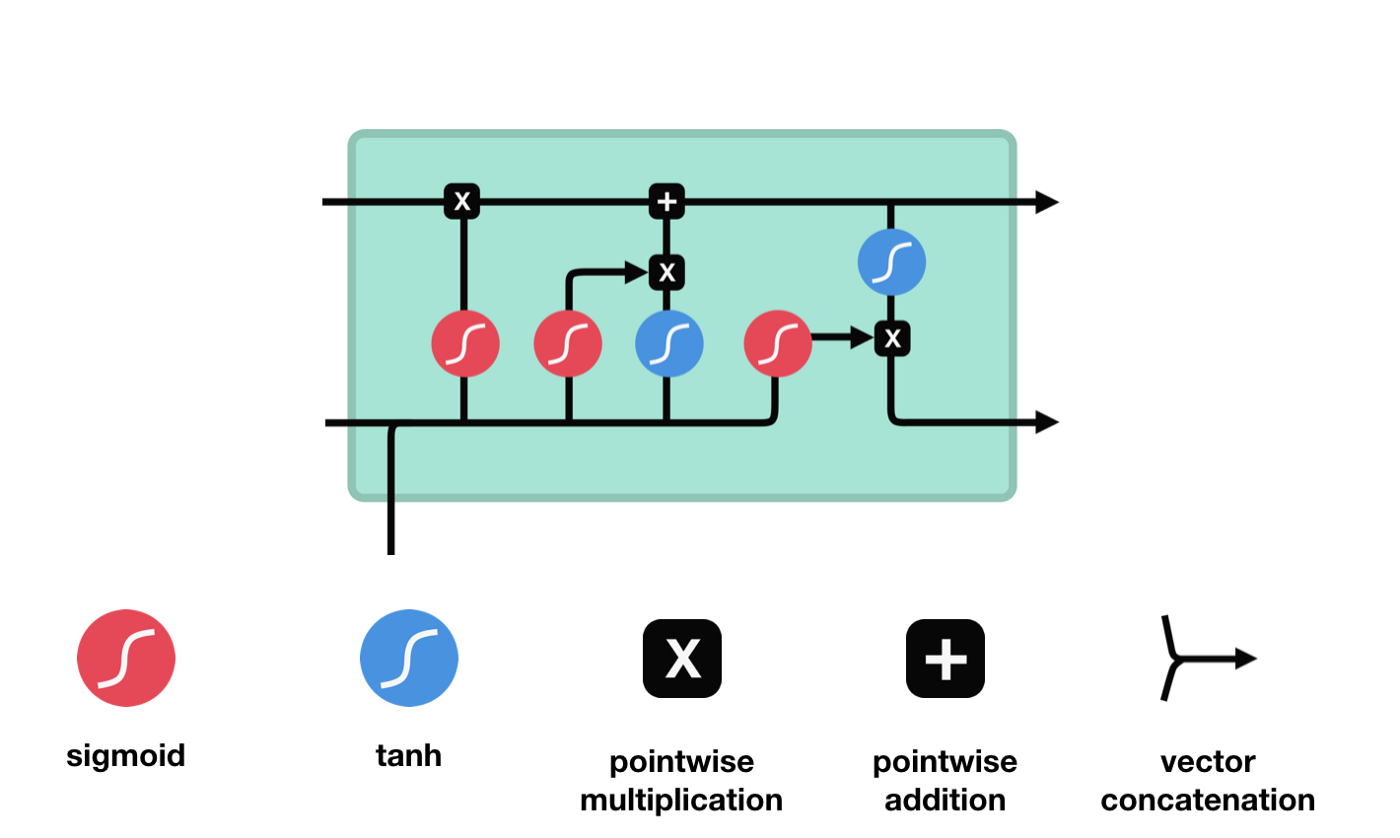
Từ biểu đồ cấu trúc mạng của LSTM, có thể thấy LSTM thực sự là một mô hình nhỏ, nó chứa 3 hàm kích hoạt sigmoid, 2 hàm kích hoạt tanh, 3 phép nhân và 1 phép cộng.
