উচ্চ ফ্রিকোয়েন্সি ট্রেডিং কৌশল সম্পর্কে চিন্তাভাবনা (2)
লেখক:লিডিয়া, সৃষ্টিঃ ২০২৩-০৮-০৪ ১৭ঃ১৭ঃ৩০, আপডেটঃ ২০২৩-০৯-১২ ১৫ঃ৫০ঃ৩১
উচ্চ ফ্রিকোয়েন্সি ট্রেডিং কৌশল সম্পর্কে চিন্তাভাবনা (2)
সংকলিত লেনদেনের পরিমাণ মডেলিং
পূর্ববর্তী নিবন্ধে, আমরা একটি একক বাণিজ্য পরিমাণ একটি নির্দিষ্ট মানের চেয়ে বড় হওয়ার সম্ভাবনা জন্য একটি অভিব্যক্তি প্রাপ্ত।
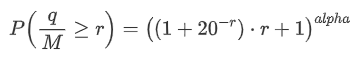
আমরা একটি নির্দিষ্ট সময়ের মধ্যে ট্রেডিং পরিমাণ বিতরণ আগ্রহী, যা স্বজ্ঞাতভাবে পৃথক বাণিজ্য পরিমাণ এবং আদেশ ফ্রিকোয়েন্সি সম্পর্কিত করা উচিত। নীচে, আমরা নির্দিষ্ট ব্যবধানে তথ্য প্রক্রিয়া এবং পূর্ববর্তী বিভাগে কি অনুরূপ তার বিতরণ গ্রাফ।
[1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
[2] এঃ
trades = pd.read_csv('HOOKUSDT-aggTrades-2023-01-27.csv')
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
buy_trades.index = buy_trades['date']
আমরা 1 সেকেন্ডের ব্যবধানে পৃথক বাণিজ্যের পরিমাণগুলি একত্রিত করি যাতে কোনও ট্রেডিং ক্রিয়াকলাপ ছাড়াই সময়কাল ছাড়াই সমষ্টিগত ট্রেডিং পরিমাণ পাওয়া যায়। আমরা তারপরে পূর্বে উল্লিখিত একক বাণিজ্যের পরিমাণ বিশ্লেষণ থেকে প্রাপ্ত বিতরণ ব্যবহার করে এই সমষ্টিগত পরিমাণটি ফিট করি। ফলাফলগুলি 1 সেকেন্ডের ব্যবধানের মধ্যে প্রতিটি বাণিজ্যকে একক বাণিজ্য হিসাবে বিবেচনা করার সময় একটি ভাল ফিট দেখায়, কার্যকরভাবে সমস্যাটি সমাধান করে। তবে, যখন ব্যবসায়ের ফ্রিকোয়েন্সির তুলনায় সময় ব্যবধান বাড়ানো হয়, তখন আমরা ত্রুটিগুলির বৃদ্ধি লক্ষ্য করি। আরও গবেষণা প্রকাশ করে যে এই ত্রুটিটি প্যারেটো বিতরণ দ্বারা প্রবর্তিত সংশোধন মেয়াদ দ্বারা সৃষ্ট। এটি পরামর্শ দেয় যে সময় বাড়ার সাথে সাথে আরও পৃথক বাণিজ্য অন্তর্ভুক্ত করে, একাধিক ব্যবসায়ের সমষ্টি প্যারেটো বিতরণের আরও ঘনিষ্ঠভাবে কাছে আসে, সংশোধন মেয়াদ অপসারণের প্রয়োজন হয়।
[3] এঃ
df_resampled = buy_trades['quantity'].resample('1S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
