Tres imágenes para entender el aprendizaje automático: conceptos básicos, cinco grandes escuelas y nueve algoritmos comunes
 0
2546
0
2546
Tres imágenes para entender el aprendizaje automático: conceptos básicos, cinco grandes escuelas y nueve algoritmos comunes
- #### Una visión general del aprendizaje automático

¿Qué es el aprendizaje automático?
Las máquinas aprenden analizando grandes cantidades de datos. Por ejemplo, no necesitan ser programadas para reconocer gatos o rostros humanos, sino que pueden ser entrenadas para usar imágenes para resumir y reconocer objetivos específicos.
El aprendizaje automático y la inteligencia artificial
El aprendizaje automático es una disciplina de investigación y algoritmos que busca patrones en los datos y los utiliza para hacer predicciones. El aprendizaje automático es parte del campo de la inteligencia artificial y se encuentra en la intersección entre el descubrimiento de conocimiento y la minería de datos.
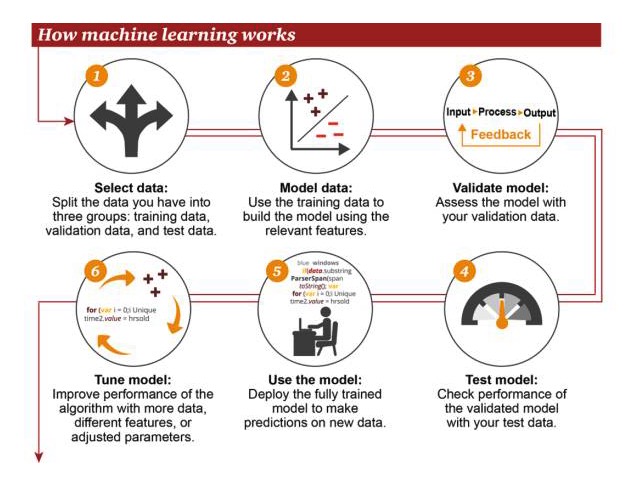
Cómo funciona el aprendizaje automático
1 Selección de datos: divida sus datos en tres grupos: datos de entrenamiento, datos de verificación y datos de prueba 2 Datos del modelo: usar datos de entrenamiento para construir modelos que utilicen características relacionadas 3 Modelos de verificación: usa tus datos de verificación para acceder a tu modelo 4 Modelos de prueba: el rendimiento de los modelos verificados con sus datos de prueba 5 Usar modelos: usar modelos completamente entrenados para hacer predicciones sobre nuevos datos 6 Modelo de ajuste: usa más datos, diferentes características o parámetros ajustados para mejorar el rendimiento del algoritmo
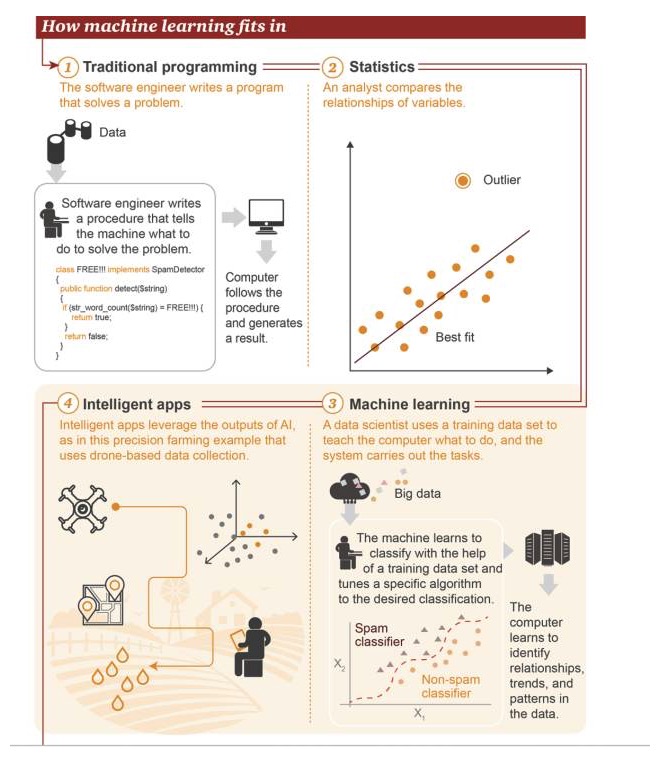
La ubicación del aprendizaje automático
1 Programación tradicional: los ingenieros de software escriben programas para resolver problemas. Primero existen algunos datos. Para resolver un problema, los ingenieros de software escriben un proceso para decirle a la máquina cómo debe hacerse. 2 Estadística: los analistas comparan las relaciones entre las variables 3 Aprendizaje automático: los científicos de datos utilizan un conjunto de datos de entrenamiento para enseñar a la computadora lo que debe hacer, y luego el sistema ejecuta la tarea. Primero, existe el Big Data→ La máquina aprende a usar el conjunto de datos de entrenamiento para clasificar y ajustar un algoritmo específico para lograr la clasificación de objetivos→ La computadora aprende a identificar relaciones, tendencias y patrones en los datos 4 Aplicaciones inteligentes: Aplicaciones inteligentes que utilizan los resultados obtenidos por la inteligencia artificial, como se muestra en el gráfico es un caso de aplicación de agricultura de precisión, que se basa en los datos recopilados por los drones

Aplicaciones prácticas del aprendizaje automático
Hay muchos escenarios de aplicación de aprendizaje automático, aquí hay algunos ejemplos, ¿cómo lo usarías?
