Three graphs to understand machine learning: basic concepts, five genres and nine common algorithms
Author: The Little Dream, Created: 2017-05-02 14:49:49, Updated:Three graphs to understand machine learning: basic concepts, five genres and nine common algorithms
-
The first is an overview of machine learning.

-
What is machine learning?
Machines learn by analyzing large amounts of data. For example, they don't need to be programmed to recognize cats or faces; they can be trained to infer and identify specific targets by using images.
-
Machine learning and AI
Machine learning is a discipline of research and algorithms that focuses on finding patterns in data and using those patterns to make predictions. Machine learning is part of the field of artificial intelligence and intersects with knowledge discovery and data mining.
-
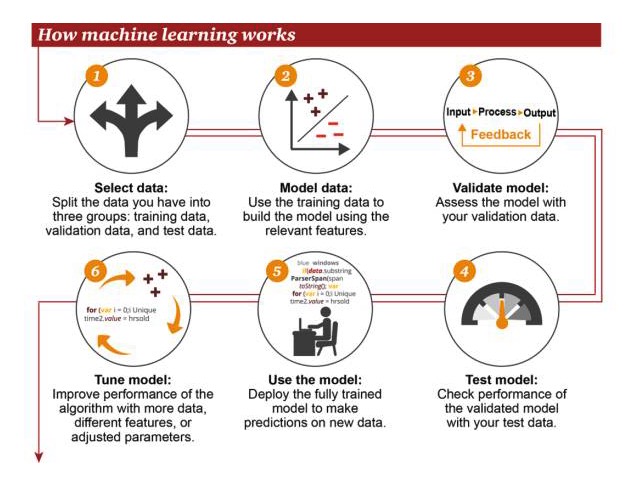
How machine learning works
1 Select data: divide your data into three groups: training data, verification data, and test data 2 Model data: Use training data to build models using relevant features 3 Validation model: Use your validation data to access your model 4 Test model: use your test data to check the performance of the validated model 5 Using models: using fully trained models to make predictions on new data 6 Optimization model: using more data, different features or modified parameters to improve algorithm performance
-
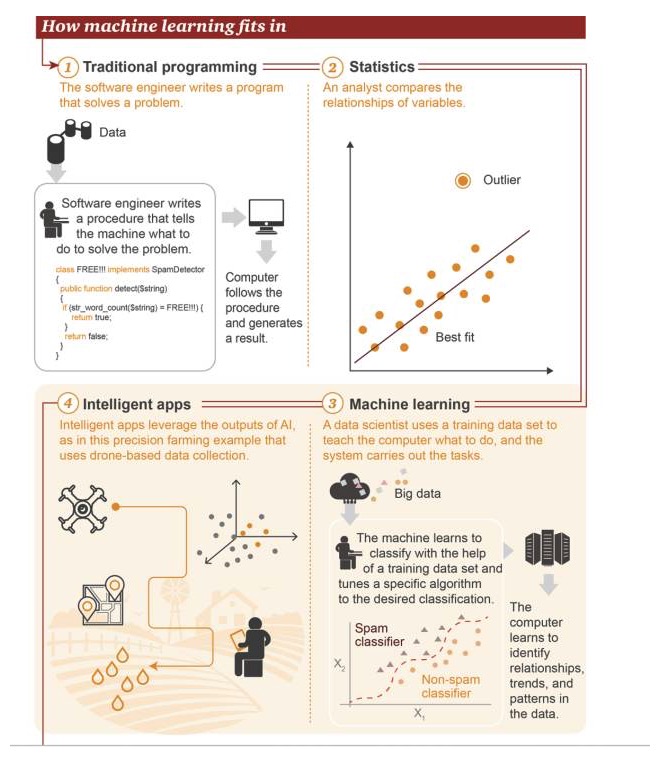
Where is machine learning?