[4] এঃ
# Cumulative distribution in 1s
depths = np.array(range(0, 3000, 5))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
আউট[4]:
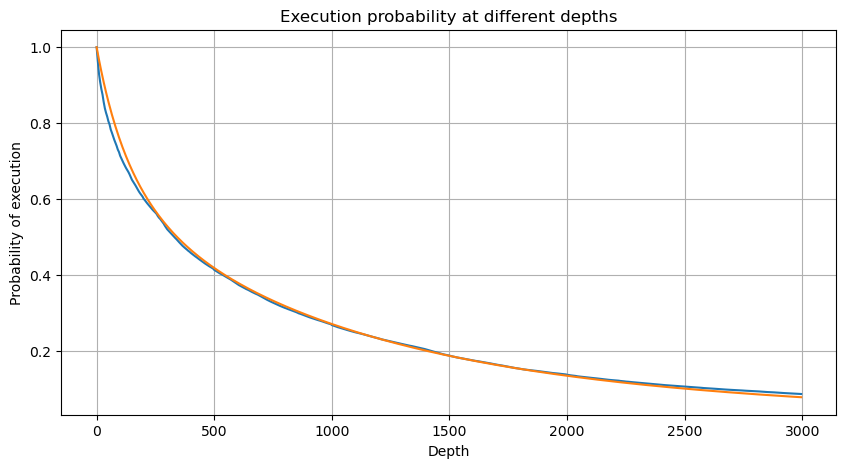
[5] এঃ
df_resampled = buy_trades['quantity'].resample('30S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 12000, 20))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2)
probabilities_s_2 = np.array([(depth/mean+1)**alpha for depth in depths]) # No amendment
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities,label='Probabilities (True)')
plt.plot(depths, probabilities_s, label='Probabilities (Simulation 1)')
plt.plot(depths, probabilities_s_2, label='Probabilities (Simulation 2)')
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.legend()
plt.grid(True)
আউট[5]:
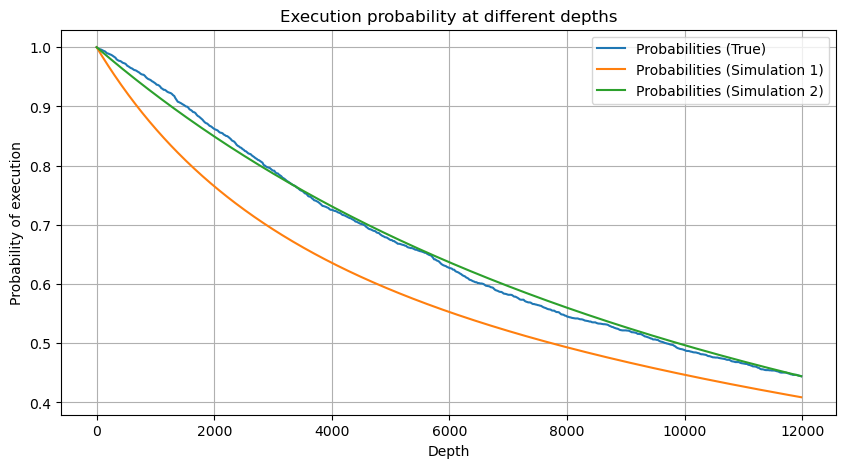
এখন বিভিন্ন সময়কালের জন্য সঞ্চিত ট্রেডিং পরিমাণ বিতরণের জন্য একটি সাধারণ সূত্র সংক্ষিপ্ত বিবরণ, ফিট করার জন্য একক লেনদেনের পরিমাণ বিতরণ ব্যবহার করে, প্রতিটি সময় পৃথকভাবে গণনা করার পরিবর্তে। এখানে সূত্রঃ
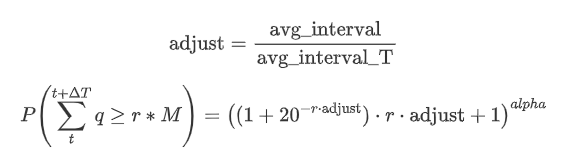
এখানে, avg_interval একক লেনদেনের গড় ব্যবধানকে উপস্থাপন করে, এবং avg_interval_T অনুমান করা দরকার এমন ব্যবধানের গড় ব্যবধানকে উপস্থাপন করে। এটি কিছুটা বিভ্রান্তিকর মনে হতে পারে। যদি আমরা 1 সেকেন্ডের জন্য ট্রেডিং পরিমাণ অনুমান করতে চাই তবে আমাদের 1 সেকেন্ডের মধ্যে লেনদেন থাকা ইভেন্টগুলির মধ্যে গড় ব্যবধান গণনা করতে হবে। যদি অর্ডারের আগমনের সম্ভাবনা একটি পয়েসন বিতরণ অনুসরণ করে তবে এটি সরাসরি অনুমানযোগ্য হওয়া উচিত। তবে বাস্তবে, একটি উল্লেখযোগ্য বিচ্যুতি রয়েছে, তবে আমি এখানে এটি বিশদ করব না।
