

1. সংক্ষিপ্ত ভূমিকা
সাম্প্রতিক বছরগুলিতে গভীর নিউরাল নেটওয়ার্কগুলি আরও বেশি জনপ্রিয় হয়ে উঠেছে, অতীতে অনেক ক্ষেত্রে অমীমাংসিত সমস্যাগুলি সমাধান করে এবং শক্তিশালী ক্ষমতা প্রদর্শন করে। টাইম সিরিজের ভবিষ্যদ্বাণীতে, সাধারণত ব্যবহৃত নিউরাল নেটওয়ার্কের মূল্য হল RNN, কারণ RNN-এ শুধুমাত্র বর্তমান ডেটা ইনপুট নয়, তবে অবশ্যই, আমরা যখন RNN মূল্যের পূর্বাভাস সম্পর্কে কথা বলি, তখন আমরা প্রায়ই RNN-এর একটি প্রকারের কথা বলি: LSTM। . এই নিবন্ধটি বিটকয়েনের দামের পূর্বাভাস দেওয়ার জন্য একটি মডেল তৈরি করার ভিত্তি হিসাবে পাইটর্চ ব্যবহার করবে। যদিও ইন্টারনেটে অনেক প্রাসঙ্গিক তথ্য রয়েছে, এটি এখনও যথেষ্ট পুঙ্খানুপুঙ্খ নয়, এবং pytorch ব্যবহার করে এখনও একটি নিবন্ধ লিখতে হবে চূড়ান্ত ফলাফল, ক্লোজিং প্রাইস। বিটকয়েন বাজারের সর্বোচ্চ মূল্য, সর্বনিম্ন মূল্য এবং লেনদেনের পরিমাণ পরবর্তী সমাপনী মূল্যের পূর্বাভাস দিতে। নিউরাল নেটওয়ার্ক সম্পর্কে আমার ব্যক্তিগত জ্ঞান গড়, এবং আমি আপনার সমালোচনা এবং সংশোধনকে স্বাগত জানাই।
এই টিউটোরিয়ালটি FMZ উদ্ভাবক ডিজিটাল কারেন্সি কোয়ান্টিটেটিভ ট্রেডিং প্ল্যাটফর্ম (www.fmz.com) দ্বারা উত্পাদিত হয়েছে যোগাযোগের জন্য QQ গ্রুপে যোগদান করার জন্য: 863946592।
2. ডেটা এবং রেফারেন্স
একটি সম্পর্কিত মূল্য পূর্বাভাসের উদাহরণ: https://yq.aliyun.com/articles/538484
RNN মডেলের বিস্তারিত পরিচিতি: https://zhuanlan.zhihu.com/p/27485750
RNN এর ইনপুট এবং আউটপুট বোঝা: https://www.zhihu.com/question/41949741/answer/318771336
পাইটর্চ সম্পর্কে: অফিসিয়াল ডকুমেন্টেশন https://pytorch.org/docs অন্যান্য তথ্য নিজেই অনুসন্ধান করুন।
এছাড়াও, এই নিবন্ধটি বোঝার জন্য কিছু পূর্বশর্ত জ্ঞান প্রয়োজন, যেমন পান্ডা/ক্রলার/ডেটা প্রসেসিং ইত্যাদি, তবে আপনি যদি এটি না জানেন তবে তাতে কিছু যায় আসে না।
