

Utilicemos el aprendizaje por refuerzo en inteligencia artificial para crear un robot de comercio de criptomonedas
En este artículo, crearemos y aplicaremos un marco de aprendizaje de refuerzo para aprender cómo crear un robot de comercio de Bitcoin. En este tutorial, utilizaremos el gimnasio de OpenAI y el robot PPO de la biblioteca stable-baselines, que es una bifurcación de la biblioteca baselines de OpenAI.
Muchas gracias a OpenAI y DeepMind por proporcionar software de código abierto a los investigadores de aprendizaje profundo durante los últimos años. Si no has visto los increíbles logros que han alcanzado con tecnologías como AlphaGo, OpenAI Five y AlphaStar, es posible que hayas estado viviendo aislado durante el último año, pero deberías echarles un vistazo.
Entrenamiento AlphaStar https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
Si bien no crearemos nada impresionante, el comercio de robots de Bitcoin aún no es una tarea fácil en el comercio diario. Sin embargo, como dijo una vez Teddy Roosevelt:
Las cosas que llegan demasiado fácilmente no tienen valor.
Por lo tanto, no sólo aprenda a comerciar por usted mismo… sino que también deje que los robots comercien por nosotros.
plan

-
Crea un entorno de gimnasio para que nuestro robot realice el aprendizaje automático.
-
Cree un entorno de visualización simple y elegante
-
Entrenar a nuestro robot para que aprenda una estrategia de trading rentable
Si aún no está familiarizado con cómo crear entornos de gimnasios desde cero, o cómo simplemente renderizar visualizaciones de estos entornos. Siéntete libre de buscar en Google un artículo como este antes de continuar. Estas dos acciones no serán difíciles incluso para los programadores más principiantes.
empezando
En este tutorial, utilizaremos el conjunto de datos de Kaggle generado por Zielak. Si desea descargar el código fuente, está disponible en mi repositorio de Github, junto con el archivo de datos .csv. Bueno, comencemos.
Primero, importemos todas las bibliotecas necesarias. Asegúrate de instalar todas las bibliotecas que te faltan usando pip.
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessing
A continuación, crearemos nuestra clase para el entorno. Necesitamos pasar un marco de datos de pandas, así como un initial_balance opcional y un lookback_window_size que dictarán cuántos pasos de tiempo pasados observará el robot en cada paso. Establecemos la comisión por operación en 0,075 %, la tasa actual en Bitmex, y establecemos el parámetro serial en falso, lo que significa que nuestro marco de datos se recorrerá en partes aleatorias de manera predeterminada.
También llamamos dropna() y reset_index() en los datos, primero para eliminar las filas con valores NaN y luego para restablecer el índice para el número de marco ya que hemos eliminado los datos.
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)
Nuestro espacio de acción se representa aquí como un conjunto de 3 opciones (comprar, vender o mantener) y otro conjunto de 10 cantidades (1/10, 2/10, 3/10, etc.). Al elegir la acción de compra, compraremos una cantidad * valor de saldo propio en BTC. Para vender, venderemos una cantidad de BTC equivalente a * self.btc_held. Por supuesto, la acción de retención ignora la cantidad y no hace nada.
Nuestro espacio de observación se define como un conjunto de flotantes continuos entre 0 y 1, con forma (10, tamaño de ventana retrospectiva + 1). + 1 se utiliza para calcular el paso de tiempo actual. Para cada paso de tiempo en la ventana, observaremos el valor OHCLV. Nuestro patrimonio neto es igual a la cantidad de BTC comprados o vendidos y la cantidad total de USD que gastamos o recibimos en esos BTC.
A continuación, debemos escribir el método de reinicio para inicializar el entorno.
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()
Aquí usamos self._reset_session y yo mismo._next_observation, aún no los hemos definido. Vamos a definirlos primero.
Sesión de negociación
Una parte importante de nuestro entorno es el concepto de sesión comercial. Si implementáramos este bot fuera del mercado, probablemente nunca lo utilizaríamos durante más de unos pocos meses. Por este motivo, limitaremos el número de fotogramas consecutivos en self.df, es decir, el número de fotogramas que nuestro robot puede ver al mismo tiempo.