মনে রাখবেন যে একটি নির্দিষ্ট সময়ের ব্যবধানের মধ্যে একটি নির্দিষ্ট মান অতিক্রম করার ট্রেডিং পরিমাণের সম্ভাবনা এবং গভীরতার মধ্যে সেই অবস্থানে ট্রেডিংয়ের প্রকৃত সম্ভাবনা বেশ আলাদা হওয়া উচিত। অপেক্ষার সময় বাড়ার সাথে সাথে অর্ডার বইয়ের পরিবর্তনের সম্ভাবনা বৃদ্ধি পায় এবং ট্রেডিংও গভীরতার পরিবর্তনের দিকে পরিচালিত করে। অতএব, ডেটা আপডেটের সাথে একই গভীরতার অবস্থানে ট্রেডিংয়ের সম্ভাবনা রিয়েল-টাইমে পরিবর্তন হয়।
[6] এঃ
df_resampled = buy_trades['quantity'].resample('2S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 6500, 10))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = buy_trades['quantity'].mean()
adjust = buy_trades['interval'].mean() / 2620
alpha = np.log(np.mean(buy_trades['quantity'] > mean))/0.7178397931503168
probabilities_s = np.array([((1+20**(-depth*adjust/mean))*depth*adjust/mean+1)**(alpha) for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
আউট[6]:
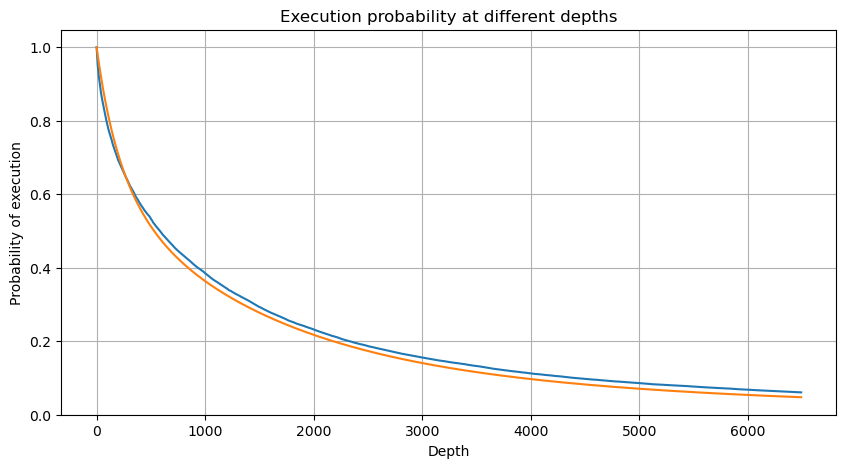
একক বাণিজ্য মূল্যের প্রভাব
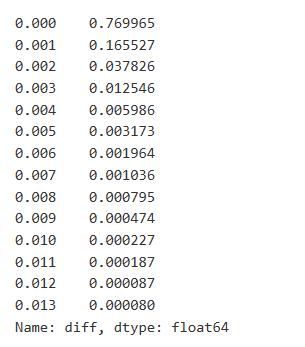
ট্রেড ডেটা মূল্যবান, এবং এখনও অনেক ডেটা আছে যা খনন করা যায়। আমাদের মূল্যের উপর অর্ডারের প্রভাবের দিকে খুব মনোযোগ দেওয়া উচিত, কারণ এটি কৌশলগুলির অবস্থানকে প্রভাবিত করে। একইভাবে, লেনদেন_টাইমের উপর ভিত্তি করে ডেটা একত্রিত করে, আমরা শেষ মূল্য এবং প্রথম মূল্যের মধ্যে পার্থক্য গণনা করি। যদি কেবলমাত্র একটি অর্ডার থাকে তবে দামের পার্থক্য ০। আকর্ষণীয়ভাবে, কিছু ডেটা ফলাফল রয়েছে যা নেতিবাচক, যা ডেটা অর্ডার করার কারণে হতে পারে, তবে আমরা এখানে এটিতে গভীরভাবে প্রবেশ করব না।
ফলাফলগুলি দেখায় যে কোনও প্রভাব সৃষ্টি না করে এমন ব্যবসায়ের অনুপাত 77% পর্যন্ত, যখন 1 টি টিকের দামের আন্দোলনের কারণ ব্যবসায়ের অনুপাত 16.5%, 2 টি টিক 3.7%, 3 টি টিক 1.2%, এবং 4 টিরও বেশি টিক 1% এরও কম। এটি মূলত একটি এক্সপোনেনশিয়াল ফাংশনের বৈশিষ্ট্য অনুসরণ করে, তবে ফিটিংটি সঠিক নয়।
