
在使用发明者量化工作流的过程中,许多开发者在评论区和社群里提出了大量疑问。本文整理了这些高频问题,涵盖环境配置、节点使用、数据读取、AI调用、回测机制等各个方面,帮助大家快速找到解决方案。
一、环境配置类问题
Q1:为什么我的实盘无法运行工作流策略?
只有最新版本的托管者才支持运行工作流。如果你的托管者版本过旧,工作流策略就无法启动,需要及时更新到最新版本。
Q2:工作流支持哪些编程语言?
工作流的代码节点只支持JavaScript,不支持Python。如果你习惯用Python写策略,需要转换成JS语法。好在JS和Python的基本逻辑是相通的,主要是语法差异。
二、节点运行机制
Q3:工作流中的节点是同时触发还是依次执行?
工作流节点是严格串联的,只能一个接一个触发,不会并行运行。每个节点必须等前面的节点执行完成后才会开始,大家在设置策略机制的时候需要考虑到这一特性。
Q4:为什么设置了K线更新节点后,工作流一直在等待不执行?
如果你设置了1小时K线更新触发,那么工作流会等待到整点K线收盘才开始运行。在等待期间,工作流不会执行,这是正常的。如果你希望在等待期间执行不同的策略逻辑,可以设置第二个触发器执行你的策略逻辑。
三、数据读取与变量保存
Q5:如何读取某个节点的输出数据?
标准写法是:
javascript
$node["节点名称"].json
这个语法可以读取任意节点的JSON输出。但这里有个限制,只能读取直接相连的父节点数据。如果两个节点之间没有直接连接关系,就不能用这种方式读取。
Q6:如何在不直接相连的节点之间共享数据?
可以使用_G全局变量。_G是FMZ工作流提供的全局内存存储,可以在任何节点、任何flow之间共享数据。
用法很简单:
javascript
// 保存数据
_G("变量名", 值)
// 读取数据
_G("变量名")
但要特别注意,_G中的变量会一直存在,即使实盘重启也不会清除。如果发现读取到了错误的旧数据,需要手动设置_G("变量名",null)来清除,或者直接删除实盘重新创建。
