

Recientemente, el término "destilación" se ha utilizado cada vez con más frecuencia. En el campo de la IA, generalmente significa extraer habilidades complejas en estructuras más compactas y reutilizables; y trasladado a la investigación de estrategias, esta idea también es válida. Dicho de manera más directa, se trata de organizar conocimientos que originalmente estaban dispersos, vagos y dependientes de la experiencia subjetiva en un sistema que pueda calcularse, verificarse y también corregirse continuamente.
El proyecto crypto-kol-quant se ha vuelto muy popular recientemente. Lo realmente interesante no es la cantidad de KOL que captura, ni que use LLM, sino que intenta hacer algo poco común en la investigación cuantitativa: destilar la experiencia de los traders en un conjunto de factores de habilidad computables y luego agregarlos aún más en una señal de consenso. Este problema en sí mismo merece una seria consideración. Porque si un grupo de traders activos a largo plazo y con estilos consistentes han formado sus propios marcos cognitivos en el mercado, entonces estos marcos, en teoría, no deberían existir solo en tweets, gráficos y fragmentos de palabras; también deberían tener la oportunidad de ser extraídos, organizados e integrados en una cadena de estrategias ejecutables.
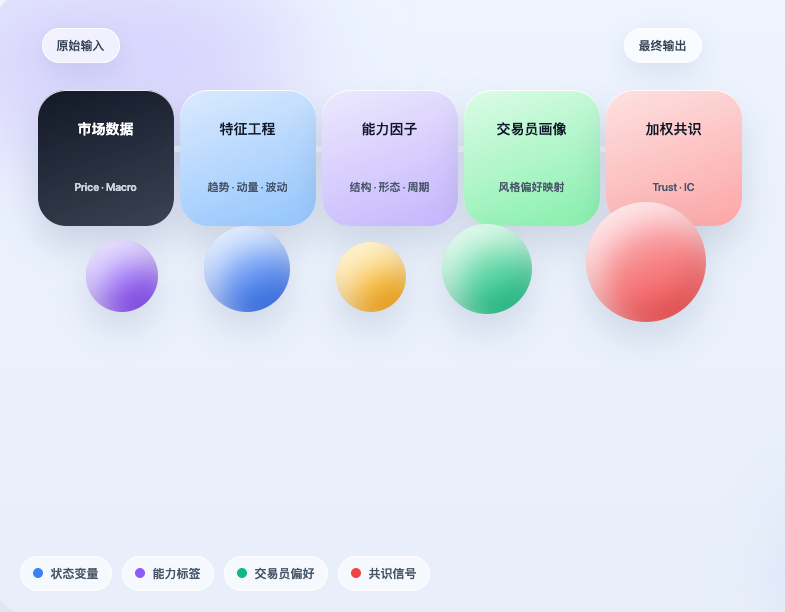
Basándonos en esta idea, hemos implementado una versión preliminar en el entorno de cuantificación del inventor. El enfoque no es simplemente "trasladar" el proyecto, sino realmente conectar su lógica central: primero obtener datos del mercado, luego traducir el mercado a un estado estructurado; luego, según estos estados, determinar qué habilidades comerciales se están activando; luego mapear estas habilidades de vuelta al perfil del trader; y finalmente, agregar los juicios individuales de diferentes traders en una señal de consenso ponderada. Claramente, aún no es un sistema de trading maduro, pero al menos ha completado algo importante: demostrar que la experiencia de los traders puede comprimirse, estructurarse y realmente ingresar al proceso de juicio de la estrategia.
El objeto de la destilación no son las opiniones, sino la capacidad de trading
Muchas personas, al encontrarse por primera vez con este tipo de proyectos, tienden a interpretarlo como una "estrategia de sentimiento de KOL". Pero esto no es muy preciso. Lo que realmente hace el proyecto original no es simplemente juzgar quién está más optimista hoy, ni contar quién dijo "largo" o "corto", sino ir un paso más allá y preguntarse: ¿cómo entiende realmente este trader el mercado? ¿Bajo qué estructura se inclina por lo alcista? ¿Se enfoca más en tendencia, posición, patrón, volatilidad o entorno macro? ¿Se pueden organizar estas formas de juicio en un conjunto de etiquetas de habilidad estables?
Una vez que se plantea la pregunta de esta manera, el centro de gravedad de la estrategia cambia. El sistema ya no se preocupa por una frase en particular, sino por la metodología detrás de esa frase. En otras palabras, el verdadero objeto de destilación de esta estrategia no es el texto, sino el conocimiento comercial en sí mismo. Intenta traducir la experiencia subjetiva que originalmente dependía de la comprensión humana en habilidades regladas que el programa puede identificar e invocar. Esta es también su mayor diferencia con los modelos de sentimiento comunes: no se trata de juzgar qué tan caliente está el sentimiento del mercado, sino de reconstruir cómo reaccionan los diferentes marcos comerciales en el mercado actual.
Primer paso: traducir el mercado en variables de estado
Para que la destilación realmente aterrice, el primer paso no es la predicción, sino la ingeniería de características. La razón es simple: el lenguaje del trader está hecho para los humanos, no para los programas. Por ejemplo, la frase "el precio retrocede hacia la media móvil clave, es un buen punto de reingreso" es fácil de entender para un trader, pero para un programa, primero debe desglosarse: ¿qué es la media móvil clave? ¿Es de 50 o 200 días? ¿El precio actual está cerca de esa media? ¿La tendencia se ha roto? ¿Hay señales de absorción?
Por lo tanto, lo primero que debe hacer el sistema no es dar una conclusión de largo o corto, sino convertir los datos de mercado sin procesar en un conjunto de estados estructurados. La capa más básica aquí es construir características de tendencia e impulso a partir de los precios. Variables como medias móviles simples, medias móviles exponenciales, RSI, MACD, etc., no son para acumular indicadores, sino para responder una pregunta simple: ¿en qué estado se encuentra aproximadamente el mercado en este momento?

El código clave es el siguiente:
python
# Usar medias móviles de diferentes períodos para describir la posición de la tendencia del precio
f['ma20'] = _sma(c,20)
f['ma50'] = _sma(c,50)
f['ma100'] = _sma(c,100)
f['ma200'] = _sma(c,200)
# Las medias móviles exponenciales son más sensibles a los cambios de precio recientes
f['ema20'] = _ema(c,20)
f['ema50'] = _ema(c,50)
# RSI se usa para describir si el mercado está en sobrecompra o sobreventa, o si el impulso está decayendo
f['rsi14'] = _rsi(c,14)
# MACD y su línea de señal, histograma, para observar cambios de tendencia e impulso
ml, ms, mh = _macd(c)
f['macd'] = ml
f['macd_sig'] = ms
f['macd_hist'] = mh
Lo que hace este código no es complicado. Las medias móviles ayudan al sistema a juzgar la posición del precio actual en relación con la tendencia a largo plazo, mientras que RSI y MACD se utilizan para describir si el impulso se está fortaleciendo o debilitando. Todavía no entra en el juicio de trading, solo está estableciendo una capa de "descripción del estado del mercado".
A continuación, el sistema también debe agregar la volatilidad y la relación de posición, porque muchos juicios de trading no solo dependen de la tendencia, sino también de "si ahora es un período de contracción de volatilidad" o "si el precio está cerca de un máximo o mínimo del rango".
El código correspondiente es:
python
# El rendimiento logarítmico es la base para calcular la volatilidad
logr = np.log(c / c.shift(1))
# Volatilidad anualizada de los últimos 30 días, para medir el nivel de volatilidad actual del mercado
f['rv30'] = logr.rolling(30, min_periods=10).std() * np.sqrt(365)
# Máximos y mínimos de los últimos 20 y 50 días, para juzgar la posición del precio
f['high_20d'] = h.rolling(20, min_periods=1).max()
f['low_20d'] = l.rolling(20, min_periods=1).min()
f['high_50d'] = h.rolling(50, min_periods=1).max()
f['low_50d'] = l.rolling(50, min_periods=1).min()
Aquí rv30 representa el nivel de volatilidad anualizada de los últimos 30 días, mientras que los máximos y mínimos del rango ayudan al sistema a juzgar dónde se encuentra el precio actual dentro de la estructura de precios reciente. Además, el fondo macro también se incluye en el espacio de estado. Porque hay un tipo de trader que no solo mira el precio de la criptomoneda, sino que también observa simultáneamente el índice del dólar estadounidense, el apetito por el riesgo del mercado de valores de EE. UU. y el entorno de tasas de interés. La forma correspondiente de manejo en el código es primero alinear estas variables por día y luego convertirlas en estados legibles:
python
# DXY como variable de fondo de fortaleza del dólar
if 'DXY' in macro:
dxy = _align(macro['DXY'])
f['dxy_ret_20d'] = dxy.pct_change(20)
f['dxy_trend_down'] = (dxy.pct_change(20) < -0.01).astype(int)
# SPX como variable de fondo de apetito por el riesgo
if 'SPX' in macro:
spx = _align(macro['SPX'])
f['spx_ret_20d'] = spx.pct_change(20)
f['spx_trend_up'] = (spx.pct_change(20) > 0).astype(int)
El significado de este paso se puede resumir en una frase: primero, traducir "cómo está el mercado ahora" a un estado estructurado que la máquina pueda leer continuamente. Sin esta capa, la destilación posterior sería imposible.
Segundo paso: escribir la experiencia subjetiva como factores de habilidad
Solo las características no son suficientes, porque las características solo describen el mercado, no expresan directamente "qué significa este estado". El siguiente paso debe ser escribir la experiencia del trader en reglas, es decir, según estas variables de estado actuales, determinar qué habilidades comerciales se están activando.
Este paso es la parte más fuerte del sabor de destilación de toda la estrategia. Porque aquí ya no se dice abstractamente que "cierto marco es importante", sino que realmente se escribe en condiciones de programa. Los factores de habilidad incluidos en la implementación actual cubren varios niveles: patrones, estructura, indicadores, ciclo y macro. Por ejemplo, algunas habilidades provienen del reconocimiento de patrones, como bandera alcista, bandera bajista, doble techo/doble suelo, patrón de cabeza y hombros, triángulo; algunas provienen del análisis estructural, como marcos Wyckoff, SMC, ICT; algunas provienen de los propios indicadores, como divergencia RSI, cruce de medias (golden cross/death cross), compresión de Bollinger y ruptura; y otras provienen del ciclo y el entorno macro, como el ciclo de halving, cambio entre mercado de tendencia y mercado lateral, caída del DXY, aumento del apetito por el riesgo, etc.
Un ejemplo muy típico es la "continuación de retroceso en tendencia". Muchos traders tienen experiencias similares: si la tendencia principal sigue siendo alcista, el precio retrocede hacia una media móvil clave, y la vela actual muestra absorción, entonces a menudo significa continuación de la tendencia. La expresión del programa es muy directa:
python
# Determinar si el precio actual está cerca de la media móvil de 50 días
near_ma50 = abs(close - ma50_v) / close < 0.02 if close > 0 else False
# Si la media móvil de 50 días todavía está por encima de la media de 200 días, y después del retroceso hacia la media aparece una vela verde de absorción
# entonces se registra como una señal de habilidad de continuación de tendencia
s['cap_014_trend_pullback_continuation'] = 0.6 if (ma50_gt and near_ma50 and is_green) else 0.0
Aquí no hay nada misterioso, simplemente se desglosa una frase de lenguaje humano en varias condiciones que la máquina puede juzgar una por una. Otro ejemplo es la "ruptura por compresión de Bollinger". Para muchos traders, una contracción prolongada de la volatilidad seguida de una expansión repentina hacia arriba o hacia abajo a menudo significa una nueva dirección. La regla correspondiente se escribe:
python
# Si el ancho de las bandas de Bollinger de la vela anterior es menor que el umbral de compresión, se considera contracción de volatilidad
squeezed = bb_w_p1 < bb_w20_p1 if bb_w20_p1 > 0 else False
# Después de la contracción, si el precio rompe la banda superior, se da una señal positiva; si rompe la banda inferior, señal negativa
s['cap_021_bollinger_squeeze_breakout'] = (
0.6 if (squeezed and close > bb_u) else
-0.6 if (squeezed and close < bb_l) else 0.0
)
El manejo de los factores macro es igual. Para un tipo de traders más orientados a lo macro, BTC no es una serie de precios completamente aislada; se ve afectada por el dólar, el mercado de valores y el entorno de tasas de interés. Por lo tanto, esta comprensión también se escribe como juicios de habilidad.
python
# La caída del DXY generalmente se considera un trasfondo positivo para BTC
s['cap_027_dxy_inverse_btc'] = 0.4 if (not _nm(dxy_r20) and dxy_r20 < -0.01) else 0.0
# El alza del S&P puede interpretarse como mejora en el apetito por riesgo
s['cap_028_spx_risk_on_off'] = 0.4 if (not _nm(spx_r20) and spx_r20 > 0.02) else 0.0
# La caída de las tasas cortas puede verse como una mejora marginal en liquidez
s['cap_029_yields_liquidity'] = 0.4 if (not _nm(y_r20) and y_r20 < -0.02) else 0.0
Lo realmente importante en esta capa no es cuántas reglas escribe, sino que logra el paso más crítico de la destilación: comprimir juicios que antes solo podían entenderse subjetivamente en condiciones calculables. Cabe señalar que la mayoría de los factores de capacidad en la versión actual son del tipo de activación por condición, no de puntuación continua. Esto significa que el sistema se enfoca más en determinar si una cierta estructura se cumple, en lugar de revalorizar constantemente cada micro fluctuación. Esto también determina que actualmente sea más adecuado para juicios diarios o de baja/mediana frecuencia, no para trading de alta frecuencia.
Tercer paso: Los factores no se suman directamente, primero se mapean al perfil del trader
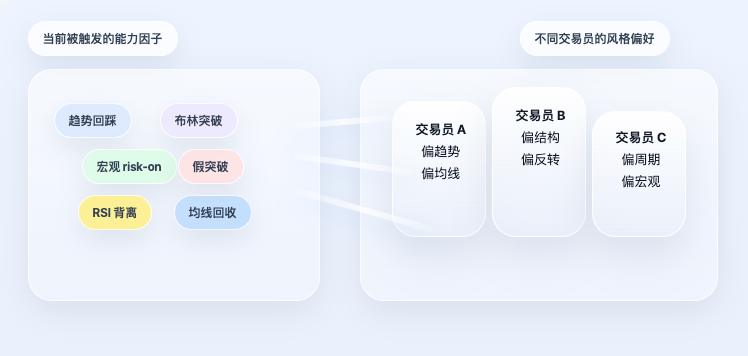
Si la estrategia se quedara solo en la capa de factores, seguiría siendo un sistema de reglas común. Lo más especial del proyecto original es que no se detuvo aquí, sino que avanzó un paso más: los factores no determinan directamente la dirección, sino que primero se mapean al perfil del trader.
Esto es fundamental. Porque en la realidad, los traders no "usan todas las capacidades por igual". Algunos se inclinan por tendencias, otros por estructuras, otros por ciclos, otros por macro. Incluso ante el mismo estado del mercado, el enfoque de cada persona es completamente diferente. Por lo tanto, el sistema no simplemente promedia todos los factores, sino que primero lee las preferencias de capacidades de cada trader, y luego calcula una señal personal para él según el estado actual de los factores.
La lógica de lectura de perfiles correspondiente es la siguiente:
python
# Lee los factores de capacidad utilizados por cada trader y sus pesos
caps = {c['id']: float(c.get('weight', 0.5))
for c in p.get('capabilities_used', [])}
profiles.append({
'handle': p.get('handle', item['name'][:-5]),
'caps': caps
})
Cada perfil esencialmente responde a una pregunta: ¿de qué factores de capacidad depende más este trader, y cuánto peso tienen esos factores en su marco? Una vez que se tiene este perfil, el sistema procede a calcular la "señal personal" de cada trader en el mercado actual:
python
for p in profiles:
sig = 0.0
wt = 0.0
# Recorre todos los factores de capacidad que le interesan a ese trader
for cap_id, w in p['caps'].items():
score = factor_scores.get(cap_id, 0.0)
# Puntuación del factor actual multiplicada por la preferencia de peso del trader sobre ese factor
sig += w * score
wt += abs(w)
# Normalizado para obtener la señal personal de ese trader en el mercado actual
trader_raw = sig / wt if wt > 0 else 0.0
Al ver esto, la esencia de este sistema ya es bastante diferente. Ya no solo se trata de "qué factores se activan", sino que se intenta reconstruir algo: si se le presentara el mercado de hoy a estos 99 traders, ¿cómo juzgaría cada uno?
Cuarto paso: De la señal personal al consenso ponderado
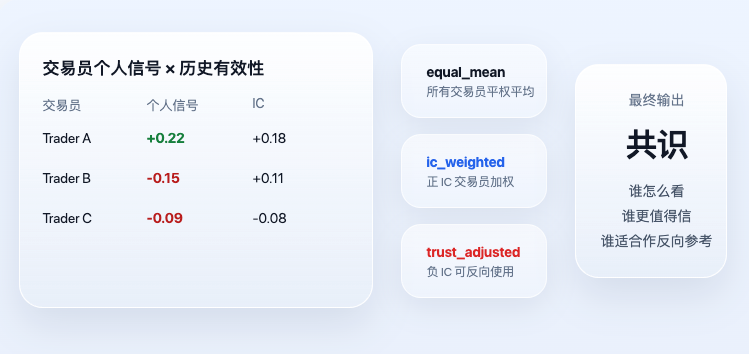
Una vez calculadas las señales personales de cada trader, el sistema entra en la verdadera capa de consenso. Aquí, el "consenso" no es una simple votación, ni mucho menos quien grita más fuerte tiene la razón, sino que se considera además la efectividad histórica.
Los dos resultados más importantes en el código actual son ic_weighted y trust_adjusted. La lógica central correspondiente es:
python
# Primero se pondera positivamente a los traders con IC positivo, obteniendo ic_weighted
pos_w = sum(max(t['ic'], 0) for t in trader_signals)
ic_wt = (
sum(t['signal'] * max(t['ic'], 0) for t in trader_signals) / pos_w
if pos_w > 0 else 0.0
)
# trust_adjusted va un paso más allá:
# IC positivo se usa en la misma dirección, IC negativo se usa en dirección inversa, y se pondera por el valor absoluto del IC
abs_w = sum(abs(t['ic']) for t in trader_signals)
trust = (
sum((t['signal'] if t['ic'] >= 0 else -t['signal']) * abs(t['ic'])
for t in trader_signals) / abs_w
if abs_w > 0 else 0.0
)
Este código expresa dos principios muy simples pero importantes. Primero, los traders históricamente más efectivos tienen mayor peso hoy. Segundo, los traders con IC histórico negativo no son descartados, sino que pueden ser utilizados como indicadores inversos. Por lo tanto, el trust_adjusted final no es simplemente "qué opina la mayoría", sino "quién opina qué, y quién es más digno de confianza".
Esta es también la razón por la que este sistema es diferente de los modelos de sentimiento comunes. No cuenta cuántas voces hay, sino que realiza una agregación cognitiva con validación histórica. Si se pudiera comprimir todo el método en una frase, sería: primero transformar el mercado en variables de estado, luego mapear las variables de estado en factores de capacidad, luego mapear los factores de capacidad en señales personales de los traders, y finalmente agregar esas señales personales en un juicio de consenso según la efectividad histórica.
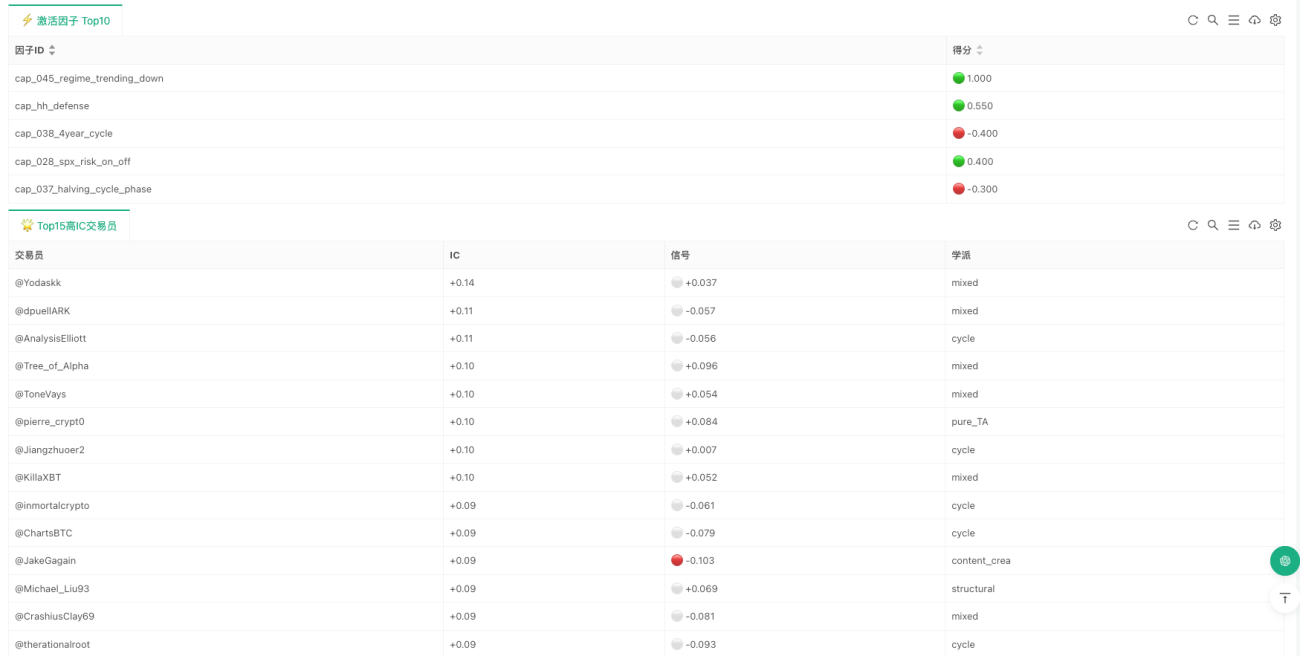
¿Qué se logró realmente con la implementación en Inventor?
Si se quedara solo como un proyecto de investigación, este sistema sería más un "analizador de consenso"; la implementación en Inventor se enfoca en conectar toda la cadena para que pueda ejecutarse de forma continua. El código más central tiene solo tres líneas:
python
# Primer paso: convertir los datos brutos de mercado y las variables macro en un estado estructurado
feat_df = build_features(records, macro if macro else None)
# Segundo paso: evaluar qué factores de capacidad se activan según las variables de estado
factor_scores = evaluate_factors(feat_df)
# Tercer paso: mapear los factores de capacidad en perfiles de traders y agregarlos en un resultado de consenso
consensus = compute_consensus(factor_scores)
Estas tres líneas representan las tres capas de abstracción más importantes de toda la estrategia. La primera capa se encarga del estado del mercado, la segunda del juicio de capacidades, y la tercera del consenso de los traders. Por supuesto, después vienen la capa de ejecución, la de gestión de riesgos y la de visualización de estados, pero desde la lógica de investigación, la parte más crítica ya está completa. Es decir, la importancia principal de esta implementación no radica en cuántos detalles operativos añade, sino en que los perfiles de capacidades del proyecto original ya no son solo archivos estáticos, los factores ya no son solo resultados de investigación, el consenso ya no es solo un número en un informe; todo ha sido integrado en un flujo de juicio continuo.
¿Por qué sigue siendo solo un prototipo?
Por supuesto, esta implementación no es el final. El código actual utiliza un marco diario de BTC, por lo que es más adecuado para juicios de consenso de baja/mediana frecuencia, no para sistemas de trading de alta frecuencia. Su núcleo sigue girando en torno a la estructura diaria, la posición cíclica, el trasfondo macro y las preferencias de capacidades de los traders. Además, los perfiles de los traders y el IC siguen siendo entradas estáticas, aún no han entrado en una fase de evolución en línea. Es decir, aunque el sistema ha completado el primer paso de la "destilación de conocimiento", aún no ha logrado completamente que "el conocimiento destilado se autocorrija".
Pero esto no impide que ya haya demostrado algo muy importante: la experiencia de los traders puede ser comprimida capa por capa, estructurada, y efectivamente incorporada en la cadena de estrategias. Su valor no radica en que ya genere rendimientos estables, sino en que ha avanzado una línea de investigación que antes se quedaba en el plano conceptual a una fase operativa. En cuanto a cómo evolucionarán estos factores de capacidad, cómo se actualizarán los pesos de los traders, cómo se corregirá continuamente el consenso en el mercado real, aún se necesita más datos de ejecución para responder.
Conclusión
Lo realmente inspirador de crypto-kol-quant no es la cantidad de conceptos populares que utiliza, sino que ha logrado avanzar un paso más en algo que es muy difícil de sistematizar: convertir la experiencia de los traders, de expresión a capacidad, de capacidad a factor, y de factor a consenso. Y la implementación en Inventor hace precisamente eso: hacer que esta cadena de destilación realmente funcione. No exagera diciendo que ya es el final, ni intenta ocultar que sigue siendo solo un prototipo temprano. Pero al menos demuestra que la experiencia de trading no tiene por qué quedarse solo en gráficos y palabras; puede ser destilada, estructurada, ejecutada, e incluso incorporada en un sistema que juzgue continuamente el mercado.
Si el quant tradicional es bueno extrayendo patrones de las series de precios, entonces la dirección que realmente vale la pena seguir para este tipo de estrategias quizás sea: extraer patrones de la cognición humana, y luego dejar que esos patrones participen en el mercado a su vez. Y eso, quizás, es lo más notable de la "destilación" en la investigación de estrategias.
Proyecto original: 锁妖塔 Skill — 炼化99个加密交易员
Agradecimiento especial al usuario "GiantBin" por las ideas y sugerencias. Si alguien tiene buenas ideas o pensamientos, son bienvenidos a compartir y discutir.
- 1