En nuestro método _reset_session, primero restablecemos el current_step a 0. A continuación, estableceremos steps_left en un número aleatorio entre 1 y MAX_TRADING_SESSION, que definiremos en la parte superior del programa.
MAX_TRADING_SESSION = 100000 # ~2个月
A continuación, si queremos iterar sobre los fotogramas de forma continua, debemos configurarlo para que itere sobre todo el fotograma; de lo contrario, configuramos frame_start en un punto aleatorio en self.df y creamos un nuevo marco de datos llamado active_df que es simplemente self. de df desde frame_start hasta frame_start + steps_left.
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]
Un efecto secundario importante de iterar sobre la cantidad de marcos de datos en cortes aleatorios es que nuestro robot tendrá más datos únicos para usar durante el entrenamiento durante un tiempo prolongado. Por ejemplo, si simplemente iteráramos a través del número de marcos de datos de manera serial (es decir, en orden desde 0 hasta len(df)), entonces solo tendríamos tantos puntos de datos únicos como haya en el número de marcos de datos. Nuestro espacio de observación sólo puede adoptar un número discreto de estados en cada paso de tiempo.
Sin embargo, al iterar aleatoriamente sobre partes del conjunto de datos, podemos crear un conjunto más significativo de resultados comerciales para cada paso de tiempo en el conjunto de datos inicial, es decir, una combinación de acciones comerciales y acciones de precios vistas previamente para crear un conjunto de datos más únicos. Déjame explicarlo con un ejemplo.
En un paso de tiempo de 10 después de restablecer el entorno serial, nuestro robot siempre se ejecutará simultáneamente dentro del conjunto de datos y tendrá 3 opciones después de cada paso de tiempo: Comprar, Vender o Mantener. Para cada una de estas tres opciones, existe otra opción: 10%, 20%, ... o 100% del importe específico de ejecución. Esto significa que nuestro robot podría encontrarse con cualquiera de 103 elevado a 10, para un total de 1030 situaciones.
Ahora volvamos a nuestro entorno de corte aleatorio. En un paso de tiempo de 10, nuestro robot puede estar en cualquier paso de tiempo len(df) dentro del número de marcos de datos. Suponiendo que se realiza la misma elección después de cada paso de tiempo, esto significa que el robot puede pasar por cualquier estado único de len(df)30 en los mismos 10 pasos de tiempo.
Si bien esto puede introducir ruido considerable en grandes conjuntos de datos, creo que debería permitir que los robots aprendan más de la cantidad limitada de datos que tenemos. Seguiremos iterando a través de nuestros datos de prueba de manera serial para obtener los datos más actualizados, aparentemente en “tiempo real”, para lograr una comprensión más precisa de la efectividad del algoritmo.
A través de los ojos de un robot
A menudo es útil tener una buena descripción visual del entorno para comprender los tipos de funciones que utilizará nuestro robot. Por ejemplo, aquí hay una visualización del espacio observable renderizada usando OpenCV.

Observación del entorno de visualización de OpenCV
Cada fila de la imagen representa una fila en nuestro espacio de observación. Las primeras 4 líneas de frecuencia similar (líneas rojas) representan datos OHCL, y los puntos naranjas y amarillos justo debajo representan el volumen. La barra azul fluctuante que se muestra a continuación representa el capital del bot, mientras que las barras más claras que se muestran a continuación representan las operaciones del bot.
Si observas con atención, incluso puedes crear tu propio gráfico de velas. Debajo de la barra de volumen hay una interfaz similar al código Morse que muestra el historial de operaciones. Parece que nuestro bot debería poder aprender adecuadamente de los datos en nuestro espacio de observación, así que continuemos. Aquí definiremos el método _next_observation donde escalaremos los datos observados de 0 a 1.
- Es importante ampliar únicamente los datos que el robot ha observado hasta el momento para evitar el sesgo de anticipación.
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0)
return obs
Tomar medidas
Ahora que tenemos nuestro espacio de observación configurado, es hora de escribir nuestra función de paso y luego realizar las acciones que el robot pretende realizar. Siempre que self.steps_left == 0 para nuestra sesión comercial actual, venderemos nuestras tenencias de BTC y llamaremos a reset session(). De lo contrario, establecemos la recompensa en el capital actual o establecemos "hecho" en Verdadero si nos quedamos sin fondos.