3. pytorch LSTM মডেলের পরামিতি
LSTM এর পরামিতি:
যখন আমি প্রথমবার নথিতে এই ঘনবসতিপূর্ণ প্যারামিটারগুলি দেখেছিলাম, তখন আমার প্রতিক্রিয়া ছিল:

ধীরে ধীরে পড়তে পড়তে অবশেষে বুঝতে পারলাম।

input_size: ইনপুট ভেক্টর x এর বৈশিষ্ট্যগত আকার যদি ক্লোজিং প্রাইস দ্বারা ভবিষ্যদ্বাণী করা হয়, তাহলে ইনপুট_সাইজ=1;
hidden_size: লুকানো স্তরের আকার
num_layers: RNN এর স্তরের সংখ্যা
batch_first: যদি সত্য হয়, প্রথম ইনপুটটি হল ব্যাচ_সাইজ
ইনপুট ডেটা প্যারামিটার:
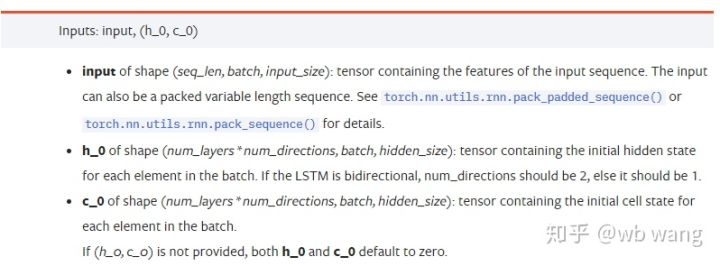
input: নির্দিষ্ট ইনপুট ডেটা হল একটি ত্রিমাত্রিক টেনসর, এবং নির্দিষ্ট আকৃতি হল: (seq_len, ব্যাচ, input_size)। তাদের মধ্যে, seq_len অনুক্রমের দৈর্ঘ্যকে বোঝায়, অর্থাৎ, LSTM কে কতক্ষণের জন্য ঐতিহাসিক ডেটা বিবেচনা করতে হবে মনে রাখবেন যে এটি শুধুমাত্র LSTM মডেলের অভ্যন্তরীণ কাঠামোকে নির্দেশ করে বিভিন্ন seq_len এর ইনপুট ডেটা এবং ফলাফল ব্যাচের আকারকে বোঝায়, যেটি আগের ইনপুট_সাইজের কতগুলি সেট রয়েছে;
h_0: প্রারম্ভিক লুকানো অবস্থা, আকৃতি হল (সংখ্যা_স্তর * সংখ্যা_নির্দেশ, ব্যাচ, লুকানো_ আকার), যদি দ্বিমুখী নেটওয়ার্ক num_directions=2
c_0: প্রাথমিক কোষের অবস্থা, আকৃতিটি উপরের মতই, এবং এটি নির্দিষ্ট করার প্রয়োজন নেই।
আউটপুট পরামিতি:
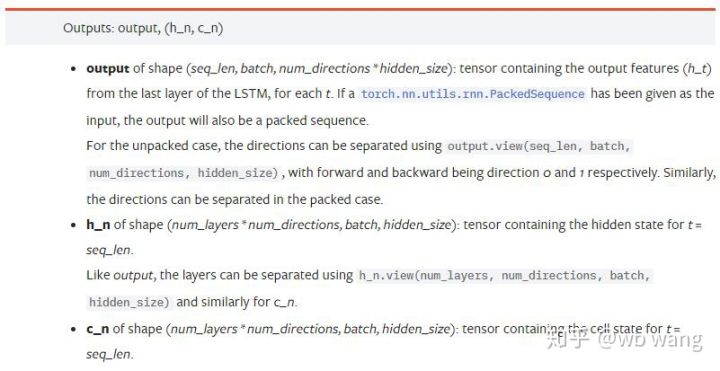
output: আউটপুট আকৃতি (seq_len, ব্যাচ, num_directions * hidden_size), মনে রাখবেন এটি মডেল প্যারামিটার ব্যাচ_প্রথম এর সাথে সম্পর্কিত
h_n: t = h অবস্থা seq_len সময়ে, আকৃতি h_0 এর মতোই
c_n: t = c অবস্থা seq_len সময়ে, আকৃতি c_0 এর মতোই
4. LSTM ইনপুট এবং আউটপুটের সহজ উদাহরণ
প্রথমে প্রয়োজনীয় প্যাকেজ আমদানি করুন
python
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
LSTM মডেলের সংজ্ঞা
python
LSTM = nn.LSTM(input_size=5, hidden_size=10, num_layers=2, batch_first=True)
