Réflexions sur les stratégies de négociation à haute fréquence (3)
Auteur:Je ne sais pas., Créé à partir de: 2023-08-08 10:05:19, Mis à jour à partir de: 2023-09-12 15:50:55
Réflexions sur les stratégies de négociation à haute fréquence (3)
Dans l'article précédent, j'ai présenté comment modéliser le volume cumulatif des transactions et analysé le phénomène de l'impact des prix. Dans cet article, je continuerai à analyser les données des ordres de transactions. YGG a récemment lancé des contrats basés sur Binance U, et les fluctuations de prix ont été importantes, le volume des transactions dépassant même BTC à un moment donné. Aujourd'hui, je vais l'analyser.
Temps de commande
En général, on suppose que le temps d'arrivée des commandes suit un processus de Poisson.Le procédé du poissonJe vais vous fournir des preuves empiriques.
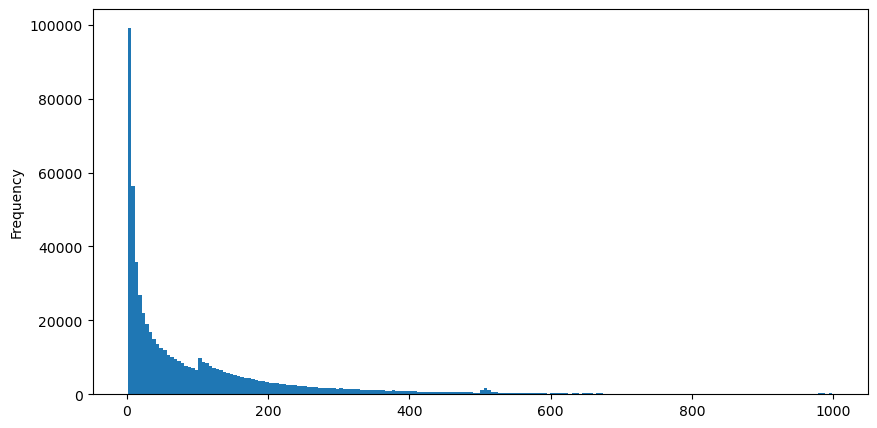
J'ai téléchargé les données aggTrades pour le 5 août, qui se compose de 1 931 193 transactions, ce qui est assez significatif. Tout d'abord, jetons un coup d'œil à la distribution des ordres d'achat. Nous pouvons voir un pic local non lisse autour de 100 ms et 500 ms, ce qui est probablement causé par des ordres d'iceberg placés par des robots de trading à intervalles réguliers. Cela peut également être l'une des raisons des conditions de marché inhabituelles ce jour-là.
La fonction de masse de probabilité de la distribution de Poisson est donnée par la formule suivante:
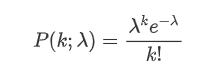
Où:
- κ est le nombre d'événements qui nous intéressent.
- λ est le taux moyen d'événements survenant par unité de temps (ou unité d'espace).
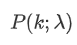 représente la probabilité que se produisent exactement κ événements, étant donné le taux moyen λ.
représente la probabilité que se produisent exactement κ événements, étant donné le taux moyen λ.
Dans un processus de Poisson, les intervalles de temps entre les événements suivent une distribution exponentielle.
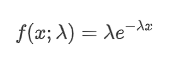
Le processus de Poisson sous-estime la fréquence des intervalles de temps longs et surestime la fréquence des intervalles de temps courts. (La distribution réelle des intervalles est plus proche d'une distribution de Pareto modifiée)
Dans [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
Dans [2]:
trades = pd.read_csv('YGGUSDT-aggTrades-2023-08-05.csv')
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
buy_trades.index = buy_trades['date']
Dans [10]:
buy_trades['interval'][buy_trades['interval']<1000].plot.hist(bins=200,figsize=(10, 5));
À l'extérieur [10]:
Dans [20]:
Intervals = np.array(range(0, 1000, 5))
mean_intervals = buy_trades['interval'].mean()
buy_rates = 1000/mean_intervals
probabilities = np.array([np.mean(buy_trades['interval'] > interval) for interval in Intervals])
probabilities_s = np.array([np.e**(-buy_rates*interval/1000) for interval in Intervals])
plt.figure(figsize=(10, 5))
plt.plot(Intervals, probabilities)
plt.plot(Intervals, probabilities_s)
plt.xlabel('Intervals')
plt.ylabel('Probability')
plt.grid(True)
Extrait [1]:
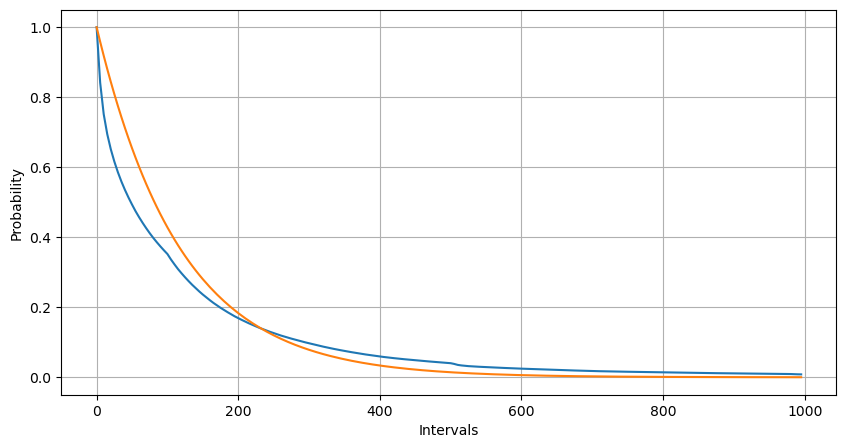
Lorsque l'on compare la distribution du nombre d'événements d'ordre en 1 seconde avec la distribution de Poisson, la différence est également significative.
- Taux d'occurrence non constant: le processus de Poisson suppose que le taux moyen d'événements se produisant dans un intervalle de temps donné est constant.
- Interactions entre les processus: Une autre hypothèse fondamentale du processus de Poisson est que les événements sont indépendants les uns des autres.
En d'autres termes, dans un environnement réel, la fréquence des occurrences d'ordres n'est pas constante et doit être mise à jour en temps réel.
En [190]:
result_df = buy_trades.resample('1S').agg({
'price': 'count',
'quantity': 'sum'
}).rename(columns={'price': 'order_count', 'quantity': 'quantity_sum'})
Dans [219]:
count_df = result_df['order_count'].value_counts().sort_index()[result_df['order_count'].value_counts()>20]
(count_df/count_df.sum()).plot(figsize=(10,5),grid=True,label='sample pmf');
from scipy.stats import poisson
prob_values = poisson.pmf(count_df.index, 1000/mean_intervals)
plt.plot(count_df.index, prob_values,label='poisson pmf');
plt.legend() ;
À l'extérieur[219]:
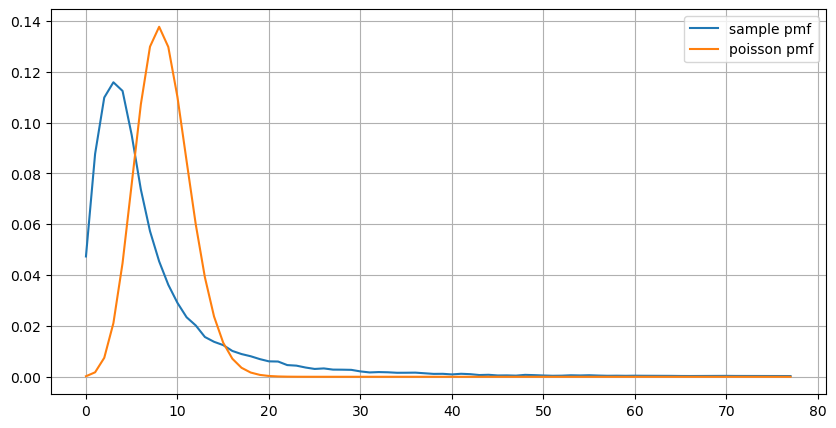
Mise à jour des paramètres en temps réel
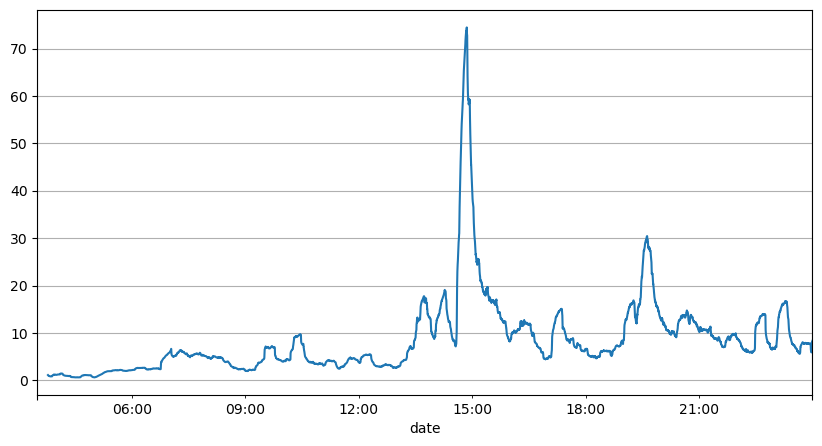
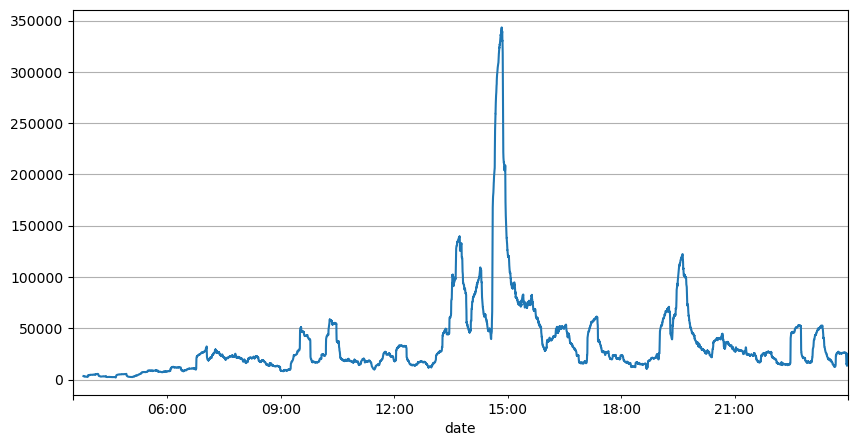
L'analyse des intervalles d'ordres précédents permet de conclure que les paramètres fixes ne sont pas adaptés aux conditions réelles du marché et que les paramètres clés décrivant le marché dans la stratégie doivent être mis à jour en temps réel. La solution la plus simple consiste à utiliser une moyenne mobile de fenêtre mobile. Les deux graphiques ci-dessous montrent la fréquence des ordres d'achat en 1 seconde et la moyenne du volume de négociation avec une taille de fenêtre de 1000. On peut observer qu'il existe un phénomène de regroupement dans le commerce, où la fréquence des ordres est nettement plus élevée que d'habitude pendant une période de temps, et le volume augmente également de manière synchrone.
Les graphes nous permettent de comprendre pourquoi la fréquence d'ordre s'écarte si fortement de la distribution de Poisson.
Il s'avère que l'utilisation de la moyenne des deux secondes précédentes pour prédire produit la plus petite erreur résiduelle, et c'est beaucoup mieux que d'utiliser simplement la moyenne pour les résultats de prédiction.
Dans [221]:
result_df['order_count'].rolling(1000).mean().plot(figsize=(10,5),grid=True);
À l'extérieur [1]:
En [193]:
result_df['quantity_sum'].rolling(1000).mean().plot(figsize=(10,5),grid=True);
À l'extérieur [1]:
En [195]:
(result_df['order_count'] - result_df['mean_count'].mean()).abs().mean()
Extrait[195]:
6.985628185332997
Dans [205]:
result_df['mean_count'] = result_df['order_count'].rolling(2).mean()
(result_df['order_count'] - result_df['mean_count'].shift()).abs().mean()
À l'extérieur[205]:
3.091737586730269
Résumé
Cet article explique brièvement les raisons de l'écart des intervalles de temps d'ordre du processus de Poisson, principalement en raison de la variation des paramètres au fil du temps. Afin de prédire avec précision le marché, les stratégies doivent faire des prévisions en temps réel des paramètres fondamentaux du marché. Les résidus peuvent être utilisés pour mesurer la qualité des prédictions.
- Delta contre les options Bitcoin avec une courbe souriante
- Réflexions sur les stratégies de négociation à haute fréquence (5)
- Réflexions sur les stratégies de négociation à haute fréquence (4)
- Réflexion sur la stratégie de trading à haute fréquence (5)
- Réflexion sur les stratégies de trading à haute fréquence (4)
- Réflexion sur les stratégies de trading à haute fréquence (3)
- Réflexions sur les stratégies de négociation à haute fréquence (2)
- Réflexion sur la stratégie de trading à haute fréquence (2)
- Réflexions sur les stratégies de négociation à haute fréquence (1)
- Réflexion sur les stratégies de trading à haute fréquence (1)
- Document de description de la configuration des titres Futu
- FMZ Quant Uniswap V3 Guide des opérations liées à la liquidité des fonds communs de change (partie 1)
- FMZ quantifier Uniswap V3 pour les opérations liées à la fluidité des bassins de change (part 1)