Überlegungen zu Hochfrequenzhandelsstrategien (2)
Schriftsteller:Lydia., Erstellt: 2023-08-04 17:17:30, Aktualisiert: 2023-09-12 15:50:31
Überlegungen zu Hochfrequenzhandelsstrategien (2)
Modelle für den kumulierten Handelsbetrag
Im vorherigen Artikel haben wir einen Ausdruck für die Wahrscheinlichkeit ermittelt, dass ein einzelner Handelsbetrag größer als ein bestimmter Wert ist.
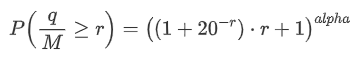
Wir interessieren uns auch für die Verteilung des Handelsbetrags über einen Zeitraum, der intuitiv mit dem einzelnen Handelsbetrag und der Auftragsfrequenz zusammenhängen sollte.
In [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
In [2]:
trades = pd.read_csv('HOOKUSDT-aggTrades-2023-01-27.csv')
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
buy_trades.index = buy_trades['date']
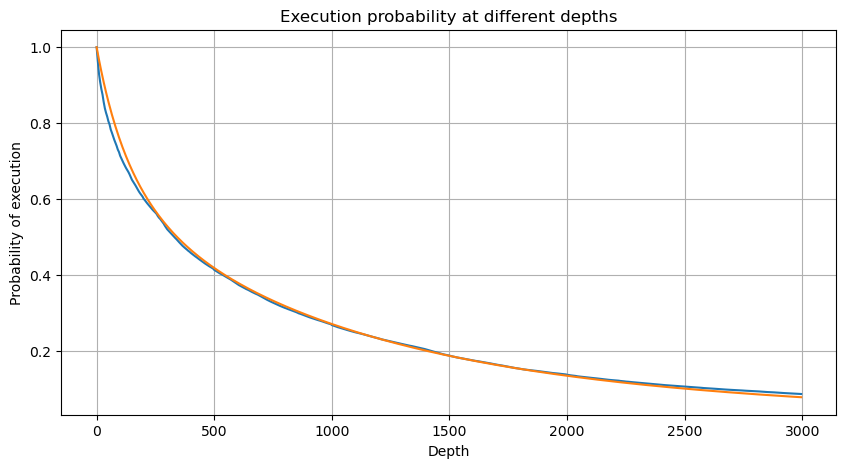
Wir kombinieren die einzelnen Handelsbeträge in Abständen von 1 Sekunde, um den aggregierten Handelsbetrag zu erhalten, ausgenommen die Zeiträume ohne Handelsaktivität. Wir passen diesen aggregierten Betrag dann anhand der zuvor erwähnten Verteilung der einzelnen Handelsbetragsanalyse an. Die Ergebnisse zeigen eine gute Passform, wenn jeder Handel innerhalb des 1-Sekunden-Intervalls als ein einziger Handel betrachtet wird, wodurch das Problem effektiv gelöst wird. Wenn jedoch das Zeitrahmen in Bezug auf die Handelsfrequenz verlängert wird, beobachten wir eine Zunahme der Fehler. Weitere Untersuchungen zeigen, dass dieser Fehler durch den Korrekturbegriff verursacht wird, der durch die Pareto-Verteilung eingeführt wurde. Dies legt nahe, dass sich die Aggregation mehrerer Trades der Pareto-Verteilung näher nähert, was die Beseitigung des Korrekturbegriffs erfordert.