তথ্য প্রবেশ করাতে হবে
python
x = torch.randn(3,4,5)
# x的值为:
tensor([[[ 0.4657, 1.4398, -0.3479, 0.2685, 1.6903],
[ 1.0738, 0.6283, -1.3682, -0.1002, -1.7200],
[ 0.2836, 0.3013, -0.3373, -0.3271, 0.0375],
[-0.8852, 1.8098, -1.7099, -0.5992, -0.1143]],
[[ 0.6970, 0.6124, -0.1679, 0.8537, -0.1116],
[ 0.1997, -0.1041, -0.4871, 0.8724, 1.2750],
[ 1.9647, -0.3489, 0.7340, 1.3713, 0.3762],
[ 0.4603, -1.6203, -0.6294, -0.1459, -0.0317]],
[[-0.5309, 0.1540, -0.4613, -0.6425, -0.1957],
[-1.9796, -0.1186, -0.2930, -0.2619, -0.4039],
[-0.4453, 0.1987, -1.0775, 1.3212, 1.3577],
[-0.5488, 0.6669, -0.2151, 0.9337, -1.1805]]])
x এর আকৃতি হল (3,4,5), যেহেতু আমরা সংজ্ঞায়িত করেছিbatch_first=True, এই সময়ে, ব্যাচ_সাইজ হল 3, sqe_len হল 4, এবং input_size হল 5। x[0] প্রথম ব্যাচ প্রতিনিধিত্ব করে।
যদি batch_first সংজ্ঞায়িত না করা থাকে, তাহলে এটি ডিফল্টভাবে False তে থাকে এবং ডেটা সম্পূর্ণ ভিন্নভাবে উপস্থাপন করা হয়, যার ব্যাচের আকার 4, sqe_len 3 এবং input_size 5। এই সময়ে x[0] টি = 0 এ সমস্ত ব্যাচের ডেটা উপস্থাপন করে এবং আরও অনেক কিছু। ব্যক্তিগতভাবে, আমি অনুভব করি যে এই সেটিংটি স্বজ্ঞাত নয়, তাই আমি পরামিতি যোগ করেছি।batch_first=True.
উভয়ের মধ্যে ডেটা রূপান্তরও খুব সুবিধাজনক:x.permute(1,0,2)
ইনপুট এবং আউটপুট
LSTM এর ইনপুট এবং আউটপুটের আকৃতি সহজেই বিভ্রান্তিকর, নিম্নলিখিত চিত্রটি বুঝতে সাহায্য করতে পারে:
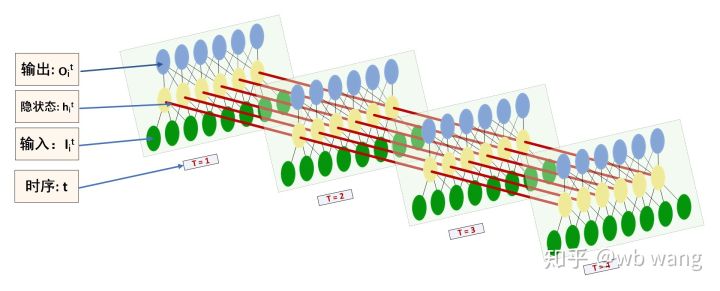
সূত্র: https://www.zhihu.com/question/41949741/answer/318771336
python
x = torch.randn(3,4,5)
h0 = torch.randn(2, 3, 10)
c0 = torch.randn(2, 3, 10)
output, (hn, cn) = LSTM(x, (h0, c0))
print(output.size()) #在这里思考一下,如果batch_first=False输出的大小会是多少?