Tình trạng tế bào
Trạng thái tế bào là cốt lõi của LSTM, là đường màu đen ở trên cùng của biểu đồ trên, bên dưới đường màu đen là một số cửa, chúng tôi giới thiệu sau đây. Các trạng thái tế bào sẽ được cập nhật theo kết quả của mỗi cửa.
Mạng LSTM có thể xóa hoặc thêm thông tin về trạng thái tế bào thông qua một cấu trúc được gọi là cửa. Cửa có thể quyết định chọn lọc thông tin nào để thông qua. Cửa được cấu trúc là một lớp sigmoid và một kết hợp của thao tác nhân điểm. Vì đầu ra của lớp sigmoid là giá trị 0-1, 0 không thể thông qua, 1 có thể thông qua.
Cổng quên lãng
Bước đầu tiên của LSTM là quyết định thông tin mà trạng thái tế bào cần loại bỏ. Phần này được xử lý bởi một đơn vị sigmoid gọi là cửa quên.
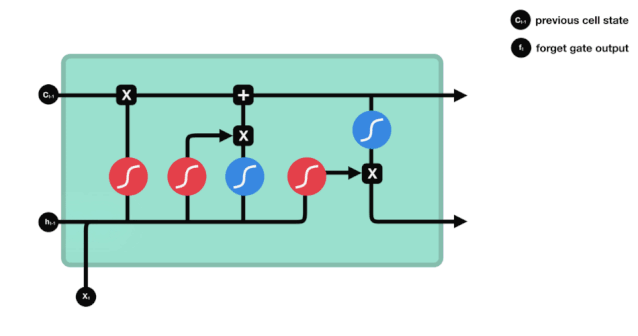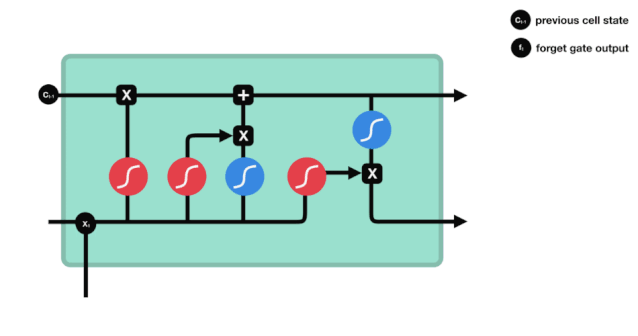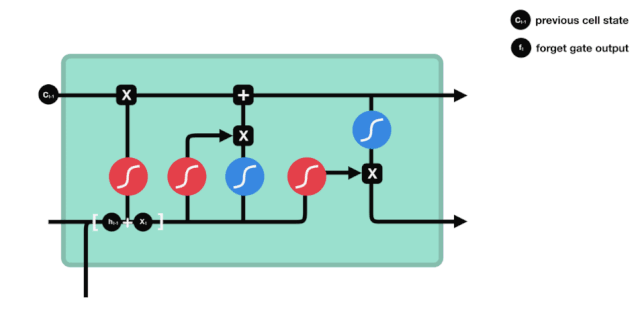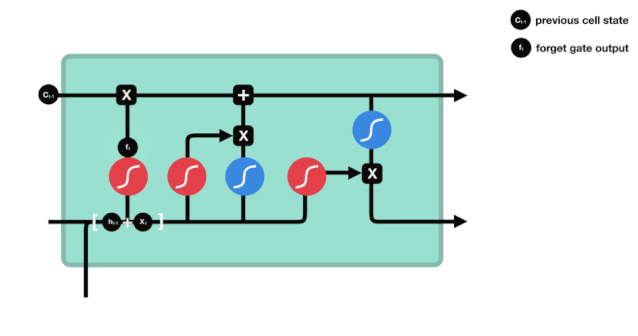
Chúng ta có thể thấy rằng cổng lãng quên, bằng cách xem thông tin \(h_{l-1}\) và \(x_{t}\), sẽ đưa ra một vector từ 0 đến 0, trong đó giá trị 0 đến 1 cho biết trong trạng thái \(C_{t-1}\) của tế bào, thông tin nào được giữ lại hoặc bị loại bỏ.