Mapeo y modelado tridimensional rápido: para construir un puente ferroviario, los científicos de datos y expertos en el campo de PwC aplican el aprendizaje automático a los datos recopilados por los drones. Esta combinación permite una supervisión precisa y una retroalimentación rápida del éxito del trabajo.
Análisis de potenciación para reducir el riesgo: para detectar transacciones internas, PwC combina el aprendizaje automático con otras técnicas de análisis, lo que permite desarrollar un perfil de usuario más completo y obtener un conocimiento más profundo de comportamientos sospechosos complejos.
Objetivos de predicción de la mejor actuación: PwC utiliza el aprendizaje automático y otros métodos analíticos para evaluar el potencial de los diferentes caballos en la Melbourne Cup.
- #### La evolución del aprendizaje automático

Las “tribus” de investigadores de inteligencia artificial han estado luchando entre sí por la supremacía durante décadas. ¿Es el momento de que estas tribus se unan? Tal vez tengan que hacerlo, ya que la colaboración y la fusión de algoritmos es la única manera de lograr una verdadera inteligencia artificial general (AGI).
Las cinco grandes corrientes
1 Simbolismo: el uso de símbolos, reglas y lógica para representar el conocimiento y el razonamiento lógico, el algoritmo favorito es: reglas y árboles de decisión 2 Bayesianismo: obtener la probabilidad de que ocurra para hacer inferencias de probabilidad, el algoritmo favorito es: simple Bayes o Markov 3 Conectivismo: el uso de matrices de probabilidad y neuronas ponderadas para identificar y resumir patrones de manera dinámica, el algoritmo favorito es: redes neuronales 4 Evolucionismo: generar cambios y luego obtener el mejor de ellos para un objetivo específico, el algoritmo favorito es: algoritmo genético 5 Analogizador: optimiza la función en función de las restricciones ((llega lo más alto posible, pero al mismo tiempo no te alejes del camino), el algoritmo favorito es: soporte para máquinas vectoriales
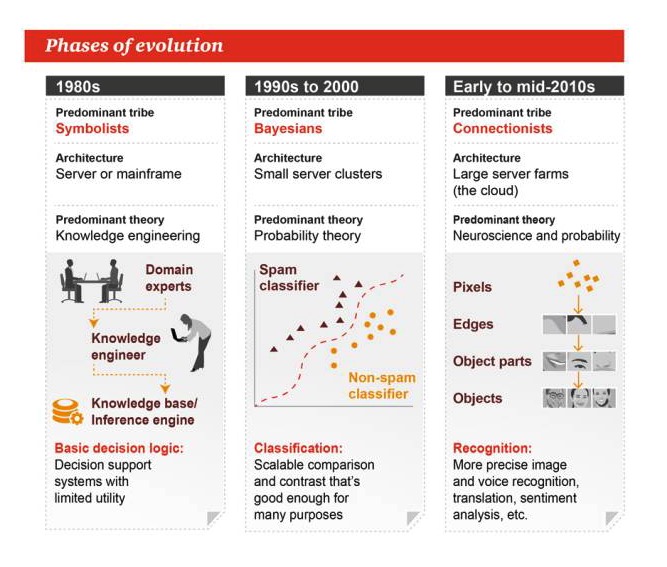
Las etapas de la evolución
La década de 1980
El simbolismo es el género dominante. Arquitectura: Servidor o máquina grande Teoría dominante: la ingeniería del conocimiento Lógica básica de la toma de decisiones: sistemas de apoyo a la toma de decisiones, de utilidad limitada
De los años 1990 al 2000
El género predominante: Bayes Arquitectura: pequeño grupo de servidores La teoría dominante es la teoría de la probabilidad. Clasificación: comparación o contraste extensible, lo cual es suficiente para muchas tareas
A principios y mediados de los 2010s
Las principales corrientes son: el sindicalismo Arquitectura: granjas de servidores Las teorías dominantes: la neurociencia y la probabilidad Identificación: reconocimiento de imágenes y voces con mayor precisión, traducción, análisis de emociones, etc.
