Opiniones sobre las estrategias de negociación de alta frecuencia (2)
El autor:- ¿ Por qué?, Creado: 2023-08-04 17:17:30, Actualizado: 2023-09-12 15:50:31
Opiniones sobre las estrategias de negociación de alta frecuencia (2)
Modelado del importe de negociación acumulado
En el artículo anterior, derivamos una expresión para la probabilidad de que una sola cantidad de comercio sea mayor que un cierto valor.
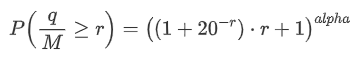
También estamos interesados en la distribución de la cantidad de operaciones durante un período de tiempo, que intuitivamente debe estar relacionada con el monto de las operaciones individuales y la frecuencia de los pedidos.
En [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
En [2]:
trades = pd.read_csv('HOOKUSDT-aggTrades-2023-01-27.csv')
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
buy_trades.index = buy_trades['date']
Combinamos los importes de las operaciones individuales a intervalos de 1 segundo para obtener el importe agregado de las operaciones, excluyendo los períodos sin actividad comercial. Luego ajustamos este importe agregado utilizando la distribución derivada del análisis del importe de las operaciones individuales mencionado anteriormente. Los resultados muestran un buen ajuste cuando se considera cada operación dentro del intervalo de 1 segundo como una sola operación, lo que resuelve efectivamente el problema. Sin embargo, cuando el intervalo de tiempo se extiende en relación con la frecuencia de operaciones, observamos un aumento en los errores.
En [3]:
df_resampled = buy_trades['quantity'].resample('1S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
En [4]:
# Cumulative distribution in 1s
depths = np.array(range(0, 3000, 5))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
Fuera[4]:
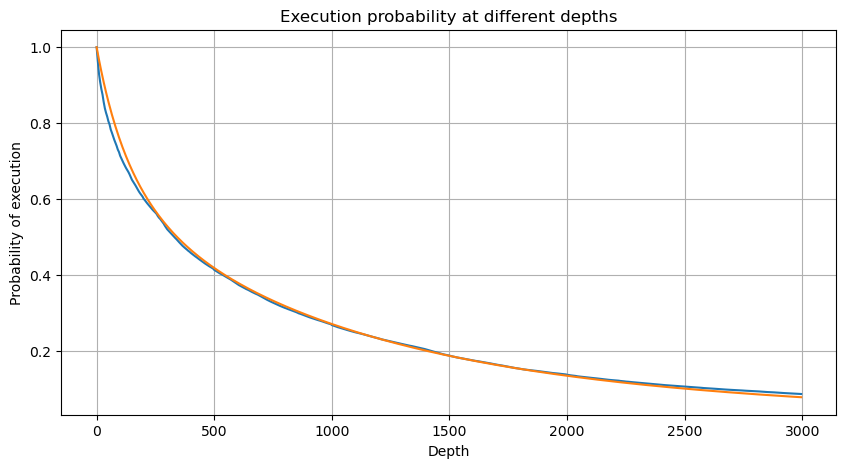
En [5]:
df_resampled = buy_trades['quantity'].resample('30S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 12000, 20))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2)
probabilities_s_2 = np.array([(depth/mean+1)**alpha for depth in depths]) # No amendment
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities,label='Probabilities (True)')
plt.plot(depths, probabilities_s, label='Probabilities (Simulation 1)')
plt.plot(depths, probabilities_s_2, label='Probabilities (Simulation 2)')
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.legend()
plt.grid(True)
Fuera[5]:
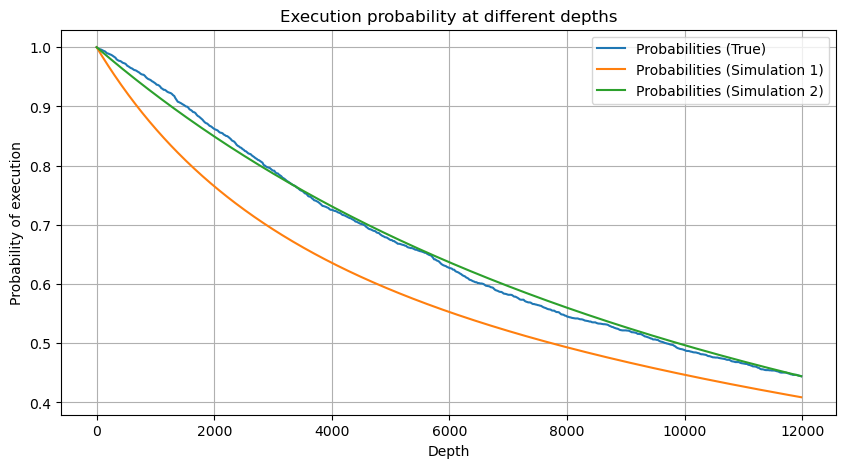
Ahora resumir una fórmula general para la distribución de la cantidad de comercio acumulado para diferentes períodos de tiempo, utilizando la distribución de la cantidad de transacción única para adaptarse, en lugar de calcular por separado cada vez.