1 Traditional programming: Software engineers write programs to solve problems. First there is some data→ To solve a problem, the software engineer writes a process to tell the machine what to do→ The computer follows this process and then produces results 2 Statistics: Analysts compare the relationships between variables 3 Machine learning: Data scientists use training data sets to teach a computer what to do, and then the system performs the task. First, there is big data→ The machine learns to use training data sets to classify, adjust specific algorithms to achieve the target classification→ The computer learns to identify relationships, trends and patterns in the data 4 Smart Applications: The results of smart applications using artificial intelligence, as shown in the figure, are an example of an application case for precision agriculture based on data collected by drones

-
Practical applications of machine learning
There are a lot of application scenarios for machine learning, and here are some examples of how you would use it.
Rapid 3D mapping and modeling: To build a railway bridge, PwC's data scientists and field experts apply machine learning to the data collected by the drones. This combination enables precise monitoring and rapid feedback in the success of the work.
Enhanced analytics to reduce risk: In order to detect internal transactions, PwC combines machine learning with other analytics techniques to develop a more comprehensive user profile and gain a deeper understanding of complex suspicious behavior.
Predict best performing targets: PwC uses machine learning and other analytical methods to evaluate the potential of different horses at Melbourne Cup racetracks.
-
-
The evolution of machine learning

For decades, various "tribes" of AI researchers have been competing for dominance. Is it time for these tribes to unite? They may have to, too, because collaboration and algorithm fusion is the only way to achieve truly universal AI (AGI).
-
The five major genres
1 Symbolism: use of symbols, rules and logic to represent knowledge and make logical inferences, preferred algorithms are: rules and decision trees 2 Bayesian: Obtaining the probability of occurrence to make probability inference, preferred algorithms are: Simple Bayesian or Markov 3 Connectivism: using probability matrices and weighted neurons to dynamically identify and infer patterns, preferred algorithm: neural network 4 Evolutionism: generating variation and then selecting the best of them for a specific goal. 5 Analogizer: Optimize the function according to constraints (go as high as possible, but at the same time do not go off the road), favorite algorithm is: support vector machine
