Überlegungen zu Hochfrequenzhandelsstrategien (3)
Schriftsteller:Lydia., Erstellt: 2023-08-08 10:05:19, Aktualisiert: 2023-09-12 15:50:55
Überlegungen zu Hochfrequenzhandelsstrategien (3)
In dem vorherigen Artikel habe ich vorgestellt, wie man das kumulative Handelsvolumen modelliert und das Phänomen der Preiswirkung analysiert. In diesem Artikel werde ich die Daten der Handelsbestellungen weiter analysieren. YGG hat kürzlich Binance U-basierte Verträge eingeführt, und die Preisschwankungen waren erheblich, wobei das Handelsvolumen zu einem bestimmten Zeitpunkt sogar BTC übertraf. Heute werde ich es analysieren.
Bestellzeitintervalle
Im Allgemeinen wird davon ausgegangen, daß die Ankunftszeit der Bestellungen einem Poisson-Prozess folgt.Prozess von PoissonIch werde empirische Beweise liefern.
Ich habe die AggTrades-Daten für den 5. August heruntergeladen, die aus 1.931.193 Trades bestehen, was ziemlich signifikant ist. Zuerst werfen wir einen Blick auf die Verteilung der Kauforders. Wir können einen nicht glatten lokalen Höchststand um 100ms und 500ms sehen, der wahrscheinlich durch Eisberg-Orders verursacht wird, die von Trading-Bots in regelmäßigen Abständen platziert werden. Dies kann auch einer der Gründe für die ungewöhnlichen Marktbedingungen an diesem Tag sein.
Die Wahrscheinlichkeitsmassenfunktion (PMF) der Poisson-Verteilung ergibt sich aus der folgenden Formel:
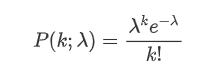
Wo:
- κ ist die Anzahl der von uns interessierten Veranstaltungen.
- λ ist die durchschnittliche Geschwindigkeit der Ereignisse pro Zeiteinheit (oder Raum-Einheit).
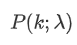 stellt die Wahrscheinlichkeit dar, dass genau κ Ereignisse auftreten, wenn die durchschnittliche Rate λ gegeben ist.
stellt die Wahrscheinlichkeit dar, dass genau κ Ereignisse auftreten, wenn die durchschnittliche Rate λ gegeben ist.
In einem Poisson-Prozess folgen die Zeitintervalle zwischen Ereignissen einer exponentiellen Verteilung.
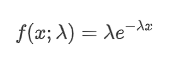