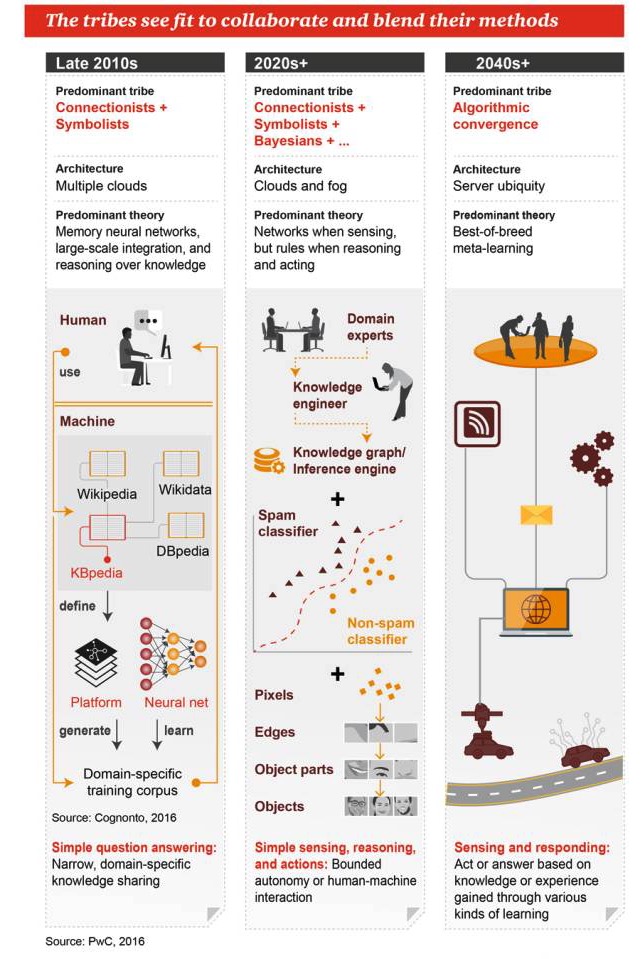
Estas corrientes esperan trabajar juntas y fusionar sus métodos.
A finales de la década de 2010
El género dominante: el sindicalismo y el simbolismo Arquitectura: muchas nubes Teorías dominantes: redes neuronales de la memoria, integración masiva, razonamiento basado en el conocimiento Preguntas y respuestas sencillas: compartir conocimiento de ámbito limitado y específico
Años 2020+
Los principales géneros: sindicalismo + simbolismo + Bayesianismo + … Arquitectura: computación en la nube y la computación en la niebla Teoría dominante: cuando hay redes de percepción, hay reglas para razonar y trabajar Sencilla percepción, razonamiento y acción: una automatización limitada o una interacción entre humanos y máquinas
2040 y más
Los géneros dominantes: la fusión de los algoritmos Arquitectura: servidores ubicuos Teoría dominante: el aprendizaje meta de la mejor combinación Percepción y respuesta: tomar medidas o dar respuestas basadas en el conocimiento o la experiencia adquirida a través de múltiples formas de aprendizaje
- #### En tercer lugar, los algoritmos de aprendizaje automático.

¿Qué algoritmo de aprendizaje automático deberías usar? Esto depende en gran medida de la naturaleza y cantidad de datos disponibles y de tus objetivos de entrenamiento en cada caso de uso específico. No utilices los algoritmos más complejos, a menos que el resultado valga la pena el gasto y los recursos costosos.
Árbol de decisión: En el proceso de respuesta gradual, el análisis típico de árboles de decisión utiliza variables estratificadas o nodos de decisión, por ejemplo, para clasificar a un usuario dado como confiable o no confiable.