-
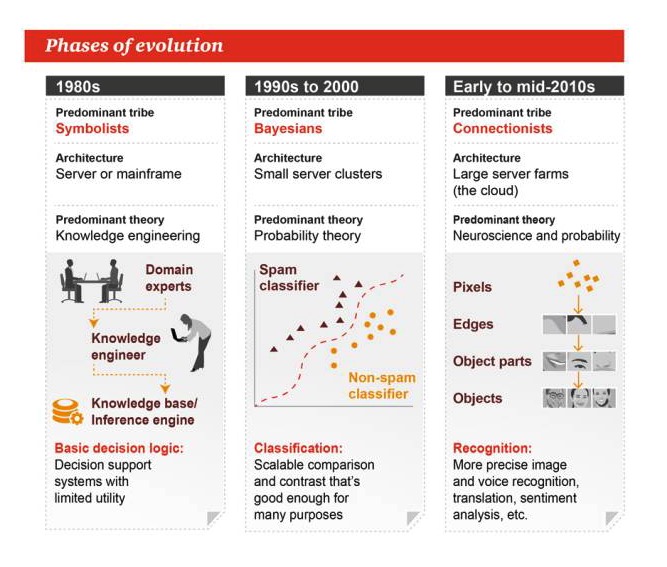
Stages of evolution
1980s
The main genre: Symbolism Architecture: server or mainframe The dominant theory: knowledge engineering Basic decision logic: decision support systems with limited practicality
1990s to 2000s
The main genre: Baez Architecture: Small clusters of servers The dominant theory is probability theory. Categories: Scalable comparisons or contrasts, good enough for many tasks
Early to mid-2010s
The main genre: Unionism Architecture: Large server farms The dominant theory: neuroscience and probability Recognition: more accurate image and voice recognition, translation, emotion analysis and more
-
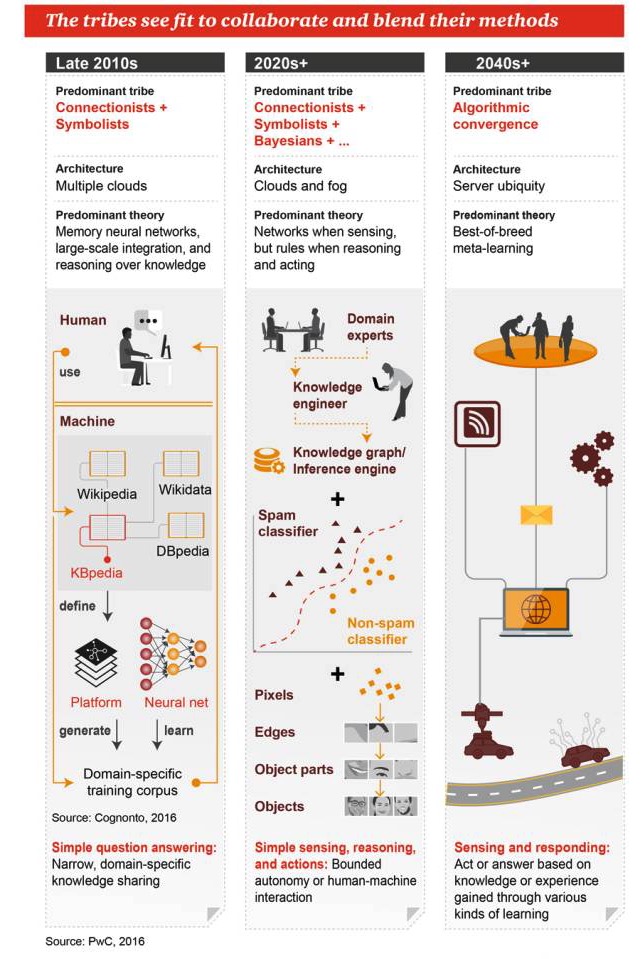
These genres are expected to collaborate and blend their respective approaches together.
Late 2010s
The main genre: Unionism + Symbolism Architecture: many clouds The dominant theories: memory neural networks, mass integration, knowledge-based reasoning Simple questions and answers: narrow, domain-specific knowledge sharing
The 2020s+
The main styles are unionism + symbolism + Bayes +... Architecture: cloud computing and fog computing The dominant theory: there are networks when it comes to perception, rules when it comes to reasoning and working Simple perception, reasoning and action: limited automation or human-computer interaction
The 2040s+
The main genre: algorithmic fusion Architecture: servers everywhere The dominant theory: the best combination of meta-learning Perception and response: taking action or responding based on knowledge or experience gained through multiple learning modalities
-
-
Three, algorithms for machine learning

Which machine learning algorithm should you use? This largely depends on the nature and quantity of data available and your training objectives in each specific use case. Do not use the most complex algorithms unless the results are worth the costly expense and resources. Here are some of the most common algorithms, sorted by ease of use.
-
Decision Tree: In step-by-step response, typical decision tree analysis uses hierarchical variables or decision nodes, for example, to classify a given user as creditworthy or not.
Pros: Good at evaluating a range of different characteristics, qualities and properties of people, places and things Scenario examples: rule-based credit assessments, horse race results predictions
-
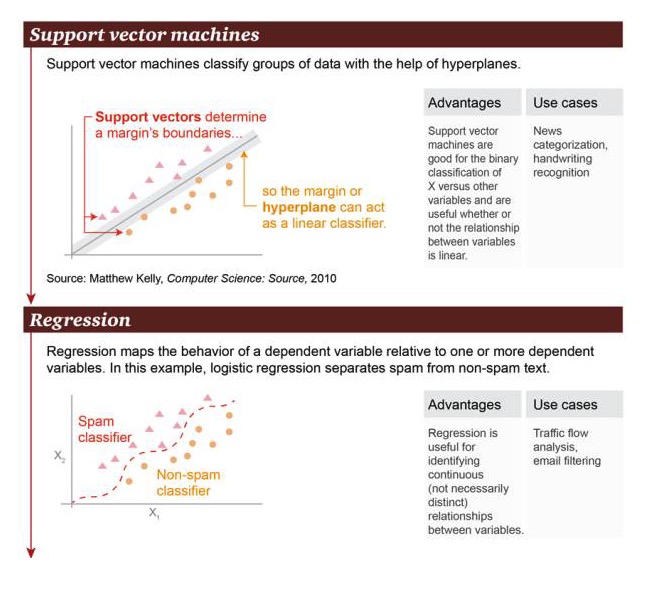
Support Vector Machine: based on hyperplane, support vector machines to classify data sets.