Biểu thức toán học: \(f_{t}=\sigma\left(W_{f} \cdot\left[h_{t-1}, x_{t}\right]+b_{f}\right)\)
Lối vào
Bước tiếp theo là quyết định thêm thông tin mới nào vào trạng thái của tế bào, và bước này được thực hiện bằng cách mở cửa nhập.
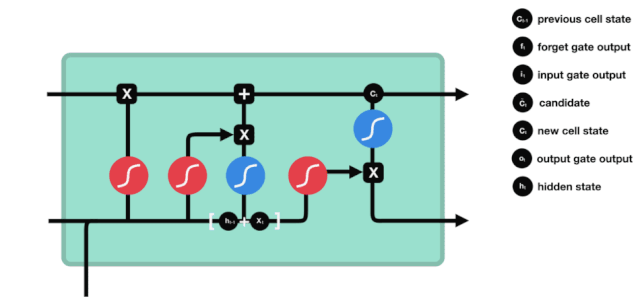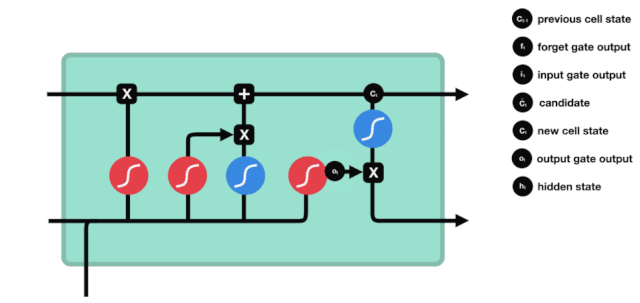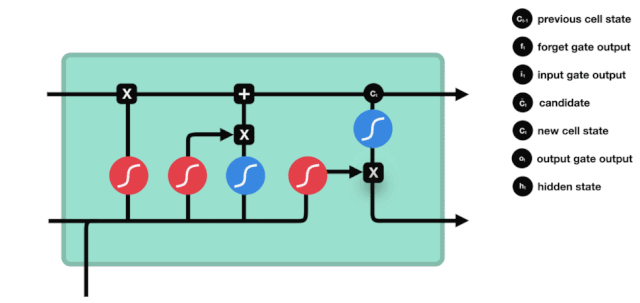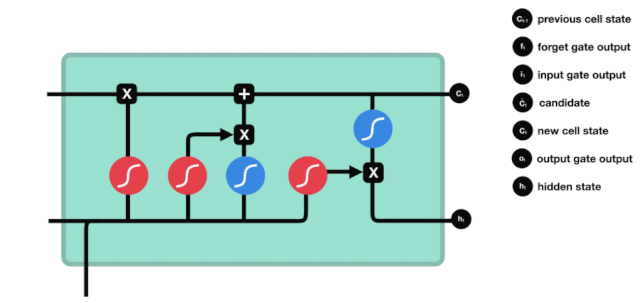
Chúng ta thấy thông tin \(h_{l-1}\) và \(x_{t}\) được đưa vào một cổng quên (sigmoid) và cổng đầu vào (tanh). Bởi vì đầu ra của cổng quên là giá trị 0-1, do đó, nếu cổng quên đầu ra là 0, kết quả \(C_{i}\) sau cổng đầu vào sẽ không được thêm vào trạng thái tế bào hiện tại, nếu là 1, tất cả sẽ được thêm vào trạng thái tế bào, do đó, chức năng của cổng quên ở đây là chọn lọc kết quả đầu vào vào trạng thái tế bào.