Q7:什么时候需要使用JSON.stringify?
在处理复杂数据时,经常需要用到JSON.stringify方法。这个方法可以把复杂的对象和数组转成文本字符串,这在传递数据给AI节点时特别有用,因为AI只能理解文本格式的输入。
四、代码节点的数据传递
Q8:代码节点必须要返回数据吗?
是的,这是一个非常关键的要求。代码节点最后必须return返回数据,才能保持数据在节点之间的传递。即使你的代码逻辑不需要输出任何数据,也要返回一个空数组:
javascript
return {}
如果忘记return,后续节点就接收不到数据,导致整个工作流中断。
Q9:如何处理节点输出的多项数据?
如果你的某个节点输出了多条数据,比如获取了10条新闻,而你需要整合处理而不是分别处理,这时候不能直接传给下一个节点,需要使用合并节点或者聚合节点,把多项数据整合成一个数据包。
这样做的好处是数据结构清晰,方便后续节点处理。比如要把多条新闻传给AI分析,就需要先聚合成一个数组,AI才能一次性看到所有信息。
五、AI节点配置与调试
Q10:AI节点出现错误,首先应该检查什么?
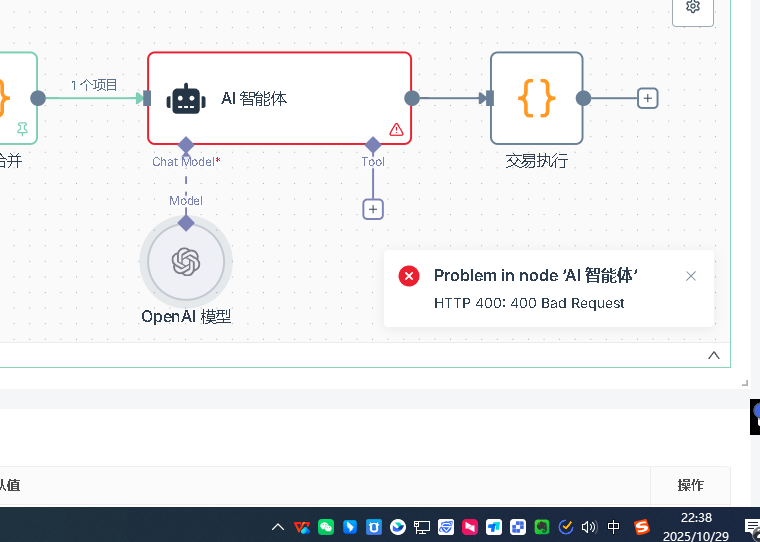
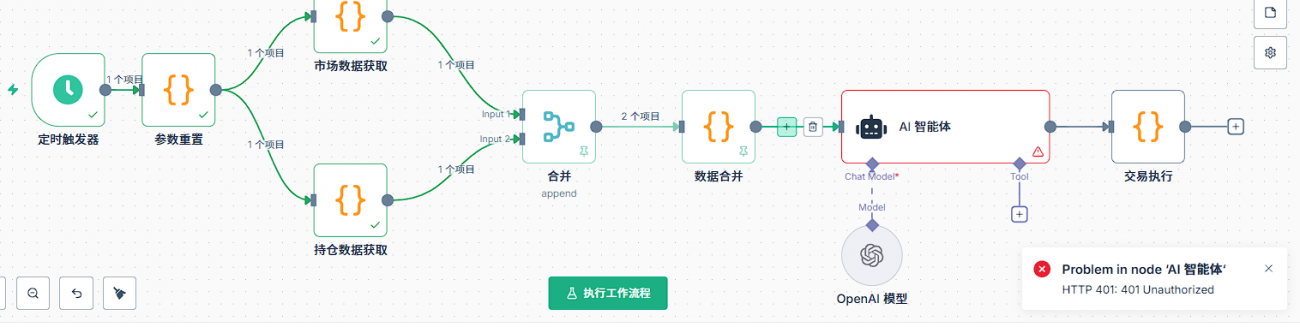
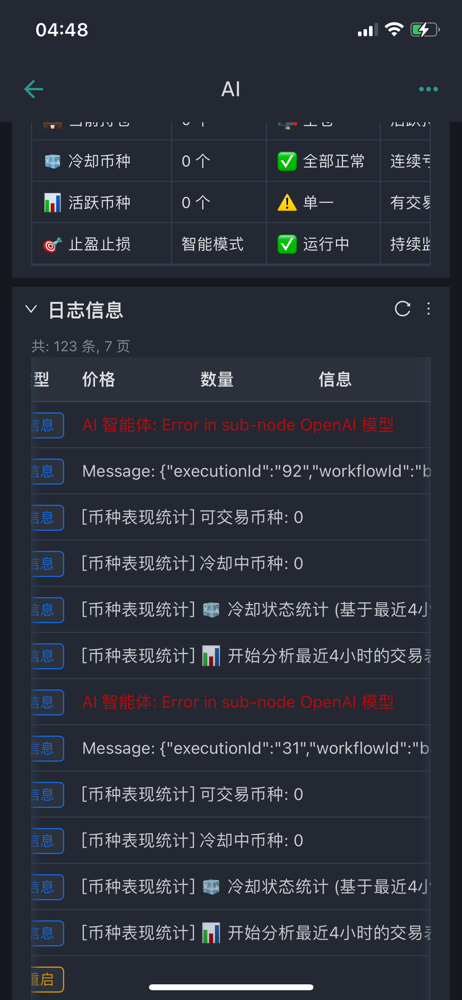
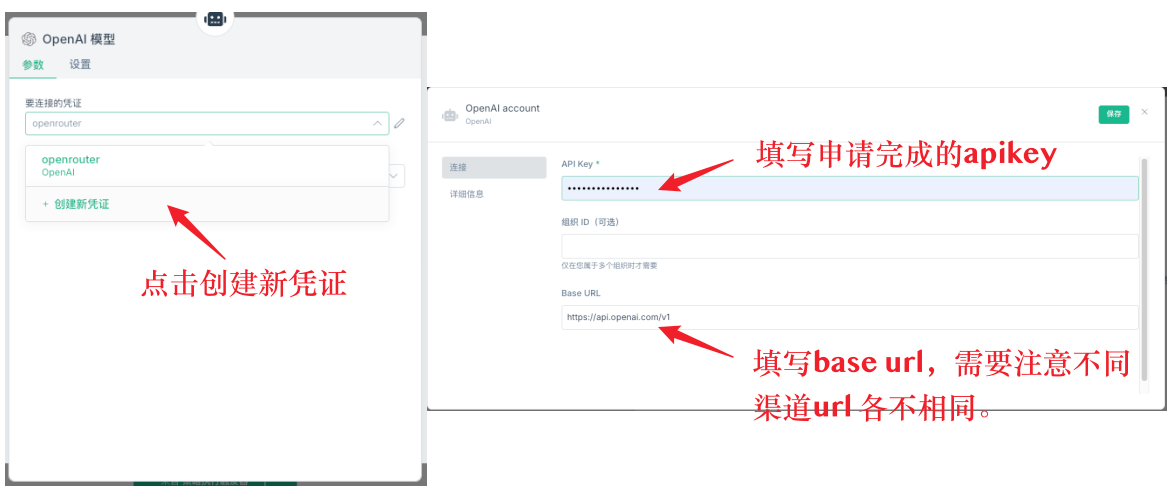
首先是AI节点的基础设置。AI节点需要添加model模型,在model中必须设置凭证。首先创建新凭证,凭证配置包括两个关键信息:API key和base url。API key是你在对应平台申请的密钥,base url是API的请求地址。特别要注意,不同渠道的base url是不同的,比如OpenRouter、DeepSeek、还是其他代理服务,它们的base url都不一样,一定要填对。
Q11:使用哪个API服务比较好?