In [3]:
df_resampled = buy_trades['quantity'].resample('1S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
In [4]:
# Cumulative distribution in 1s
depths = np.array(range(0, 3000, 5))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
Ausgeschaltet[4]:
In [5]:
df_resampled = buy_trades['quantity'].resample('30S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 12000, 20))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2)
probabilities_s_2 = np.array([(depth/mean+1)**alpha for depth in depths]) # No amendment
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities,label='Probabilities (True)')
plt.plot(depths, probabilities_s, label='Probabilities (Simulation 1)')
plt.plot(depths, probabilities_s_2, label='Probabilities (Simulation 2)')
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.legend()
plt.grid(True)
Ausgeschaltet[5]:
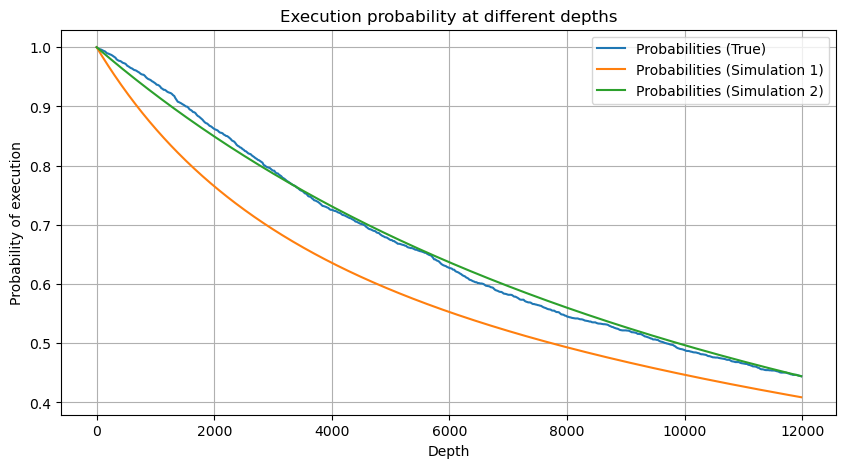
Jetzt fassen Sie eine allgemeine Formel für die Verteilung der kumulierten Handelsbetrag für verschiedene Zeiträume, mit der Verteilung der einzelnen Transaktionsbetrag zu passen, anstatt separat jedes Mal zu berechnen.
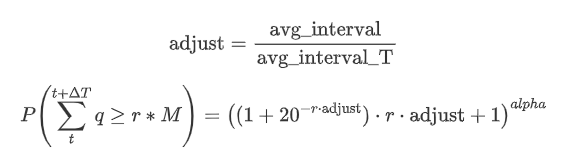
Hier stellt avg_interval das durchschnittliche Intervall einzelner Transaktionen dar, und avg_interval_T das durchschnittliche Intervall des Intervalls, das geschätzt werden muss. Es mag ein wenig verwirrend klingen. Wenn wir den Handelsbetrag für 1 Sekunde schätzen wollen, müssen wir das durchschnittliche Intervall zwischen Ereignissen berechnen, die Transaktionen innerhalb von 1 Sekunde enthalten. Wenn die Ankunftswahrscheinlichkeit von Aufträgen einer Poisson-Verteilung folgt, sollte sie direkt abschätzbar sein. In Wirklichkeit gibt es jedoch eine signifikante Abweichung, aber ich werde sie hier nicht ausführlich erläutern.
Beachten Sie, dass die Wahrscheinlichkeit, dass der Handelsbetrag innerhalb eines bestimmten Zeitabschnitts einen bestimmten Wert übersteigt, und die tatsächliche Wahrscheinlichkeit des Handels an dieser Position in der Tiefe ziemlich unterschiedlich sein sollten. Mit zunehmender Wartezeit steigt die Möglichkeit von Änderungen im Auftragsbuch und der Handel führt auch zu Änderungen in der Tiefe. Daher ändert sich die Wahrscheinlichkeit des Handels an der gleichen Tiefenposition in Echtzeit, wenn die Daten aktualisiert werden.