অতিরিক্ত প্রভাবের কারণে বিকৃতিকে বাদ দিয়ে সংশ্লিষ্ট মূল্য পার্থক্যের কারণ হ'ল ব্যবসায়ের পরিমাণও বিশ্লেষণ করা হয়েছিল। এটি একটি রৈখিক সম্পর্ক দেখায়, প্রতি 1000 ইউনিট পরিমাণের কারণে প্রায় 1 টি টিক দামের ওঠানামা। এটি অর্ডার বইয়ের প্রতিটি মূল্য স্তরের কাছাকাছি স্থাপন করা প্রায় 1000 ইউনিটের অর্ডারগুলির গড় হিসাবেও বোঝা যায়।
[৭] এঃ
diff_df = trades[trades['is_buyer_maker']==False].groupby('transact_time')['price'].agg(lambda x: abs(round(x.iloc[-1] - x.iloc[0],3)) if len(x) > 1 else 0)
buy_trades['diff'] = buy_trades['transact_time'].map(diff_df)
[8] এঃ
diff_counts = buy_trades['diff'].value_counts()
diff_counts[diff_counts>10]/diff_counts.sum()
আউট[8]:
[৯] এঃ
diff_group = buy_trades.groupby('diff').agg({
'quantity': 'mean',
'diff': 'last',
})
[১০] এঃ
diff_group['quantity'][diff_group['diff']>0][diff_group['diff']<0.01].plot(figsize=(10,5),grid=True);
আউট[10]:
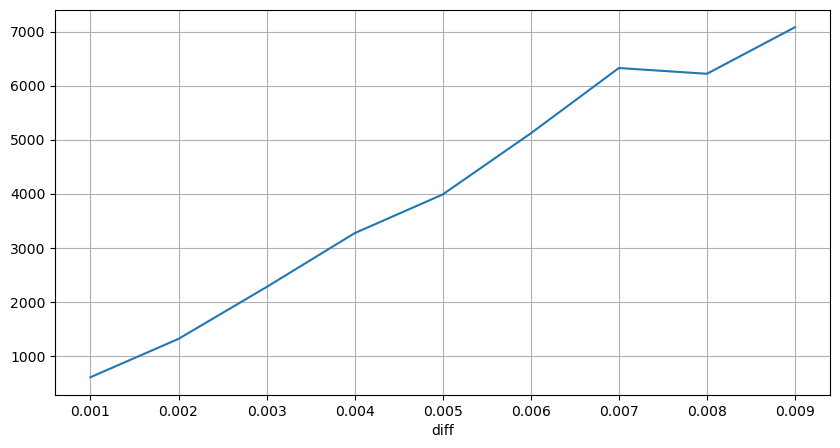
স্থির সময়ের দামের প্রভাব
আসুন 2 সেকেন্ডের ব্যবধানে মূল্যের প্রভাব বিশ্লেষণ করি। পার্থক্য এখানে এটি যে নেতিবাচক মান থাকতে পারে। তবে, যেহেতু আমরা কেবল ক্রয় আদেশ বিবেচনা করছি, তাই সমান্তরাল অবস্থানের উপর প্রভাব এক টিক বেশি হবে। বাণিজ্য পরিমাণ এবং প্রভাবের মধ্যে সম্পর্ক পর্যবেক্ষণ অব্যাহত রেখে, আমরা কেবলমাত্র 0 এর চেয়ে বড় ফলাফল বিবেচনা করি। উপসংহারটি একক আদেশের অনুরূপ, প্রতিটি টিকের জন্য প্রায় 2000 ইউনিট পরিমাণের প্রয়োজন সহ আনুমানিক রৈখিক সম্পর্ক দেখায়।
[11] এঃ
df_resampled = buy_trades.resample('2S').agg({
'price': ['first', 'last', 'count'],
'quantity': 'sum'
})
df_resampled['price_diff'] = round(df_resampled[('price', 'last')] - df_resampled[('price', 'first')],3)
df_resampled['price_diff'] = df_resampled['price_diff'].fillna(0)
result_df_raw = pd.DataFrame({
'price_diff': df_resampled['price_diff'],
'quantity_sum': df_resampled[('quantity', 'sum')],
