

In letzter Zeit wird der Begriff „Destillation“ immer häufiger verwendet. Im KI-Bereich bedeutet er meist, komplexe Fähigkeiten in kompaktere, wiederverwendbare Strukturen zu extrahieren. Dieser Gedanke lässt sich auch auf die Strategieforschung übertragen. Konkret bedeutet das, ursprünglich verstreutes, vages und auf subjektiver Erfahrung basierendes Wissen in ein System zu überführen, das berechenbar, überprüfbar und kontinuierlich verbesserbar ist.
Das Projekt crypto-kol-quant ist in letzter Zeit sehr populär. Das wirklich Interessante daran ist nicht, wie viele KOLs es erfasst hat oder dass es LLMs verwendet, sondern dass es etwas tut, das in der quantitativen Forschung nicht alltäglich ist: Die Erfahrungen von Tradern in eine Reihe berechenbarer Fähigkeitsfaktoren zu destillieren und diese dann zu einem Konsenssignal zu aggregieren. Dieses Problem an sich ist durchaus ernst zu nehmen. Denn wenn eine Gruppe von langjährig aktiven, in ihrem Stil konsistenten Tradern tatsächlich jeweils ihre eigenen kognitiven Rahmen im Markt entwickelt hat, dann sollten diese Rahmen theoretisch nicht nur in Tweets, Charts und bruchstückhaften Aussagen existieren. Sie sollten auch die Chance haben, extrahiert, strukturiert und in eine lauffähige Strategie-Kette integriert zu werden.
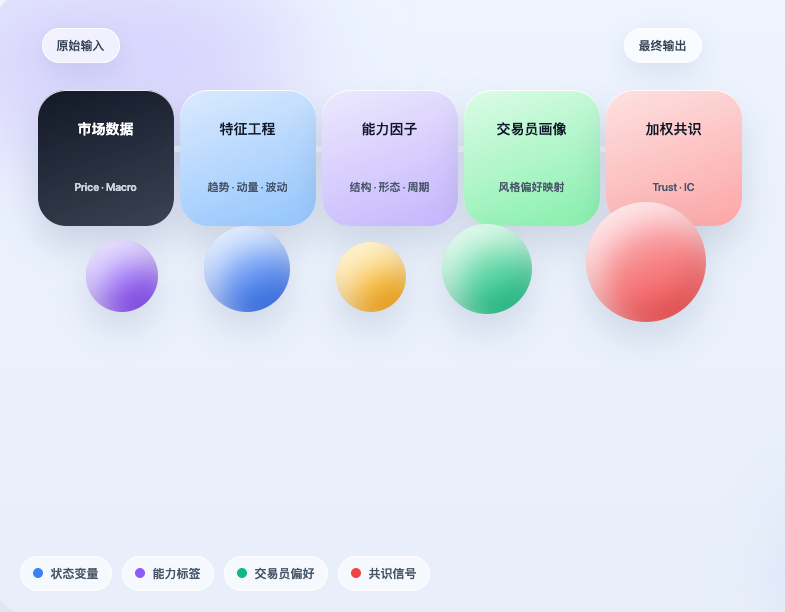
Basierend auf diesem Gedanken haben wir in der FMZ-Umgebung eine erste Implementierung vorgenommen. Der Schwerpunkt lag nicht darauf, das Projekt einfach zu „kopieren“, sondern seine Kernlogik wirklich zu verketten: Zuerst Marktdaten erfassen, dann den Markt in einen strukturierten Zustand übersetzen; basierend auf diesen Zuständen beurteilen, welche Handelsfähigkeiten gerade ausgelöst werden; diese Fähigkeiten dann auf das Profil der Trader abbilden; und schließlich die individuellen Einschätzungen verschiedener Trader zu einem gewichteten Konsenssignal aggregieren. Es ist offensichtlich noch kein ausgereiftes Handelssystem, aber es hat zumindest eine wichtige Sache geleistet: Es zeigt, dass Erfahrungen von Tradern tatsächlich komprimiert, strukturiert und in den Entscheidungsprozess einer Strategie einbezogen werden können.