Công thức toán học là: \(C_{t}=f_{t} * C_{t-1}+i_{t} *\tilde{C}_{t}\)
Cửa ra
Sau khi cập nhật trạng thái tế bào, cần phải đánh giá các đặc tính trạng thái của tế bào đầu ra dựa trên tổng \( h_{l-1}\) và \( x_{t}\) đầu vào, ở đây cần đưa đầu vào thông qua một lớp sigmoid được gọi là cửa ra, sau đó đưa trạng thái tế bào thông qua lớp tanh để có được một vector có giá trị từ -1 đến 1, và vector này được nhân với các điều kiện được đưa ra bởi cửa ra để có được đầu ra của đơn vị RNN cuối cùng.
def create_model():
model = Sequential()
model.add(LSTM(50, input_shape=(train_x.shape[1], train_x.shape[2])))
model.add(Dense(1))
model.compile(loss='mae', optimizer='adam')
model.summary()
return model
model = create_model()

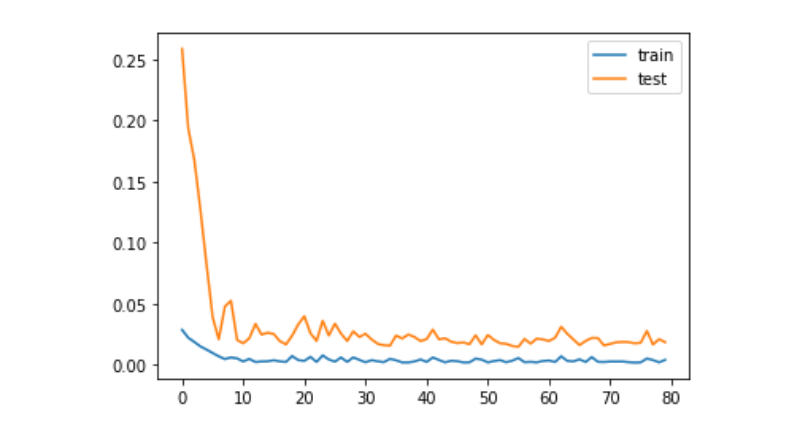
history = model.fit(train_x, train_y, epochs=80, batch_size=64, validation_data=(test_x, test_y), verbose=1, shuffle=False)
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
plt.legend()
plt.show()
train_x, train_y = create_dataset(train)
test_x, test_y = create_dataset(test)
Dự đoán
predict = model.predict(test_x)
plt.plot(predict, label='predict')
plt.plot(test_y, label='ground true')
plt.legend()
plt.show()
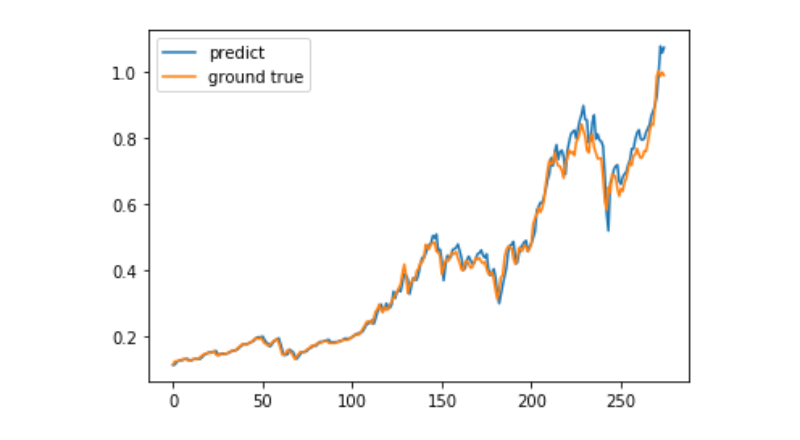
Hiện tại, việc sử dụng học máy để dự đoán biến động giá dài hạn của Bitcoin vẫn rất khó khăn, bài viết này chỉ được sử dụng như một trường hợp học. Trường hợp này sau đó sẽ được đưa lên mạng với các hình ảnh demo của METC, người dùng quan tâm có thể trải nghiệm trực tiếp.