'data_count': df_resampled[('price', 'count')]
})
result_df = result_df_raw[result_df_raw['price_diff'] != 0]
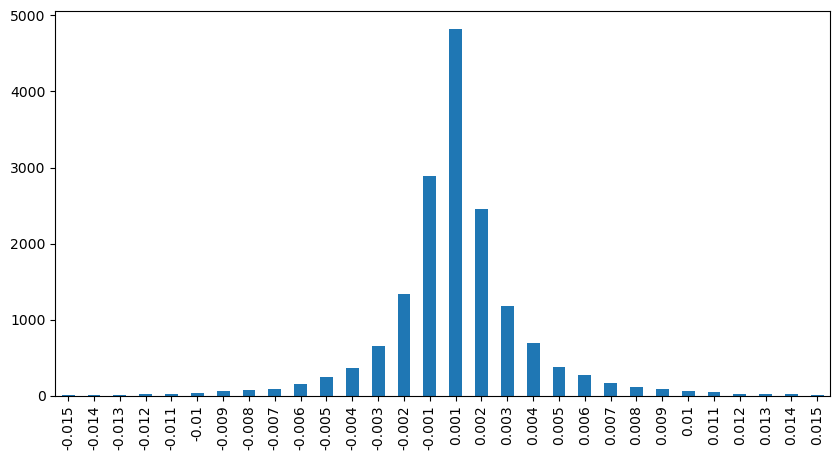
[১২] এঃ
result_df['price_diff'][abs(result_df['price_diff'])<0.016].value_counts().sort_index().plot.bar(figsize=(10,5));
আউট[১২]:
[২৩] এঃ
result_df['price_diff'].value_counts()[result_df['price_diff'].value_counts()>30]
আউট[23]:
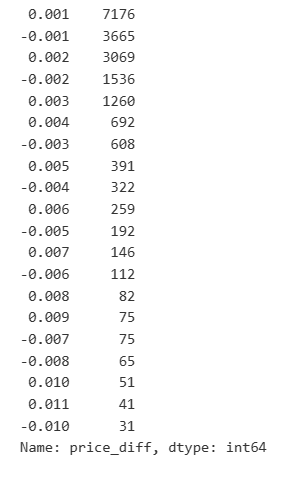
[14] এঃ
diff_group = result_df.groupby('price_diff').agg({ 'quantity_sum': 'mean'})
[15] এঃ
diff_group[(diff_group.index>0) & (diff_group.index<0.015)].plot(figsize=(10,5),grid=True);
আউট[15]:
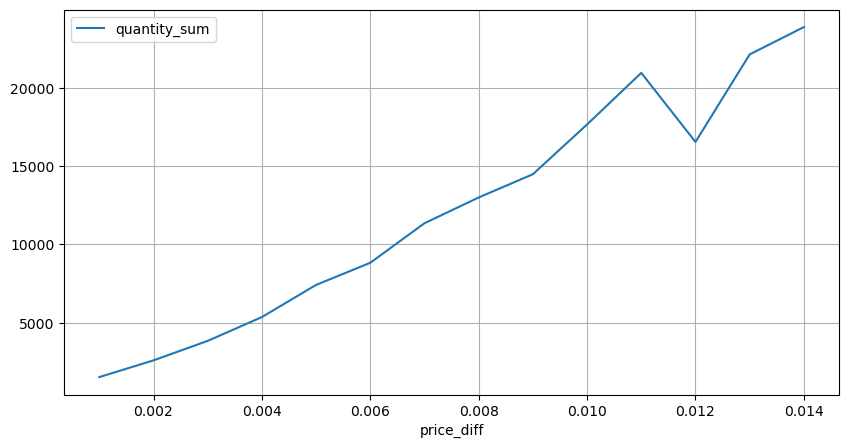
বাণিজ্যের পরিমাণের দামের প্রভাব
পূর্বে, আমরা একটি টিক পরিবর্তনের জন্য প্রয়োজনীয় ট্রেড পরিমাণ নির্ধারণ করেছি, কিন্তু এটি সঠিক ছিল না কারণ এটি অনুমান করা হয়েছিল যে প্রভাব ইতিমধ্যে ঘটেছে। এখন, আসুন দৃষ্টিভঙ্গিটি উল্টে দিন এবং ট্রেড পরিমাণ দ্বারা সৃষ্ট মূল্য প্রভাব পরীক্ষা করুন।
এই বিশ্লেষণে, তথ্য প্রতি 1 সেকেন্ডে নমুনা করা হয়, প্রতিটি পদক্ষেপ পরিমাণ 100 ইউনিট প্রতিনিধিত্ব করে। তারপর আমরা এই পরিমাণ পরিসীমা মধ্যে মূল্য পরিবর্তন গণনা। এখানে কিছু মূল্যবান সিদ্ধান্তঃ
- যখন ক্রয় আদেশের পরিমাণ 500 এর নিচে হয়, তখন প্রত্যাশিত মূল্য পরিবর্তন হ্রাস হয়, যা প্রত্যাশিত কারণ দামের উপর প্রভাব ফেলতে বিক্রয় আদেশও রয়েছে।
- কম বাণিজ্যিক পরিমাণে, একটি রৈখিক সম্পর্ক রয়েছে, যার অর্থ হল যে বাণিজ্যিক পরিমাণ যত বড়, দামের বৃদ্ধি তত বেশি।
- ক্রয় আদেশের পরিমাণ বাড়ার সাথে সাথে দামের পরিবর্তন আরও উল্লেখযোগ্য হয়ে ওঠে। এটি প্রায়শই দামের অগ্রগতি নির্দেশ করে, যা পরে ফিরে আসতে পারে। অতিরিক্তভাবে, স্থির ব্যবধানের নমুনা গ্রহণ ডেটা অস্থিতিশীলতা যুক্ত করে।
- বিচ্ছিন্নতা গ্রাফের উপরের অংশে মনোযোগ দেওয়া গুরুত্বপূর্ণ, যা বাণিজ্যের পরিমাণের সাথে দামের বৃদ্ধিকে প্রতিফলিত করে।