Destilliert werden nicht Meinungen, sondern Handelsfähigkeiten
Viele, die zum ersten Mal mit solchen Projekten in Kontakt kommen, neigen dazu, sie als „KOL-Stimmungsstrategie“ zu verstehen. Das ist aber nicht ganz richtig. Was das ursprüngliche Projekt wirklich tut, ist nicht einfach zu beurteilen, wer heute optimistischer ist, oder zu zählen, wer Long und wer Short gerufen hat. Es geht einen Schritt weiter und fragt: Wie versteht dieser Trader den Markt eigentlich? In welcher Struktur tendiert er zu Long? Achtet er mehr auf Trend, Position, Form, Volatilität oder das makroökonomische Umfeld? Lassen sich diese Beurteilungsweisen in eine Reihe stabiler Fähigkeitslabels fassen?
Wenn man die Frage so stellt, verschiebt sich der Fokus der Strategie. Das System interessiert sich nicht mehr für einen einzelnen Satz, sondern für die dahinterstehende Methodik. Mit anderen Worten: Das, was diese Strategie wirklich destilliert, ist nicht Text, sondern Handelswissen an sich. Sie versucht, subjektive Erfahrungen, die normalerweise vom Menschen verstanden werden müssen, in regelbasierte Fähigkeiten zu übersetzen, die ein Programm erkennen und aufrufen kann. Das ist auch der größte Unterschied zu gängigen Stimmungsmodellen: Sie beurteilt nicht, wie heiß die Marktstimmung ist, sondern rekonstruiert, wie unterschiedliche Handelsrahmen auf den aktuellen Markt reagieren.
Schritt 1: Den Markt erst einmal in Zustandsvariablen übersetzen
Damit die Destillation wirklich greift, ist der erste Schritt nicht die Vorhersage, sondern das Feature Engineering. Der Grund ist einfach: Die Sprache der Trader ist für Menschen gemacht, nicht für Programme. Wenn ein Trader zum Beispiel sagt: „Der Preis testet den gleitenden Durchschnitt einer wichtigen Linie, das ist ein guter zweiter Einstiegspunkt“, versteht ein Trader das sofort. Für ein Programm muss es aber erst zerlegt werden: Was ist der wichtige gleitende Durchschnitt? Der 50-Tage- oder der 200-Tage-Durchschnitt? Liegt der aktuelle Preis nahe an diesem Durchschnitt? Ist der Trend intakt? Gibt es ein Zeichen für Unterstützung?
Das System muss also nicht zuerst eine Long/Short-Entscheidung treffen, sondern die Rohdaten in einen Satz strukturierter Zustände umwandeln. Die grundlegendste Schicht besteht darin, aus den Kursen Trend- und Momentum-Merkmale zu konstruieren. Variablen wie SMA, EMA, RSI, MACD werden nicht verwendet, um Indikatoren zu stapeln, sondern um eine einfache Frage zu beantworten: In welchem Zustand befindet sich der Markt gerade ungefähr?

Der entsprechende Code:
python
# Gleitende Durchschnitte verschiedener Perioden, um die Trendposition des Kurses zu beschreiben
f['ma20'] = _sma(c,20)
f['ma50'] = _sma(c,50)
f['ma100'] = _sma(c,100)
f['ma200'] = _sma(c,200)
# Exponentielle gleitende Durchschnitte reagieren empfindlicher auf jüngste Kursänderungen
f['ema20'] = _ema(c,20)
f['ema50'] = _ema(c,50)
# RSI zur Beschreibung, ob der Markt überkauft oder überverkauft ist, oder ob das Momentum nachlässt
f['rsi14'] = _rsi(c,14)
# MACD mit Signallinie und Histogramm zur Beobachtung von Trend- und Momentumänderungen
ml, ms, mh = _macd(c)
f['macd'] = ml
f['macd_sig'] = ms
f['macd_hist'] = mh
Was dieser Code tut, ist nicht kompliziert. Gleitende Durchschnitte helfen dem System, die Position des aktuellen Kurses relativ zum langfristigen Trend zu beurteilen, während RSI und MACD beschreiben, ob das Momentum verstärkt oder abgeschwächt wird. Es ist noch keine Handelsentscheidung, sondern nur der Aufbau einer Schicht „Marktzustandsbeschreibung“.