不建议使用deepseek的直属API,因为响应较慢容易超时,而且额度有限制。推荐使用OpenRouter,它可以连接各种大模型,稳定性和速度都更好。
Q12:AI调用会产生费用吗?
是的,AI调用是要花钱的,每次请求都会消耗token。如果遇到调用失败,要检查账户余额是否充足。建议在测试策略逻辑阶段使用便宜的模型,确认策略逻辑正确后再换成更强大的模型。
Q13:如何编写有效的AI指导语(prompt)?
这是一门艺术,需要根据不同大模型的特性优化。比如Grok比较激进,Claude比较谨慎,DeepSeek因为用A股数据训练有天然的做多倾向。了解这些特性,才能写出更有效的prompt。
六、AI模型稳定性与风控
Q14:AI模型的决策稳定吗?
AI模型目前还不是完全稳定的。虽然AI能够提升策略的决策质量,但它本身也可能出现误判。不同的市场环境、不同的新闻表述、甚至同样的输入在不同时间都可能得到不同的输出。这种不确定性是AI的固有特性。
Q15:使用AI策略时需要注意什么?
在使用AI策略时,一定要加上严格的风控措施。比如:设置单笔交易的最大亏损额度,设置总仓位的上限,加入止损止盈逻辑,不要让AI完全控制资金。
AI应该是你的决策辅助工具,而不是全权委托的对象。人工监控和风险控制始终不能缺少。随着AI技术的发展,模型会越来越稳定,但现阶段保持谨慎是明智的选择。
七、AI策略回测的特殊性
Q16:包含AI的策略可以正常回测吗?
包含AI的策略在回测上有很大的特殊性,这点必须理解清楚。常规策略可以用历史数据随便回测,但AI策略不行。
为什么?因为每次调用AI都要消耗token,产生实际费用。如果你用一年的历史数据回测,可能要调用成千上万次AI,成本会非常高昂。
FMZ为了保护大家的钱包,设计了一个机制:在回测模式下,AI节点只会真实调用三次,后续都使用这三次的缓存数据。所以回测结果只是一个参考,不能代表真实的AI决策质量。
Q17:使用最新新闻的AI策略能回测吗?
如果你的策略调用了最新新闻信息,回测就更不合理了。因为你用的是过去的K线数据,但读取的是当前的新闻,两者时间完全不匹配,这样的回测结果毫无意义。
Q18:那应该如何测试AI策略?
建议的方法是:用小资金、小周期进行实盘测试,观察一段时间的AI决策质量和策略表现,确认稳定后再逐步放大资金。对AI策略来说,实盘验证远比历史回测重要。
八、HTTP和MCP节点配置
Q19:HTTP节点获取不到数据怎么办?
HTTP节点和MCP节点通常用来获取外部数据,但很多API服务是需要密钥才能访问的。如果你配置了HTTP请求但一直获取不到数据,要检查是否需要API密钥,是否正确配置了认证信息。有些API还有请求频率限制,如果调用太频繁会被限流甚至封禁。
Q20:如何提高外部数据获取的稳定性?
MCP节点更加强大,可以连接到各种结构化数据服务,但配置也更复杂。需要正确设置服务端点、认证方式、请求参数等。建议先用HTTP节点测试API能否正常访问,确认数据格式后再集成到工作流中。
另外,为了提高稳定性,可以给这些节点添加失败重试机制。在节点设置中开启重试,设置重试次数和间隔时间,这样临时的网络问题就不会导致整个工作流失败。
九、代码兼容性问题
Q21:FMZ工作流和n8n的代码可以互用吗?
发明者工作流是基于n8n开源框架量化定制的,但两者的代码不能直接互相复制使用。如果你在网上找到n8n的工作流代码,直接粘贴到FMZ是运行不了的,需要根据FMZ的API和节点规范进行修改。反过来,FMZ的工作流代码也不能直接用在n8n上。
主要的差异在于:FMZ对某些节点做了定制化改造,参数和输出格式都有所不同。如果要迁移代码,需要仔细检查每个节点的配置和函数调用,确保符合目标平台的规范。
总结
以上就是发明者量化工作流的常见问题解答。我们覆盖了从环境配置、节点机制、数据读取、代码规范、AI调用到回测测试的各个方面,这些都是实战中的高频问题。掌握了这些知识点,你在开发工作流时会少走很多弯路。
但量化交易是一个持续学习的过程,新的问题会不断出现。遇到问题不要气馁,先查看FMZ的官方文档,搜索社群里的讨论,很多问题都有前人遇到过。如果实在解决不了,可以在平台发起工单询问工程师。也欢迎大家在评论区留言,和其他量化交易者一起交流经验。
记住:问题是最好的老师,每解决一个问题,你对工作流的理解就会深入一分。希望这份FAQ能够帮助大家更顺利地使用工作流开发量化策略!


- 1