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}
Realizar una acción comercial es tan simple como obtener el precio actual, determinar la acción que debe realizarse y la cantidad a comprar o vender. Escribamos rápidamente _take_action para que podamos probar nuestro entorno.
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += sales
Finalmente, con el mismo método, agregaremos la operación a self.trades y actualizaremos nuestro historial de capital y cuenta.
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)
Nuestro robot ahora puede lanzar un nuevo entorno, recorrerlo y realizar acciones que afecten al entorno. Es hora de verlos comerciar.
Mira cómo comercian nuestros robots
Nuestro método de renderizado podría ser tan simple como llamar a print(self.net_worth) , pero eso no sería lo suficientemente interesante. En su lugar, dibujaremos un gráfico de velas simple con una barra de volumen y un gráfico separado para nuestro capital.
Tomaremos el código en StockTradingGraph.py de mi artículo anterior y lo reelaboraremos para que se ajuste al entorno de Bitcoin. Puedes obtener el código de mi Github.
El primer cambio que vamos a realizar es cambiar self.df[ 'Fecha'] Actualización a self.df['Timestamp'] y elimine todas las llamadas a date2num ya que nuestras fechas ya están en formato de marca de tiempo Unix. A continuación, en nuestro método de renderizado, actualizaremos la etiqueta de fecha para imprimir una fecha legible por humanos en lugar de un número.
from datetime import datetime
Primero, importaremos la biblioteca datetime, luego usaremos el método utcfromtimestamp para obtener la cadena UTC de cada marca de tiempo y strftime para convertirla en una cadena con el formato Y-m-d H:M.
date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])
Por último, utilizaremos self.df['Volumen'] se cambia a self.df['Volume_(BTC)'] para que coincida con nuestro conjunto de datos y, una vez hecho esto, estamos listos para comenzar. Volviendo a nuestro BitcoinTradingEnv, ahora podemos escribir el método de render para mostrar el gráfico.
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)
¡Mirar! Ahora podemos ver a nuestro robot comerciar con Bitcoins.

Visualizando las operaciones de nuestro robot con Matplotlib
Las etiquetas fantasma verdes representan la compra de BTC, y las etiquetas fantasma rojas representan la venta. La etiqueta blanca en la esquina superior derecha es el patrimonio neto actual del robot, y la etiqueta en la esquina inferior derecha es el precio actual de Bitcoin. Sencillo y elegante. ¡Ahora es el momento de entrenar a nuestro bot y ver cuánto dinero podemos ganar!
Tiempo de entrenamiento
Una crítica que recibí en mi artículo anterior fue la falta de validación cruzada y no dividir los datos en conjuntos de entrenamiento y prueba. El propósito de esto es probar la precisión del modelo final con datos nuevos que nunca antes se habían visto. Si bien éste no es el tema central de este artículo, ciertamente es importante. Dado que trabajamos con datos de series de tiempo, no tenemos muchas opciones cuando se trata de validación cruzada.
Por ejemplo, una forma común de validación cruzada se denomina validación k-fold, en la que se dividen los datos en k grupos iguales, se separa uno de los grupos como grupo de prueba y se utiliza el resto de los datos como grupo de entrenamiento. . Sin embargo, los datos de series temporales dependen en gran medida del tiempo, lo que significa que los datos posteriores dependen en gran medida de los datos anteriores. Por lo tanto, k-fold no funcionará porque nuestro robot aprenderá de los datos futuros antes de operar, lo que constituye una ventaja injusta.
Los mismos defectos se aplican a la mayoría de las demás estrategias de validación cruzada cuando se aplican a datos de series de tiempo. Por lo tanto, solo necesitamos utilizar una parte del número completo de marcos de datos como conjunto de entrenamiento, comenzando desde el comienzo del número de marco hasta algún índice arbitrario, y utilizar el resto de los datos como conjunto de prueba.
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]
A continuación, dado que nuestro entorno solo está configurado para manejar un único marco de datos, crearemos dos entornos, uno para los datos de entrenamiento y otro para los datos de prueba.