Advantages: Support vector machines that are good at performing binary classification operations between variables X and other variables, whether their relationships are linear or not Scenario examples: news classification, handwriting recognition.
-
Regression: Regression can draw a state relationship between a causative variable and one or more causative variables. In this example, a distinction is made between spam and non-spam.
Pros: Regression can be used to identify continuous relationships between variables, even if the relationship is not very obvious Scenario examples: traffic analysis, filtering of mail
-
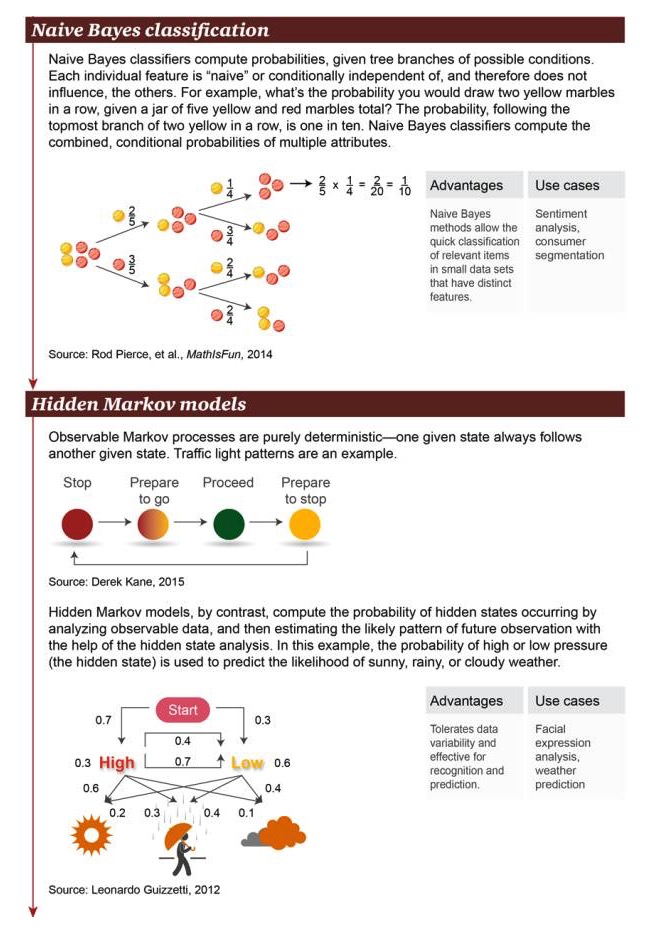
Naive Bayes Classification: Naive Bayes classifiers are used to calculate the branching probability of possible conditions. Each independent characteristic is "naïve" or conditionally independent, so they do not affect other objects. For example, what is the probability of picking up two yellow balls in a row in a deck of 5 yellow and red spheres?
Advantages: Simple Bayesian methods allow for rapid classification of relevant objects with significant features in small datasets Scenario examples: sentiment analysis, consumer classification
-
Hidden Markov model: The implicit Markov process is one in which a given state is often accompanied by another state; traffic lights are an example; instead, the Hidden Markov model calculates the occurrence of the hidden state by analyzing visible data. Subsequently, using hidden state analysis, the Hidden Markov model can estimate possible future observation patterns. In this case, the probability of high or low atmospheric pressure (which is the hidden state) can be used to predict the probability of a clear, rainy, cloudy day.