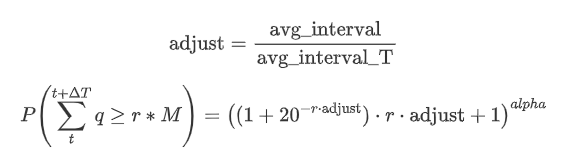
Aquí, avg_interval representa el intervalo medio de transacciones individuales, y avg_interval_T representa el intervalo medio del intervalo que debe estimarse. Puede sonar un poco confuso. Si queremos estimar el monto de negociación por 1 segundo, necesitamos calcular el intervalo medio entre eventos que contienen transacciones dentro de 1 segundo. Si la probabilidad de llegada de órdenes sigue una distribución de Poisson, debería ser directamente estimable. Sin embargo, en realidad, hay una desviación significativa, pero no lo detallaré aquí.
Tenga en cuenta que la probabilidad de que la cantidad de negociación exceda un valor específico dentro de un cierto intervalo de tiempo y la probabilidad real de negociación en esa posición en la profundidad deben ser muy diferentes. A medida que aumenta el tiempo de espera, aumenta la posibilidad de cambios en el libro de órdenes, y la negociación también conduce a cambios en la profundidad. Por lo tanto, la probabilidad de negociación en la misma posición de profundidad cambia en tiempo real a medida que se actualizan los datos.
En [6]:
df_resampled = buy_trades['quantity'].resample('2S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 6500, 10))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = buy_trades['quantity'].mean()
adjust = buy_trades['interval'].mean() / 2620
alpha = np.log(np.mean(buy_trades['quantity'] > mean))/0.7178397931503168
probabilities_s = np.array([((1+20**(-depth*adjust/mean))*depth*adjust/mean+1)**(alpha) for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
Fuera de juego[6]:
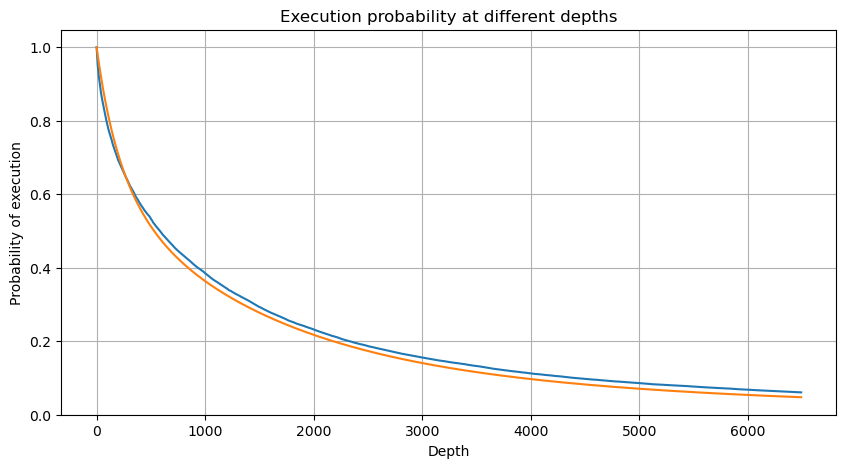
Impacto de los precios en el comercio único
Los datos comerciales son valiosos, y todavía hay muchos datos que se pueden extraer. Debemos prestar mucha atención al impacto de las órdenes en los precios, ya que esto afecta al posicionamiento de las estrategias. Del mismo modo, agregando datos basados en transact_time, calculamos la diferencia entre el último precio y el primer precio. Si solo hay un pedido, la diferencia de precio es 0.
Los resultados muestran que la proporción de operaciones que no causaron ningún impacto es tan alta como el 77%, mientras que la proporción de operaciones que causaron un movimiento de precio de 1 tick es del 16,5%, 2 ticks es del 3,7%, 3 ticks es del 1,2%, y más de 4 ticks es inferior al 1%.