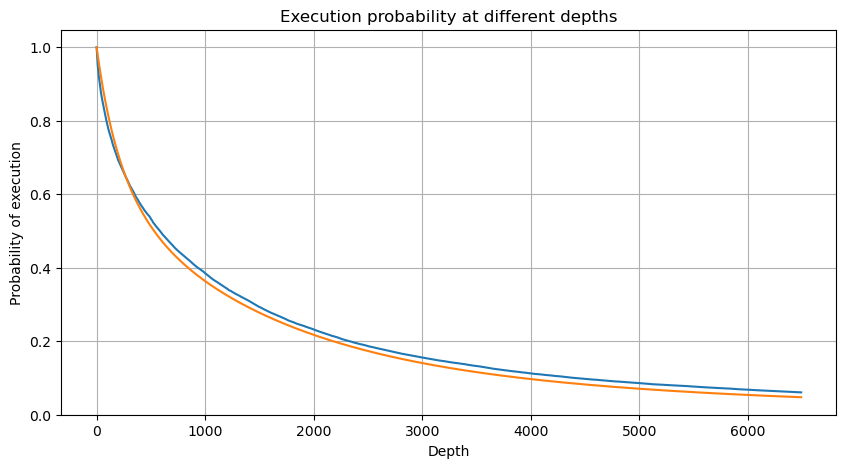
In [6]:
df_resampled = buy_trades['quantity'].resample('2S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 6500, 10))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = buy_trades['quantity'].mean()
adjust = buy_trades['interval'].mean() / 2620
alpha = np.log(np.mean(buy_trades['quantity'] > mean))/0.7178397931503168
probabilities_s = np.array([((1+20**(-depth*adjust/mean))*depth*adjust/mean+1)**(alpha) for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
Ausgeschaltet[6]:
Auswirkungen auf die Preise im Binnenhandel
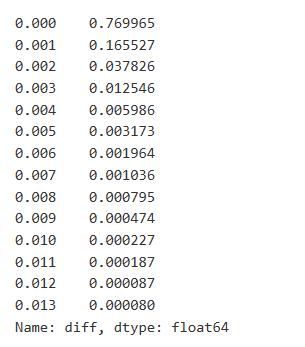
Handelsdaten sind wertvoll, und es gibt noch viele Daten, die abgebaut werden können. Wir sollten die Auswirkungen von Aufträgen auf die Preise genau beachten, da dies die Positionierung von Strategien beeinflusst. In ähnlicher Weise berechnen wir, indem wir Daten basierend auf transact_time aggregieren, die Differenz zwischen dem letzten Preis und dem ersten Preis. Wenn es nur einen Auftrag gibt, beträgt die Preisdifferenz 0. Interessanterweise gibt es einige Datenergebnisse, die negativ sind, was auf die Reihenfolge der Daten zurückzuführen sein kann, aber wir werden hier nicht eingehen.
Die Ergebnisse zeigen, dass der Anteil der Geschäfte, die keine Auswirkungen verursachten, bis zu 77% beträgt, während der Anteil der Geschäfte, die eine Preisbewegung von 1 Tic verursachten, 16,5%, 2 Tic 3,7%, 3 Tic 1,2% und mehr als 4 Tic weniger als 1% beträgt.
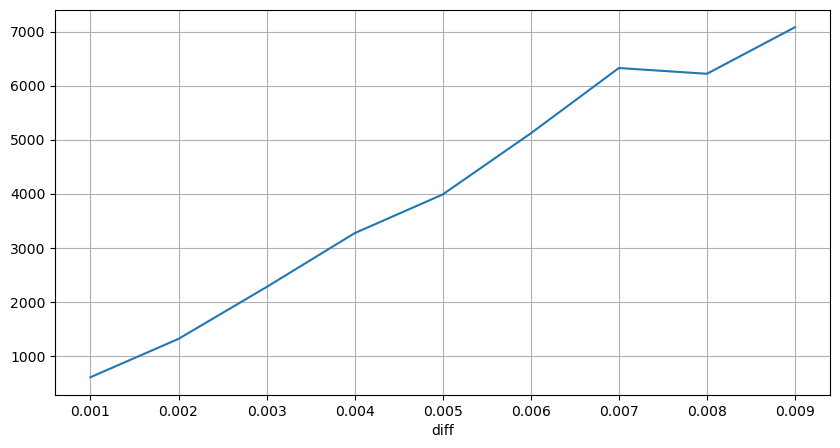
Der Handelsbetrag, der die entsprechende Preisunterschiede verursacht, wurde ebenfalls analysiert, ohne Verzerrungen durch übermäßige Auswirkungen. Er zeigt eine lineare Beziehung mit etwa 1 Tick der Preisschwankung, die durch jede 1000 Einheiten des Betrags verursacht wird. Dies kann auch als durchschnittliche Anzahl von rund 1000 Einheiten von Aufträgen verstanden werden, die in der Nähe jeder Preisstufe im Auftragsbuch platziert wurden.