print(hn.size())
print(cn.size())
#结果
torch.Size([3, 4, 10])
torch.Size([2, 3, 10])
torch.Size([2, 3, 10])
পূর্ববর্তী প্যারামিটার ব্যাখ্যার সাথে সামঞ্জস্যপূর্ণ আউটপুট ফলাফলগুলি পর্যবেক্ষণ করুন। লক্ষ্য করুন যে hn.size() এর দ্বিতীয় মান 3, যা batch_size এর আকারের সাথে সামঞ্জস্যপূর্ণ, যা নির্দেশ করে যে hn তে কোনও মধ্যবর্তী অবস্থা সংরক্ষণ করা হয়নি, শুধুমাত্র শেষ ধাপটি।
যেহেতু আমাদের LSTM নেটওয়ার্কে দুটি স্তর রয়েছে, প্রকৃতপক্ষে, hn এর শেষ স্তরের আউটপুট হল আউটপুটের মান এবং আউটপুটের আকার হল[3, 4, 10], সর্বদা ফলাফল সংরক্ষণ করা t=0,1,2,3, তাই:
python
hn[-1][0] == output[0][-1] #第一个batch在hn最后一层的输出等于第一个batch在t=3时output的结果
hn[-1][1] == output[1][-1]
hn[-1][2] == output[2][-1]
5. বিটকয়েন মার্কেট ডেটা প্রস্তুত করুন
আমি এর আগেও অনেক কিছু বলেছি, কিন্তু এটি LSTM এর ইনপুট এবং আউটপুট বোঝা খুবই গুরুত্বপূর্ণ, অন্যথায়, এর শক্তিশালী ক্ষমতার কারণে এলোমেলোভাবে ভুল করা যায় সময় সিরিজে LSTM, মডেলটি ভুল হলেও, আপনি শেষ পর্যন্ত ফলাফল পেতে পারেন।
ডেটা অধিগ্রহণ
ডেটা বিটফাইনেক্স এক্সচেঞ্জে BTC_USD ট্রেডিং পেয়ারের বাজার ডেটা ব্যবহার করে।
python
import requests
import json
resp = requests.get('https://q.fmz.com/chart/history?symbol=bitfinex.btc_usd&resolution=15&from=0&to=0&from=1525622626&to=1562658565')
data = resp.json()
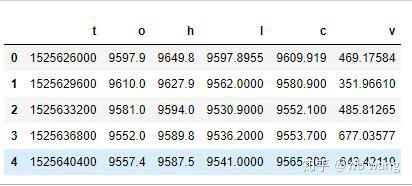
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
print(df.head(5))
তথ্য বিন্যাস নিম্নরূপ:
ডেটা প্রিপ্রসেসিং
python
df.index = df['t'] # index设为时间戳
df = (df-df.mean())/df.std() # 数据的标准化,否则模型的Loss会非常大,不利于收敛
df['n'] = df['c'].shift(-1) # n为下一个周期的收盘价,是我们预测的目标
df = df.dropna()
df = df.astype(np.float32) # 改变下数据格式适应pytorch
ডেটা স্ট্যান্ডার্ডাইজেশন পদ্ধতিটি খুব রুক্ষ এবং কিছু সমস্যা হবে এটি শুধুমাত্র একটি প্রদর্শন হিসাবে ব্যবহার করতে পারেন যেমন রিটার্ন রেট।
প্রশিক্ষণ তথ্য প্রস্তুত
python
seq_len = 10 # 输入10个周期的数据
train_size = 800 # 训练集batch_size
def create_dataset(data, seq_len):
dataX, dataY=[], []
for i in range(0,len(data)-seq_len, seq_len):
dataX.append(data[['o','h','l','c','v']][i:i+seq_len].values)
dataY.append(data['n'][i:i+seq_len].values)
return np.array(dataX), np.array(dataY)
data_X, data_Y = create_dataset(df, seq_len)
train_x = torch.from_numpy(data_X[:train_size].reshape(-1,seq_len,5)) #变化形状,-1代表的值会自动计算
train_y = torch.from_numpy(data_Y[:train_size].reshape(-1,seq_len,1))
ট্রেন_এক্স এবং ট্রেন_ই এর চূড়ান্ত আকার যথাক্রমে: টর্চ। আকার([800, 10, 5]), torch.Size([800, 10, 1])। যেহেতু আমাদের মডেল 10 পিরিয়ডের ডেটার উপর ভিত্তি করে পরবর্তী পিরিয়ডের ক্লোজিং প্রাইসের ভবিষ্যদ্বাণী করে, তাত্ত্বিকভাবে 800 এর একটি ব্যাচের জন্য শুধুমাত্র 800 পূর্বাভাসিত সমাপনী দামের প্রয়োজন। কিন্তু ট্রেন_ওয়াই-এর প্রতিটি ব্যাচে 10টি ডেটা থাকে, প্রকৃতপক্ষে, প্রতিটি ব্যাচের দ্বারা পূর্বাভাস দেওয়া মধ্যবর্তী ফলাফলগুলি শুধুমাত্র শেষটি নয়। চূড়ান্ত ক্ষতি গণনা করার সময়, সমস্ত 10টি ভবিষ্যদ্বাণী ফলাফল বিবেচনায় নেওয়া যেতে পারে এবং ট্রেন_ই এর প্রকৃত মানের সাথে তুলনা করা যেতে পারে। তাত্ত্বিকভাবে, শেষ ভবিষ্যদ্বাণী ফলাফলের শুধুমাত্র ক্ষতি গণনা করাও সম্ভব। এই সমস্যাটি ব্যাখ্যা করার জন্য একটি মোটামুটি চিত্র আঁকুন। যেহেতু LSTM মডেলে আসলে seq_len প্যারামিটার থাকে না, মডেলটি বিভিন্ন দৈর্ঘ্যে প্রয়োগ করা যেতে পারে, এবং মধ্যবর্তী ভবিষ্যদ্বাণী ফলাফলগুলিও অর্থবহ, তাই আমি একত্রিত এবং ক্ষতি গণনা করার প্রবণতা রাখি।
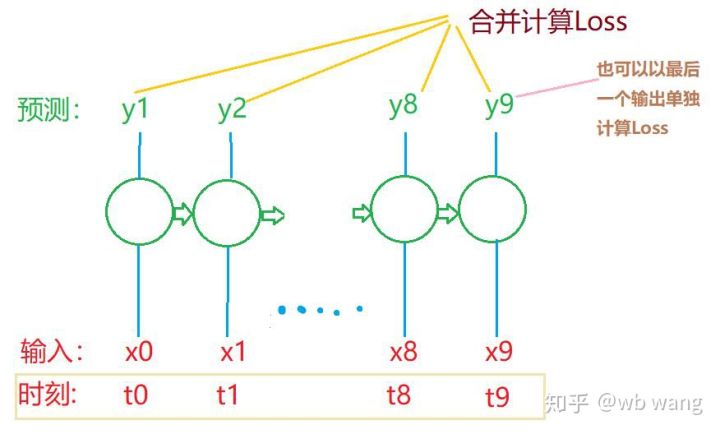
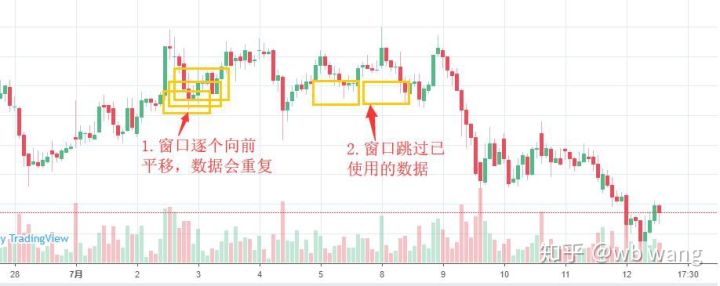
মনে রাখবেন যে প্রশিক্ষণের তথ্য প্রস্তুত করার সময়, উইন্ডোর নড়াচড়া খুব বেশি হয় না এবং ব্যবহৃত ডেটা আর ব্যবহার করা হয় না। অবশ্যই, উইন্ডোগুলিও একে একে সরানো যেতে পারে, যাতে প্রাপ্ত প্রশিক্ষণ সেটটি অনেক বড় হয়। . কিন্তু আমার মনে হয়েছিল যে সংলগ্ন ব্যাচের ডেটা খুব বেশি পুনরাবৃত্তিমূলক ছিল, তাই আমি বর্তমান পদ্ধতিটি গ্রহণ করেছি।
6. LSTM মডেল তৈরি করুন
একটি দ্বি-স্তর LSTM এবং একটি লিনিয়ার স্তর সহ নির্মিত চূড়ান্ত মডেলটি নিম্নরূপ।
python
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size=1, num_layers=2):
super(LSTM, self).__init__()
self.rnn = nn.LSTM(input_size,hidden_size,num_layers,batch_first=True)
self.reg = nn.Linear(hidden_size,output_size) # 线性层,把LSTM的结果输出成一个值
def forward(self, x):
x, _ = self.rnn(x) # 如果不理解前向传播中数据维度的变化,可单独调试
x = self.reg(x)
return x
net = LSTM(5, 10) # input_size为5,代表了高开低收和交易量. 隐含层为10.