También se analizó el importe de la operación que causa la diferencia de precio correspondiente, excluyendo las distorsiones causadas por un impacto excesivo. Muestra una relación lineal, con aproximadamente 1 marca de fluctuación de precios causada por cada 1000 unidades de importe. Esto también puede entenderse como un promedio de alrededor de 1000 unidades de pedidos realizados cerca de cada nivel de precio en el libro de pedidos.
En [7]:
diff_df = trades[trades['is_buyer_maker']==False].groupby('transact_time')['price'].agg(lambda x: abs(round(x.iloc[-1] - x.iloc[0],3)) if len(x) > 1 else 0)
buy_trades['diff'] = buy_trades['transact_time'].map(diff_df)
En [8]:
diff_counts = buy_trades['diff'].value_counts()
diff_counts[diff_counts>10]/diff_counts.sum()
Fuera[8]:
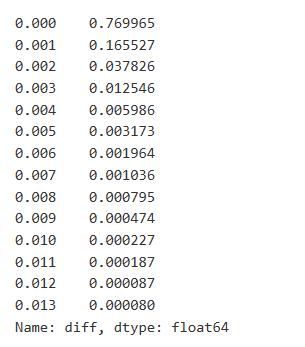
En [9]:
diff_group = buy_trades.groupby('diff').agg({
'quantity': 'mean',
'diff': 'last',
})
En el [10]:
diff_group['quantity'][diff_group['diff']>0][diff_group['diff']<0.01].plot(figsize=(10,5),grid=True);
Fuera [10]:
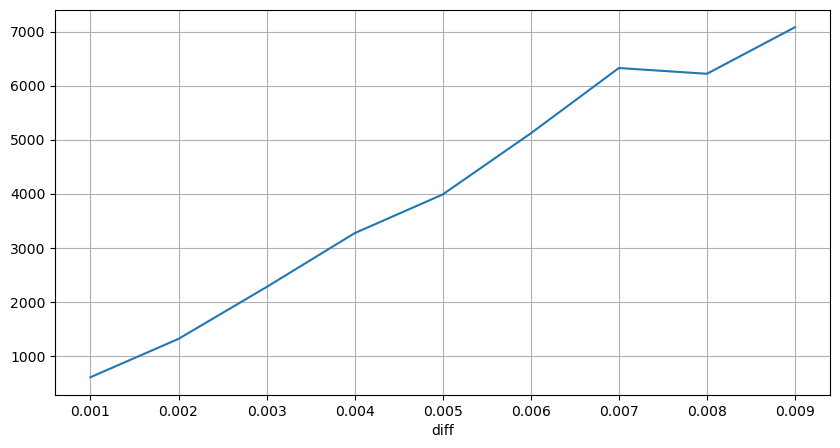
Impacto de los precios de los intervalos fijos
Analicemos el impacto del precio dentro de un intervalo de 2 segundos. La diferencia aquí es que puede haber valores negativos. Sin embargo, dado que solo estamos considerando órdenes de compra, el impacto en la posición simétrica sería un tick más alto. Continuando observando la relación entre el monto del comercio y el impacto, solo consideramos resultados mayores de 0.