In [7]:
diff_df = trades[trades['is_buyer_maker']==False].groupby('transact_time')['price'].agg(lambda x: abs(round(x.iloc[-1] - x.iloc[0],3)) if len(x) > 1 else 0)
buy_trades['diff'] = buy_trades['transact_time'].map(diff_df)
In [8]:
diff_counts = buy_trades['diff'].value_counts()
diff_counts[diff_counts>10]/diff_counts.sum()
Außen[8]:
In [9]:
diff_group = buy_trades.groupby('diff').agg({
'quantity': 'mean',
'diff': 'last',
})
In [10]:
diff_group['quantity'][diff_group['diff']>0][diff_group['diff']<0.01].plot(figsize=(10,5),grid=True);
Ausgeschaltet[10]:
Einfluss auf die Preise in festen Intervallen
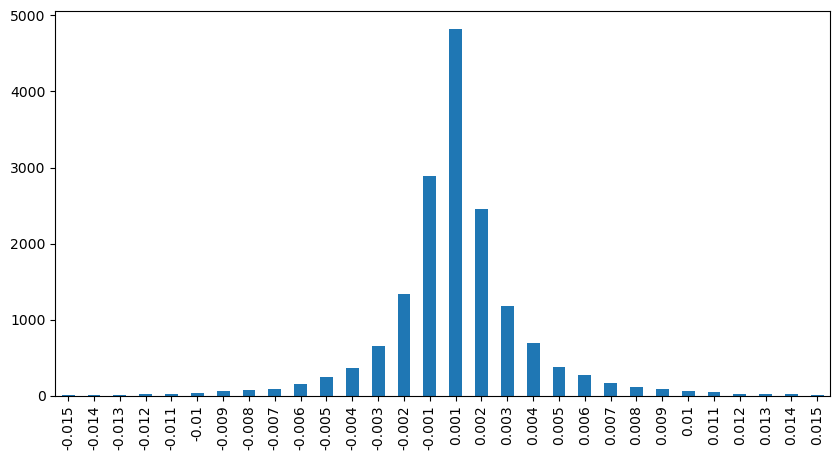
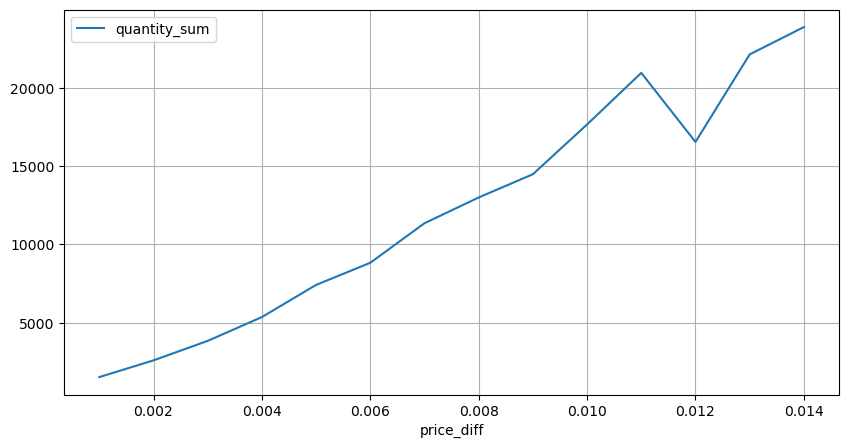
Lassen Sie uns die Preiswirkung innerhalb eines 2-Sekunden-Intervalls analysieren. Der Unterschied hier ist, dass es negative Werte geben kann. Da wir jedoch nur Kaufbestellungen in Betracht ziehen, wäre die Wirkung auf die symmetrische Position einen Tick höher. Wenn wir weiterhin die Beziehung zwischen Handelsbetrag und Wirkung beobachten, betrachten wir nur Ergebnisse, die größer als 0 sind. Die Schlussfolgerung ist ähnlich wie bei einer einzigen Bestellung, die eine ungefähre lineare Beziehung zeigt, wobei für jeden Tick etwa 2000 Einheiten des Betrags benötigt werden.