Die passenden Ergebnisse zeigen, dass es einen signifikanten Unterschied zwischen den beobachteten Daten und der erwarteten Poisson-Verteilung gibt. Der Poisson-Prozess unterschätzt die Häufigkeit langer Zeitintervalle und überschätzt die Häufigkeit kurzer Zeitintervalle. (Die tatsächliche Verteilung der Intervalle ist einer modifizierten Pareto-Verteilung näher)
In [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
In [2]:
trades = pd.read_csv('YGGUSDT-aggTrades-2023-08-05.csv')
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
buy_trades.index = buy_trades['date']
In [10]:
buy_trades['interval'][buy_trades['interval']<1000].plot.hist(bins=200,figsize=(10, 5));
Ausgeschaltet[10]:
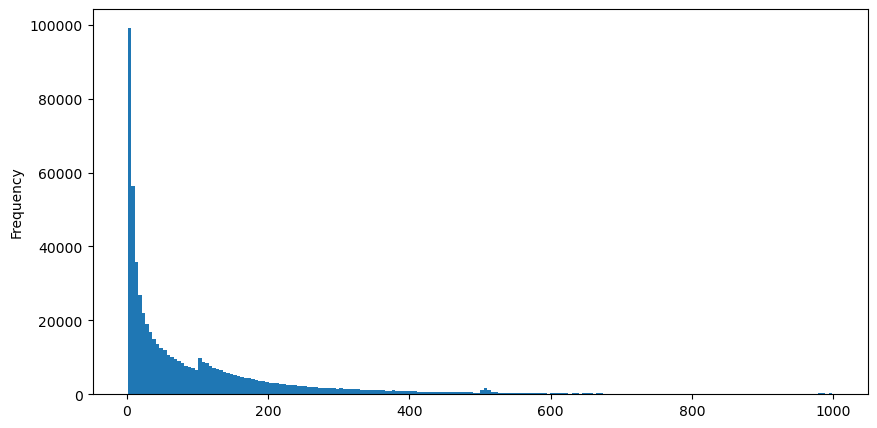
In [20]:
Intervals = np.array(range(0, 1000, 5))
mean_intervals = buy_trades['interval'].mean()
buy_rates = 1000/mean_intervals
probabilities = np.array([np.mean(buy_trades['interval'] > interval) for interval in Intervals])
probabilities_s = np.array([np.e**(-buy_rates*interval/1000) for interval in Intervals])
plt.figure(figsize=(10, 5))
plt.plot(Intervals, probabilities)
plt.plot(Intervals, probabilities_s)
plt.xlabel('Intervals')
plt.ylabel('Probability')
plt.grid(True)
Ausgeschaltet[1]:
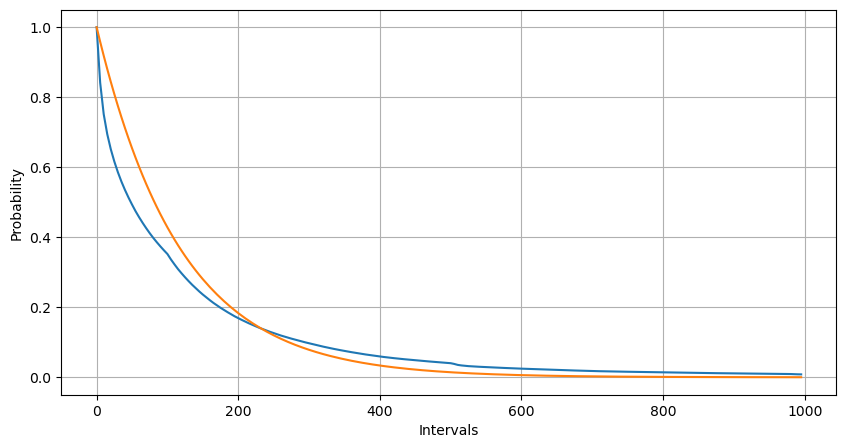
Bei einem Vergleich der Verteilung der Anzahl der Auftragsereignisse innerhalb einer Sekunde mit der Poisson-Verteilung ist der Unterschied ebenfalls signifikant.
- Nichtkonstante Auftretungsrate: Der Poisson-Prozess geht davon aus, dass die durchschnittliche Häufigkeit von Ereignissen, die innerhalb eines bestimmten Zeitabschnitts auftreten, konstant ist.
- Wechselwirkungen zwischen Prozessen: Eine weitere grundlegende Annahme des Poisson-Prozesses ist, dass Ereignisse unabhängig voneinander sind.
In einer realen Umgebung ist die Häufigkeit von Auftragseinsätzen nicht konstant und muss in Echtzeit aktualisiert werden. Es kann auch einen Anreizeffekt geben, bei dem mehr Aufträge innerhalb eines festen Zeitraums mehr Aufträge stimulieren. Dies macht Strategien nicht in der Lage, sich auf einen einzigen festen Parameter zu verlassen.
Im Jahre [190]:
result_df = buy_trades.resample('1S').agg({
'price': 'count',
'quantity': 'sum'
}).rename(columns={'price': 'order_count', 'quantity': 'quantity_sum'})
In [219]:
count_df = result_df['order_count'].value_counts().sort_index()[result_df['order_count'].value_counts()>20]
(count_df/count_df.sum()).plot(figsize=(10,5),grid=True,label='sample pmf');
from scipy.stats import poisson
prob_values = poisson.pmf(count_df.index, 1000/mean_intervals)
plt.plot(count_df.index, prob_values,label='poisson pmf');
plt.legend() ;
Aus [219]:
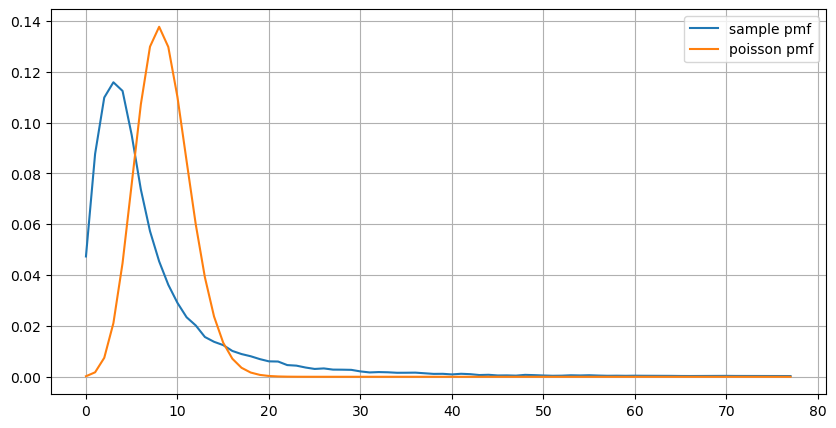
Echtzeit-Aktualisierung der Parameter
Aus der Analyse der Auftragsintervalle zuvor kann der Schluss gezogen werden, dass feste Parameter nicht für die realen Marktbedingungen geeignet sind, und die wichtigsten Parameter, die den Markt in der Strategie beschreiben, in Echtzeit aktualisiert werden müssen. Die einfachste Lösung besteht darin, einen gleitenden gleitenden Durchschnitt zu verwenden. Die beiden folgenden Grafiken zeigen die Häufigkeit von Kaufbestellungen innerhalb einer Sekunde und das durchschnittliche Handelsvolumen mit einer Fenstergröße von 1000. Es kann beobachtet werden, dass es ein Clustering-Phänomen im Handel gibt, bei dem die Häufigkeit von Aufträgen für einen bestimmten Zeitraum signifikant höher als üblich ist und das Volumen auch synchron steigt. Hier wird das Mittel der vorherigen Werte verwendet, um den letzten absoluten Wert vorherzusagen, und der durchschnittliche Fehler der Restwerte wird verwendet, um die Qualität der Vorhersage zu messen.
Aus den Grafiken können wir auch verstehen, warum die Ordnungsfrequenz so stark von der Poisson-Verteilung abweicht.
Es stellt sich heraus, dass die Verwendung des Mittelwerts der vorangegangenen zwei Sekunden zur Vorhersage den kleinsten Restfehler erzeugt, und es ist viel besser, als einfach den Mittelwert für Vorhersageergebnisse zu verwenden.