En [11]:
df_resampled = buy_trades.resample('2S').agg({
'price': ['first', 'last', 'count'],
'quantity': 'sum'
})
df_resampled['price_diff'] = round(df_resampled[('price', 'last')] - df_resampled[('price', 'first')],3)
df_resampled['price_diff'] = df_resampled['price_diff'].fillna(0)
result_df_raw = pd.DataFrame({
'price_diff': df_resampled['price_diff'],
'quantity_sum': df_resampled[('quantity', 'sum')],
'data_count': df_resampled[('price', 'count')]
})
result_df = result_df_raw[result_df_raw['price_diff'] != 0]
En [12]:
result_df['price_diff'][abs(result_df['price_diff'])<0.016].value_counts().sort_index().plot.bar(figsize=(10,5));
Fuera [12]:
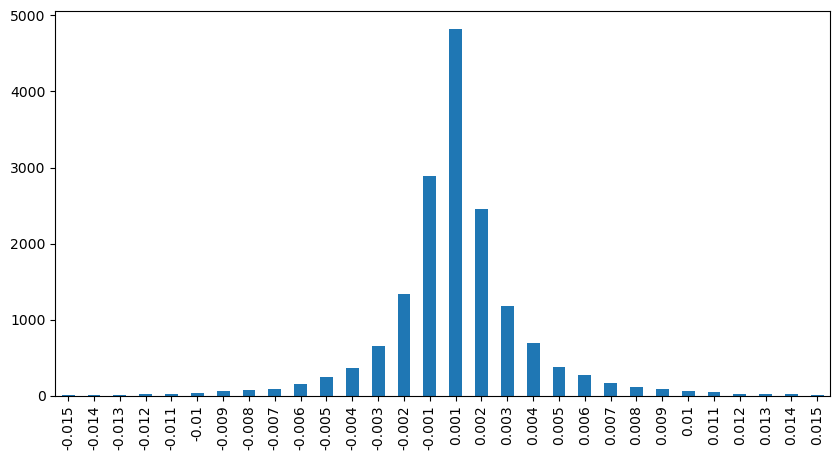
En [23]:
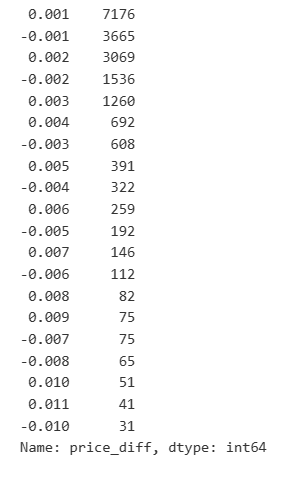
result_df['price_diff'].value_counts()[result_df['price_diff'].value_counts()>30]
Fuera[23]:
En [14]:
diff_group = result_df.groupby('price_diff').agg({ 'quantity_sum': 'mean'})
En [15]:
diff_group[(diff_group.index>0) & (diff_group.index<0.015)].plot(figsize=(10,5),grid=True);
Fuera [1]:
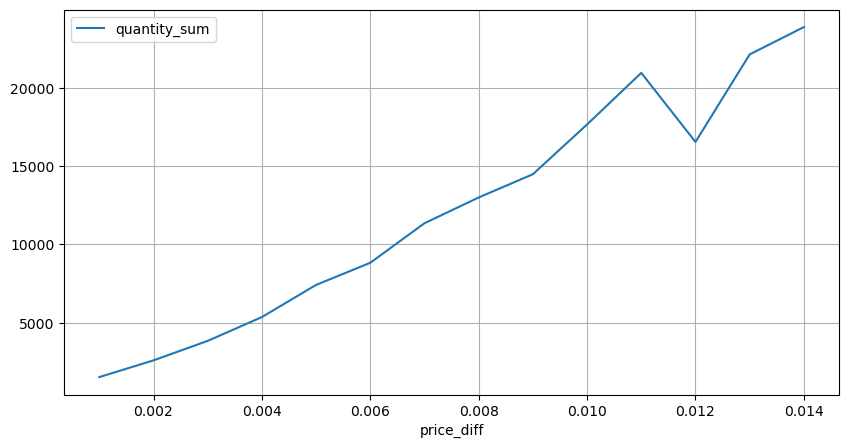
Impacto del importe del comercio sobre los precios
Anteriormente, determinamos el importe de la operación requerida para un cambio de tick, pero no era preciso, ya que se basaba en la suposición de que el impacto ya se había producido.
En este análisis, los datos se muestran cada 1 segundo, con cada paso que representa 100 unidades de cantidad.
- Cuando el importe de la orden de compra es inferior a 500, el cambio de precio esperado es una disminución, que es lo esperado ya que también hay órdenes de venta que afectan al precio.
- En cantidades de comercio más bajas, existe una relación lineal, lo que significa que cuanto mayor sea la cantidad de comercio, mayor será el aumento del precio.
- A medida que aumenta el monto de la orden de compra, el cambio de precio se vuelve más significativo. Esto a menudo indica un avance de precios, que luego puede regredir. Además, el muestreo de intervalos fijos se suma a la inestabilidad de los datos.
- Es importante prestar atención a la parte superior de la gráfica de dispersión, que corresponde al aumento del precio con el importe de la operación.
- Para este par comercial específico, proporcionamos una versión aproximada de la relación entre el monto de la operación y el cambio de precio.
