
Market Collector wurde erneut aktualisiert - unterstützt den Import von Dateien im CSV-Format und bietet benutzerdefinierte Datenquellen
Vor Kurzem musste ein Benutzer seine eigene Datei im CSV-Format als Datenquelle für das Backtesting-System der Inventor Quantitative Trading Platform verwenden. Das Backtesting-System der Inventor Quantitative Trading Platform verfügt über viele Funktionen und ist einfach und effizient zu verwenden. Solange Sie über die Daten verfügen, können Sie Backtests durchführen und sind nicht mehr auf die vom Plattform-Rechenzentrum unterstützten Börsen und Produkte beschränkt .
Gestaltungsideen
Die Designidee ist eigentlich sehr einfach. Wir müssen nur eine kleine Änderung am bisherigen Marktsammler vornehmen. Wir fügen dem Marktsammler einen Parameter hinzu.isOnlySupportCSVWird verwendet, um zu steuern, ob nur CSV-Dateien als Datenquellen für das Backtesting-System verwendet werden sollen, und um einen weiteren Parameter hinzuzufügenfilePathForCSV, wird verwendet, um den Pfad zur CSV-Datendatei auf dem Server festzulegen, auf dem der Market Collector-Roboter ausgeführt wird. Schließlich, nachisOnlySupportCSVIst der Parameter aufTrueUm zu entscheiden, welche Datenquelle verwendet werden soll (1. selbst gesammelt, 2. Daten in CSV-Datei), ist diese Änderung vor allem inProviderKlassedo_GETFunktion.
Was ist eine CSV-Datei?
Comma-Separated Values (CSV, manchmal auch Character-Separated Values genannt, da die Trennzeichen auch andere als Kommas sein können) sind Dateien, die tabellarische Daten (Zahlen und Texte) im Klartext speichern. Reiner Text bedeutet, dass die Datei eine Zeichenfolge ist und keine Daten enthält, die wie Binärzahlen interpretiert werden müssen. Eine CSV-Datei besteht aus einer beliebigen Anzahl von Datensätzen, die durch eine Art Zeilenumbruchzeichen getrennt sind. Jeder Datensatz besteht aus Feldern und die Felder werden durch andere Zeichen oder Zeichenfolgen getrennt. Am häufigsten sind Kommas oder Tabulatoren. Normalerweise haben alle Datensätze genau die gleiche Feldfolge. Dabei handelt es sich normalerweise um reine Textdateien. Es wird empfohlen, WORDPAD oder Notepad zum Öffnen zu verwenden. Eine andere Methode besteht darin, es als neue Datei zu speichern und dann mit EXCEL zu öffnen.
Für das CSV-Dateiformat gibt es keinen universellen Standard, aber es gelten bestimmte Regeln: Im Allgemeinen eine Zeile pro Datensatz, wobei die erste Zeile die Kopfzeile ist. Die Daten in jeder Zeile sind durch Kommas getrennt.
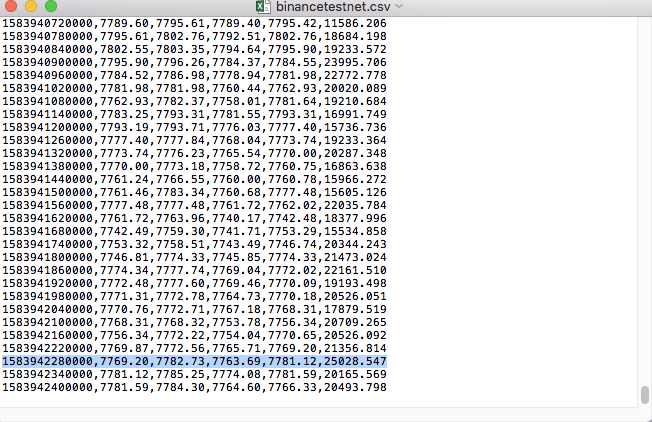
Beispielsweise sieht die CSV-Datei, die wir zum Testen verwendet haben, folgendermaßen aus, wenn sie mit Notepad geöffnet wird:
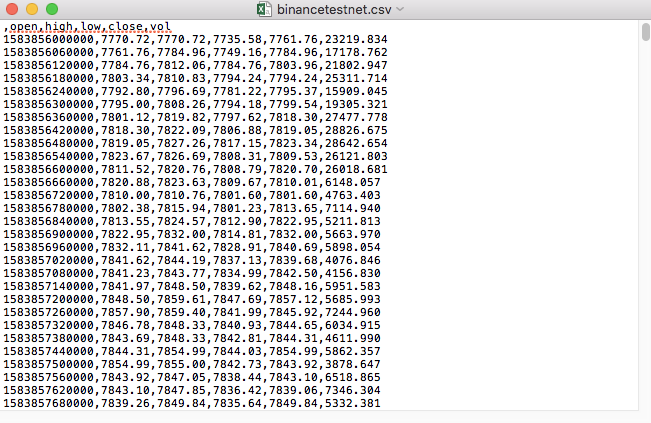
Beachten Sie, dass die erste Zeile der CSV-Datei die Tabellenüberschrift ist.
,open,high,low,close,vol
Wir müssen diese Daten analysieren und organisieren und sie dann in das Format bringen, das von der benutzerdefinierten Datenquelle des Backtesting-Systems benötigt wird. Dies wurde bereits im Code unseres vorherigen Artikels behandelt und erfordert nur geringfügige Änderungen.
Geänderter Code
import _thread
import pymongo
import json
import math
import csv
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global isOnlySupportCSV, filePathForCSV
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
# 目前回测系统只能从列表中选择交易所名称,在添加自定义数据源时,设置为币安,即:Binance
exName = exchange.GetName()
# 注意,period为底层K线周期
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# 要求应答的数据
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
if isOnlySupportCSV:
# 处理CSV读取,filePathForCSV路径
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
# 获取表头
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
# 读取内容
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据:", data, "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
return
# 连接数据库
Log("连接数据库服务,获取数据,数据库:", exName, "表:", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# 构造查询条件:大于某个值{'age': {'$gt': 20}} 小于某个值{'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("查询条件:", dbQuery, "查询条数:", exRecords.find(dbQuery).count(), "数据库总条数:", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# 需要根据请求参数round和vround,处理数据精度
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("数据:", data, "响应回测系统请求。")
# 写入数据应答
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
if (isOnlySupportCSV):
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程,数据由CSV文件提供。", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
LogStatus(_D(), "只启动自定义数据源服务,不收集数据!")
Sleep(2000)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("收集", exName, "交易所的K线数据,", "K线周期:", period, "秒")
# 连接数据库服务,服务地址 mongodb://127.0.0.1:27017 具体看服务器上安装的mongodb设置
Log("连接托管者所在设备mongodb服务,mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# 创建数据库
ex_DB = myDBClient[exName]
# 打印目前数据库表
collist = ex_DB.list_collection_names()
Log("mongodb ", exName, " collist:", collist)
# 检测是否删除表
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "删除:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "删除失败")
else :
Log(dropName, "删除成功")
# 开启一个线程,提供自定义数据源服务
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
# 创建records表
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("开始收集", exName, "K线数据", "周期:", period, "打开(创建)数据库表:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# 首次写入所有BAR数据
for i in range(len(r) - 1):
bar = r[i]
# 逐根写入,需要判断当前数据库表中是否已经有该条数据,基于时间戳检测,如果有该条数据,则跳过,没有则写入
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# 写入bar到数据库表
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# 写入数据前检测,数据是否已经存在,基于时间戳检测
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# 增加画图展示
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
Ausführen von Tests
Zuerst starten wir den Marktsammelroboter, fügen dem Roboter eine Börse hinzu und lassen den Roboter laufen.
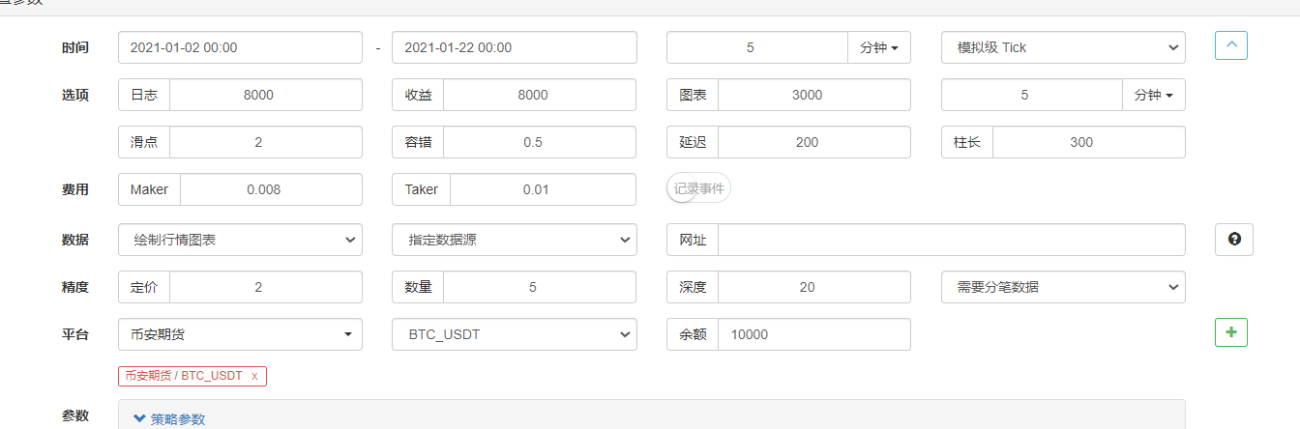
Parameterkonfiguration:

Dann erstellen wir eine Teststrategie:
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
}
Die Strategie ist sehr einfach: Es müssen lediglich drei K-Zeilen-Daten abgerufen und gedruckt werden.
Legen Sie auf der Backtesting-Seite die Datenquelle des Backtesting-Systems auf eine benutzerdefinierte Datenquelle fest und geben Sie die Serveradresse ein, auf der der Market Collector-Roboter ausgeführt wird. Da es sich bei den Daten in unserer CSV-Datei um 1-Minuten-K-Linien handelt. Daher legen wir beim Backtesting die K-Line-Periode auf 1 Minute fest.
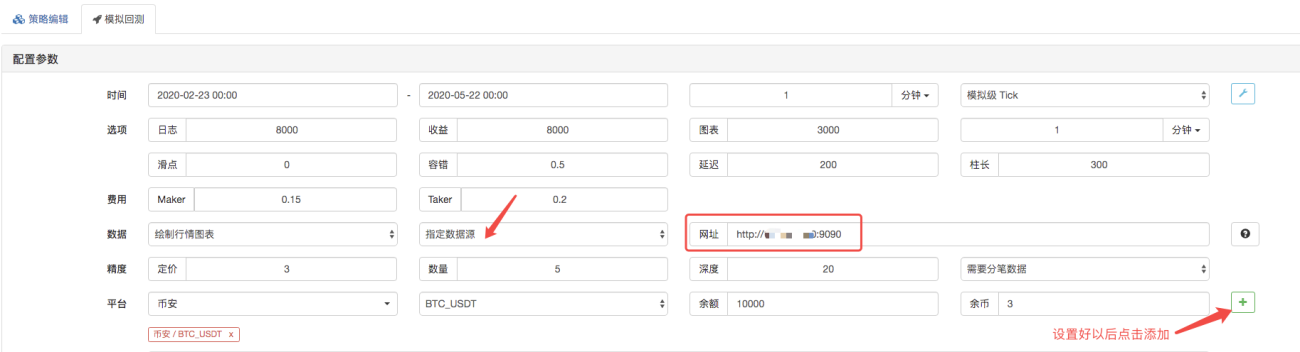
Klicken Sie auf „Backtesting starten“, und der Marktsammelroboter empfängt die Datenanforderung:

Nachdem das Backtesting-System die Ausführung der Strategie abgeschlossen hat, generiert es ein K-Line-Diagramm basierend auf den K-Line-Daten in der Datenquelle.
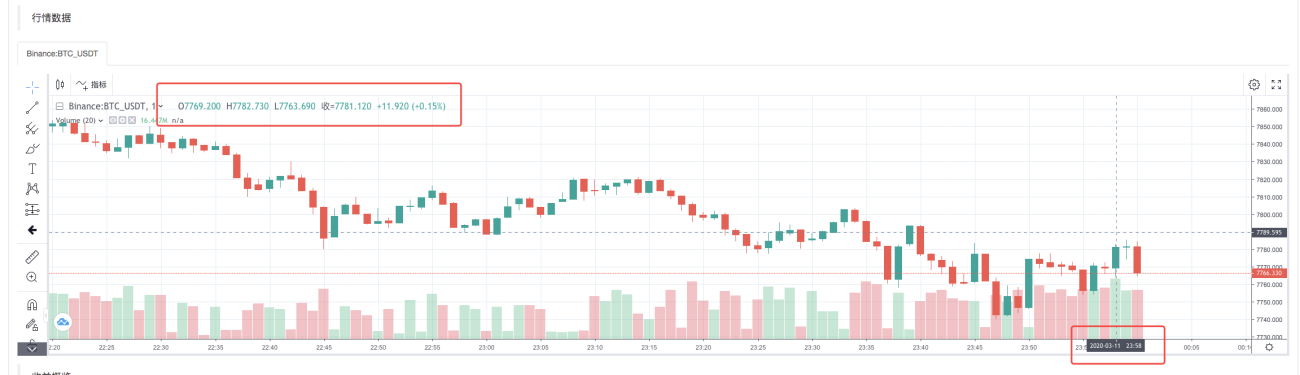
Vergleichen Sie die Daten in der Datei:

Dies ist nur ein Ausgangspunkt. Sie können gerne eine Nachricht hinterlassen.




请问一下,为什么我在托管服务器上面设置好了自定义CSV数据源,用页面请求有数据的返回,然后在回测中没有数据的返回,当把数据直接设置为只有俩个数据的时候httpserver服务端可以接收请求中, 




你在浏览器端可以是因为 你指定写的查询参数, 回测系统 触发不了 机器人 应答,说明机器人没接受到请求, 说明回测时那个地方配置错了, 检查下,调试下就能找到问题。
请问一下 怎么可以在本地起http服务端 本地回测数据, 是不是本地回测不支持回测自定义数据源?我在本地回测添加exchanges: [{"eid":"Huobi","currency":"ETH_USDT","feeder":"http://127.0.0.1:9090"}]这种参数,以及改成机器人的IP也是没有请求到服务端



- 1