In [11]:
df_resampled = buy_trades.resample('2S').agg({
'price': ['first', 'last', 'count'],
'quantity': 'sum'
})
df_resampled['price_diff'] = round(df_resampled[('price', 'last')] - df_resampled[('price', 'first')],3)
df_resampled['price_diff'] = df_resampled['price_diff'].fillna(0)
result_df_raw = pd.DataFrame({
'price_diff': df_resampled['price_diff'],
'quantity_sum': df_resampled[('quantity', 'sum')],
'data_count': df_resampled[('price', 'count')]
})
result_df = result_df_raw[result_df_raw['price_diff'] != 0]
In [12]:
result_df['price_diff'][abs(result_df['price_diff'])<0.016].value_counts().sort_index().plot.bar(figsize=(10,5));
Ausgeschaltet:
In [23]:
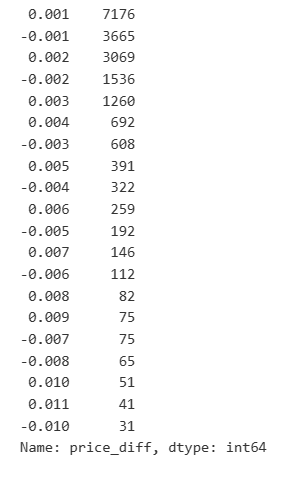
result_df['price_diff'].value_counts()[result_df['price_diff'].value_counts()>30]
Außen [1]:
In [14]:
diff_group = result_df.groupby('price_diff').agg({ 'quantity_sum': 'mean'})
In [15]:
diff_group[(diff_group.index>0) & (diff_group.index<0.015)].plot(figsize=(10,5),grid=True);
Ausgeschaltet[1]:
Preiswirkung des Handelsbetrags
Zuvor haben wir den für eine Tick-Änderung erforderlichen Handelsbetrag ermittelt, der jedoch nicht präzise war, da er auf der Annahme beruhte, dass die Auswirkungen bereits eingetreten sind.
In dieser Analyse werden die Daten alle 1 Sekunde ausgewertet, wobei jeder Schritt 100 Einheiten der Menge darstellt.
- Wenn der Kaufbefehl unter 500 liegt, ist die erwartete Preisänderung eine Abnahme, was erwartet wird, da auch Verkaufsbefehle auf den Preis wirken.
- Bei niedrigeren Handelsbeträgen besteht eine lineare Beziehung, was bedeutet, dass je größer der Handelsbetrag, desto größer der Preisanstieg ist.
- Da der Kaufbestellbetrag steigt, wird die Preisänderung signifikanter. Dies zeigt oft einen Preisdurchbruch an, der später rückläufig sein kann. Darüber hinaus erhöht die Festintervallsprobenahme die Dateninstabilität.
- Es ist wichtig, auf den oberen Teil des Scatter-Graphs zu achten, der dem Preisanstieg mit dem Handelsbetrag entspricht.
- Für dieses spezifische Handelspaar geben wir eine grobe Version der Beziehung zwischen Handelsbetrag und Preisänderung an.
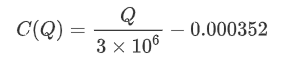
Hierbei stellt
In [16]:
df_resampled = buy_trades.resample('1S').agg({
'price': ['first', 'last', 'count'],
'quantity': 'sum'
})
df_resampled['price_diff'] = round(df_resampled[('price', 'last')] - df_resampled[('price', 'first')],3)
df_resampled['price_diff'] = df_resampled['price_diff'].fillna(0)
result_df_raw = pd.DataFrame({