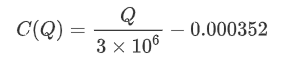
Donde
En [16]:
df_resampled = buy_trades.resample('1S').agg({
'price': ['first', 'last', 'count'],
'quantity': 'sum'
})
df_resampled['price_diff'] = round(df_resampled[('price', 'last')] - df_resampled[('price', 'first')],3)
df_resampled['price_diff'] = df_resampled['price_diff'].fillna(0)
result_df_raw = pd.DataFrame({
'price_diff': df_resampled['price_diff'],
'quantity_sum': df_resampled[('quantity', 'sum')],
'data_count': df_resampled[('price', 'count')]
})
result_df = result_df_raw[result_df_raw['price_diff'] != 0]
En [24]:
df = result_df.copy()
bins = np.arange(0, 30000, 100) #
labels = [f'{i}-{i+100-1}' for i in bins[:-1]]
df.loc[:, 'quantity_group'] = pd.cut(df['quantity_sum'], bins=bins, labels=labels)
grouped = df.groupby('quantity_group')['price_diff'].mean()
En el [25]:
grouped_df = pd.DataFrame(grouped).reset_index()
grouped_df['quantity_group_center'] = grouped_df['quantity_group'].apply(lambda x: (float(x.split('-')[0]) + float(x.split('-')[1])) / 2)
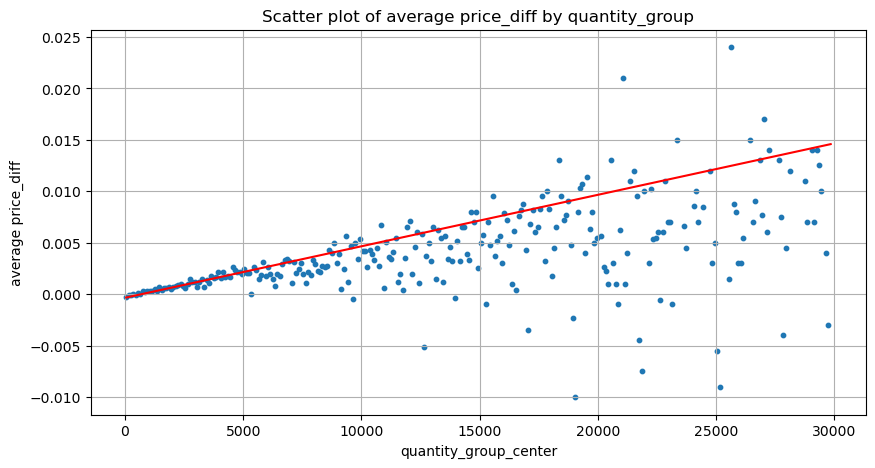
plt.figure(figsize=(10,5))
plt.scatter(grouped_df['quantity_group_center'], grouped_df['price_diff'],s=10)
plt.plot(grouped_df['quantity_group_center'], np.array(grouped_df['quantity_group_center'].values)/2e6-0.000352,color='red')
plt.xlabel('quantity_group_center')
plt.ylabel('average price_diff')
plt.title('Scatter plot of average price_diff by quantity_group')
plt.grid(True)
Fuera de juego[25]:
En [19]:
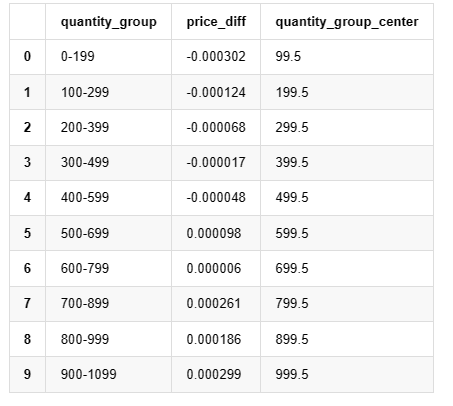
grouped_df.head(10)
Fuera [1]: No, no, no, no, no, no, no, no, no, no, no, no, no.
Posicionamiento preliminar de pedidos óptimos
Con el modelado del importe de la operación y el modelo aproximado del impacto del precio correspondiente al importe de la operación, parece posible calcular la colocación óptima de la orden.
- Supongamos que el precio regresa a su valor original después del impacto (lo que es muy poco probable y requeriría un análisis adicional del cambio de precio después del impacto).
- Supongamos que la distribución del volumen de operaciones y la frecuencia de las órdenes durante este período siguen un patrón preestablecido (lo cual también es inexacto, ya que estamos estimando sobre la base de datos de un día y las operaciones presentan fenómenos claros de agrupación).