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])
Ahora, entrenar nuestro modelo es tan simple como crear un robot con nuestro entorno y llamar a model.learn.
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)
Aquí usamos tensorboard para que podamos visualizar fácilmente nuestro gráfico de tensorflow y ver algunas métricas cuantitativas sobre nuestro robot. Por ejemplo, aquí hay un gráfico de recompensas con descuento para muchos robots durante 200.000 pasos de tiempo:
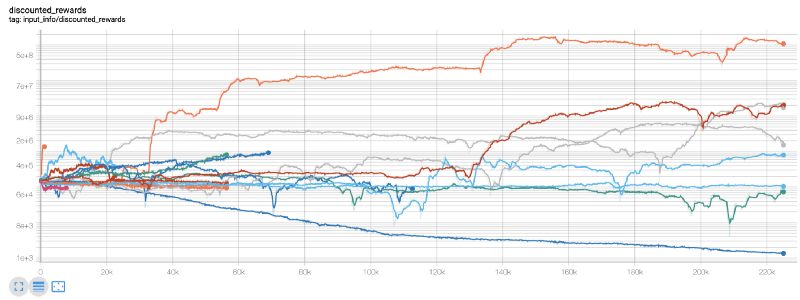
¡Vaya, parece que nuestro bot es bastante rentable! ¡Nuestro mejor robot incluso fue capaz de lograr un equilibrio 1000 veces mejor en el transcurso de 200.000 pasos, y el resto tuvo una mejora media de al menos 30 veces!
Fue en ese momento que me di cuenta de que había un error en el entorno... Después de solucionarlo, aquí está el nuevo mapa de recompensas:
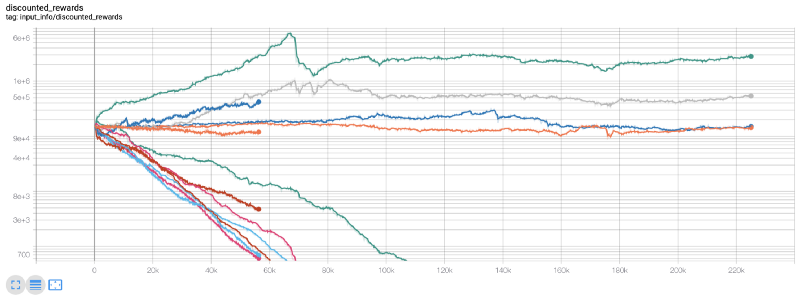
Como podéis ver, algunos de nuestros robots hicieron un gran trabajo, y el resto se declararon en quiebra por su propia cuenta. Sin embargo, un bot de buen rendimiento puede lograr hasta 10 o incluso 60 veces el saldo inicial. Debo admitir que todos los bots rentables se entrenan y prueban sin comisiones, por lo que no es realista que nuestros bots ganen dinero real. Pero al menos encontramos la dirección!
Probemos nuestros bots en un entorno de prueba (con datos nuevos que nunca habían visto antes) y veamos cómo funcionan.
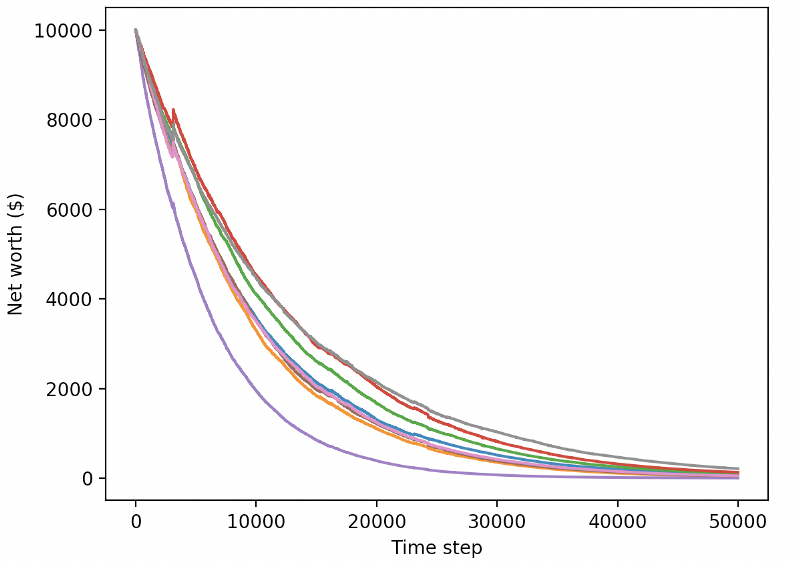
Nuestro robot entrenado se declara en quiebra al intercambiar nuevos datos de prueba
Está claro que todavía tenemos mucho trabajo por hacer. Con solo cambiar el modelo para utilizar una A2C de referencia estable, en lugar del robot PPO2 actual, podemos mejorar significativamente nuestro desempeño en este conjunto de datos. Finalmente, siguiendo la sugerencia de Sean O'Gorman, podemos actualizar ligeramente nuestra función de recompensa para que agreguemos recompensas al patrimonio neto en lugar de simplemente alcanzar un patrimonio neto alto y dejarlo allí.
reward = self.net_worth - prev_net_worth
Estos dos cambios por sí solos mejoran significativamente el rendimiento en el conjunto de datos de prueba y, como puede ver a continuación, finalmente podemos lograr rentabilidad en datos nuevos que no estaban en el conjunto de entrenamiento.
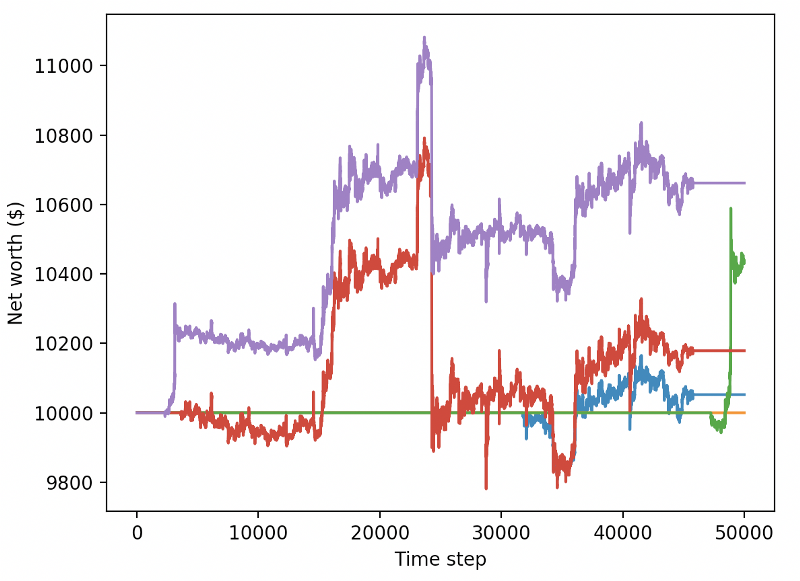
Pero podemos hacerlo mejor. Para poder mejorar estos resultados, necesitamos optimizar nuestros hiperparámetros y entrenar a nuestro bot durante más tiempo. ¡Es hora de poner tu GPU a trabajar y a funcionar a pleno rendimiento!
Esta publicación se ha vuelto un poco larga en este punto, y aún tenemos muchos detalles que considerar, por lo que vamos a tomar un descanso aquí. En la próxima publicación, utilizaremos la optimización bayesiana para particionar los mejores hiperparámetros para nuestro espacio de problemas y prepararnos para el entrenamiento/prueba en GPU usando CUDA.
en conclusión
En este artículo, nos propusimos crear un robot de comercio de Bitcoin rentable desde cero utilizando aprendizaje de refuerzo. Podemos realizar las siguientes tareas:
-
Cree un entorno de comercio de Bitcoin desde cero utilizando el gimnasio de OpenAI.
-
Utilice Matplotlib para crear una visualización del entorno.
-
Entrena y prueba nuestro bot usando una validación cruzada simple.
-
Modificar ligeramente nuestro robot para lograr rentabilidad
Aunque nuestro robot comercial no es tan rentable como nos gustaría, vamos en la dirección correcta. La próxima vez, nos aseguraremos de que nuestro bot pueda superar al mercado de manera consistente y veremos cómo se desempeña nuestro bot comercial en datos en vivo. ¡Esté atento a mi próximo artículo y larga vida a Bitcoin!
- 1