'price_diff': df_resampled['price_diff'],
'quantity_sum': df_resampled[('quantity', 'sum')],
'data_count': df_resampled[('price', 'count')]
})
result_df = result_df_raw[result_df_raw['price_diff'] != 0]
In [24]:
df = result_df.copy()
bins = np.arange(0, 30000, 100) #
labels = [f'{i}-{i+100-1}' for i in bins[:-1]]
df.loc[:, 'quantity_group'] = pd.cut(df['quantity_sum'], bins=bins, labels=labels)
grouped = df.groupby('quantity_group')['price_diff'].mean()
In [25]:
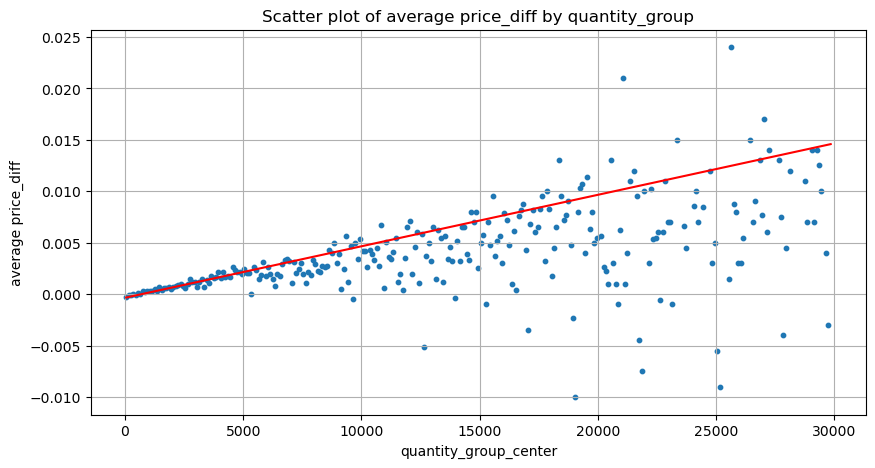
grouped_df = pd.DataFrame(grouped).reset_index()
grouped_df['quantity_group_center'] = grouped_df['quantity_group'].apply(lambda x: (float(x.split('-')[0]) + float(x.split('-')[1])) / 2)
plt.figure(figsize=(10,5))
plt.scatter(grouped_df['quantity_group_center'], grouped_df['price_diff'],s=10)
plt.plot(grouped_df['quantity_group_center'], np.array(grouped_df['quantity_group_center'].values)/2e6-0.000352,color='red')
plt.xlabel('quantity_group_center')
plt.ylabel('average price_diff')
plt.title('Scatter plot of average price_diff by quantity_group')
plt.grid(True)
Ausgeschaltet[25]:
In [19]:
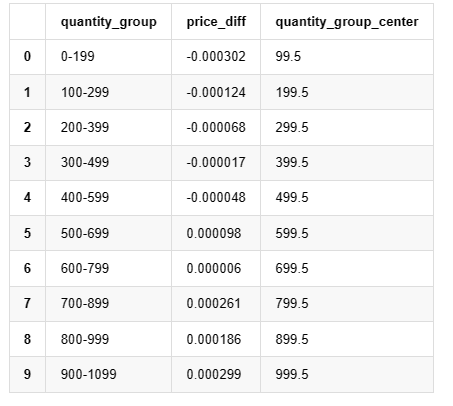
grouped_df.head(10)
Ausgeschaltet[1]: Ich bin nicht derjenige, der dich anspricht. Ich bin nicht derjenige, der dich anspricht.
Vorläufige optimale Auftragserteilung
Mit der Modellierung des Handelsbetrags und dem groben Modell der Preiseffekte, die dem Handelsbetrag entsprechen, scheint es möglich zu sein, die optimale Auftragsstellung zu berechnen.
- Angenommen, der Preis kehrt nach dem Einfluss auf seinen ursprünglichen Wert zurück (was höchst unwahrscheinlich ist und eine weitere Analyse der Preisänderung nach dem Einfluss erfordern würde).
- Angenommen, die Verteilung des Handelsbetrags und der Auftragshäufigkeit während dieses Zeitraums folgt einem vorgegebenen Muster (was ebenfalls ungenau ist, da wir auf der Grundlage von Daten aus einem Tag schätzen und der Handel deutliche Clustering-Phänomene aufweist).
- Angenommen, während der simulierten Zeit tritt nur ein Verkaufsbefehl auf und wird dann geschlossen.
- Nehmen wir an, dass nach der Ausführung der Bestellung weitere Kaufbestellungen den Preis weiter nach oben drücken, insbesondere wenn der Betrag sehr niedrig ist.
Beginnen wir damit, eine einfache erwartete Rendite zu schreiben, d. h. die Wahrscheinlichkeit, dass kumulierte Kaufbestellungen Q innerhalb einer Sekunde übersteigen, multipliziert mit der erwarteten Rendite (d. h. der Preiswirkung).