In [221]:
result_df['order_count'].rolling(1000).mean().plot(figsize=(10,5),grid=True);
Ausgeschaltet[1]:
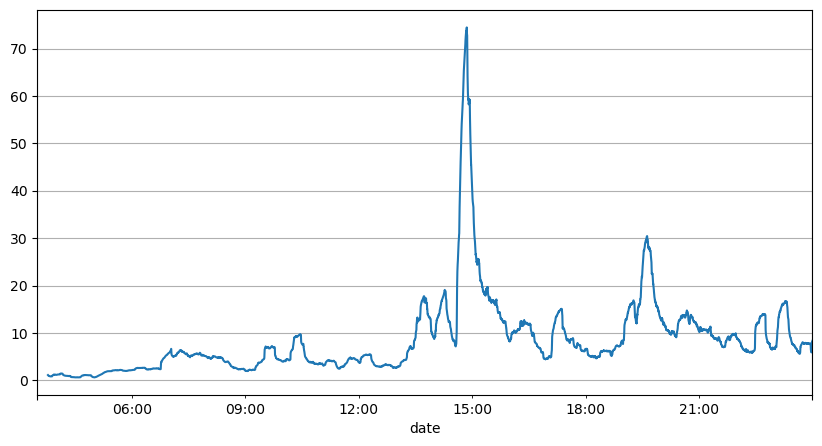
Im Jahr [193]:
result_df['quantity_sum'].rolling(1000).mean().plot(figsize=(10,5),grid=True);
Ausgeschaltet[1]:
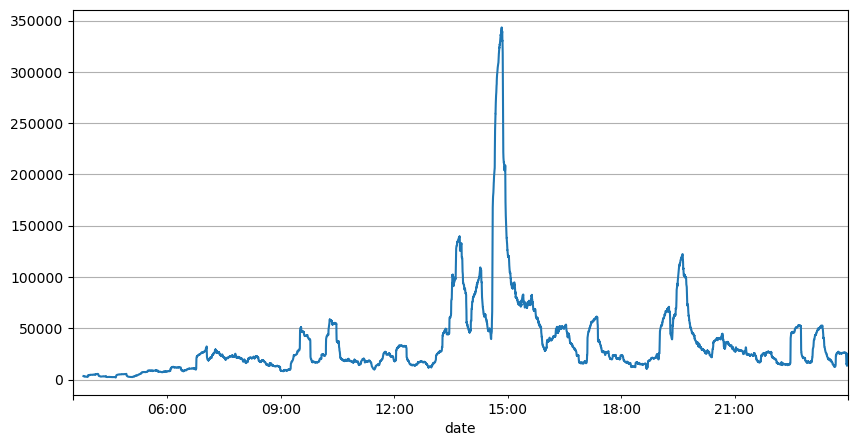
Im Jahre [195]:
(result_df['order_count'] - result_df['mean_count'].mean()).abs().mean()
Ausgeschaltet[195]:
6.985628185332997
In [205]:
result_df['mean_count'] = result_df['order_count'].rolling(2).mean()
(result_df['order_count'] - result_df['mean_count'].shift()).abs().mean()
Ausgeschaltet[1]:
3.091737586730269
Zusammenfassung
Dieser Artikel erläutert kurz die Gründe für die Abweichung der Auftragszeitintervalle vom Poisson-Prozess, hauptsächlich aufgrund der Veränderung der Parameter im Laufe der Zeit. Um den Markt genau vorherzusagen, müssen Strategien Echtzeitprognosen der grundlegenden Parameter des Marktes erstellen. Restwerte können verwendet werden, um die Qualität der Vorhersagen zu messen. Das oben genannte Beispiel ist eine einfache Demonstration, und es gibt umfangreiche Forschungen zu spezifischen Zeitreihenanalysen, Volatilitätsclustering und anderen verwandten Themen, die obige Demonstration kann weiter verbessert werden.
- Delta-Hedging für Bitcoin-Optionen mit einer Lächeln-Kurve
- Überlegungen zu Hochfrequenzhandelsstrategien (5)
- Überlegungen zu Hochfrequenz-Handelsstrategien (4)
- Überlegungen zur Hochfrequenz-Handelstrategie (5)
- Denken Sie über die Strategie des Hochfrequenz-Handels nach (4)
- Überlegungen zur Hochfrequenz-Handelsstrategie (3)
- Überlegungen zu Hochfrequenzhandelsstrategien (2)
- Denken Sie über die Strategie des Hochfrequenz-Handels nach.
- Überlegungen zu Hochfrequenzhandelsstrategien (1)
- Denken Sie über die Strategie des Hochfrequenz-Handels nach (1)
- Dokument zur Beschreibung der Konfiguration von Futu Securities
- FMZ Quant Uniswap V3 Leitfaden für Börsenpool-Liquiditätsbezogene Operationen (Teil 1)
- FMZ Quantitative Uniswap V3 Betriebsanleitungen für die Wechselpool-Liquidität (I)