- Supongamos que solo se produce una orden de venta durante el tiempo simulado y luego se cierra.
- Supongamos que después de la ejecución de la orden, hay otras órdenes de compra que continúan empujando hacia arriba el precio, especialmente cuando la cantidad es muy baja.
Comencemos escribiendo un rendimiento esperado simple, que es la probabilidad de que las órdenes de compra acumuladas excedan Q dentro de 1 segundo, multiplicado por la tasa de rendimiento esperada (es decir, el impacto del precio).
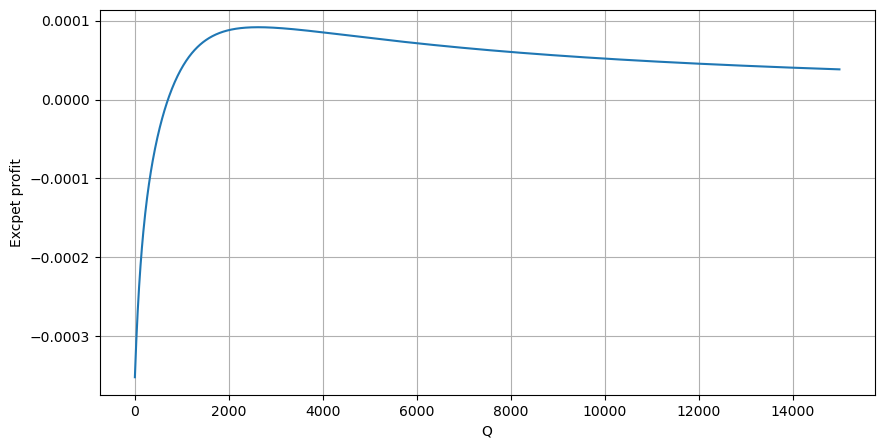
Según el gráfico, el rendimiento máximo esperado es de aproximadamente 2500, que es aproximadamente 2,5 veces el monto promedio de la operación. Esto sugiere que la orden de venta debe colocarse en una posición de precio de 2500. Es importante enfatizar que el eje horizontal representa el monto de la operación dentro de 1 segundo y no debe ser equiparado con la posición de profundidad. Además, este análisis se basa en datos de operaciones y carece de datos importantes de profundidad.
Resumen de las actividades
Hemos descubierto que la distribución de la cantidad de comercio en diferentes intervalos de tiempo es una escalada simple de la distribución de cantidades individuales de comercio. También hemos desarrollado un modelo de retorno esperado simple basado en el impacto del precio y la probabilidad de comercio. Los resultados de este modelo se alinean con nuestras expectativas, mostrando que si la cantidad de orden de venta es baja, indica una disminución del precio, y se necesita una cierta cantidad para el potencial de ganancia. La probabilidad disminuye a medida que aumenta la cantidad de comercio, con un tamaño óptimo en el medio, lo que representa la estrategia óptima de colocación de pedidos. Sin embargo, este modelo sigue siendo demasiado simplista. En el próximo artículo, profundizaré más en este tema.
En [20]:
# Cumulative distribution in 1s
df_resampled = buy_trades['quantity'].resample('1S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 15000, 10))
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
profit_s = np.array([depth/2e6-0.000352 for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities_s*profit_s)
plt.xlabel('Q')
plt.ylabel('Excpet profit')
plt.grid(True)
Fuera [1]:
- Hacer una cobertura delta con una curva de sonrisas para opciones de Bitcoin
- Opiniones sobre las estrategias de negociación de alta frecuencia (5)
- Opiniones sobre las estrategias de negociación de alta frecuencia (4)
- Pensamiento sobre estrategias de trading de alta frecuencia (5)
- Pensamiento sobre estrategias de trading de alta frecuencia (4)
- Opiniones sobre las estrategias de negociación de alta frecuencia (3)
- Pensamiento sobre estrategias de trading de alta frecuencia (3)
- Pensamiento sobre estrategias de trading de alta frecuencia (2)
- Opiniones sobre las estrategias de negociación de alta frecuencia (1)
- Pensamiento sobre estrategias de trading de alta frecuencia (1)
- Documento de descripción de la configuración de Futu Securities
- FMZ Quant Uniswap V3 Guía de operaciones relacionadas con la liquidez del fondo de cambio (Parte 1)
- FMZ Uniswap V3 Cuantificación de la movilidad de las piscinas de intercambio (I)