7. মডেল প্রশিক্ষণ শুরু করুন
অবশেষে প্রশিক্ষণ শুরু হয়েছে, কোডটি নিম্নরূপ:
python
criterion = nn.MSELoss() # 使用了简单的均方差损失函数
optimizer = torch.optim.Adam(net.parameters(),lr=0.01) # 优化函数,lr可调
for epoch in range(600): # 由于速度很快,这里的epoch多一些
out = net(train_x) # 由于数据量很小, 直接拿全量数据计算
loss = criterion(out, train_y)
optimizer.zero_grad()
loss.backward() # 反向传播损失
optimizer.step() # 更新参数
print('Epoch: {:<3}, Loss:{:.6f}'.format(epoch+1, loss.item()))
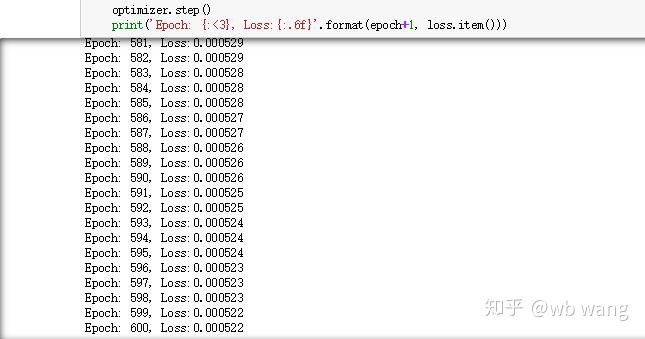
প্রশিক্ষণের ফলাফল নিম্নরূপ:
৮. মডেল মূল্যায়ন
মডেলের পূর্বাভাসিত মান:
python
p = net(torch.from_numpy(data_X))[:,-1,0] # 这里只取最后一个预测值作为比较
plt.figure(figsize=(12,8))
plt.plot(p.data.numpy(), label= 'predict')
plt.plot(data_Y[:,-1], label = 'real')
plt.legend()
plt.show()
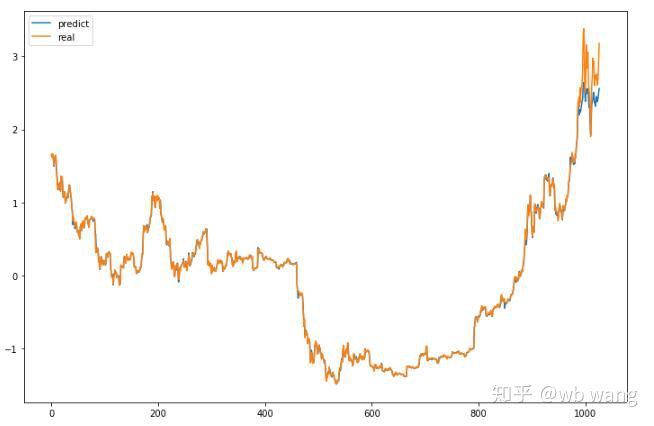
চিত্র থেকে দেখা যায়, প্রশিক্ষণ তথ্য (আগে 800) চুক্তির একটি খুব উচ্চ ডিগ্রী আছে, যদিও, বিটকয়েনের দাম একটি নতুন উচ্চ, এবং দেখা যায় না ভবিষ্যদ্বাণী তা করতে অক্ষম। এটিও দেখায় যে আগের ডেটা স্ট্যান্ডার্ডাইজেশনে সমস্যা ছিল।
যদিও ভবিষ্যদ্বাণী করা মূল্য সঠিক নাও হতে পারে, ভবিষ্যদ্বাণীকৃত বৃদ্ধি বা হ্রাস কতটা সঠিক?
python
r = data_Y[:,-1][800:1000]
y = p.data.numpy()[800:1000]
r_change = np.array([1 if i > 0 else 0 for i in r[1:200] - r[:199]])
y_change = np.array([1 if i > 0 else 0 for i in y[1:200] - r[:199]])
print((r_change == y_change).sum()/float(len(r_change)))
ফলস্বরূপ, বৃদ্ধি এবং পতনের পূর্বাভাসের যথার্থতা 81.4% এ পৌঁছেছে, যা এখনও আমার প্রত্যাশা ছাড়িয়ে গেছে। কোথাও ভুল করেছি কিনা জানি না।
অবশ্যই, এই মডেলের কোন প্রকৃত মূল্য নেই, তবে এটি সহজ এবং সহজে আপনি এটি দিয়ে শুরু করতে পারেন।