- এই নির্দিষ্ট ট্রেডিং জোড়ার জন্য, আমরা ট্রেড পরিমাণ এবং মূল্য পরিবর্তনের মধ্যে সম্পর্কের একটি মোটামুটি সংস্করণ প্রদান করি।
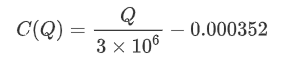
যেখানে
[১৬] এঃ
df_resampled = buy_trades.resample('1S').agg({
'price': ['first', 'last', 'count'],
'quantity': 'sum'
})
df_resampled['price_diff'] = round(df_resampled[('price', 'last')] - df_resampled[('price', 'first')],3)
df_resampled['price_diff'] = df_resampled['price_diff'].fillna(0)
result_df_raw = pd.DataFrame({
'price_diff': df_resampled['price_diff'],
'quantity_sum': df_resampled[('quantity', 'sum')],
'data_count': df_resampled[('price', 'count')]
})
result_df = result_df_raw[result_df_raw['price_diff'] != 0]
[২৪] এঃ
df = result_df.copy()
bins = np.arange(0, 30000, 100) #
labels = [f'{i}-{i+100-1}' for i in bins[:-1]]
df.loc[:, 'quantity_group'] = pd.cut(df['quantity_sum'], bins=bins, labels=labels)
grouped = df.groupby('quantity_group')['price_diff'].mean()
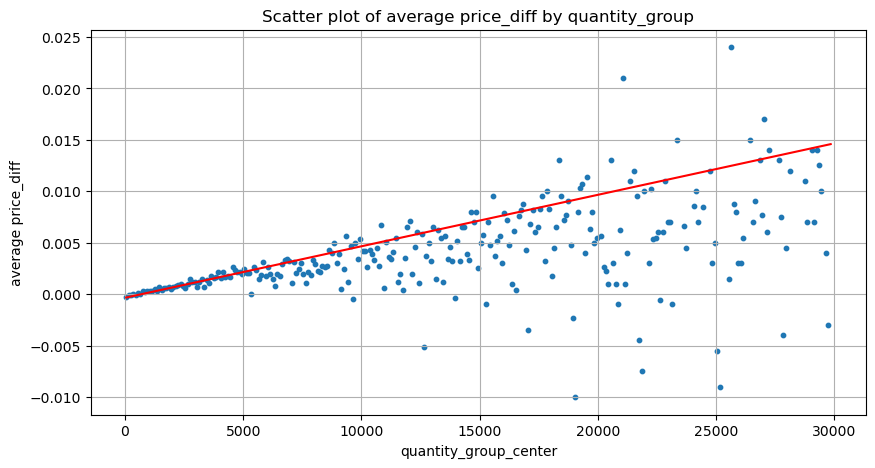
[২৫] এঃ
grouped_df = pd.DataFrame(grouped).reset_index()
grouped_df['quantity_group_center'] = grouped_df['quantity_group'].apply(lambda x: (float(x.split('-')[0]) + float(x.split('-')[1])) / 2)
plt.figure(figsize=(10,5))
plt.scatter(grouped_df['quantity_group_center'], grouped_df['price_diff'],s=10)
plt.plot(grouped_df['quantity_group_center'], np.array(grouped_df['quantity_group_center'].values)/2e6-0.000352,color='red')
plt.xlabel('quantity_group_center')
plt.ylabel('average price_diff')
plt.title('Scatter plot of average price_diff by quantity_group')
plt.grid(True)
আউট[২৫]:
[19] এঃ
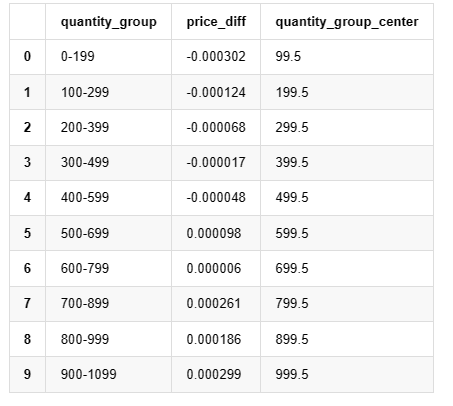
grouped_df.head(10)
আউট[19]: ,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
প্রাথমিক সর্বোত্তম অর্ডার স্থাপন
ট্রেড পরিমাণের মডেলিং এবং ট্রেড পরিমাণের সাথে সামঞ্জস্যপূর্ণ মূল্যের প্রভাবের মোটামুটি মডেল দিয়ে, সর্বোত্তম অর্ডার স্থাপন গণনা করা সম্ভব বলে মনে হয়। আসুন কিছু অনুমান করি এবং একটি দায়িত্বহীন সর্বোত্তম মূল্য অবস্থান সরবরাহ করি।
- অনুমান করুন যে প্রভাবের পরে মূল্য তার মূল মান ফিরে আসে (যা অত্যন্ত অসম্ভব এবং প্রভাবের পরে মূল্য পরিবর্তনের আরও বিশ্লেষণ প্রয়োজন হবে) ।
- অনুমান করুন যে এই সময়ের মধ্যে ব্যবসায়ের পরিমাণ এবং আদেশের ফ্রিকোয়েন্সি একটি পূর্বনির্ধারিত প্যাটার্ন অনুসরণ করে (যাও ভুল, কারণ আমরা এক দিনের তথ্যের ভিত্তিতে অনুমান করছি এবং ট্রেডিং স্পষ্ট ক্লাস্টারিং ঘটনা প্রদর্শন করে) ।
- অনুমান করুন যে সিমুলেটেড সময়ের মধ্যে কেবলমাত্র একটি বিক্রয় অর্ডার ঘটে এবং তারপরে বন্ধ হয়।
- অনুমান করুন যে অর্ডারটি কার্যকর হওয়ার পরে, অন্যান্য ক্রয় অর্ডার রয়েছে যা দামকে বাড়িয়ে তুলতে থাকে, বিশেষত যখন পরিমাণটি খুব কম হয়। এই প্রভাবটি এখানে উপেক্ষা করা হয়, এবং এটি কেবল অনুমান করা হয় যে দামটি ফিরে আসবে।
আসুন একটি সহজ প্রত্যাশিত রিটার্ন লিখতে শুরু করি, যা 1 সেকেন্ডের মধ্যে Q ছাড়িয়ে যাওয়া ক্রমবর্ধমান ক্রয় আদেশের সম্ভাবনা, প্রত্যাশিত রিটার্ন হার (অর্থাৎ, মূল্যের প্রভাব) দ্বারা গুণিত।
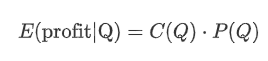
গ্রাফের উপর ভিত্তি করে, সর্বাধিক প্রত্যাশিত রিটার্ন প্রায় 2500 হয়, যা গড় বাণিজ্যের পরিমাণের প্রায় 2.5 গুণ। এটি পরামর্শ দেয় যে বিক্রয় অর্ডারটি 2500 এর মূল্য পজিশনে স্থাপন করা উচিত। এটি জোর দেওয়া গুরুত্বপূর্ণ যে অনুভূমিক অক্ষটি 1 সেকেন্ডের মধ্যে বাণিজ্যের পরিমাণকে উপস্থাপন করে এবং গভীরতার অবস্থানের সাথে সমান করা উচিত নয়। অতিরিক্তভাবে, এই বিশ্লেষণটি ব্যবসায়ের ডেটাতে ভিত্তি করে এবং গুরুত্বপূর্ণ গভীরতার ডেটা নেই।
সংক্ষিপ্তসার