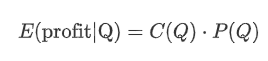
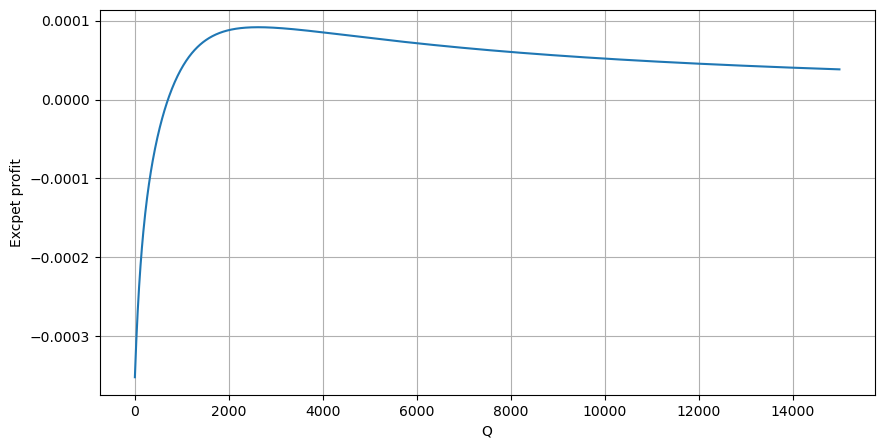
Auf der Grundlage der Grafik beträgt die maximal erwartete Rendite etwa 2500, was etwa das 2,5-fache des durchschnittlichen Handelsbetrags entspricht. Dies legt nahe, dass die Verkaufsbestellung in einer Preisposition von 2500 platziert werden sollte. Es ist wichtig zu betonen, dass die horizontale Achse den Handelsbetrag innerhalb von 1 Sekunde darstellt und nicht mit der Tiefenposition gleichgesetzt werden sollte. Zusätzlich basiert diese Analyse auf Handelsdaten und fehlt es an wichtigen Tiefendaten.
Zusammenfassung
Wir haben entdeckt, dass die Verteilung der Handelsmenge in verschiedenen Zeitintervallen eine einfache Skalierung der Verteilung der einzelnen Handelsbeträge ist. Wir haben auch ein einfaches erwartetes Rendite-Modell entwickelt, das auf Preiseffekten und Handelswahrscheinlichkeit basiert. Die Ergebnisse dieses Modells entsprechen unseren Erwartungen und zeigen, dass, wenn die Verkaufsbestellungsmenge niedrig ist, dies einen Preisrückgang anzeigt und ein bestimmter Betrag für das Gewinnpotenzial erforderlich ist. Die Wahrscheinlichkeit sinkt, wenn die Handelsmenge steigt, wobei eine optimale Größe dazwischen liegt, was die optimale Bestellplatzierungsstrategie darstellt. Dieses Modell ist jedoch immer noch zu vereinfacht. Im nächsten Artikel werde ich tiefer in dieses Thema eintauchen.
In [20]:
# Cumulative distribution in 1s
df_resampled = buy_trades['quantity'].resample('1S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 15000, 10))
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
profit_s = np.array([depth/2e6-0.000352 for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities_s*profit_s)
plt.xlabel('Q')
plt.ylabel('Excpet profit')
plt.grid(True)
Ausgeschaltet[1]:
- Delta-Hedging für Bitcoin-Optionen mit einer Lächeln-Kurve
- Überlegungen zu Hochfrequenzhandelsstrategien (5)
- Überlegungen zu Hochfrequenz-Handelsstrategien (4)
- Überlegungen zur Hochfrequenz-Handelstrategie (5)
- Denken Sie über die Strategie des Hochfrequenz-Handels nach (4)
- Überlegungen zu Hochfrequenzhandelsstrategien (3)
- Überlegungen zur Hochfrequenz-Handelsstrategie (3)
- Denken Sie über die Strategie des Hochfrequenz-Handels nach.
- Überlegungen zu Hochfrequenzhandelsstrategien (1)
- Denken Sie über die Strategie des Hochfrequenz-Handels nach (1)
- Dokument zur Beschreibung der Konfiguration von Futu Securities
- FMZ Quant Uniswap V3 Leitfaden für Börsenpool-Liquiditätsbezogene Operationen (Teil 1)
- FMZ Quantitative Uniswap V3 Betriebsanleitungen für die Wechselpool-Liquidität (I)