Als nächstes muss das System Volatilität und Positionsbeziehungen ergänzen, da viele Handelsentscheidungen nicht nur vom Trend abhängen, sondern auch davon, ob wir uns gerade in einer Phase der Volatilitätskontraktion befinden oder ob der Preis nahe einem Bereichshoch oder -tief liegt.
Der entsprechende Code:
python
# Logarithmische Rendite als Grundlage zur Berechnung der Volatilität
logr = np.log(c / c.shift(1))
# Annualisierte Volatilität der letzten 30 Tage zur Messung des aktuellen Marktvolatilitätsniveaus
f['rv30'] = logr.rolling(30, min_periods=10).std() * np.sqrt(365)
# Hoch- und Tiefpunkte der letzten 20 und 50 Tage zur Beurteilung der aktuellen Kurslage
f['high_20d'] = h.rolling(20, min_periods=1).max()
f['low_20d'] = l.rolling(20, min_periods=1).min()
f['high_50d'] = h.rolling(50, min_periods=1).max()
f['low_50d'] = l.rolling(50, min_periods=1).min()
Hier steht rv30 für das annualisierte Volatilitätsniveau der letzten 30 Tage, während die Bereichshochs und -tiefs dem System helfen zu beurteilen, wo sich der aktuelle Kurs innerhalb der jüngsten Kursstruktur befindet.
Darüber hinaus wird auch der makroökonomische Hintergrund in den Zustandsraum einbezogen. Denn eine bestimmte Art von Tradern betrachtet nicht nur den Kryptopreis selbst, sondern beobachtet gleichzeitig den US-Dollar-Index, die Risikobereitschaft an den Aktienmärkten und das Zinsumfeld. Die entsprechende Verarbeitung im Code besteht darin, diese Variablen zunächst tagesgenau auszurichten und dann in lesbare Zustände zu überführen:
python
# DXY als Hintergrundvariable für die Stärke des US-Dollars
if 'DXY' in macro:
dxy = _align(macro['DXY'])
f['dxy_ret_20d'] = dxy.pct_change(20)
f['dxy_trend_down'] = (dxy.pct_change(20) < -0.01).astype(int)
# SPX als Hintergrundvariable für die Risikobereitschaft
if 'SPX' in macro:
spx = _align(macro['SPX'])
f['spx_ret_20d'] = spx.pct_change(20)
f['spx_trend_up'] = (spx.pct_change(20) > 0).astype(int)
Die Bedeutung dieses Schritts lässt sich in einem Satz zusammenfassen: Zuerst wird „Wie ist der Markt gerade?“ in einen strukturierten Zustand übersetzt, den die Maschine kontinuierlich lesen kann. Ohne diese Schicht wäre die spätere Destillation unmöglich.
Schritt 2: Subjektive Erfahrung in Fähigkeitsfaktoren umwandeln
Allein die Merkmale reichen nicht, denn sie beschreiben nur den Markt, drücken aber nicht direkt aus, „was dieser Zustand bedeutet“. Im nächsten Schritt muss die Erfahrung der Trader in Regeln gefasst werden, d.h. anhand der aktuellen Zustandsvariablen beurteilt werden, welche Handelsfähigkeiten gerade ausgelöst werden.
Dieser Schritt ist der destillationsstärkste Teil der gesamten Strategie. Denn hier wird nicht mehr abstrakt gesagt, „ein bestimmter Rahmen ist wichtig“, sondern er wird tatsächlich in Programm-Bedingungen geschrieben. Die in der aktuellen Implementierung enthaltenen Fähigkeitsfaktoren decken die Ebenen Form, Struktur, Indikatoren, Zyklen und Makroökonomie ab. Einige Fähigkeiten stammen aus der Formerkennung wie Bullenflaggen, Bärenflaggen, Doppeltops/-bottoms, Kopf-Schulter-Strukturen, Dreiecke; einige aus der Strukturanalyse wie Wyckoff, SMC, ICT; einige aus Indikatoren selbst wie RSI-Divergenz, goldenes/kreuzendes Gleitender-Durchschnitt-Kreuz, Bollinger-Band-Kompression und -Ausbruch; andere aus Zyklen und dem makroökonomischen Umfeld wie Halbierungszyklen, Wechsel zwischen Trend- und Seitwärtsmärkten, fallender DXY, steigende Risikobereitschaft.