Ventajas: Habilidad para evaluar una serie de características, cualidades y características diferentes de personas, lugares y cosas Ejemplos de escenarios: evaluaciones de crédito basadas en reglas, pronósticos de resultados de carreras
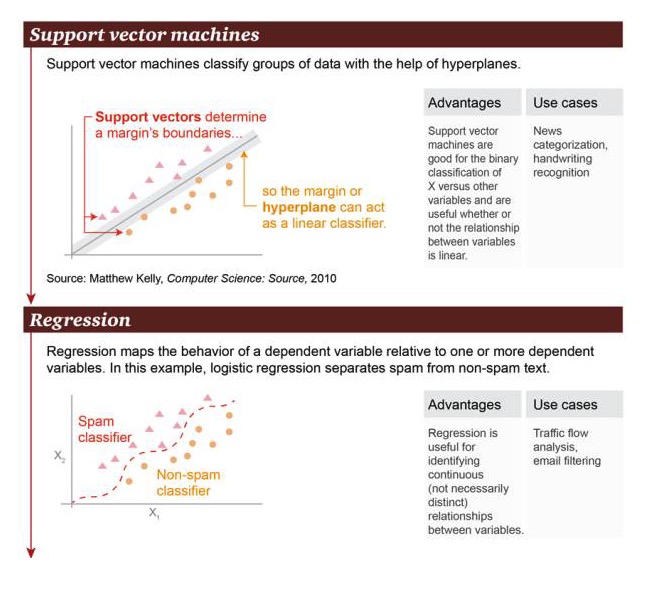
Máquina de vectores de soporte: basada en el hiperplano, la máquina de vectores de soporte puede clasificar grupos de datos.
Ventajas: La máquina de soporte vectorial es buena para realizar operaciones de clasificación binaria entre la variable X y otras variables, independientemente de si su relación es lineal o no Ejemplos de escenarios: clasificación de noticias, reconocimiento de escritura a mano.
Regresión: La regresión puede trazar la relación de estado entre una variable causal y una o más variables causal. En este ejemplo, se distingue entre correo basura y correo no basura.
Ventajas: La regresión puede usarse para identificar una relación continua entre variables, incluso si esta relación no es muy obvia Ejemplos de escenarios: análisis de tráfico en la calle, filtración de correo
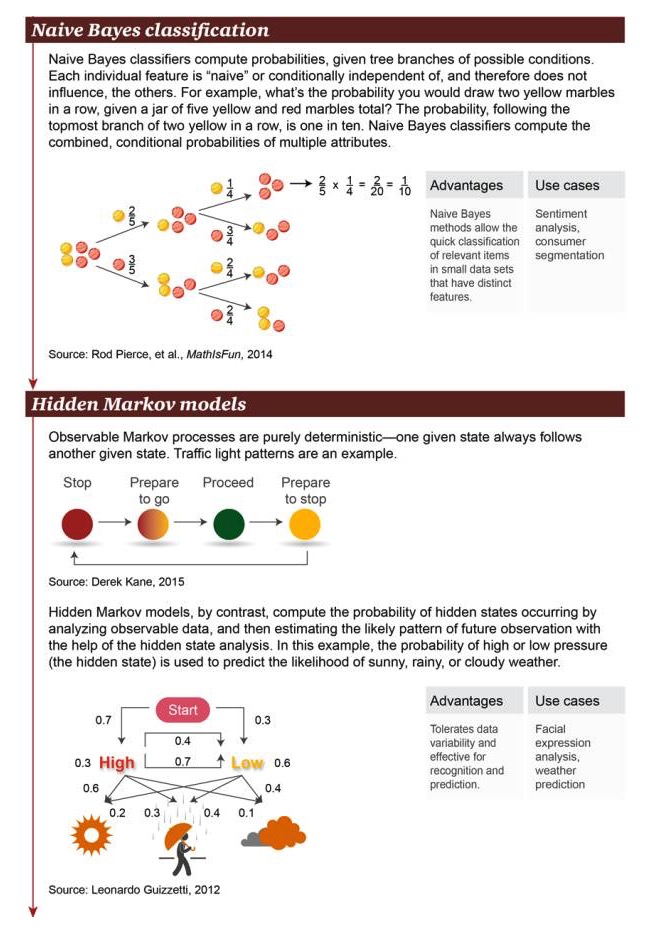
Clasificación naive de Bayes: la clasificación naive de Bayes se utiliza para calcular la probabilidad de ramificación de posibles condiciones. Cada característica independiente es “naive” o independiente de la condición, por lo que no afecta a otros objetos. Por ejemplo, ¿cuál es la probabilidad de obtener dos bolas amarillas consecutivas en un cuadro con un total de 5 bolas amarillas y rojas?
Ventajas: El método simplista de Bayes permite clasificar rápidamente los objetos relevantes con características notables en pequeños conjuntos de datos Ejemplos de escenarios: análisis de sentimientos, clasificación de consumidores
El modelo de Hidden Markov: muestra que el proceso de Markov es una certeza absoluta de que un estado dado suele estar acompañado de otro estado. Un semáforo es un ejemplo. Por el contrario, el modelo de Markov calcula la ocurrencia de estados ocultos mediante el análisis de datos visibles.