আমরা আবিষ্কার করেছি যে বিভিন্ন সময়ের ব্যবধানে বাণিজ্যের পরিমাণ বিতরণ পৃথক বাণিজ্যের পরিমাণের বিতরণের একটি সহজ স্কেলিং। আমরা মূল্যের প্রভাব এবং বাণিজ্যের সম্ভাবনার উপর ভিত্তি করে একটি সহজ প্রত্যাশিত রিটার্ন মডেলও তৈরি করেছি। এই মডেলের ফলাফলগুলি আমাদের প্রত্যাশার সাথে সামঞ্জস্যপূর্ণ, এটি দেখায় যে যদি বিক্রয় আদেশের পরিমাণ কম হয় তবে এটি মূল্য হ্রাসের ইঙ্গিত দেয় এবং লাভের সম্ভাবনার জন্য একটি নির্দিষ্ট পরিমাণ প্রয়োজন। বাণিজ্যের পরিমাণ বাড়ার সাথে সাথে সম্ভাবনা হ্রাস পায়, এর মধ্যে একটি অনুকূল আকার রয়েছে, যা অনুকূল অর্ডার স্থাপনের কৌশলকে উপস্থাপন করে। তবে, এই মডেলটি এখনও খুব সরল। পরবর্তী নিবন্ধে, আমি এই বিষয়ে আরও গভীরভাবে আবিষ্কার করব।
[২০] এঃ
# Cumulative distribution in 1s
df_resampled = buy_trades['quantity'].resample('1S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 15000, 10))
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
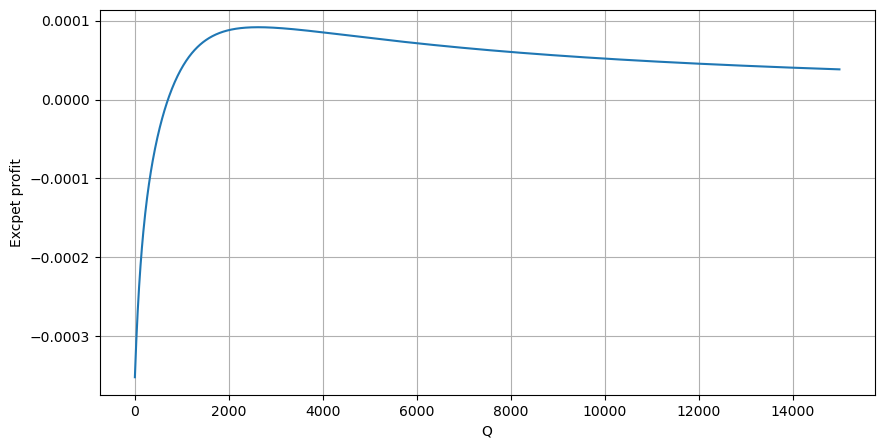
profit_s = np.array([depth/2e6-0.000352 for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities_s*profit_s)
plt.xlabel('Q')
plt.ylabel('Excpet profit')
plt.grid(True)
আউট[20]:
- বিটকয়েনের জন্য ডেল্টা হিজিংয়ের জন্য হাসি কার্ভ ব্যবহার করুন
- উচ্চ ফ্রিকোয়েন্সি ট্রেডিং কৌশল সম্পর্কে চিন্তাভাবনা (5)
- উচ্চ ফ্রিকোয়েন্সি ট্রেডিং কৌশল সম্পর্কে চিন্তাভাবনা (4)
- হাই ফ্রিকোয়েন্সি ট্রেডিং কৌশল সম্পর্কে চিন্তাভাবনা (5)
- হাই ফ্রিকোয়েন্সি ট্রেডিং কৌশল চিন্তা ((4)
- উচ্চ ফ্রিকোয়েন্সি ট্রেডিং কৌশল সম্পর্কে চিন্তাভাবনা (3)
- হাই ফ্রিকোয়েন্সি ট্রেডিং কৌশল সম্পর্কে চিন্তাভাবনা (3)
- হাই ফ্রিকোয়েন্সি ট্রেডিং কৌশল সম্পর্কে চিন্তাভাবনা (২)
- উচ্চ ফ্রিকোয়েন্সি ট্রেডিং কৌশল সম্পর্কে চিন্তাভাবনা (1)
- হাই ফ্রিকোয়েন্সি ট্রেডিং কৌশল সম্পর্কে চিন্তা ((1))
- ফিটু সিকিউরিটিজ কনফিগারেশন বর্ণনা নথি
- FMZ Quant Uniswap V3 এক্সচেঞ্জ পুল লিকুইডিটি সম্পর্কিত অপারেশন গাইড (পার্ট 1)
- FMZ কোয়ালিফাইড Uniswap V3 এক্সচেঞ্জ পুকুর তরলতা সম্পর্কিত অপারেশন গাইড (১)