Ein sehr typisches Beispiel ist die „Trend-Rücksetzer-Fortsetzung“. Viele Trader haben die Erfahrung gemacht: Wenn der große Trend immer noch nach oben zeigt, der Preis auf den entscheidenden gleitenden Durchschnitt zurückfällt und die aktuelle Kerze Unterstützung zeigt, dann bedeutet das oft eine Trendfortsetzung. Der Code drückt das sehr direkt aus:
python
# Prüfen, ob der aktuelle Preis nahe am 50-Tage-Durchschnitt liegt
near_ma50 = abs(close - ma50_v) / close < 0.02 if close > 0 else False
# Wenn der 50-Tage-Durchschnitt immer noch über dem 200-Tage-Durchschnitt liegt und nach dem Rücksetzer eine grüne Kerze erscheint
# dann wird ein Fähigkeitssignal für Trendfortsetzung gesetzt
s['cap_014_trend_pullback_continuation'] = 0.6 if (ma50_gt and near_ma50 and is_green) else 0.0
Hier gibt es nichts Geheimnisvolles; es wird lediglich ein Satz in natürlicher Sprache in mehrere maschinell überprüfbare Bedingungen zerlegt.
Ein weiteres Beispiel ist der „Bollinger-Band-Kompression-Ausbruch“. Für viele Trader bedeutet eine langanhaltende Volatilitätskontraktion, gefolgt von einer plötzlichen Aufwärts- oder Abwärtsausdehnung, oft eine neue Richtungsentscheidung. Die entsprechende Regel:
python
# Wenn die Breite des vorherigen Bollinger-Bandes unter der Kompressionsschwelle liegt, gilt dies als Volatilitätskontraktion
squeezed = bb_w_p1 < bb_w20_p1 if bb_w20_p1 > 0 else False
# Nach der Kontraktion: Ausbruch über das obere Band gibt positives Signal, Ausbruch unter das untere Band gibt negatives Signal
s['cap_021_bollinger_squeeze_breakout'] = (
0.6 if (squeezed and close > bb_u) else
-0.6 if (squeezed and close < bb_l) else 0.0
)
Die Behandlung der makroökonomischen Faktoren ist ähnlich. Für eine eher makroökonomisch orientierte Art von Tradern ist BTC keine vollständig isolierte Kursreihe; sie wird vom US-Dollar, den Aktienmärkten und dem Zinsumfeld beeinflusst. Daher werden auch diese Einsichten als Fähigkeitsbewertungen kodiert:
python
# Ein Rückgang des DXY wird in der Regel als positiver Hintergrund für BTC angesehen
s['cap_027_dxy_inverse_btc'] = 0.4 if (not _nm(dxy_r20) and dxy_r20 < -0.01) else 0.0
# Der Anstieg des S&P deutet auf eine Verbesserung der Risikobereitschaft hin
s['cap_028_spx_risk_on_off'] = 0.4 if (not _nm(spx_r20) and spx_r20 > 0.02) else 0.0
# Ein Rückgang der kurzfristigen Zinssätze kann als marginale Liquiditätsverbesserung angesehen werden
s['cap_029_yields_liquidity'] = 0.4 if (not _nm(y_r20) and y_r20 < -0.02) else 0.0
Was auf dieser Ebene wirklich zählt, ist nicht, wie viele Regeln sie enthält, sondern dass sie den entscheidendsten Schritt der Destillation vollendet: Die Beurteilungen, die zuvor nur subjektiv verstanden werden konnten, wurden in berechenbare Bedingungen komprimiert. An dieser Stelle ist zu erwähnen, dass die meisten Fähigkeitsfaktoren der aktuellen Version immer noch konditionsgetriggert sind und keine kontinuierliche Bewertung darstellen. Das bedeutet, das System beurteilt eher, ob eine bestimmte Struktur vorliegt, anstatt kontinuierlich jede kleine Fluktuation neu zu bewerten. Dies bestimmt auch, dass es derzeit besser für tägliche oder mittelfrequente Entscheidungen geeignet ist, nicht für Hochfrequenzhandel.
Schritt 3: Faktoren werden nicht direkt summiert, sondern zunächst auf Händlerprofile abgebildet
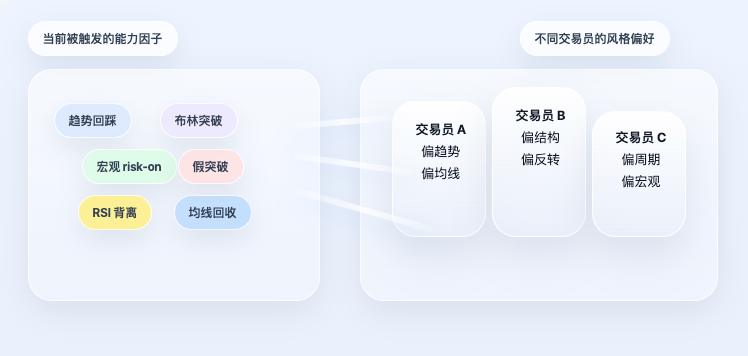
Wenn die Strategie nur auf der Faktorenebene enden würde, wäre sie immer noch ein gewöhnliches Regelsystem. Das Besondere am ursprünglichen Projekt ist, dass es hier nicht aufhört, sondern einen Schritt weitergeht: Die Faktoren bestimmen nicht direkt die Richtung, sondern werden zunächst auf Händlerprofile abgebildet.
Dies ist ein entscheidender Punkt. Denn in der Realität nutzen Händler nicht "alle Fähigkeiten gleichermaßen". Manche neigen zu Trends, andere zu Strukturen, wieder andere zu Zyklen oder makroökonomischen Faktoren. Selbst bei gleicher Marktlage konzentrieren sich verschiedene Personen auf völlig unterschiedliche Aspekte. Daher mittelt das System nicht einfach alle Faktoren, sondern liest zunächst die Fähigkeitspräferenzen jedes Händlers aus und berechnet auf Basis der aktuellen Faktorzustände sein persönliches Signal.
Die entsprechende Logik zum Auslesen der Profile sieht wie folgt aus:
python
# Fähigkeitsfaktoren und deren Gewichtungen jedes Händlers aus dem Profil auslesen
caps = {c['id']: float(c.get('weight', 0.5))
for c in p.get('capabilities_used', [])}
profiles.append({
'handle': p.get('handle', item['name'][:-5]),
'caps': caps
})
Jedes Profil beantwortet im Wesentlichen eine Frage: Auf welche Fähigkeitsfaktoren verlässt sich dieser Händler und wie stark gewichtet er sie in seinem Rahmenwerk? Mit diesem Profil berechnet das System dann das "persönliche Signal" jedes Händlers im aktuellen Markt:
python
for p in profiles:
sig = 0.0
wt = 0.0
# Alle Fähigkeitsfaktoren durchlaufen, die dieser Händler beachtet
for cap_id, w in p['caps'].items():
score = factor_scores.get(cap_id, 0.0)
# Faktor-Score multipliziert mit der Präferenzgewichtung des Händlers
sig += w * score
wt += abs(w)
# Normalisiert ergibt sich das persönliche Signal des Händlers im aktuellen Markt
trader_raw = sig / wt if wt > 0 else 0.0
An diesem Punkt ist der Charakter des Systems bereits deutlich anders. Es geht nicht mehr nur darum, "welche Faktoren leuchten", sondern es wird etwas Ähnliches rekonstruiert: Wenn man den heutigen Markt diesen 99 Händlern übergeben würde, wie würden sie jeweils urteilen?
Schritt 4: Vom persönlichen Signal zum gewichteten Konsens
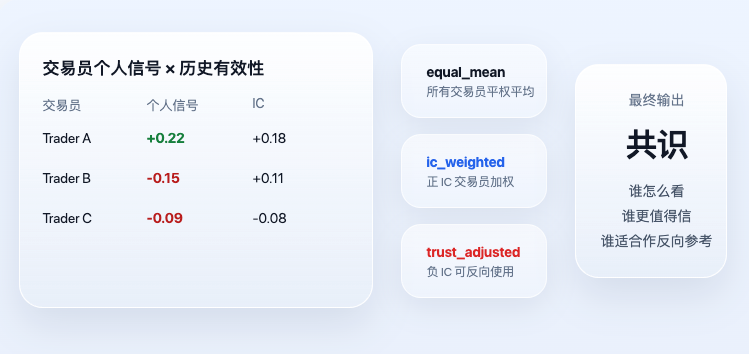
Sobald das persönliche Signal jedes Händlers berechnet ist, tritt das System in die eigentliche Konsensebene ein. Der "Konsens" hier ist keine einfache Abstimmung, geschweige denn, wer die lauteste Stimme hat, entscheidet. Vielmehr wird die historische Effektivität weiter berücksichtigt.
Die beiden wichtigsten Ergebnisse im aktuellen Code sind ic_weighted und trust_adjusted. Die zugehörige Kernlogik lautet:
python
# Zunächst die Händler mit positivem IC positiv gewichten, ergibt ic_weighted
pos_w = sum(max(t['ic'], 0) for t in trader_signals)
ic_wt = (
sum(t['signal'] * max(t['ic'], 0) for t in trader_signals) / pos_w
if pos_w > 0 else 0.0
)
# trust_adjusted geht noch einen Schritt weiter:
# Positives IC wird gleichsinnig verwendet, negatives IC gegensinnig, dann nach absolutem IC gewichtet
abs_w = sum(abs(t['ic']) for t in trader_signals)
trust = (
sum((t['signal'] if t['ic'] >= 0 else -t['signal']) * abs(t['ic'])
for t in trader_signals) / abs_w
if abs_w > 0 else 0.0
)
Dieser Code drückt zwei sehr einfache, aber äußerst wichtige Prinzipien aus. Erstens: Händler, die historisch effektiver waren, erhalten heute ein größeres Gewicht. Zweitens: Händler mit historisch negativem IC werden nicht verworfen, sondern möglicherweise als konträre Indikatoren genutzt. Daher ist der endgültige trust_adjusted nicht einfach "was alle denken", sondern "wer denkt was und wem ist mehr zu vertrauen".
Deshalb unterscheidet sich dieses System auch von gewöhnlichen Sentiment-Modellen. Es zählt nicht die Anzahl der Stimmen, sondern führt eine kognitive Aggregation mit historischer Überprüfung durch. Wenn man die gesamte Methode auf einen Satz komprimieren würde, wäre es: Zuerst den Markt in Zustandsvariablen umwandeln, dann die Zustandsvariablen auf Fähigkeitsfaktoren abbilden, dann die Fähigkeitsfaktoren auf persönliche Händlersignale abbilden und schließlich diese persönlichen Signale nach historischer Effektivität zu einer Konsensentscheidung aggregieren.
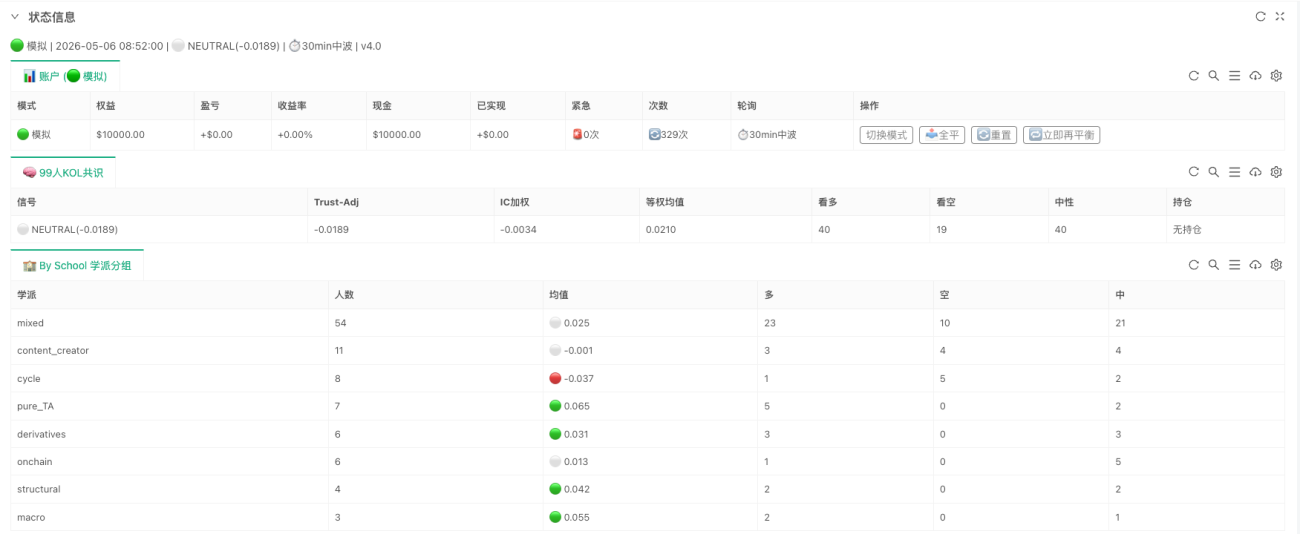
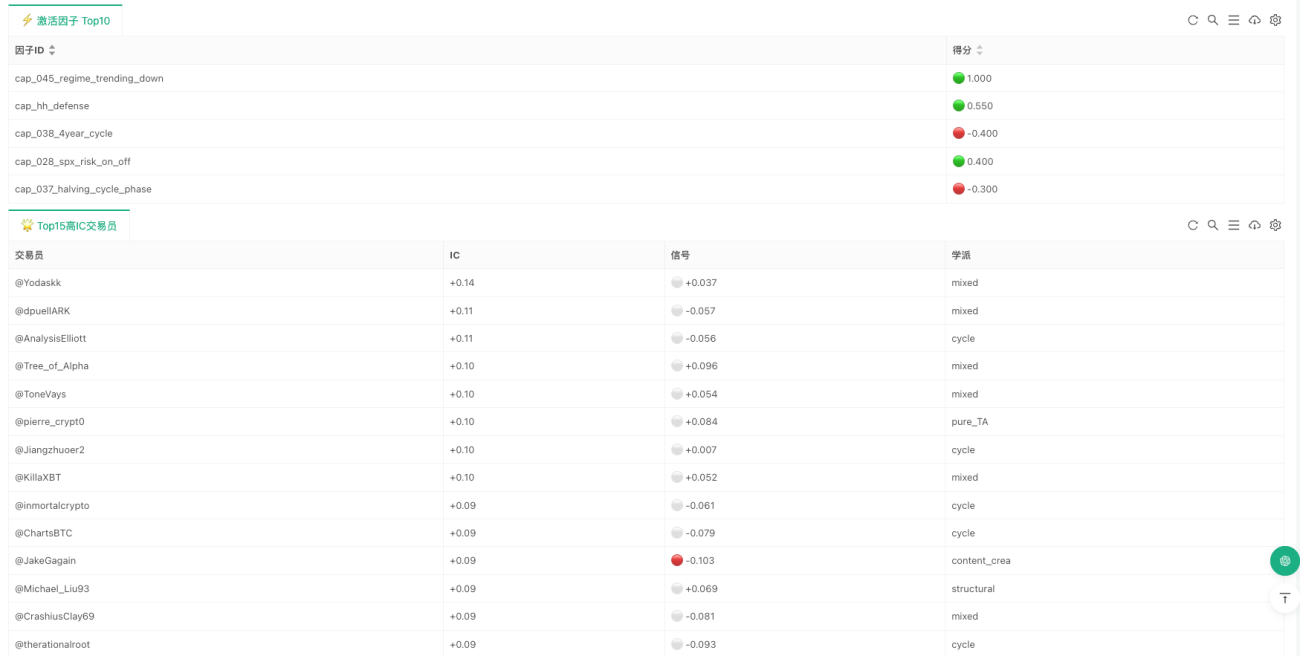
Was die Implementierung auf FMZ (Inventor) wirklich durchlaufen lässt
Wenn diese Systeme nur in Forschungsprojekten bleiben würden, wären sie eher ein "Konsensanalysator". Die Implementierung auf FMZ konzentriert sich darauf, die gesamte Kette tatsächlich zu verbinden und kontinuierlich laufen zu lassen. Der Kerncode besteht eigentlich nur aus drei Zeilen:
python
# Schritt 1: Rohdaten und makroökonomische Variablen in strukturierte Zustände umwandeln
feat_df = build_features(records, macro if macro else None)
# Schritt 2: Bewerten, welche Fähigkeitsfaktoren basierend auf Zustandsvariablen ausgelöst werden
factor_scores = evaluate_factors(feat_df)
# Schritt 3: Fähigkeitsfaktoren auf Händlerprofile abbilden und zu einem Konsensergebnis aggregieren
consensus = compute_consensus(factor_scores)
Diese drei Zeilen stellen die wichtigsten drei Abstraktionsebenen der gesamten Strategie dar. Die erste Ebene kümmert sich um den Marktzustand, die zweite um die Fähigkeitsbeurteilung und die dritte um den Händlerkonsens. Dahinter folgen natürlich noch die Ausführungsebene, das Risikomanagement und die Zustandsanzeige, aber aus Forschungssicht ist der wesentliche Teil bereits vollständig etabliert. Die Hauptbedeutung dieser Implementierung liegt nicht darin, wie viele Ausführungsdetails sie hinzufügt, sondern dass die Fähigkeitsprofile des ursprünglichen Projekts nicht länger statische Dateien sind, die Faktoren nicht länger reine Forschungsoutputs und der Konsens nicht länger nur eine Zahl in einem Bericht. Sie wurden in einen kontinuierlich laufenden Beurteilungsprozess integriert.
Warum es dennoch nur ein Prototyp ist
Natürlich ist diese Implementierung nicht das Endprodukt. Der aktuelle Code verwendet einen BTC-Tagesrahmen, daher eignet er sich besser für mittel- bis niederfrequente Konsensentscheidungen als für Hochfrequenzhandelssysteme. Sein Kern konzentriert sich weiterhin auf Tagesstrukturen, zyklische Positionen, makroökonomische Hintergründe und Händlerfähigkeitspräferenzen. Darüber hinaus sind die Händlerprofile und ICs derzeit noch statische Eingaben, die noch keine Online-Evolution durchlaufen haben. Das System hat zwar den ersten Schritt der "Wissensdestillation" abgeschlossen, aber noch nicht vollständig erreicht, dass sich das destillierte Wissen selbst korrigiert.
Dennoch zeigt es bereits eine sehr wichtige Sache: Die Erfahrung von Händlern kann schichtweise komprimiert, strukturiert und tatsächlich in eine Strategiekette integriert werden. Sein Wert liegt nicht darin, bereits stabile Renditen zu erzielen, sondern darin, einen Forschungspfad, der zuvor auf konzeptioneller Ebene verblieb, in eine ausführbare Phase zu bringen. Wie sich diese Fähigkeitsfaktoren weiterentwickeln, wie die Händlergewichte aktualisiert werden und wie der Konsens in echten Märkten kontinuierlich kalibriert wird, erfordert noch mehr Betriebsdaten zur Beantwortung.
Schlussbemerkung
Das wirklich Inspirierende an crypto-kol-quant liegt nicht darin, wie viele trendige Konzepte es verwendet, sondern darin, dass es etwas, das nur schwer systematisierbar ist, einen Schritt vorangebracht hat: Die Erfahrung von Händlern wurde von einer Beschreibung zu einer Fähigkeit, von einer Fähigkeit zu einem Faktor und vom Faktor zu einem Konsens gemacht. Die Implementierung auf FMZ tut genau das: Sie bringt diese Destillationskette tatsächlich zum Laufen. Sie behauptet nicht, bereits das Endprodukt zu sein, und versucht nicht zu verbergen, dass sie immer noch ein früher Prototyp ist. Aber sie hat zumindest bewiesen, dass Handelserfahrung nicht nur in Charts und Sprache verbleiben muss; sie kann destilliert, strukturiert, ausgeführt und sogar in ein System integriert werden, das kontinuierlich den Markt beurteilt.
Wenn traditionelle quantitative Methoden darin gut sind, Muster aus Preisserien zu extrahieren, dann besteht die lohnende Richtung für solche Strategien vielleicht darin: Muster aus menschlicher Kognition zu extrahieren und diese Muster dann wiederum am Markt teilnehmen zu lassen. Und das könnte genau der Aspekt sein, der bei der "Destillation" in der Strategieforschung am meisten Beachtung verdient.
Ursprüngliches Projekt: 锁妖塔 Skill — 炼化99个加密交易员
Besonderer Dank gilt dem Benutzer "GiantBin" für die bereitgestellten Ideen. Wenn jemand gute Ideen oder Gedanken hat, sind Austausch und Diskussion jederzeit willkommen.
- 1