Ventajas: Permite variabilidad de los datos, aplicabilidad para operaciones de reconocimiento y predicción Ejemplos de escenarios: análisis de expresiones faciales, pronóstico meteorológico
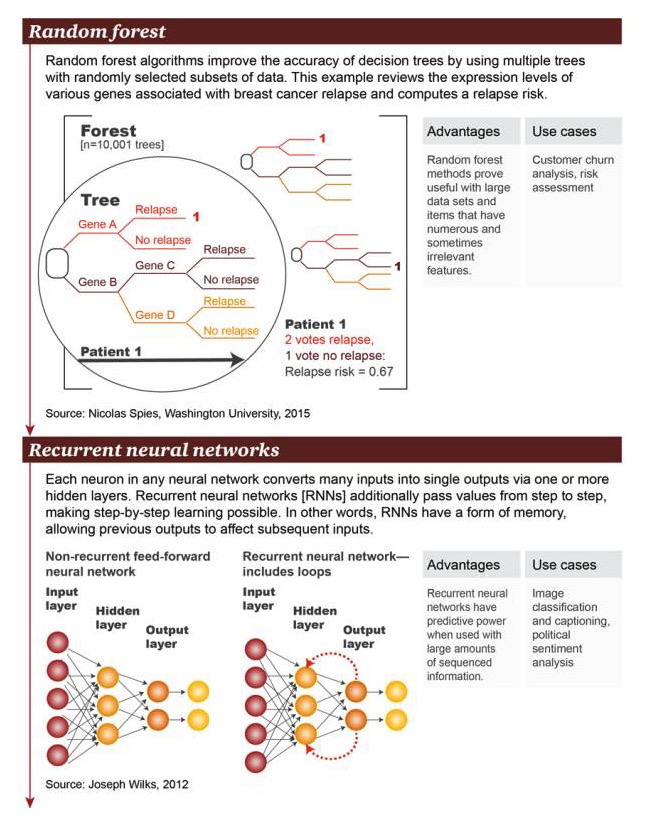
El algoritmo de bosque aleatorio mejora la precisión del árbol de decisión mediante el uso de árboles con varios subconjuntos de datos seleccionados al azar. Este ejemplo examina una gran cantidad de genes asociados con la reaparición de cáncer de mama a nivel de expresión genética y calcula el riesgo de reaparición.
Ventajas: El método de bosques aleatorios ha demostrado ser útil para grandes conjuntos de datos y la existencia de una gran cantidad de elementos con características a veces irrelevantes Ejemplos de escenarios: análisis de pérdidas de usuarios, evaluación de riesgos
Red neuronal recurrente: en una red neuronal arbitraria, cada neurona convierte muchas entradas en una sola salida a través de una o más capas ocultas. La red neuronal recurrente transmite valores más allá, por capas, lo que hace posible el aprendizaje por capas. En otras palabras, la RNN tiene algún tipo de memoria que permite que las entradas anteriores afecten a las entradas posteriores.
Ventajas: Las redes neuronales circulares tienen una capacidad de predicción cuando hay una gran cantidad de información ordenada Ejemplos de escenarios: clasificación de imágenes con subtítulos, análisis de sentimientos políticos

La memoria a corto plazo larga (LSTM) y la unidad recurrente de control de puerta (GRU) tienen memoria a largo plazo y a corto plazo. En otras palabras, estas RNN recientes tienen una mejor capacidad de control de la memoria, lo que permite conservar valores anteriores o restablecerlos cuando es necesario para procesar una serie de pasos, lo que evita la degradación final de los valores transmitidos gradualmente. Con las redes GRU podemos usar una estructura de memoria o módulo llamado “puerta” para controlar la puerta de memoria, que puede ser transferida o restablecida cuando sea apropiado.
Ventajas: La memoria a largo plazo y las redes neuronales de células circulares de control de puerta tienen las mismas ventajas que otras redes neuronales circulares, pero se utilizan más a menudo porque tienen una mejor capacidad de memoria. Ejemplos de escenarios: procesamiento y traducción de lenguaje natural
Convolutional neural network: La convulsión es la fusión de los pesos de las capas posteriores, que se pueden usar para marcar las capas de salida.
Ventajas: Las redes neuronales envueltas son muy útiles cuando hay conjuntos de datos muy grandes, una gran cantidad de características y tareas de clasificación complejas. Ejemplos de escenarios: reconocimiento de imágenes, traducción de texto a voz, detección de drogas.
- #### Enlace al artículo original:
http://usblogs.pwc.com/emerging-technology/a-look-at-machine-learning-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-methods-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-evolution-infographic/
El sitio web de Big Data dice: