Réflexions sur les stratégies de négociation à haute fréquence (2)
Auteur:Je ne sais pas., Créé à partir de: 2023-08-04 17:17:30, Mis à jour à partir de: 2023-09-12 15:50:31
Réflexions sur les stratégies de négociation à haute fréquence (2)
Modélisation du montant de négociation cumulé
Dans l'article précédent, nous avons dérivé une expression pour la probabilité qu'un seul montant de transaction soit supérieur à une certaine valeur.
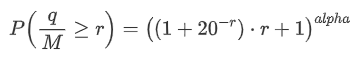
Nous sommes également intéressés par la répartition du montant des transactions sur une période de temps, qui devrait être intuitivement liée au montant des transactions individuelles et à la fréquence des commandes.
Dans [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
Dans [2]:
trades = pd.read_csv('HOOKUSDT-aggTrades-2023-01-27.csv')
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
buy_trades.index = buy_trades['date']
Nous combinons les montants des transactions individuelles à des intervalles de 1 seconde pour obtenir le montant des transactions agrégées, à l'exclusion des périodes sans activité de négociation. Nous ajustons ensuite ce montant agrégé en utilisant la distribution dérivée de l'analyse du montant des transactions individuelles mentionnée précédemment. Les résultats montrent un bon ajustement lorsque nous considérons chaque transaction dans l'intervalle de 1 seconde comme un seul commerce, résolvant efficacement le problème. Cependant, lorsque l'intervalle de temps est prolongé par rapport à la fréquence des transactions, nous observons une augmentation des erreurs. Des recherches ultérieures révèlent que cette erreur est causée par le terme de correction introduit par la distribution de Pareto.
Dans [3]:
df_resampled = buy_trades['quantity'].resample('1S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
Dans [4]:
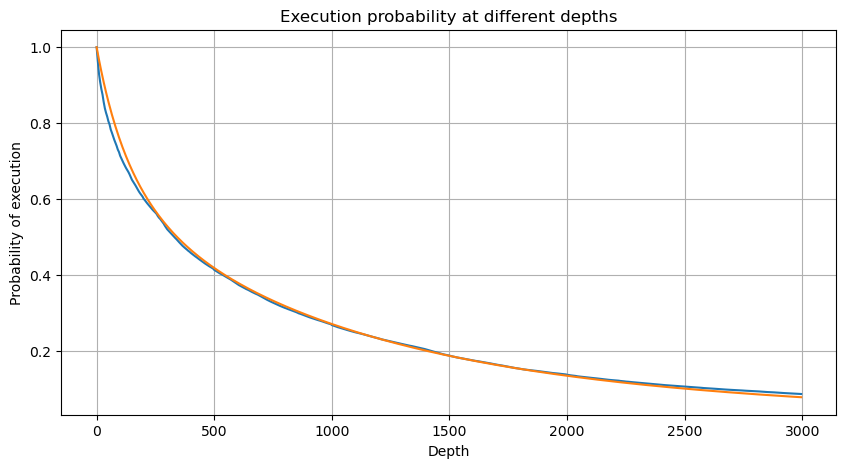
# Cumulative distribution in 1s
depths = np.array(range(0, 3000, 5))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
Extrait [4]:
Dans [5]:
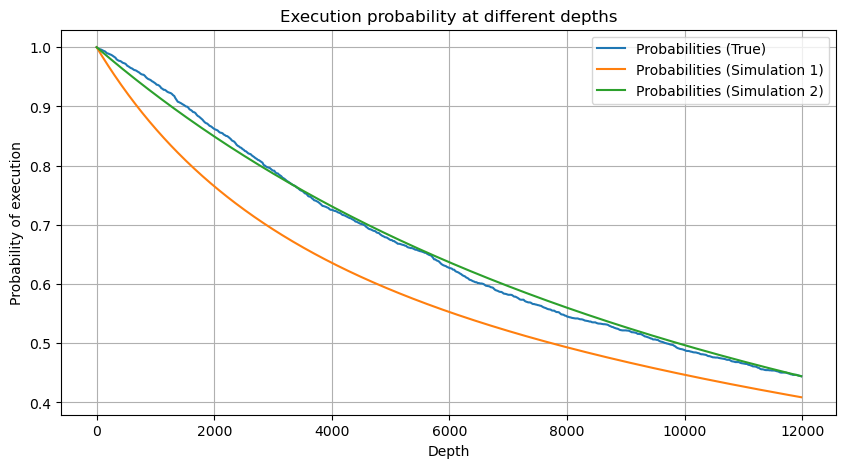
df_resampled = buy_trades['quantity'].resample('30S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 12000, 20))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2)
probabilities_s_2 = np.array([(depth/mean+1)**alpha for depth in depths]) # No amendment
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities,label='Probabilities (True)')
plt.plot(depths, probabilities_s, label='Probabilities (Simulation 1)')
plt.plot(depths, probabilities_s_2, label='Probabilities (Simulation 2)')
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.legend()
plt.grid(True)
Extrait [5]:
Résumez maintenant une formule générale pour la distribution du montant cumulé des transactions pour différentes périodes de temps, en utilisant la distribution du montant de la transaction unique pour s'adapter, au lieu de calculer séparément à chaque fois.
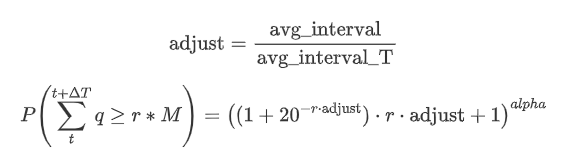
Ici, avg_interval représente l'intervalle moyen des transactions individuelles, et avg_interval_T représente l'intervalle moyen de l'intervalle qui doit être estimé. Cela peut sembler un peu déroutant. Si nous voulons estimer le montant de la transaction pour 1 seconde, nous devons calculer l'intervalle moyen entre les événements contenant des transactions dans un délai de 1 seconde. Si la probabilité d'arrivée des ordres suit une distribution de Poisson, elle devrait être directement estimable. Cependant, en réalité, il y a un écart significatif, mais je ne vais pas l'expliquer ici.
Notez que la probabilité que le montant de négociation dépasse une valeur spécifique dans un certain intervalle de temps et la probabilité réelle de négocier à cette position dans la profondeur devraient être très différentes. Au fur et à mesure que le temps d'attente augmente, la possibilité de changements dans le carnet d'ordres augmente et la négociation entraîne également des changements dans la profondeur. Par conséquent, la probabilité de négocier à la même position de profondeur change en temps réel à mesure que les données sont mises à jour.
Dans [6]:
df_resampled = buy_trades['quantity'].resample('2S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 6500, 10))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = buy_trades['quantity'].mean()
adjust = buy_trades['interval'].mean() / 2620
alpha = np.log(np.mean(buy_trades['quantity'] > mean))/0.7178397931503168
probabilities_s = np.array([((1+20**(-depth*adjust/mean))*depth*adjust/mean+1)**(alpha) for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
Extrait [6]:
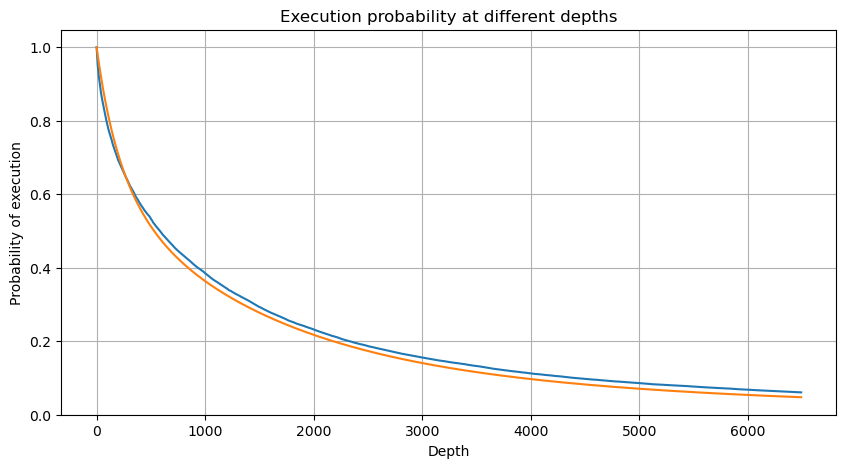
Impact sur les prix du commerce unique
Les données commerciales sont précieuses, et il y a encore beaucoup de données qui peuvent être extraites. Nous devrions prêter une attention particulière à l'impact des ordres sur les prix, car cela affecte le positionnement des stratégies. De même, en agrégant les données basées sur transact_time, nous calculons la différence entre le dernier prix et le premier prix. S'il n'y a qu'un seul ordre, la différence de prix est 0.
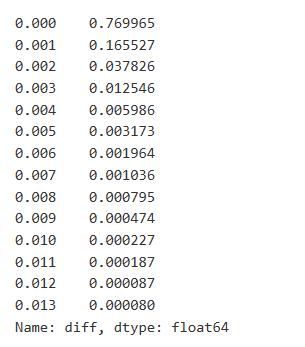
Les résultats montrent que la proportion de transactions qui n'ont pas eu d'impact est aussi élevée que 77%, tandis que la proportion de transactions qui ont provoqué un mouvement de prix de 1 tick est de 16,5%, 2 ticks est de 3,7%, 3 ticks est de 1,2%, et plus de 4 ticks est inférieure à 1%.
Le montant des transactions provoquant la différence de prix correspondante a également été analysé, à l'exclusion des distorsions causées par un impact excessif. Il montre une relation linéaire, avec environ 1 tick de fluctuation des prix causée par chaque 1000 unités de montant. Cela peut également être compris comme une moyenne d'environ 1000 unités d'ordres placés près de chaque niveau de prix du carnet de commandes.
Dans [7]:
diff_df = trades[trades['is_buyer_maker']==False].groupby('transact_time')['price'].agg(lambda x: abs(round(x.iloc[-1] - x.iloc[0],3)) if len(x) > 1 else 0)
buy_trades['diff'] = buy_trades['transact_time'].map(diff_df)
Dans [8]:
diff_counts = buy_trades['diff'].value_counts()
diff_counts[diff_counts>10]/diff_counts.sum()
À l'extérieur[8]:
Dans [9]:
diff_group = buy_trades.groupby('diff').agg({
'quantity': 'mean',
'diff': 'last',
})
Dans [10]:
diff_group['quantity'][diff_group['diff']>0][diff_group['diff']<0.01].plot(figsize=(10,5),grid=True);
À l'extérieur [10]:
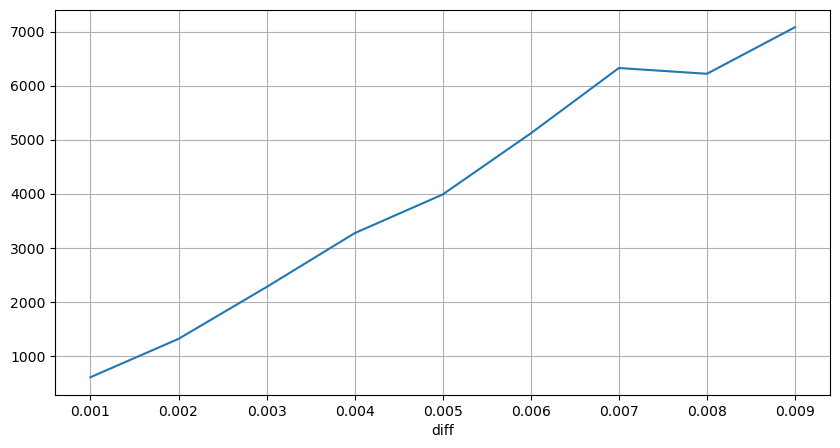
Impact sur les prix à intervalles fixes
La différence ici est qu'il peut y avoir des valeurs négatives. Cependant, comme nous ne considérons que des ordres d'achat, l'impact sur la position symétrique serait un tick plus élevé. Continuant à observer la relation entre le montant du commerce et l'impact, nous ne considérons que des résultats supérieurs à 0.
Dans [11]:
df_resampled = buy_trades.resample('2S').agg({
'price': ['first', 'last', 'count'],
'quantity': 'sum'
})
df_resampled['price_diff'] = round(df_resampled[('price', 'last')] - df_resampled[('price', 'first')],3)
df_resampled['price_diff'] = df_resampled['price_diff'].fillna(0)
result_df_raw = pd.DataFrame({
'price_diff': df_resampled['price_diff'],
'quantity_sum': df_resampled[('quantity', 'sum')],
'data_count': df_resampled[('price', 'count')]
})
result_df = result_df_raw[result_df_raw['price_diff'] != 0]
Dans [12]:
result_df['price_diff'][abs(result_df['price_diff'])<0.016].value_counts().sort_index().plot.bar(figsize=(10,5));
À l'extérieur [12]:
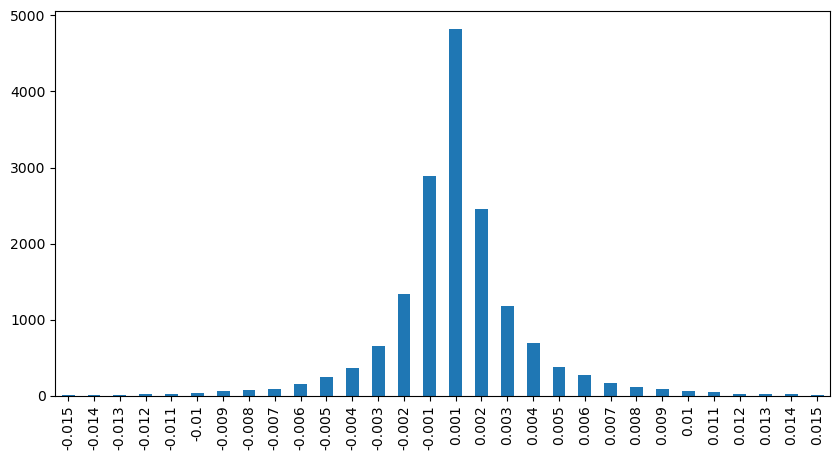
Dans [23]:
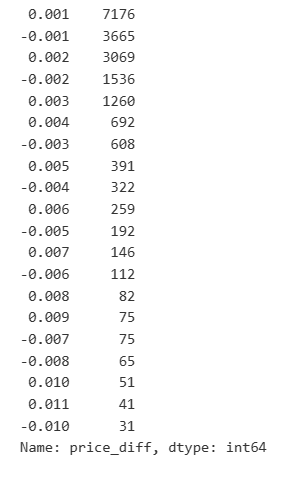
result_df['price_diff'].value_counts()[result_df['price_diff'].value_counts()>30]
Extrait[23]:
Dans [14]:
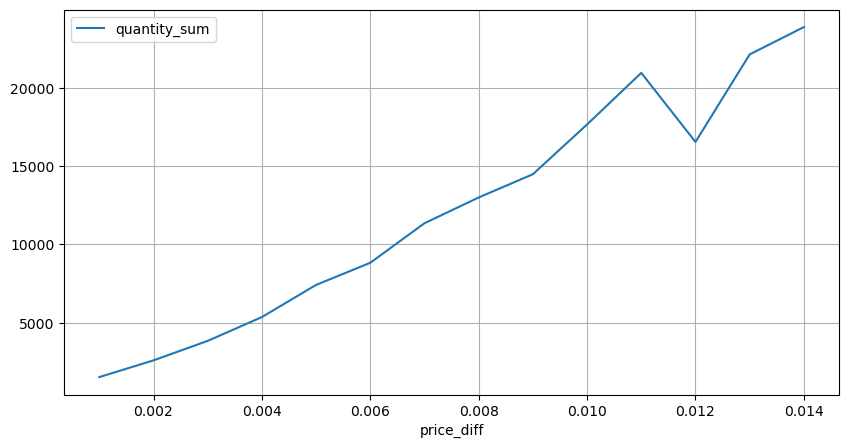
diff_group = result_df.groupby('price_diff').agg({ 'quantity_sum': 'mean'})
Dans [15]:
diff_group[(diff_group.index>0) & (diff_group.index<0.015)].plot(figsize=(10,5),grid=True);
Extrait [1]:
Impact sur les prix du montant des échanges
Auparavant, nous avons déterminé le montant des échanges requis pour un changement de tick, mais il n'était pas précis car il était basé sur l'hypothèse que l'impact s'était déjà produit.
Dans cette analyse, les données sont échantillonnées toutes les 1 seconde, chaque étape représentant 100 unités de quantité.
- Lorsque le montant de l'ordre d'achat est inférieur à 500, la variation de prix attendue est une baisse, ce qui est attendu puisqu'il y a aussi des ordres de vente ayant une incidence sur le prix.
- À des montants d'échange inférieurs, il existe une relation linéaire, ce qui signifie que plus le montant de l'échange est important, plus l'augmentation de prix est importante.
- En outre, l'échantillonnage à intervalles fixes ajoute à l'instabilité des données.
- Il est important de faire attention à la partie supérieure du graphique de dispersion, qui correspond à l'augmentation du prix avec le montant des transactions.
- Pour cette paire de transactions spécifique, nous fournissons une version approximative de la relation entre le montant des transactions et la variation des prix.
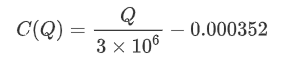
où
Dans [16]:
df_resampled = buy_trades.resample('1S').agg({
'price': ['first', 'last', 'count'],
'quantity': 'sum'
})
df_resampled['price_diff'] = round(df_resampled[('price', 'last')] - df_resampled[('price', 'first')],3)
df_resampled['price_diff'] = df_resampled['price_diff'].fillna(0)
result_df_raw = pd.DataFrame({
'price_diff': df_resampled['price_diff'],
'quantity_sum': df_resampled[('quantity', 'sum')],
'data_count': df_resampled[('price', 'count')]
})
result_df = result_df_raw[result_df_raw['price_diff'] != 0]
Dans [24]:
df = result_df.copy()
bins = np.arange(0, 30000, 100) #
labels = [f'{i}-{i+100-1}' for i in bins[:-1]]
df.loc[:, 'quantity_group'] = pd.cut(df['quantity_sum'], bins=bins, labels=labels)
grouped = df.groupby('quantity_group')['price_diff'].mean()
Dans [25]:
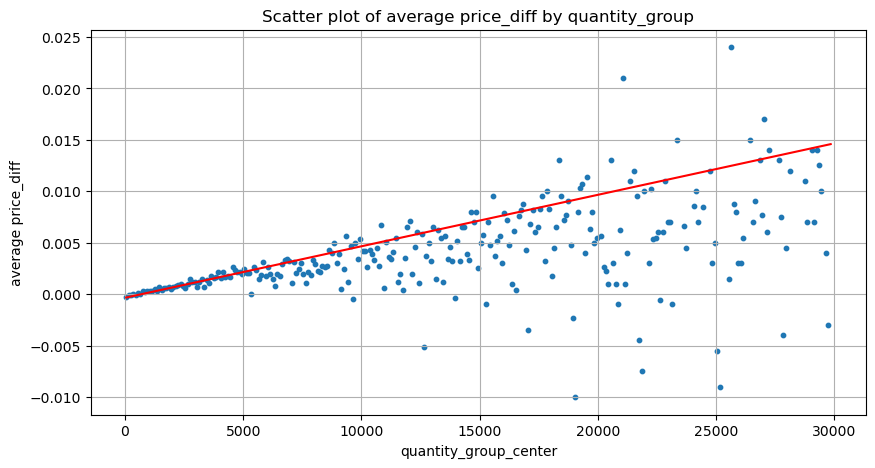
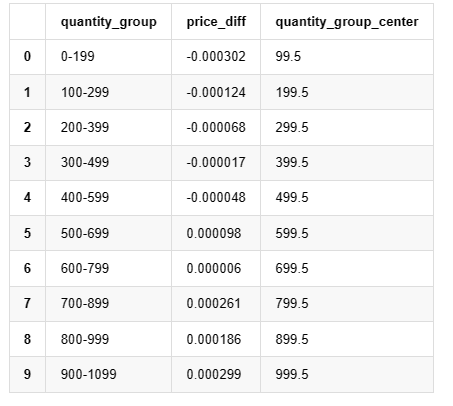
grouped_df = pd.DataFrame(grouped).reset_index()
grouped_df['quantity_group_center'] = grouped_df['quantity_group'].apply(lambda x: (float(x.split('-')[0]) + float(x.split('-')[1])) / 2)
plt.figure(figsize=(10,5))
plt.scatter(grouped_df['quantity_group_center'], grouped_df['price_diff'],s=10)
plt.plot(grouped_df['quantity_group_center'], np.array(grouped_df['quantity_group_center'].values)/2e6-0.000352,color='red')
plt.xlabel('quantity_group_center')
plt.ylabel('average price_diff')
plt.title('Scatter plot of average price_diff by quantity_group')
plt.grid(True)
Extrait[25]:
Dans [19]:
grouped_df.head(10)
Extrait [1]: Je ne veux pas de toi. Je veux de toi.
Placement préliminaire d'une commande optimale
Il semble possible de calculer le placement optimal des ordres en utilisant la modélisation du montant des transactions et le modèle approximatif de l'impact sur les prix correspondant au montant des transactions.
- Supposons que le prix revienne à sa valeur initiale après l'impact (ce qui est hautement improbable et nécessiterait une analyse plus approfondie du changement de prix après l'impact).
- Supposons que la répartition du volume des transactions et de la fréquence des commandes pendant cette période suit un schéma prédéfini (ce qui est également inexact, car nous estimons sur la base de données d'une journée et que les transactions présentent des phénomènes clairs de regroupement).
- Supposons qu'un seul ordre de vente se produise au cours du temps simulé, puis qu'il soit clôturé.
- Supposons qu'après l'exécution de l'ordre, il y ait d'autres ordres d'achat qui continuent à pousser le prix, surtout lorsque le montant est très bas.
Commençons par écrire un rendement attendu simple, qui est la probabilité que les ordres d'achat cumulés dépassent Q en 1 seconde, multipliée par le taux de rendement attendu (c'est-à-dire l'impact sur le prix).
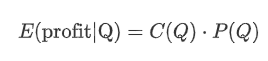
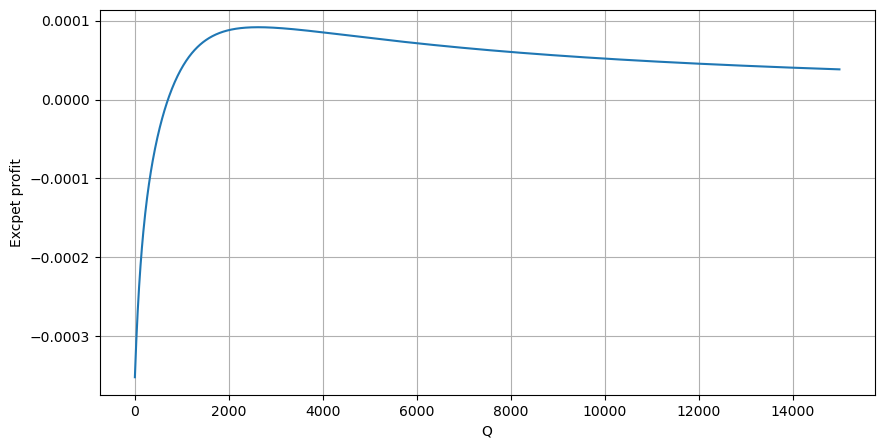
En fonction du graphique, le rendement maximal attendu est d'environ 2500, soit environ 2,5 fois le montant moyen des transactions. Cela suggère que l'ordre de vente doit être placé à une position de prix de 2500. Il est important de souligner que l'axe horizontal représente le montant des transactions en 1 seconde et ne doit pas être assimilé à la position de profondeur.
Résumé
Nous avons découvert que la répartition du montant des transactions à différents intervalles de temps est une simple mise à l'échelle de la répartition des montants des transactions individuelles. Nous avons également développé un modèle de rendement attendu simple basé sur l'impact des prix et la probabilité des transactions. Les résultats de ce modèle correspondent à nos attentes, montrant que si le montant de l'ordre de vente est faible, cela indique une baisse des prix et qu'un certain montant est nécessaire pour le potentiel de profit. La probabilité diminue à mesure que le montant des transactions augmente, avec une taille optimale entre les deux, ce qui représente la stratégie optimale de placement des commandes. Cependant, ce modèle est encore trop simpliste.
Dans [20]:
# Cumulative distribution in 1s
df_resampled = buy_trades['quantity'].resample('1S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 15000, 10))
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
profit_s = np.array([depth/2e6-0.000352 for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities_s*profit_s)
plt.xlabel('Q')
plt.ylabel('Excpet profit')
plt.grid(True)
Extrait [1]:
- Delta contre les options Bitcoin avec une courbe souriante
- Réflexions sur les stratégies de négociation à haute fréquence (5)
- Réflexions sur les stratégies de négociation à haute fréquence (4)
- Réflexion sur la stratégie de trading à haute fréquence (5)
- Réflexion sur les stratégies de trading à haute fréquence (4)
- Réflexions sur les stratégies de négociation à haute fréquence (3)
- Réflexion sur les stratégies de trading à haute fréquence (3)
- Réflexion sur la stratégie de trading à haute fréquence (2)
- Réflexions sur les stratégies de négociation à haute fréquence (1)
- Réflexion sur les stratégies de trading à haute fréquence (1)
- Document de description de la configuration des titres Futu
- FMZ Quant Uniswap V3 Guide des opérations liées à la liquidité des fonds communs de change (partie 1)
- FMZ quantifier Uniswap V3 pour les opérations liées à la fluidité des bassins de change (part 1)