Advantages: Allows variability of data, suitable for recognition and predictive operations Examples of scenarios: facial expressions, weather forecasts
-
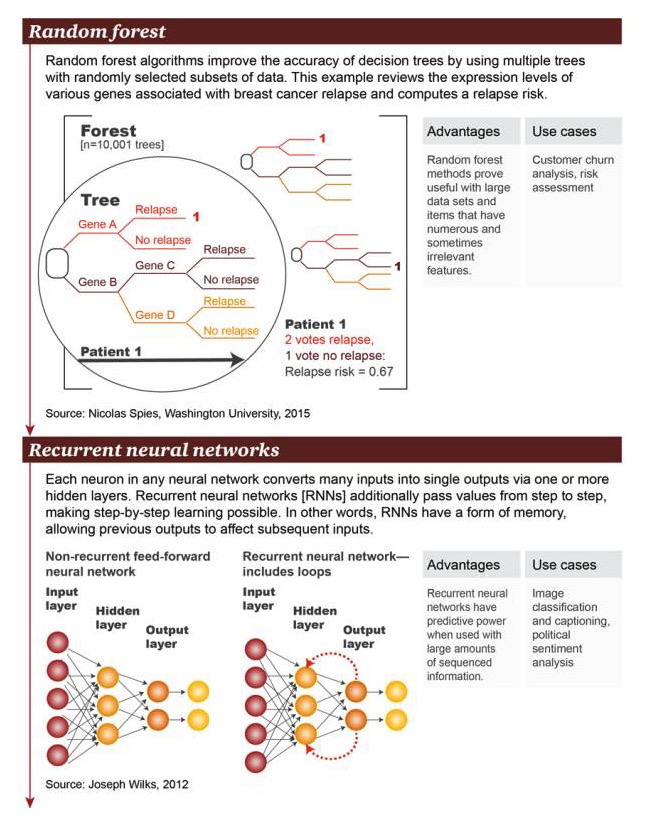
Random forest: Random forest algorithms improve the accuracy of decision trees by using multiple trees with a randomly selected subset of data. This case examines a large number of genes associated with breast cancer recurrence at the level of gene expression and calculates the risk of recurrence.
Pros: The random forest method has been shown to be useful for large datasets and items with large and sometimes unrelated features Scenario examples: analysis of user losses, risk assessment
-
Recurrent neural network: In an arbitrary neural network, each neuron converts many inputs into a single output through one or more hidden layers. A recurrent neural network (RNN) passes values further down the layer, making layered learning possible. In other words, an RNN has some form of memory that allows the previous output to influence the subsequent input.
Pros: Circular neural networks are predictive when there is a large amount of ordered information Scene examples: image classification and subtitling, political sentiment analysis

-
Long short-term memory (LSTM) with gated recurrent unit neural networks: Although these early forms of RNNs allowed only a small amount of early information to be retained, newer LSTMs with gated short-term memory (GRUs) have both long and short-term memory. In other words, these newer RNNs have better control memory capabilities, allowing for the retention of earlier processing or repositioning of values when many series of steps are needed, which avoids the eventual degradation of values that can be "gradient decayed" or layered over.
Advantages: Long- and short-term memory and gate-controlled circular cell neural networks have the same advantages as other circular neural networks, but are more often used because they have better memory capabilities Scenario examples: natural language processing, translation
-
Convolutional neural network: Convolution refers to the convergence of weights from subsequent layers, which can be used to mark the output layer.
Advantages: convolutional neural networks are very useful when there are very large data sets, a large number of features and complex classification tasks Scenario examples: image recognition, text translation of speech, drug discovery
-
-
The original link:
http://usblogs.pwc.com/emerging-technology/a-look-at-machine-learning-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-methods-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-evolution-infographic/
Transcribed from Big Data Landscape
- Why is the difference in the area a measure of the degree of dissociation?
- How to determine the failure of a procedural transaction model
- BitMEX exchange API note BitMEX exchange API terms of use
- Extreme trading in trend trading exposed
- How to use code to fine-tune the filter feedback system to set the filter by default
- High frequency strategy
- The classic mistakes newcomers make when making options
- How Bitcoin's High-Frequency Harvester Strategy 1 was implemented
- Understanding the various stakeholders in the futures market
- The trend is backtracking.
- The consistency of the dividend that determines profitability
- 2.14 How to call an exchange's API
- What do you think of the latest Ethereum and Ethereum platforms?
- null
- Six tips to keep your futures safe overnight
- The gold standard for overnight futures trading (trend trading)
- Playing games
- The Mystery of Leisure
- Sharp is 0.6, should we throw it out?
- How to make money with options strategies, someone finally told us!